With the rise of generative AI and information extraction in AI programs, Retrieval Augmented Technology (RAG) has change into a outstanding device for enhancing the accuracy and reliability of AI-generated responses. RAG is as a approach to incorporate extra information that the big language mannequin (LLM) was not skilled on. This will additionally assist cut back era of false or deceptive info (hallucinations). Nevertheless, even with RAG’s capabilities, the problem of AI hallucinations stays a major concern.
As AI programs change into more and more built-in into our every day lives and significant decision-making processes, the flexibility to detect and mitigate hallucinations is paramount. Most hallucination detection methods concentrate on the immediate and the response alone. Nevertheless, the place extra context is obtainable, reminiscent of in RAG-based purposes, new methods could be launched to raised mitigate the hallucination drawback.
This submit walks you thru learn how to create a fundamental hallucination detection system for RAG-based purposes. We additionally weigh the professionals and cons of various strategies when it comes to accuracy, precision, recall, and price.
Though there are at present many new state-of-the-art methods, the approaches outlined on this submit intention to supply easy, user-friendly methods which you could rapidly incorporate into your RAG pipeline to extend the standard of the outputs in your RAG system.
Answer overview
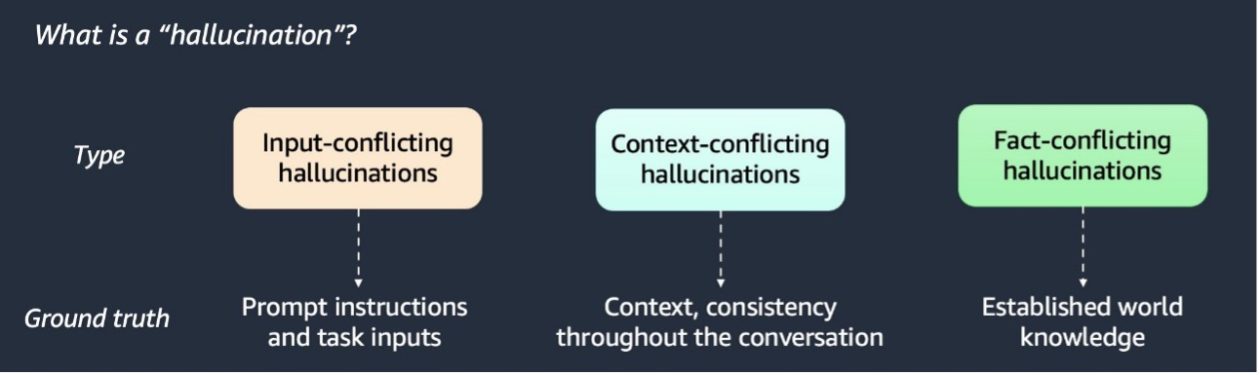
Hallucinations could be categorized into three varieties, as illustrated within the following graphic.

Scientific literature has give you a number of hallucination detection methods. Within the following sections, we talk about and implement 4 outstanding approaches to detecting hallucinations: utilizing an LLM prompt-based detector, semantic similarity detector, BERT stochastic checker, and token similarity detector. Lastly, we evaluate approaches when it comes to their efficiency and latency.
Stipulations
To make use of the strategies offered on this submit, you want an AWS account with entry to Amazon SageMaker, Amazon Bedrock, and Amazon Easy Storage Service (Amazon S3).
Out of your RAG system, you’ll need to retailer three issues:
- Context – The realm of textual content that’s related to a consumer’s question
- Query – The consumer’s question
- Reply – The reply offered by the LLM
The ensuing desk ought to look just like the next instance.
| query | context | reply |
| What are cocktails? | Cocktails are alcoholic blended… | Cocktails are alcoholic blended… |
| What are cocktails? | Cocktails are alcoholic blended… | They’ve distinct histories… |
| What’s Fortnite? | Fortnite is a well-liked video… | Fortnite is a web-based multi… |
| What’s Fortnite? | Fortnite is a well-liked video… | The typical Fortnite participant spends… |
Method 1: LLM-based hallucination detection
We are able to use an LLM to categorise the responses from our RAG system into context-conflicting hallucinations and information. The intention is to determine which responses are based mostly on the context or whether or not they include hallucinations.
This method consists of the next steps:
- Create a dataset with questions, context, and the response you wish to classify.
- Ship a name to the LLM with the next info:
- Present the assertion (the reply from the LLM that we wish to classify).
- Present the context from which the LLM created the reply.
