
Organizations and people working a number of customized AI fashions, particularly latest Combination of Specialists (MoE) mannequin households, can face the problem of paying for idle GPU capability when the person fashions don’t obtain sufficient visitors to saturate a devoted compute endpoint. To resolve this drawback, we have now partnered with the vLLM group and developed an environment friendly answer for Multi-Low-Rank Adaptation (Multi-LoRA) serving of fashionable open-source MoE fashions like GPT-OSS or Qwen. Multi-LoRA is a well-liked strategy to fine-tune fashions. As an alternative of retraining complete mannequin weights, multi-LoRA retains the unique weights frozen and injects small, trainable adapters into the mannequin’s layers. With multi-LoRA, at inference time, a number of customized fashions share the identical GPU, with solely the adapters swapped out and in per request. For instance, 5 clients every using solely 10% of a devoted GPU will be served from a single GPU with multi-LoRA, turning 5 underutilized GPUs into one effectively shared GPU.
On this submit, we clarify how we carried out multi-LoRA inference for Combination of Specialists (MoE) fashions in vLLM, describe the kernel-level optimizations we carried out, and present you how one can profit from this work. We use GPT-OSS 20B as our main instance all through this submit.
You should use these enhancements right now in your native vLLM deployments with model 0.15.0 or later. Multi-LoRA serving now works for MoE mannequin households together with GPT-OSS, Qwen3-MoE, DeepSeek, and Llama MoE. Our optimizations additionally assist enhance multi-LoRA internet hosting for dense fashions, e.g., Llama3.3 70B or Qwen3 32B. Amazon-specific optimizations ship extra latency enhancements over vLLM 0.15.0, e.g., 19% larger Output Tokens Per Second (OTPS) (i.e., how briskly the mannequin generates output) and eight% decrease Time To First Token (TTFT) (i.e., how lengthy you must wait earlier than the mannequin begins to generate output) for GPT-OSS 20B. To learn from these optimizations, host your LoRA personalized fashions on Amazon SageMaker AI or Amazon Bedrock.
Implementing multi-LoRA inference for MoE fashions in vLLM
Earlier than we dive into our preliminary implementation of multi-LoRA inference for MoE fashions in vLLM, we wish to present some background info on MoE fashions and LoRA fine-tuning that’s essential for understanding the rationale behind our optimizations. MoE fashions include a number of specialised neural networks known as consultants. A router directs every enter token to probably the most related consultants, whose outputs are then aggregated. This sparse structure processes bigger fashions with fewer computational assets as a result of solely a fraction of the mannequin’s whole parameters are activated per token, see Determine 1 under for a visualization.
Every skilled is a small feed-forward community that processes a token’s hidden state in two levels. First, the gate_up projection expands the compact hidden state (e.g., 4096 dims) into a bigger intermediate area (e.g., 11008 dims). This enlargement is critical as a result of options within the compact area are tightly entangled – the bigger area provides the community room to drag them aside, rework them, and selectively gate which of them matter. Second, the down projection compresses the outcome again to the unique dimension. This helps maintain the output suitable with the remainder of the mannequin and acts as a bottleneck, forcing the community to retain solely probably the most helpful options. Collectively, this “expand-then-compress” sample lets every skilled apply wealthy transformations whereas sustaining a constant output measurement. vLLM makes use of a fused_moe kernel to execute these projections as Group Basic Matrix Multiply (Group GEMM) operations — one GEMM per skilled assigned to a given token. Multi-LoRA fine-tuning retains the bottom mannequin weights W, e.g., W_gate_up for the gate_up projection, frozen and trains two small matrices A and B that collectively kind an adapter. For a projection with base weights W of form h_in × h_out, LoRA trains A of form h_in × r and B of form r × h_out, the place r is the LoRA rank (sometimes 16-64). The fine-tuned output turns into y = xW + xAB. Every LoRA adapter provides two operations to a projection. The shrink operation computes z=xA, decreasing the enter from h_in dimensions all the way down to r dimensions. The increase operation takes that r-dimensional outcome and tasks it again to h_out dimensions by multiplying z with B. That is illustrated on the appropriate of Determine 1.
