Generative AI and huge language fashions (LLMs) are revolutionizing organizations throughout numerous sectors to reinforce buyer expertise, which historically would take years to make progress. Each group has information saved in information shops, both on premises or in cloud suppliers.
You may embrace generative AI and improve buyer expertise by changing your current information into an index on which generative AI can search. If you ask a query to an open supply LLM, you get publicly accessible data as a response. Though that is useful, generative AI might help you perceive your information together with extra context from LLMs. That is achieved via Retrieval Augmented Technology (RAG).
RAG retrieves information from a preexisting data base (your information), combines it with the LLM’s data, and generates responses with extra human-like language. Nonetheless, to ensure that generative AI to grasp your information, some quantity of information preparation is required, which includes a giant studying curve.
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database constructed for the cloud. Aurora combines the efficiency and availability of conventional enterprise databases with the simplicity and cost-effectiveness of open supply databases.
On this submit, we stroll you thru how you can convert your current Aurora information into an index with no need information preparation for Amazon Kendra to carry out information search and implement RAG that mixes your information together with LLM data to supply correct responses.
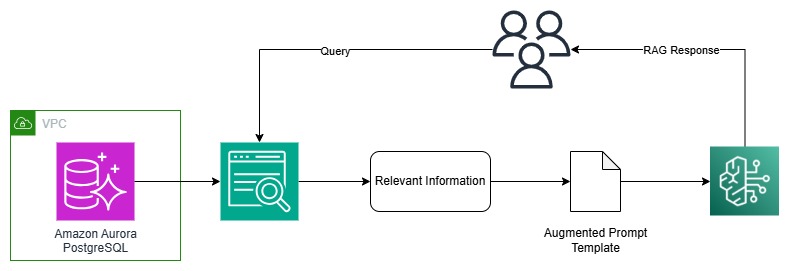
Answer overview
On this answer, use your current information as an information supply (Aurora), create an clever search service by connecting and syncing your information supply to Amazon Kendra search, and carry out generative AI information search, which makes use of RAG to supply correct responses by combining your information together with the LLM’s data. For this submit, we use Anthropic’s Claude on Amazon Bedrock as our LLM.
The next are the high-level steps for the answer:
The next diagram illustrates the answer structure.

Conditions
To observe this submit, the next stipulations are required:
Create an Aurora PostgreSQL cluster
Run the next AWS CLI instructions to create an Aurora PostgreSQL Serverless v2 cluster:
The next screenshot exhibits the created occasion.

Ingest information to Aurora PostgreSQL-Suitable
Hook up with the Aurora occasion utilizing the pgAdmin device. Seek advice from Connecting to a DB occasion operating the PostgreSQL database engine for extra data. To ingest your information, full the next steps:
- Run the next PostgreSQL statements in pgAdmin to create the database, schema, and desk:
- In your pgAdmin Aurora PostgreSQL connection, navigate to Databases, genai, Schemas, staff, Tables.
- Select (right-click) Tables and select PSQL Instrument to open a PSQL shopper connection.

- Place the csv file beneath your pgAdmin location and run the next command:

- Run the next PSQL question to confirm the variety of information copied:



Create an Amazon Kendra index
The Amazon Kendra index holds the contents of your paperwork and is structured in a option to make the paperwork searchable. It has three index sorts:
- Generative AI Enterprise Version index – Gives the very best accuracy for the Retrieve API operation and for RAG use instances (really helpful)
- Enterprise Version index – Offers semantic search capabilities and provides a high-availability service that’s appropriate for manufacturing workloads
- Developer Version index – Offers semantic search capabilities so that you can check your use instances
To create an Amazon Kendra index, full the next steps:
- On the Amazon Kendra console, select Indexes within the navigation pane.
- Select Create an index.
- On the Specify index particulars web page, present the next data:
- For Index identify, enter a reputation (for instance,
genai-kendra-index). - For IAM position, select Create a brand new position (Beneficial).
- For Position identify, enter an IAM position identify (for instance,
genai-kendra). Your position identify might be prefixed withAmazonKendra-(for instance,- AmazonKendra-us-east-2-genai-kendra).
- For Index identify, enter a reputation (for instance,
- Select Subsequent.

- On the Add extra capability web page, choose Developer version (for this demo) and select Subsequent.

- On the Configure person entry management web page, present the next data:
- Below Entry management settings¸ choose No.
- Below Person-group enlargement, choose None.
- Select Subsequent.

- On the Evaluation and create web page, confirm the small print and select Create.

It would take a while for the index to create. Test the checklist of indexes to look at the progress of making your index. When the standing of the index is ACTIVE, your index is able to use.
Arrange the Amazon Kendra Aurora PostgreSQL connector
Full the next steps to arrange your information supply connector:
- On the Amazon Kendra console, select Knowledge sources within the navigation pane.
- Select Add information supply.
- Select Aurora PostgreSQL connector as the information supply kind.

- On the Specify information supply particulars web page, present the next data:
- For Knowledge supply identify, enter a reputation (for instance,
data_source_genai_kendra_postgresql). - For Default language¸ select English (en).
- Select Subsequent.