- Instruct the LLM to tag sentences within the assertion which can be instantly based mostly on the context.
- Parse the outputs and procure sentence-level numeric scores between 0–1.
- Be sure to maintain the LLM, reminiscence, and parameters unbiased from those used for Q&A. (That is so the LLM can’t entry the earlier chat historical past to attract conclusions.)
- Tune the choice threshold for the hallucination scores for a particular dataset based mostly on area, for instance.
- Use the edge to categorise the assertion as hallucination or truth.
Create a immediate template
To make use of the LLM to categorise the reply to your query, it’s essential arrange a immediate. We wish the LLM to soak up the context and the reply, and decide from the given context a hallucination rating. The rating shall be encoded between 0 and 1, with 0 being a solution instantly from the context and 1 being a solution with no foundation from the context.
The next is a immediate with few-shot examples so the LLM is aware of what the anticipated format and content material of the reply ought to be:
immediate = """nnHuman: You might be an knowledgeable assistant serving to human to examine if statements are based mostly on the context.
Your job is to learn context and assertion and point out which sentences within the assertion are based mostly instantly on the context.
Present response as a quantity, the place the quantity represents a hallucination rating, which is a float between 0 and 1.
Set the float to 0 if you're assured that the sentence is instantly based mostly on the context.
Set the float to 1 if you're assured that the sentence shouldn't be based mostly on the context.
If you're not assured, set the rating to a float quantity between 0 and 1. Greater numbers characterize larger confidence that the sentence shouldn't be based mostly on the context.
Don't embody some other info apart from the the rating within the response. There isn't a want to elucidate your considering.
Context: Amazon Net Companies, Inc. (AWS) is a subsidiary of Amazon that gives on-demand cloud computing platforms and APIs to people, firms, and governments, on a metered, pay-as-you-go foundation. Purchasers will typically use this together with autoscaling (a course of that permits a consumer to make use of extra computing in occasions of excessive utility utilization, after which scale down to scale back prices when there's much less site visitors). These cloud computing net companies present varied companies associated to networking, compute, storage, middleware, IoT and different processing capability, in addition to software program instruments through AWS server farms. This frees shoppers from managing, scaling, and patching {hardware} and working programs. One of many foundational companies is Amazon Elastic Compute Cloud (EC2), which permits customers to have at their disposal a digital cluster of computer systems, with extraordinarily excessive availability, which could be interacted with over the web through REST APIs, a CLI or the AWS console. AWS's digital computer systems emulate a lot of the attributes of an actual pc, together with {hardware} central processing items (CPUs) and graphics processing items (GPUs) for processing; native/RAM reminiscence; hard-disk/SSD storage; a alternative of working programs; networking; and pre-loaded utility software program reminiscent of net servers, databases, and buyer relationship administration (CRM).
Assertion: 'AWS is Amazon subsidiary that gives cloud computing companies.'
Assistant: 0.05
Context: Amazon Net Companies, Inc. (AWS) is a subsidiary of Amazon that gives on-demand cloud computing platforms and APIs to people, firms, and governments, on a metered, pay-as-you-go foundation. Purchasers will typically use this together with autoscaling (a course of that permits a consumer to make use of extra computing in occasions of excessive utility utilization, after which scale down to scale back prices when there's much less site visitors). These cloud computing net companies present varied companies associated to networking, compute, storage, middleware, IoT and different processing capability, in addition to software program instruments through AWS server farms. This frees shoppers from managing, scaling, and patching {hardware} and working programs. One of many foundational companies is Amazon Elastic Compute Cloud (EC2), which permits customers to have at their disposal a digital cluster of computer systems, with extraordinarily excessive availability, which could be interacted with over the web through REST APIs, a CLI or the AWS console. AWS's digital computer systems emulate a lot of the attributes of an actual pc, together with {hardware} central processing items (CPUs) and graphics processing items (GPUs) for processing; native/RAM reminiscence; hard-disk/SSD storage; a alternative of working programs; networking; and pre-loaded utility software program reminiscent of net servers, databases, and buyer relationship administration (CRM).
Assertion: 'AWS income in 2022 was $80 billion.'
Assistant: 1
Context: Monkey is a standard identify that will consult with most mammals of the infraorder Simiiformes, also referred to as the simians. Historically, all animals within the group now often known as simians are counted as monkeys besides the apes, which constitutes an incomplete paraphyletic grouping; nevertheless, within the broader sense based mostly on cladistics, apes (Hominoidea) are additionally included, making the phrases monkeys and simians synonyms in regard to their scope. On common, monkeys are 150 cm tall.