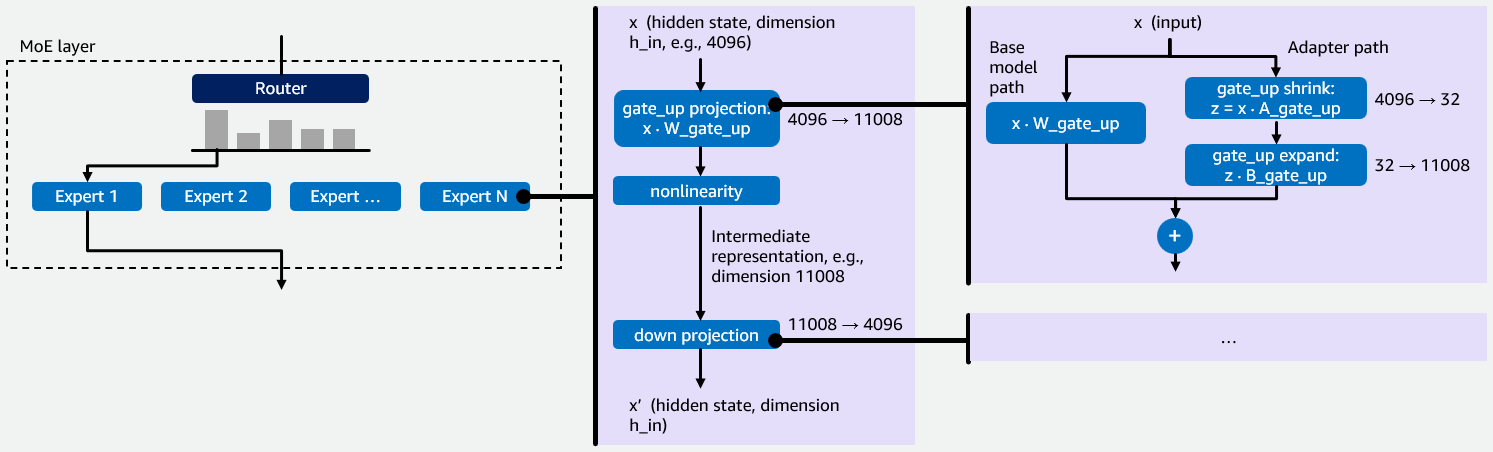
Determine 1: Illustration of how MoE-LoRA fashions work with an instance hidden state dimension 4096, intermediate illustration dimension 11008 and LoRA rank r = 32.
Every skilled has two weight projections: gate_up and down. When a LoRA adapter is utilized, it provides two low-rank operations, i.e., shrink and increase, to every projection. This implies each skilled requires 4 LoRA kernel operations in whole: shrink and increase for gate_up, and shrink and increase for down. In a multi-LoRA serving setup, the place a number of LoRA adapters are served concurrently for various customers or duties, the system should effectively handle these 4 operations per skilled, per adapter, per request. This makes it a key efficiency bottleneck for MoE fashions. The 4 operations contain matrices, the place one dimension (the LoRA rank r) is 100-300× smaller than the opposite (e.g., hidden state and intermediate illustration dimension). Customary GEMM kernels are designed for roughly sq. matrices and carry out poorly on skinny matrices, which is why the kernel optimizations described later on this submit are vital. Moreover having to optimize for skinny matrices, including multi-LoRA help for MoE fashions introduced two technical challenges. First, vLLM lacked a kernel to carry out LoRA on MoE layers as a result of current dense multi-LoRA kernels don’t deal with skilled routing. Second, MoE LoRA combines two sources of sparsity: skilled routing (tokens assigned to completely different consultants) and adapter choice (requests utilizing completely different LoRA adapters). This compound sparsity requires a specialised kernel design. To handle these challenges, we created a fused_moe_lora kernel that integrates LoRA operations into the fused_moe kernel. This new kernel performs LoRA shrink and increase GEMMs for the gate_up and down projections. The fused_moe_lora kernel follows the identical logic because the fused_moe kernel and provides a further dimension to the grid for the corresponding activated LoRA adapters.
