Within the period of generative AI, new giant language fashions (LLMs) are frequently rising, every with distinctive capabilities, architectures, and optimizations. Amongst these, Amazon Nova basis fashions (FMs) ship frontier intelligence and industry-leading cost-performance, obtainable completely on Amazon Bedrock. Since its launch in 2024, generative AI practitioners, together with the groups in Amazon, have began transitioning their workloads from present FMs and adopting Amazon Nova fashions.
Nonetheless, when transitioning between totally different basis fashions, the prompts created in your unique mannequin may not be as performant for Amazon Nova fashions with out immediate engineering and optimization. Amazon Bedrock immediate optimization gives a instrument to robotically optimize prompts in your specified goal fashions (on this case, Amazon Nova fashions). It will possibly convert your unique prompts to Amazon Nova-style prompts. Moreover, in the course of the migration to Amazon Nova, a key problem is ensuring that efficiency after migration is at the least pretty much as good as or higher than previous to the migration. To mitigate this problem, thorough mannequin analysis, benchmarking, and data-aware optimization are important, to check the Amazon Nova mannequin’s efficiency towards the mannequin used earlier than the migration, and optimize the prompts on Amazon Nova to align efficiency with that of the earlier workload or enhance upon them.
On this publish, we current an LLM migration paradigm and structure, together with a steady strategy of mannequin analysis, immediate technology utilizing Amazon Bedrock, and data-aware optimization. The answer evaluates the mannequin efficiency earlier than migration and iteratively optimizes the Amazon Nova mannequin prompts utilizing user-provided dataset and goal metrics. We exhibit profitable migration to Amazon Nova for 3 LLM duties: textual content summarization, multi-class textual content classification, and question-answering applied by Retrieval Augmented Technology (RAG). We additionally focus on the teachings realized and greatest practices so that you can implement the answer in your real-world use instances.
Migrating your generative AI workloads to Amazon Nova
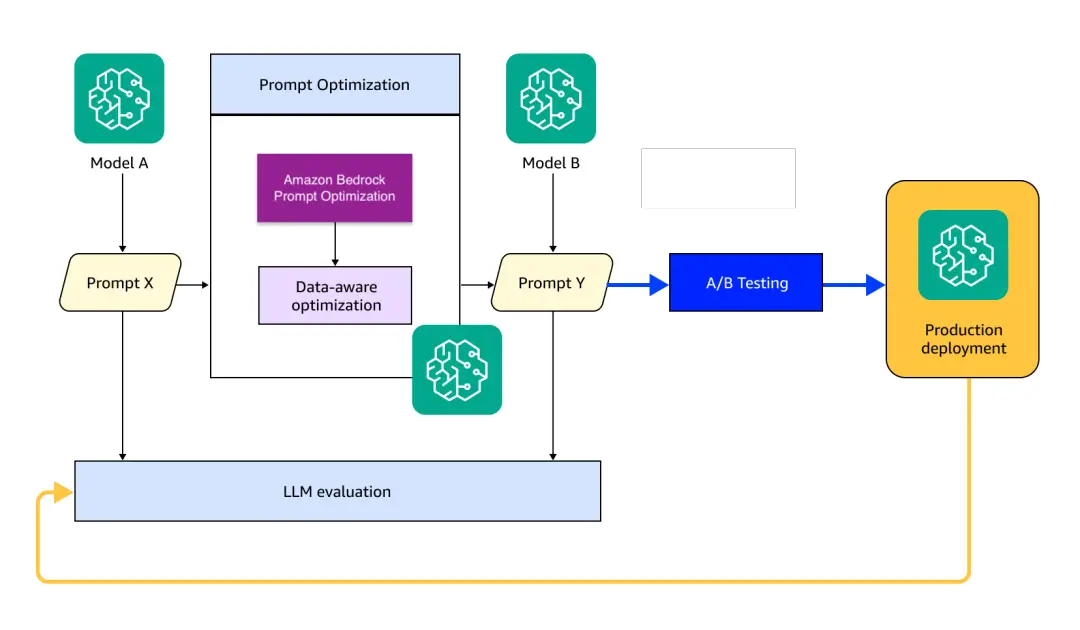
Migrating the mannequin out of your generative AI workload to Amazon Nova requires a structured method to realize efficiency consistency and enchancment. It consists of evaluating and benchmarking the outdated and new fashions, optimizing prompts on the brand new mannequin, and testing and deploying the brand new fashions in your manufacturing. On this part, we current a four-step workflow and an answer structure, as proven within the following structure diagram.

The workflow consists of the next steps:
- Consider the supply mannequin and gather key efficiency metrics based mostly on what you are promoting use case, akin to response accuracy, response format correctness, latency, and price, to set a efficiency baseline because the mannequin migration goal.
