Serving to improve your understanding and optimum utilization of structured outputs and LLMs

Within the earlier article, we had been launched to structured outputs utilizing OpenAI. Because the normal availability launch in ChatCompletions API (v1.40.0), structured outputs have been utilized throughout dozens of use circumstances, and spawned quite a few threads on OpenAI boards.
On this article, our goal is to give you a fair deeper understanding, dispel some misconceptions, and provide you with some recommendations on tips on how to apply them in probably the most optimum method doable, throughout completely different eventualities.
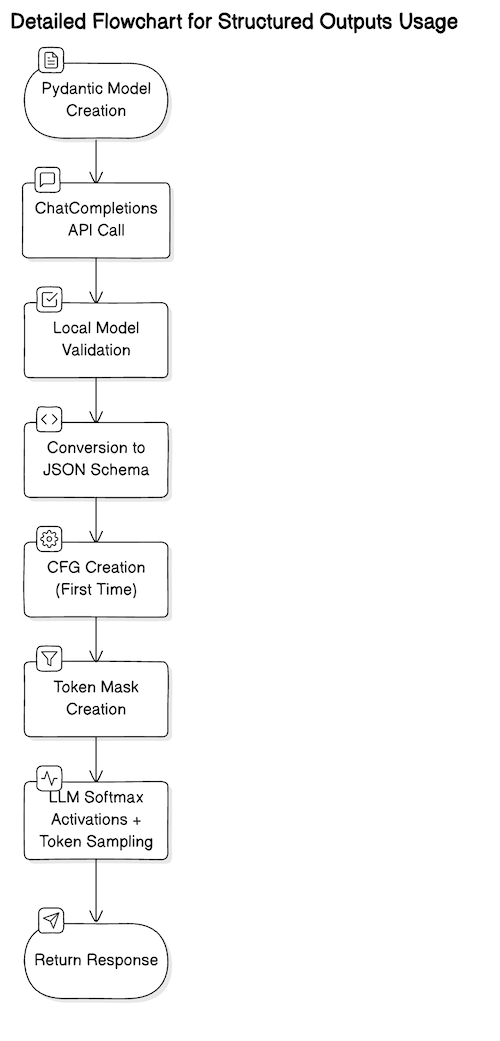
Structured outputs are a method of implementing the output of an LLM to observe a pre-defined schema — often a JSON schema. This works by reworking the schema right into a context free grammar (CFG), which throughout the token sampling step, is used along with the beforehand generated tokens, to tell which subsequent tokens are legitimate. It’s useful to think about it as making a regex for token technology.
OpenAI API implementation truly tracks a restricted subset of JSON schema options. With extra normal structured output options, equivalent to Outlines, it’s doable to make use of a considerably bigger subset of the JSON schema, and even outline fully customized non-JSON schemas — so long as one has entry to an open weight mannequin. For the aim of this text, we are going to assume the OpenAI API implementation.
In keeping with JSON Schema Core Specification, “JSON Schema asserts what a JSON doc should appear to be, methods to extract data from it, and tips on how to work together with it”. JSON schema defines six primitive sorts — null, boolean, object, array, quantity and string. It additionally defines sure key phrases, annotations, and particular behaviours. For instance, we are able to specify in our schema that we count on an array and add an annotation that minItems shall be 5 .
Pydantic is a Python library that implements the JSON schema specification. We use Pydantic to construct strong and maintainable software program in Python. Since Python is a dynamically typed language, knowledge scientists don’t essentially assume when it comes to variable sorts — these are sometimes implied of their code. For instance, a fruit could be specified as:
fruit = dict(
title="apple",
colour="pink",
weight=4.2
)
…whereas a operate declaration that returns “fruit” from some piece of knowledge would usually be specified as:
def extract_fruit(s):
...
return fruit
Pydantic however permits us to generate a JSON-schema compliant class, with correctly annotated variables and kind hints, making our code extra readable/maintainable and basically extra strong, i.e.
class Fruit(BaseModel):
title: str
colour: Literal['red', 'green']
weight: Annotated[float, Gt(0)]def extract_fruit(s: str) -> Fruit:
...
return fruit
OpenAI truly strongly recommends the usage of Pydantic for specifying schemas, versus specifying the “uncooked” JSON schema instantly. There are a number of causes for this. Firstly, Pydantic is assured to stick to the JSON schema specification, so it saves you further pre-validation steps. Secondly, for bigger schemas, it’s much less verbose, permitting you to write down cleaner code, quicker. Lastly, the openai Python bundle truly does some housekeeping, like setting additionalProperties to False for you, whereas when defining your schema “by-hand” utilizing JSON, you would want to set these manually, for each object in your schema (failing to take action ends in a fairly annoying API error).