Assertion:'Common monkey is 2 meters excessive and weights 100 kilograms.'
Assistant: 0.9
Context: {context}
Assertion: {assertion}
nnAssistant: [
"""
### LANGCHAIN CONSTRUCTS
# prompt template
prompt_template = PromptTemplate(
template=prompt,
input_variables=["context", "statement"],
)Configure the LLM
To retrieve a response from the LLM, it’s essential configure the LLM utilizing Amazon Bedrock, just like the next code:
def configure_llm() -> Bedrock:
model_params= { "answer_length": 100, # max variety of tokens within the reply
"temperature": 0.0, # temperature throughout inference
"top_p": 1, # cumulative likelihood of sampled tokens
"stop_words": [ "nnHuman:", "]", ], # phrases after which the era is stopped
}
bedrock_client = boto3.consumer(
service_name="bedrock-runtime",
region_name="us-east-1",
)
MODEL_ID = "anthropic.claude-3-5-sonnet-20240620-v1:0"
llm = Bedrock(
consumer=bedrock_client,
model_id=MODEL_ID,
model_kwargs=model_params,
)
return llm Get hallucination classifications from the LLM
The subsequent step is to make use of the immediate, dataset, and LLM to get hallucination scores for every response out of your RAG system. Taking this a step additional, you need to use a threshold to find out whether or not the response is a hallucination or not. See the next code:
def get_response_from_claude(context: str, reply: str, prompt_template: PromptTemplate, llm: Bedrock) -> float:
llm_chain = LLMChain(llm=llm, immediate=prompt_template, verbose=False)
# compute scores
response = llm_chain(
{"context": context, "assertion": str(reply)}
)
strive:
scores = float(scores)
besides Exception:
print(f"Couldn't parse LLM response: {scores}")
scores = 0
return scoresMethod 2: Semantic similarity-based detection
Beneath the belief that if an announcement is a truth, then there shall be excessive similarity with the context, you need to use semantic similarity as a way to find out whether or not an announcement is an input-conflicting hallucination.
This method consists of the next steps:
- Create embeddings for the reply and the context utilizing an LLM. (On this instance, we use the Amazon Titan Embeddings mannequin.)
- Use the embeddings to calculate similarity scores between every sentence within the reply and the (On this case, we use cosine similarity as a distance metric.) Out-of-context (hallucinated sentences) ought to have low similarity with the context.
- Tune the choice threshold for a particular dataset (reminiscent of area dependent) to categorise hallucinating statements.
Create embeddings with LLMs and calculate similarity
You should use LLMs to create embeddings for the context and the preliminary response to the query. After you’ve the embeddings, you may calculate the cosine similarity of the 2. The cosine similarity rating will return a quantity between 0 and 1, with 1 being good similarity and 0 as no similarity. To translate this to a hallucination rating, we have to take 1—the cosine similarity. See the next code:
def similarity_detector(
context: str,
reply: str,
llm: BedrockEmbeddings,
) -> float:
"""
Verify hallucinations utilizing semantic similarity strategies based mostly on embeddings
Parameters
----------
context : str
Context offered for RAG
reply : str
Reply from an LLM
llm : BedrockEmbeddings
Embeddings mannequin
Returns
-------
float
Semantic similarity rating
"""
if len(context) == 0 or len(reply) == 0:
return 0.0
# calculate embeddings
context_emb = llm.embed_query(context)
answer_emb = llm.embed_query(reply)
context_emb = np.array(context_emb).reshape(1, -1)
answer_emb = np.array(answer_emb).reshape(1, -1)
sim_score = cosine_similarity(context_emb, answer_emb)
return 1 - sim_score[0][0]Method 3: BERT stochastic checker
The BERT rating makes use of the pre-trained contextual embeddings from a pre-trained language mannequin reminiscent of BERT and matches phrases in candidate and reference sentences by cosine similarity. One of many conventional metrics for analysis in pure language processing (NLP) is the BLEU rating. The BLEU rating primarily measures precision by calculating what number of n-grams (consecutive tokens) from the candidate sentence seem within the reference sentences. It focuses on matching these consecutive token sequences between candidate and reference sentences, whereas incorporating a brevity penalty to stop overly brief translations from receiving artificially excessive scores. Not like the BLEU rating, which focuses on token-level comparisons, the BERT rating makes use of contextual embeddings to seize semantic similarities between phrases or full sentences. It has been proven to correlate with human judgment on sentence-level and system-level analysis. Furthermore, the BERT rating computes precision, recall, and F1 measure, which could be helpful for evaluating totally different language era duties.