- Robotically replace the construction, instruction, and language of your prompts to adapt to the Amazon Nova mannequin for correct, related, and trustworthy outputs. We’ll focus on this extra within the subsequent part.
- Consider the optimized prompts on the migrated Amazon Nova mannequin to satisfy the efficiency goal outlined in Step 1. You may conduct the optimization in Step 2 as an iterative course of till the optimized prompts meet what you are promoting standards.
- Conduct A/B testing to validate the Amazon Nova mannequin efficiency in your testing and manufacturing surroundings. While you’re happy, you’ll be able to deploy the Amazon Nova mannequin, settings, and prompts in manufacturing.
This four-step workflow must run repeatedly, to adapt to variations in each the mannequin and the info, pushed by the modifications in enterprise use instances. The continual adaptation supplies ongoing optimization and helps maximize total mannequin efficiency.
Knowledge-aware immediate optimization on Amazon Nova
On this part, we current a complete optimization methodology, taking two steps. Step one is to make use of Amazon Bedrock immediate optimization to refine your immediate construction, after which use an modern data-aware immediate optimization method to additional optimize the immediate to enhance the Amazon Nova mannequin efficiency.
Amazon Bedrock immediate optimization
Amazon Bedrock supplies a immediate optimization function that rewrites prompts to enhance efficiency in your use instances. Immediate optimization streamlines the way in which that AWS builders work together with FMs on Amazon Bedrock, robotically adapts the prompts to the chosen fashions, and generates for higher efficiency.
As step one, you should use immediate optimization to adapt your immediate to Amazon Nova. By analyzing the immediate you present, the function interprets the duty, system immediate, and instruction throughout the immediate, and robotically crafts the immediate with Amazon Nova particular format and acceptable phrases, phrases, and sentences. The next instance exhibits how immediate optimization converts a typical immediate for a summarization activity on Anthropic’s Claude Haiku right into a well-structured immediate for an Amazon Nova mannequin, with sections that start with particular markdown tags akin to ## Process, ### Summarization Directions, and ### Doc to Summarize.
| Mannequin | Immediate |
| Anthropic’s Claude 3 Haiku | Human: Act like you’re an clever AI assistant. You might be required to offer a summarization based mostly on given doc. Please use beneath directions when producing the response. The doc is offered in Please be temporary and concise in your reply. Don’t add any data that isn’t talked about within the doc. Don’t present any preamble and immediately begin with the summarization. Don’t make up the reply, Should you don’t know the reply, simply say that I don’t know. |
| Amazon Nova Lite with Amazon Bedrock immediate optimization |
### Process Your activity is to summarize the given doc enclosed in – Learn the doc rigorously to grasp its details and key data. – Determine the core concepts, arguments, and supporting particulars introduced within the doc. – Synthesize the important data into a transparent and succinct abstract. – Use your individual phrases to paraphrase the important thing factors – don’t copy verbatim from the unique textual content. – Omit any extraneous or redundant data not central to the principle concepts. – Don’t introduce new data or make up content material not current within the unique doc. – Should you can not summarize the doc because of lack of expertise, merely reply “I don’t know.”### Doc to Summarize |
We utilized the previous prompts to the Anthropic Claude 3 Haiku and Amazon Nova Lite fashions, respectively, utilizing the general public xsum dataset. To guage the mannequin efficiency, as a result of the summarization activity doesn’t have a predefined floor reality, we designed an LLM decide as proven within the following immediate to validate the summarization high quality:
The experiment, utilizing 80 information samples, exhibits that the accuracy is improved on the Amazon Nova Lite mannequin from 77.75% to 83.25% utilizing immediate optimization.
Knowledge-aware optimization
Though Amazon Bedrock immediate optimization helps the fundamental wants of immediate engineering, different immediate optimization strategies can be found to maximise LLM efficiency, akin to Multi-Facet Critique, Self-Reflection, Gradient Descent and Beam Search, and Meta Prompting. Particularly, we noticed necessities from customers that they should fine-tune their prompts towards their optimization goal metrics they outline, akin to ROUGE, BERT-F1, or an LLM decide rating, through the use of a dataset they supply. To fulfill these wants, we designed a data-aware optimization structure as proven within the following diagram.