As we alluded to beforehand, the ChatCompletions API offers a restricted subset of the total JSON schema specification. There are quite a few key phrases that aren’t but supported, equivalent to minimal and most for numbers, and minItems and maxItems for arrays — annotations that might be in any other case very helpful in lowering hallucinations, or constraining the output measurement.
Sure formatting options are additionally unavailable. For instance, the next Pydantic schema would lead to API error when handed to response_format in ChatCompletions:
class NewsArticle(BaseModel):
headline: str
subheading: str
authors: Listing[str]
date_published: datetime = Discipline(None, description="Date when article was printed. Use ISO 8601 date format.")
It will fail as a result of openai bundle has no format dealing with for datetime , so as a substitute you would want to set date_published as a str and carry out format validation (e.g. ISO 8601 compliance) post-hoc.
Different key limitations embody the next:
- Hallucinations are nonetheless doable — for instance, when extracting product IDs, you’d outline in your response schema the next:
product_ids: Listing[str]; whereas the output is assured to provide a listing of strings (product IDs), the strings themselves could also be hallucinated, so on this use case, you might wish to validate the output in opposition to some pre-defined set of product IDs. - The output is capped at
4096tokens, or the lesser quantity you set inside themax_tokensparameter — so despite the fact that the schema can be adopted exactly, if the output is just too giant, it is going to be truncated and produce an invalid JSON — particularly annoying on very giant Batch API jobs! - Deeply nested schemas with many object properties could yield API errors — there’s a limitation on the depth and breadth of your schema, however basically it’s best to stay to flat and easy buildings— not simply to keep away from API errors but in addition to squeeze out as a lot efficiency from the LLMs as doable (LLMs basically have bother attending to deeply nested buildings).
- Extremely dynamic or arbitrary schemas aren’t doable — despite the fact that recursion is supported, it isn’t doable to create a extremely dynamic schema of let’s say, a listing of arbitrary key-value objects, i.e.
[{"key1": "val1"}, {"key2": "val2"}, ..., {"keyN": "valN"}], because the “keys” on this case should be pre-defined; in such a situation, the most suitable choice is to not use structured outputs in any respect, however as a substitute go for commonplace JSON mode, and supply the directions on the output construction inside the system immediate.
With all this in thoughts, we are able to now undergo a few use circumstances with suggestions and methods on tips on how to improve the efficiency when utilizing structured outputs.
Creating flexibility utilizing non-obligatory parameters
Let’s say we’re constructing an internet scraping utility the place our aim is to gather particular elements from the online pages. For every internet web page, we provide the uncooked HTML within the person immediate, give particular scraping directions within the system immediate, and outline the next Pydantic mannequin:
class Webpage(BaseModel):
title: str
paragraphs: Non-obligatory[List[str]] = Discipline(None, description="Textual content contents enclosed inside tags.")
hyperlinks: Non-obligatory[List[str]] = Discipline(None, description="URLs specified by `href` subject inside tags.")
photos: Non-obligatory[List[str]] = Discipline(None, description="URLs specified by the `src` subject inside the ![]() tags.")
tags.")
We’d then name the API as follows…
response = shopper.beta.chat.completions.parse(
mannequin="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": "You are to parse HTML and return the parsed page components."
},
{
"role": "user",
"content": """
Structured Outputs Demo

Hello world!