With this implementation merged into vLLM, we may run a multi-LoRA serving with GPT-OSS 20B on an H200 GPU, reaching 26 OTPS and 1053 ms TTFT on the Sonnet dataset (a poetry-based benchmark) with enter size of 1600, output size of 600 and concurrency of 16. To breed these outcomes, try our PR within the launch 0.11.1.rc3 from the vLLM GitHub repository. In the remainder of this weblog, we are going to present how we optimized the efficiency from these baseline enablement numbers.
Bettering multi-LoRA inference efficiency in vLLM
After finalizing our preliminary implementation, we used NVIDIA Nsight Methods (Nsys) to establish bottlenecks and located the fused_moe_lora kernel to be the highest-latency element. We then used NVIDIA Nsight Compute (NCU) to profile compute and reminiscence throughput for the 4 kernel operations: gate_up_shrink, gate_up_expand, down_shrink, and down_expand. These findings led us to develop execution optimizations, kernel-level optimizations, and tuned configurations for these 4 kernels.
Execution optimizations
With our preliminary implementation, the multi-LoRA TTFT was 10x larger (worse) than the bottom mannequin TTFT (i.e., the general public launch model of GPT-OSS 20B). Our profiling revealed that the Triton compiler handled input-length-dependent variables as compile-time constants, inflicting the fused_moe_lora kernel to be recompiled from scratch for each new context size as an alternative of being reused. That is seen in Determine 2: the cuModuleLoadData calls earlier than every fused_moe_lora kernel execution point out that the GPU is loading a newly compiled kernel binary somewhat than reusing a cached one, and the big gaps between kernel begin instances present the GPU sitting idle throughout recompilation. This overhead drove the ten× TTFT regression over the bottom mannequin. We resolved this by including a do_not_specialize compiler trace for these variables, instructing Triton to compile the kernel as soon as and reuse it throughout all context lengths.
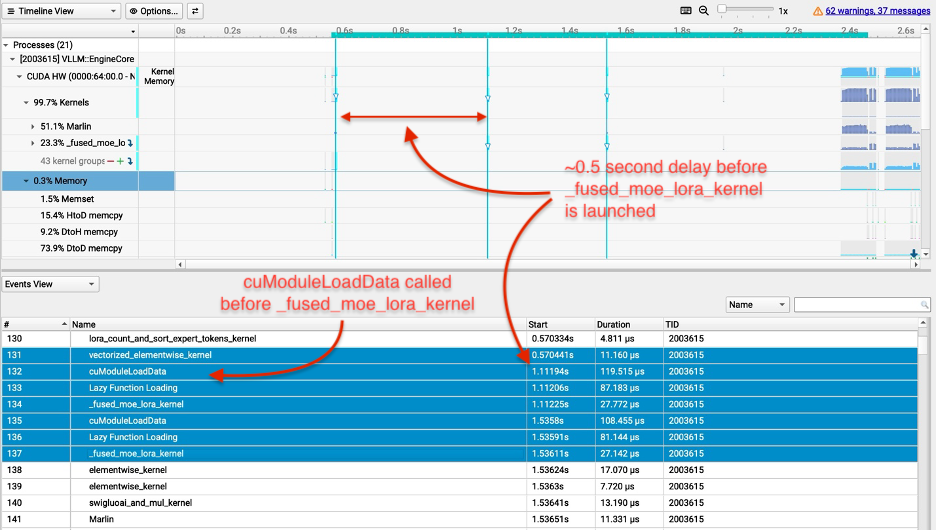
Determine 2: Profiling outcomes for fused_moe_lora kernel earlier than our execution optimizations.