The info-aware optimization takes inputs. The primary enter is the user-defined optimization goal metrics; for the summarization activity mentioned within the earlier part, you should use the BERT-F1 rating or create your individual LLM decide. The second enter is a coaching dataset (DevSet) offered by the consumer to validate the response high quality, for instance, a summarization information pattern with the next format.
| Supply Doc | Summarization |
| Officers searched properties within the Waterfront Park and Colonsay View areas of the town on Wednesday. Detectives mentioned three firearms, ammunition and a five-figure sum of cash have been recovered. A 26-year-old man who was arrested and charged appeared at Edinburgh Sheriff Courtroom on Thursday. | A person has appeared in court docket after firearms, ammunition and money have been seized by police in Edinburgh. |
|
|
The info-aware optimization makes use of these two inputs to enhance the immediate for higher Amazon Nova response high quality. On this work, we use the DSPy (Declarative Self-improving Python) optimizer for the data-aware optimization. DSPy is a broadly used framework for programming language fashions. It gives algorithms for optimizing the prompts for a number of LLM duties, from easy classifiers and summarizers to classy RAG pipelines. The dspy.MIPROv2 optimizer intelligently explores higher pure language directions for each immediate utilizing the DevSet, to maximise the metrics you outline.
We utilized the MIPROv2 optimizer on prime of the outcomes optimized by Amazon Bedrock within the earlier part for higher Amazon Nova efficiency. Within the optimizer, we specify the variety of the instruction candidates within the technology house, use Bayesian optimization to successfully search over the house, and run it iteratively to generate directions and few-shot examples for the immediate in every step:
With the setting of num_candidates=5, the optimizer generates 5 candidate directions:
We set different parameters for the optimization iteration, together with the variety of trials, the variety of few-shot examples, and the batch measurement for the optimization course of:
When the optimization begins, MIPROv2 makes use of every instruction candidate together with the mini-batch of the testing dataset we offered to deduce the LLM and calculate the metrics we outlined. After the loop is full, the optimizer evaluates the very best instruction through the use of the total testing dataset and calculates the total analysis rating. Based mostly on the iterations, the optimizer supplies the improved instruction for the immediate:
Making use of the optimized immediate, the summarization accuracy generated by the LLM decide on Amazon Nova Lite mannequin is additional improved from 83.25% to 87.75%.
We additionally utilized the optimization course of on different LLM duties, together with a multi-class textual content classification activity, and a question-answering activity utilizing RAG. In all of the duties, our method optimized the migrated Amazon Nova mannequin to out-perform the Anthropic Claude Haiku and Meta Llama fashions earlier than migration. The next desk and chart illustrate the optimization outcomes.
| Process | DevSet | Analysis | Earlier than Migration | After Migration (Amazon Bedrock Immediate Optimization) | After Migration (DSPy with Amazon Bedrock Immediate Optimization) |
| Summarization (Anthropic Claude 3 Haiku to Amazon Nova Lite) | 80 samples | LLM Choose | 77.75 | 83.25 | 87.75 |
| Classification (Meta Llama 3.2 3B to Amazon Nova Micro) | 80 samples | Accuracy | 81.25 | 81.25 | 87.5 |
| QA-RAG (Anthropic Claude 3 Haiku to Amazon Nova Lite) | 50 samples | Semantic Similarity | 52.71 | 51.6 | 57.15 |

For the textual content classification use case, we optimized the Amazon Nova Micro mannequin utilizing 80 samples, utilizing the accuracy metrics to judge the optimization efficiency in every step. After seven iterations, the optimized immediate supplies 87.5% accuracy, improved from the accuracy of 81.25% operating on the Meta Llama 3.2 3B mannequin.
For the question-answering use case, we used 50 samples to optimize the immediate for an Amazon Nova Lite mannequin within the RAG pipeline, and evaluated the efficiency utilizing a semantic similarity rating. The rating compares the cosine distance between the mannequin’s reply and the bottom reality reply. Evaluating to the testing information operating on Anthropic’s Claude 3 Haiku, the optimizer improved the rating from 52.71 to 57.15 after migrating to the Amazon Nova Lite mannequin and immediate optimization.
You’ll find extra particulars of those examples within the GitHub repository.
Classes realized and greatest practices
Via the answer design, we have now recognized greatest practices that may aid you correctly configure your immediate optimization to maximise the metrics you specify in your use case:
- Your dataset for optimizer must be of top quality and relevancy, and well-balanced to cowl the info patterns and edge instances of your use case, and nuances to reduce biases.
- The metrics you outlined because the goal of optimization must be use case particular. For instance, in case your dataset has floor reality, then you should use statistical and programmatical machine studying (ML) metrics akin to accuracy and semantic similarity In case your dataset doesn’t embody floor reality, a well-designed and human-aligned LLM decide can present a dependable analysis rating for the optimizer.