"""
}
],
response_format=Webpage
)
…with the next response:
{
'photos': ['test.gif'],
'hyperlinks': None,
'paragraphs': ['Hello world!'],
'title': 'Structured Outputs Demo'
}
Response schema equipped to the API utilizing structured outputs should return all the required fields. Nevertheless, we are able to “emulate” non-obligatory fields and add extra flexibility utilizing the Non-obligatory kind annotation. We might truly additionally use Union[List[str], None] — they’re syntactically precisely the identical. In each circumstances, we get a conversion to anyOf key phrase as per the JSON schema spec. Within the instance above, since there aren’t any tags current on the internet web page, the API nonetheless returns the hyperlinks subject, however it’s set to None .
Decreasing hallucinations utilizing enums
We talked about beforehand that even when the LLM is assured to observe the offered response schema, it might nonetheless hallucinate the precise values. Including to this, a current paper discovered that implementing a hard and fast schema on the outputs, truly causes the LLM to hallucinate, or degrade when it comes to its reasoning capabilities.
One method to overcome these limitations, is to try to make the most of enums as a lot as doable. Enums constrain the output to a really particular set of tokens, putting a likelihood of zero on the whole lot else. For instance, let’s assume you are attempting to re-rank product similarity outcomes between a goal product that comprises a description and a singular product_id , and top-5 merchandise that had been obtained utilizing some vector similarity search (e.g. utilizing a cosine distance metric). Every a kind of top-5 merchandise additionally include the corresponding textual description and a singular ID. In your response you merely want to acquire the re-ranking 1–5 as a listing (e.g. [1, 4, 3, 5, 2] ), as a substitute of getting a listing of re-ranked product ID strings, which can be hallucinated or invalid. We setup our Pydantic mannequin as follows…
class Rank(IntEnum):
RANK_1 = 1
RANK_2 = 2
RANK_3 = 3
RANK_4 = 4
RANK_5 = 5class RerankingResult(BaseModel):
ordered_ranking: Listing[Rank] = Discipline(description="Supplies ordered rating 1-5.")
…and run the API like so:
response = shopper.beta.chat.completions.parse(
mannequin="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": """
You are to rank the similarity of the candidate products against the target product.
Ranking should be orderly, from the most similar, to the least similar.
"""
},
{
"role": "user",
"content": """
## Target Product
Product ID: X56HHGHH
Product Description: 80" Samsung LED TV## Candidate Products
Product ID: 125GHJJJGH
Product Description: NVIDIA RTX 4060 GPU
Product ID: 76876876GHJ
Product Description: Sony Walkman
Product ID: 433FGHHGG
Product Description: Sony LED TV 56"
Product ID: 777888887888
Product Description: Blueray Sony Player
Product ID: JGHHJGJ56
Product Description: BenQ PC Monitor 37" 4K UHD
"""
}
],
response_format=RerankingResult
)
The ultimate result’s merely:
{'ordered_ranking': [3, 5, 1, 4, 2]}
So the LLM ranked the Sony LED TV (i.e. merchandise quantity “3” within the checklist), and the BenQ PC Monitor (i.e. merchandise quantity “5”), as the 2 most related product candidates, i.e. the primary two parts of the ordered_ranking checklist!
On this article we gave a radical deep-dive into structured outputs. We launched the JSON schema and Pydantic fashions, and related these to OpenAI’s ChatCompletions API. We walked via a variety of examples and showcased some optimum methods of resolving these utilizing structured outputs. To summarize some key takeaways:
- Structured outputs as supported by OpenAI API, and different third get together frameworks, implement solely a subset of the JSON schema specification — getting higher knowledgeable when it comes to its options and limitations will show you how to make the suitable design selections.
- Utilizing Pydantic or related frameworks that monitor JSON schema specification faithfully, is very really useful, because it means that you can create legitimate and cleaner code.
- While hallucinations are nonetheless anticipated, there are other ways of mitigating these, just by a selection of response schema design; for instance, by using enums the place acceptable.
In regards to the Creator
Armin Catovic is a Secretary of the Board at Stockholm AI, and a Vice President and a Senior ML/AI Engineer on the EQT Group, with 18 years of engineering expertise throughout Australia, South-East Asia, Europe and the US, and a variety of patents and top-tier peer-reviewed AI publications.


{kind=link}