Profiling additionally revealed that our fused_moe_lora kernel launched with the identical excessive overhead no matter whether or not the request used the bottom mannequin solely, attention-only adapters (LoRA adapters with weights solely on the eye layers), or full LoRA adapters (adapters with weights on each consideration and MoE layers). To assist resolve this, we added early exit logic to skip the fused_moe_lora kernel on layers with out LoRA adapters, serving to forestall pointless kernel execution.
The shrink and increase kernels run serially, which created bubbles between executions of two kernels in our early implementation. To overlap the kernel execution, we carried out Programmatic Dependent Launch (PDL). With PDL, a dependent kernel can start to launch earlier than the first kernel finishes, which lets the increase kernel pre-fetch weights into shared reminiscence and L2 cache whereas the shrink kernel runs. When the shrink kernel completes, the increase kernel has already loaded its weights and may instantly start computation.
We additionally added help for speculative decoding with CudaGraph for LoRA, fixing a problem in vLLM which might seize completely different CudaGraphs for the bottom mannequin and adapter. CudaGraphs are essential for effectivity since they’re used to seize sequences of GPU operations to assist scale back GPU kernel overhead, e.g., kernels as a single unit. Consequently, CudaGraphs can scale back CPU overheads and these kernel launch latencies. With our execution optimizations, OTPS improved to 50/100 with out/with speculative decoding and TTFT improved to 150 ms for GPT-OSS 20B utilizing the default configuration. For the rest of the weblog, we report the numbers with speculative decoding on.
Kernel optimizations
Cut up-Okay is a piece decomposition technique that helps enhance load balancing for skinny matrices. LoRA shrink computes xA the place x has dimension 1×h_in and A has dimension h_in×r. Every of the r output components requires summing h_in multiplications. Customary GEMM kernels assign completely different thread teams — batches of GPU threads that share quick on-chip reminiscence — to completely different output components, however every thread group computes its h_in summation sequentially. With r within the tens and h_in within the hundreds, there are few output components to parallelize throughout whereas every requires an extended sequential summation. Cut up-Okay addresses this by splitting the summation over the internal dimension Okay of a GEMM (on this instance Okay=h_in) throughout a number of thread teams, which compute partial sums in parallel after which mix their outcomes. These partial outcomes require an atomic add to provide the ultimate sum. Since we carry out pure atomic addition with no additional logic, we use the Triton compiler freedom for optimizations by setting the parameter sem="relaxed" for the atomic add operation.
The GPU scheduler assigns a number of thread teams to the identical output factor and runs thread teams for various output components on the similar time. For lora_shrink, every output factor requires studying one column of A, which spans the h_in rows. With h_in within the hundreds, every column touches cache traces unfold throughout a big reminiscence area. Close by columns share the identical rows and overlap in cache, so thread teams engaged on neighboring columns can profit from reusing one another’s loaded information. Cooperative Thread Array (CTA) swizzling reorders the schedule in order that thread teams engaged on close by columns run on the similar time, rising L2 cache reuse. We utilized CTA swizzling to the lora_shrink operation.
We additionally eliminated pointless masking and dot product operations from the shrink and increase LoRA kernels. Triton kernels load information in fixed-size blocks, however matrix dimensions might not divide evenly into these block sizes. For instance, if BLOCK_SIZE_K is 64 however the matrix dimension Okay is 100, the second block would try and learn 28 invalid reminiscence areas. Masking helps forestall these unlawful reminiscence accesses by checking whether or not every index is inside bounds earlier than loading. Nevertheless, these conditional checks execute on each load operation, which provides overhead even when the weather are legitimate. We launched an EVEN_K parameter that checks whether or not Okay divides evenly by BLOCK_SIZE_K. When true, the hundreds are legitimate and masking will be skipped completely, serving to scale back each masking overhead and pointless dot product computations.
Lastly, we fused the addition of the LoRA weights with the bottom mannequin weights into the LoRA increase kernel. This optimization helps scale back the kernel launch overhead. These kernel optimizations helped us attain 144 OTPS and 135 ms TTFT for GPT-OSS 20B.