In our method, we use the BERT rating as a stochastic checker for hallucination detection. The concept is that should you generate a number of solutions from an LLM and there are massive variations (inconsistencies) between them, then there’s a good likelihood that these solutions are hallucinated. We first generate N random samples (sentences) from the LLM. We then compute BERT scores by evaluating every sentence within the unique generated paragraph towards its corresponding sentence throughout the N newly generated stochastic samples. That is completed by embedding all sentences utilizing an LLM based mostly embedding mannequin and calculating cosine similarity. Our speculation is that factual sentences will stay constant throughout a number of generations, leading to excessive BERT scores (indicating similarity). Conversely, hallucinated content material will seemingly range throughout totally different generations, leading to low BERT scores between the unique sentence and its stochastic variants. By establishing a threshold for these similarity scores, we are able to flag sentences with constantly low BERT scores as potential hallucinations, as a result of they display semantic inconsistency throughout a number of generations from the identical mannequin.
Method 4: Token similarity detection
With the token similarity detector, we extract distinctive units of tokens from the reply and the context. Right here, we are able to use one of many LLM tokenizers or just break up the textual content into particular person phrases. Then, we calculate similarity between every sentence within the reply and the context. There are a number of metrics that can be utilized for token similarity, together with a BLEU rating over totally different n-grams, a ROUGE rating (an NLP metric just like BLEU however calculates recall vs. precision) over totally different n-grams, or just the proportion of the shared tokens between the 2 texts. Out-of-context (hallucinated) sentences ought to have low similarity with the context.
def intersection_detector(
context: str,
reply: str,
length_cutoff: int = 3,
) -> dict[str, float]:
"""
Verify hallucinations utilizing token intersection metrics
Parameters
----------
context : str
Context offered for RAG
reply : str
Reply from an LLM
length_cutoff : int
If no. tokens within the reply is smaller than length_cutoff, return scores of 1.0
Returns
-------
dict[str, float]
Token intersection and BLEU scores
"""
# populate with related stopwords reminiscent of articles
stopword_set = {}
# take away punctuation and lowercase
context = re.sub(r"[^ws]", "", context).decrease()
reply = re.sub(r"[^ws]", "", reply).decrease()
# calculate metrics
if len(reply) >= length_cutoff:
# calculate token intersection
context_split = {time period for time period in context if time period not in stopword_set}
answer_split = re.compile(r"w+").findall(reply)
answer_split = {time period for time period in answer_split if time period not in stopword_set}
intersection = sum([term in context_split for term in answer_split]) / len(answer_split)
# calculate BLEU rating
bleu = consider.load("bleu")
bleu_score = bleu.compute(predictions=[answer], references=[context])["precisions"]
bleu_score = sum(bleu_score) / len(bleu_score)
return {
"intersection": 1 - intersection,
"bleu": 1 - bleu_score,
}
return {"intersection": 0, "bleu": 0}Evaluating approaches: Analysis outcomes
On this part, we evaluate the hallucination detection approaches described within the submit. We run an experiment on three RAG datasets, together with Wikipedia article information and two synthetically generated datasets. Every instance in a dataset features a context, a consumer’s query, and an LLM reply labeled as right or hallucinated. We run every hallucination detection technique on all questions and mixture the accuracy metrics throughout the datasets.
The very best accuracy (variety of sentences appropriately labeled as hallucination vs. truth) is demonstrated by the BERT stochastic checker and the LLM prompt-based detector. The LLM prompt-based detector outperforms the BERT checker in precision, and the BERT stochastic checker has a better recall. The semantic similarity and token similarity detectors present very low accuracy and recall however carry out effectively as regards to precision. This means that these detectors may solely be helpful to determine probably the most evident hallucinations.
Apart from the token similarity detector, the LLM prompt-based detector is probably the most cost-effective choice when it comes to the quantity LLM calls as a result of it’s fixed relative to the scale of the context and the response (however price will range relying on the variety of enter tokens). The semantic similarity detector price is proportional to the variety of sentences within the context and the response, in order the context grows, this could change into more and more costly.
The next desk summarizes the metrics in contrast between every technique. To be used circumstances the place precision is the best precedence, we might suggest the token similarity, LLM prompt-based, and semantic similarity strategies, whereas to supply excessive recall, the BERT stochastic technique outperforms different strategies.