- For Knowledge supply identify, enter a reputation (for instance,
- On the Outline entry and safety web page, beneath Supply, present the next data:
- For Host, enter the host identify of the PostgreSQL occasion (
cvgupdj47zsh.us-east-2.rds.amazonaws.com). - For Port, enter the port variety of the PostgreSQL occasion (
5432). - For Occasion, enter the database identify of the PostgreSQL occasion (
genai).
- For Host, enter the host identify of the PostgreSQL occasion (
- Below Authentication, if you have already got credentials saved in AWS Secrets and techniques Supervisor, select it on the dropdown In any other case, select Create and add new secret.
- Within the Create an AWS Secrets and techniques Supervisor secret pop-up window, present the next data:
- For Secret identify, enter a reputation (for instance,
AmazonKendra-Aurora-PostgreSQL-genai-kendra-secret). - For Knowledge base person identify, enter the identify of your database person.
- For Password¸ enter the person password.
- For Secret identify, enter a reputation (for instance,
- Select Add Secret.

- Below Configure VPC and safety group, present the next data:
- For Digital Non-public Cloud, select your digital personal cloud (VPC).
- For Subnet, select your subnet.
- For VPC safety teams, select the VPC safety group to permit entry to your information supply.
- Below IAM position¸ in case you have an current position, select it on the dropdown menu. In any other case, select Create a brand new position.

- On the Configure sync settings web page, beneath Sync scope, present the next data:
- For SQL question, enter the SQL question and column values as follows:
choose * from staff.amazon_review. - For Main key, enter the first key column (
pk). - For Title, enter the title column that gives the identify of the doc title inside your database desk (
reviews_title). - For Physique, enter the physique column on which your Amazon Kendra search will occur (
reviews_text).
- For SQL question, enter the SQL question and column values as follows:
- Below Sync node, choose Full sync to transform your complete desk information right into a searchable index.
After the sync completes efficiently, your Amazon Kendra index will comprise the information from the desired Aurora PostgreSQL desk. You may then use this index for clever search and RAG purposes.
- Below Sync run schedule, select Run on demand.
- Select Subsequent.

- On the Set discipline mappings web page, depart the default settings and select Subsequent.

- Evaluation your settings and select Add information supply.


Your information supply will seem on the Knowledge sources web page after the information supply has been created efficiently.

Invoke the RAG software
The Amazon Kendra index sync can take minutes to hours relying on the amount of your information. When the sync completes with out error, you might be able to develop your RAG answer in your most popular IDE. Full the next steps:
- Configure your AWS credentials to permit Boto3 to work together with AWS companies. You are able to do this by setting the
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYsetting variables or through the use of the~/.aws/credentialsfile: - Import LangChain and the required elements:
- Create an occasion of the LLM (Anthropic’s Claude):
- Create your immediate template, which gives directions for the LLM:
- Initialize the
KendraRetrievertogether with your Amazon Kendra index ID by changing theKendra_index_idthat you just created earlier and the Amazon Kendra shopper: - Mix Anthropic’s Claude and the Amazon Kendra retriever right into a RetrievalQA chain:
- Invoke the chain with your individual question:

Clear up
To keep away from incurring future prices, delete the sources you created as a part of this submit:
Conclusion
On this submit, we mentioned how you can convert your current Aurora information into an Amazon Kendra index and implement a RAG-based answer for the information search. This answer drastically reduces the information preparation want for Amazon Kendra search. It additionally will increase the velocity of generative AI software growth by lowering the educational curve behind information preparation.
Check out the answer, and in case you have any feedback or questions, depart them within the feedback part.
Concerning the Authors
 Aravind Hariharaputran is a Knowledge Marketing consultant with the Skilled Companies crew at Amazon Net Companies. He’s obsessed with Knowledge and AIML generally with intensive expertise managing Database applied sciences .He helps clients remodel legacy database and purposes to Fashionable information platforms and generative AI purposes. He enjoys spending time with household and enjoying cricket.
Aravind Hariharaputran is a Knowledge Marketing consultant with the Skilled Companies crew at Amazon Net Companies. He’s obsessed with Knowledge and AIML generally with intensive expertise managing Database applied sciences .He helps clients remodel legacy database and purposes to Fashionable information platforms and generative AI purposes. He enjoys spending time with household and enjoying cricket.
 Ivan Cui is a Knowledge Science Lead with AWS Skilled Companies, the place he helps clients construct and deploy options utilizing ML and generative AI on AWS. He has labored with clients throughout numerous industries, together with software program, finance, pharmaceutical, healthcare, IoT, and leisure and media. In his free time, he enjoys studying, spending time together with his household, and touring.
Ivan Cui is a Knowledge Science Lead with AWS Skilled Companies, the place he helps clients construct and deploy options utilizing ML and generative AI on AWS. He has labored with clients throughout numerous industries, together with software program, finance, pharmaceutical, healthcare, IoT, and leisure and media. In his free time, he enjoys studying, spending time together with his household, and touring.



{kind=link}