- The optimizer runs with quite a lot of immediate candidates (parameter
dspy.num_candidates) and makes use of the analysis metric you outlined to pick the optimum immediate because the output. Keep away from setting too few candidates that may miss alternative for enchancment. Within the earlier summarization instance, we set 5 immediate candidates for optimizing by means of 80 coaching samples, and acquired good optimization efficiency. - The immediate candidates embody a mixture of immediate directions and few-shot examples. You may specify the variety of examples (parameter
dspy.max_labeled_demosfor examples from labeled samples, and parameterdspy.max_bootstrapped_demosfor examples from unlabeled samples); we suggest the instance quantity be at least 2. - The optimization runs in iteration (parameter
dspy.num_trials); you must set sufficient iterations that assist you to refine prompts based mostly on totally different situations and efficiency metrics, and progressively improve readability, relevance, and flexibility. Should you optimize each the directions and the few-shot examples within the immediate, we suggest you set the iteration quantity to at least 2, ideally between 5–10.
In your use case, in case your immediate construction is complicated with chain-of-thoughts or tree-of-thoughts, lengthy directions within the system immediate, and a number of inputs within the consumer immediate, you should use a task-specific class to summary the DSPy optimizer. The category helps encapsulate the optimization logic, standardize the immediate construction and optimization parameters, and permit easy implementation of various optimization methods. The next is an instance of the category created for textual content classification activity:
Conclusion
On this publish, we launched the workflow and structure so that you can migrate your present generative AI workload into Amazon Nova fashions, and introduced a complete immediate optimization method utilizing Amazon Bedrock immediate optimization and a data-aware immediate optimization methodology with DSPy. The outcomes on three LLM duties demonstrated the optimized efficiency of Amazon Nova in its intelligence courses and the mannequin efficiency improved by Amazon Bedrock immediate optimization post-model migration, which is additional enhanced by the data-aware immediate optimization methodology introduced on this publish.
The Python library and code examples are publicly obtainable on GitHub. You should use this LLM migration technique and the immediate optimization resolution emigrate your workloads into Amazon Nova, or in different mannequin migration processes.
Concerning the Authors
 Yunfei Bai is a Principal Options Architect at AWS. With a background in AI/ML, information science, and analytics, Yunfei helps prospects undertake AWS providers to ship enterprise outcomes. He designs AI/ML and information analytics options that overcome complicated technical challenges and drive strategic aims. Yunfei has a PhD in Digital and Electrical Engineering. Outdoors of labor, Yunfei enjoys studying and music.
Yunfei Bai is a Principal Options Architect at AWS. With a background in AI/ML, information science, and analytics, Yunfei helps prospects undertake AWS providers to ship enterprise outcomes. He designs AI/ML and information analytics options that overcome complicated technical challenges and drive strategic aims. Yunfei has a PhD in Digital and Electrical Engineering. Outdoors of labor, Yunfei enjoys studying and music.
 Anupam Dewan is a Senior Options Architect with a ardour for generative AI and its functions in actual life. He and his workforce allow Amazon Builders who construct buyer dealing with software utilizing generative AI. He lives in Seattle space, and outdoors of labor likes to go on mountain climbing and luxuriate in nature.
Anupam Dewan is a Senior Options Architect with a ardour for generative AI and its functions in actual life. He and his workforce allow Amazon Builders who construct buyer dealing with software utilizing generative AI. He lives in Seattle space, and outdoors of labor likes to go on mountain climbing and luxuriate in nature.
 Shuai Wang is a Senior Utilized Scientist and Supervisor at Amazon Bedrock, specializing in pure language processing, machine studying, giant language modeling, and different associated AI areas. Outdoors work, he enjoys sports activities, notably basketball, and household actions.
Shuai Wang is a Senior Utilized Scientist and Supervisor at Amazon Bedrock, specializing in pure language processing, machine studying, giant language modeling, and different associated AI areas. Outdoors work, he enjoys sports activities, notably basketball, and household actions.
 Kashif Imran is a seasoned engineering and product chief with deep experience in AI/ML, cloud structure, and large-scale distributed programs. Presently a Senior Supervisor at AWS, Kashif leads groups driving innovation in generative AI and Cloud, partnering with strategic cloud prospects to rework their companies. Kashif holds twin grasp’s levels in Pc Science and Telecommunications, and makes a speciality of translating complicated technical capabilities into measurable enterprise worth for enterprises.
Kashif Imran is a seasoned engineering and product chief with deep experience in AI/ML, cloud structure, and large-scale distributed programs. Presently a Senior Supervisor at AWS, Kashif leads groups driving innovation in generative AI and Cloud, partnering with strategic cloud prospects to rework their companies. Kashif holds twin grasp’s levels in Pc Science and Telecommunications, and makes a speciality of translating complicated technical capabilities into measurable enterprise worth for enterprises.



{kind=link}