The next desk summarizes the metrics in contrast between every technique.
| Method | Accuracy* | Precision* | Recall* | Price (Variety of LLM Calls) |
Explainability |
| Token Similarity Detector | 0.47 | 0.96 | 0.03 | 0 | Sure |
| Semantic Similarity Detector | 0.48 | 0.90 | 0.02 | Okay*** | Sure |
| LLM Immediate-Primarily based Detector | 0.75 | 0.94 | 0.53 | 1 | Sure |
| BERT Stochastic Checker | 0.76 | 0.72 | 0.90 | N+1** | Sure |
*Averaged over Wikipedia dataset and generative AI artificial datasets
**N = Variety of random samples
***Okay = Variety of sentences
These outcomes counsel that an LLM-based detector reveals trade-off between accuracy and price (extra reply latency). We suggest utilizing a mix of a token similarity detector to filter out probably the most evident hallucinations and an LLM-based detector to determine harder ones.
Conclusion
As RAG programs proceed to evolve and play an more and more essential function in AI purposes, the flexibility to detect and forestall hallucinations stays essential. By our exploration of 4 totally different approaches—LLM prompt-based detection, semantic similarity detection, BERT stochastic checking, and token similarity detection—we’ve demonstrated varied strategies to deal with this problem. Though every method has its strengths and trade-offs when it comes to accuracy, precision, recall, and price, the LLM prompt-based detector reveals significantly promising outcomes with accuracy charges above 75% and a comparatively low extra price. Organizations can select probably the most appropriate technique based mostly on their particular wants, contemplating elements reminiscent of computational sources, accuracy necessities, and price constraints. As the sphere continues to advance, these foundational methods present a place to begin for constructing extra dependable and reliable RAG programs.
Concerning the Authors
 Zainab Afolabi is a Senior Knowledge Scientist on the Generative AI Innovation Centre in London, the place she leverages her intensive experience to develop transformative AI options throughout numerous industries. She has over eight years of specialized expertise in synthetic intelligence and machine studying, in addition to a ardour for translating complicated technical ideas into sensible enterprise purposes.
Zainab Afolabi is a Senior Knowledge Scientist on the Generative AI Innovation Centre in London, the place she leverages her intensive experience to develop transformative AI options throughout numerous industries. She has over eight years of specialized expertise in synthetic intelligence and machine studying, in addition to a ardour for translating complicated technical ideas into sensible enterprise purposes.
 Aiham Taleb, PhD, is a Senior Utilized Scientist on the Generative AI Innovation Heart, working instantly with AWS enterprise clients to leverage Gen AI throughout a number of high-impact use circumstances. Aiham has a PhD in unsupervised illustration studying, and has trade expertise that spans throughout varied machine studying purposes, together with pc imaginative and prescient, pure language processing, and medical imaging.
Aiham Taleb, PhD, is a Senior Utilized Scientist on the Generative AI Innovation Heart, working instantly with AWS enterprise clients to leverage Gen AI throughout a number of high-impact use circumstances. Aiham has a PhD in unsupervised illustration studying, and has trade expertise that spans throughout varied machine studying purposes, together with pc imaginative and prescient, pure language processing, and medical imaging.
 Nikita Kozodoi, PhD, is a Senior Utilized Scientist on the AWS Generative AI Innovation Heart engaged on the frontier of AI analysis and enterprise. Nikita builds generative AI options to unravel real-world enterprise issues for AWS clients throughout industries and holds PhD in Machine Studying.
Nikita Kozodoi, PhD, is a Senior Utilized Scientist on the AWS Generative AI Innovation Heart engaged on the frontier of AI analysis and enterprise. Nikita builds generative AI options to unravel real-world enterprise issues for AWS clients throughout industries and holds PhD in Machine Studying.
 Liza (Elizaveta) Zinovyeva is an Utilized Scientist at AWS Generative AI Innovation Heart and relies in Berlin. She helps clients throughout totally different industries to combine Generative AI into their present purposes and workflows. She is enthusiastic about AI/ML, finance and software program safety subjects. In her spare time, she enjoys spending time together with her household, sports activities, studying new applied sciences, and desk quizzes.
Liza (Elizaveta) Zinovyeva is an Utilized Scientist at AWS Generative AI Innovation Heart and relies in Berlin. She helps clients throughout totally different industries to combine Generative AI into their present purposes and workflows. She is enthusiastic about AI/ML, finance and software program safety subjects. In her spare time, she enjoys spending time together with her household, sports activities, studying new applied sciences, and desk quizzes.


{kind=link}