Tuning kernel configurations for Amazon SageMaker AI and Amazon Bedrock
Triton kernels require tuning of parameters corresponding to block sizes (BLOCK_SIZE_M, BLOCK_SIZE_N, BLOCK_SIZE_K), which management how the matrix computation is split throughout thread teams. Superior parameters embrace GROUP_SIZE_M, which controls thread group ordering for cache locality, and SPLIT_K, which parallelizes summations throughout the internal matrix dimension.
We discovered that the MoE LoRA kernels utilizing default configurations optimized for traditional fused MoE carried out poorly for multi-LoRA serving. These defaults didn’t account for the extra grid dimension akin to the LoRA index and the compound sparsity from a number of adapters. To handle this bottleneck, we added help for customers to load customized tuned configurations by offering a folder path. For extra info, see the vLLM LoRA Tuning documentation. We tuned the 4 fused_moe_lora operations (gate_up shrink, gate_up increase, down shrink, down increase) concurrently since they share the identical BLOCK_SIZE_M parameter. Amazon SageMaker AI and Bedrock clients now have entry to those tuned configurations, that are loaded robotically and obtain 171 OTPS and 124 ms TTFT for GPT-OSS 20B.
Outcomes & Conclusion
By way of our collaboration with the vLLM group, we carried out and open-sourced multi-LoRA serving for MoE fashions together with GPT-OSS, Qwen3 MoE, DeepSeek, and Llama MoE. We then utilized optimizations, e.g, yielding 454% OTPS enhancements and 87% decrease TTFT for GPT-OSS 20B in vLLM 0.15.0 vs vLLM 0.11.1rc3. Some optimizations, significantly kernel tuning and CTA swizzling, additionally improved efficiency for dense fashions, e.g., Qwen3 32B OTPS improved by 99%. To leverage this work in your native deployments, use vLLM 0.15.0 or later. Amazon-specific optimizations, out there in Amazon Bedrock and Amazon SageMaker AI, assist ship extra latency enhancements throughout fashions, e.g., 19% sooner OTPS and eight% higher TTFT vs vLLM 0.15.0 for GPT-OSS 20B. To get began with customized mannequin internet hosting on Amazon, see the Amazon SageMaker AI internet hosting and Amazon Bedrock documentation.
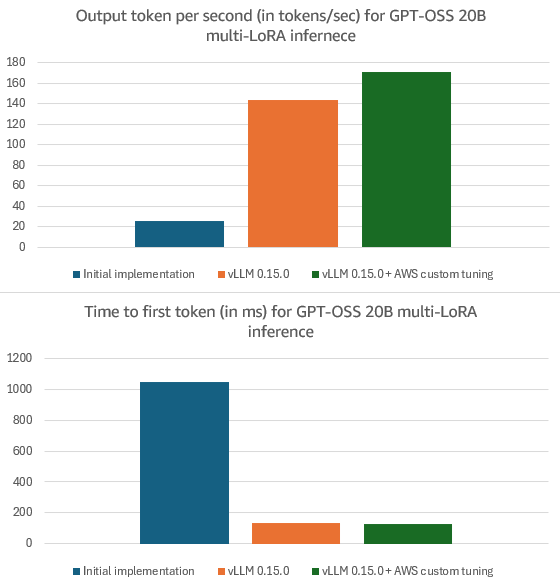
Determine 3: Output tokens per second (OTPS) and time to first token (TTFT) for GPT-OSS 20B multi-LoRA inference: 1/ Preliminary implementation in vLLM 0.11.1rc3; 2/ with vLLM 0.15.0; 3/ with vLLM 0.15.0 and AWS customized kernel tuning. Experiments used 1600 enter tokens and 600 output tokens with LoRA rank 32 and eight adapters loaded in parallel.
Acknowledgments
We wish to acknowledge the contributors and collaborators from the vLLM group: Jee Li, Chen Wu, Varun Sundar Rabindranath, Simon Mo and Robert Shaw, and our crew members: Xin Yang, Sadaf Fardeen, Ashish Khetan, and George Karypis.
In regards to the authors



{kind=link}