Trendy giant language fashions (LLMs) excel in language processing however are restricted by their static coaching information. Nonetheless, as industries require extra adaptive, decision-making AI, integrating instruments and exterior APIs has turn into important. This has led to the evolution and speedy rise of agentic workflows, the place AI techniques autonomously plan, execute, and refine duties. Correct instrument use is foundational for enhancing the decision-making and operational effectivity of those autonomous brokers and constructing profitable and sophisticated agentic workflows.
On this put up, we dissect the technical mechanisms of instrument calling utilizing Amazon Nova fashions via Amazon Bedrock, alongside strategies for mannequin customization to refine instrument calling precision.
Increasing LLM capabilities with instrument use
LLMs excel at pure language duties however turn into considerably extra highly effective with instrument integration, corresponding to APIs and computational frameworks. Instruments allow LLMs to entry real-time information, carry out domain-specific computations, and retrieve exact data, enhancing their reliability and flexibility. For instance, integrating a climate API permits for correct, real-time forecasts, or a Wikipedia API supplies up-to-date data for complicated queries. In scientific contexts, instruments like calculators or symbolic engines handle numerical inaccuracies in LLMs. These integrations rework LLMs into strong, domain-aware techniques able to dealing with dynamic, specialised duties with real-world utility.
Amazon Nova fashions and Amazon Bedrock
Amazon Nova fashions, unveiled at AWS re:Invent in December 2024, are optimized to ship distinctive price-performance worth, providing state-of-the-art efficiency on key text-understanding benchmarks at low value. The sequence contains three variants: Micro (text-only, ultra-efficient for edge use), Lite (multimodal, balanced for versatility), and Professional (multimodal, high-performance for complicated duties).
Amazon Nova fashions can be utilized for number of duties, from era to creating agentic workflows. As such, these fashions have the potential to interface with exterior instruments or providers and use them via instrument calling. This may be achieved via the Amazon Bedrock console (see Getting began with Amazon Nova within the Amazon Bedrock console) and APIs corresponding to Converse and Invoke.
Along with utilizing the pre-trained fashions, builders have the choice to fine-tune these fashions with multimodal information (Professional and Lite) or textual content information (Professional, Lite, and Micro), offering the flexibleness to attain desired accuracy, latency, and price. Builders may also run self-service customized fine-tuning and distillation of bigger fashions to smaller ones utilizing the Amazon Bedrock console and APIs.
Answer overview
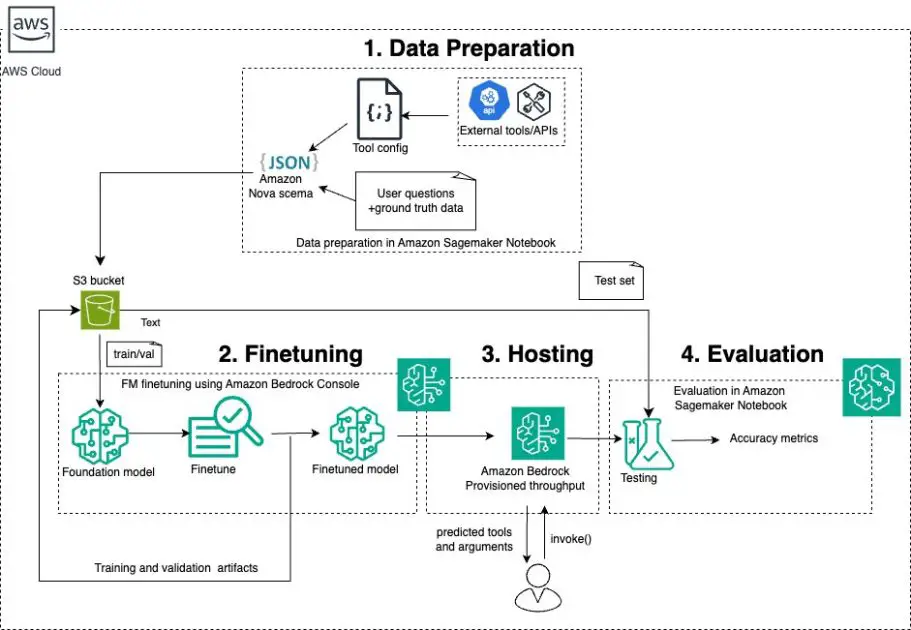
The next diagram illustrates the answer structure.

For this put up, we first ready a customized dataset for instrument utilization. We used the check set to judge Amazon Nova fashions via Amazon Bedrock utilizing the Converse and Invoke APIs. We then fine-tuned Amazon Nova Micro and Amazon Nova Lite fashions via Amazon Bedrock with our fine-tuning dataset. After the fine-tuning course of was full, we evaluated these custom-made fashions via provisioned throughput. Within the following sections, we undergo these steps in additional element.
Instruments
Device utilization in LLMs entails two crucial operations: instrument choice and argument extraction or era. As an illustration, think about a instrument designed to retrieve climate data for a selected location. When introduced with a question corresponding to “What’s the climate in Alexandria, VA?”, the LLM evaluates its repertoire of instruments to find out whether or not an applicable instrument is accessible. Upon figuring out an appropriate instrument, the mannequin selects it and extracts the required arguments—right here, “Alexandria” and “VA” as structured information varieties (for instance, strings)—to assemble the instrument name.
Every instrument is rigorously outlined with a proper specification that outlines its meant performance, the obligatory or non-compulsory arguments, and the related information varieties. Such exact definitions, often known as instrument config, make it possible for instrument calls are executed accurately and that argument parsing aligns with the instrument’s operational necessities. Following this requirement, the dataset used for this instance defines eight instruments with their arguments and configures them in a structured JSON format. We outline the next eight instruments (we use seven of them for fine-tuning and maintain out the weather_api_call instrument throughout testing with a purpose to consider the accuracy on unseen instrument use):
- weather_api_call – Customized instrument for getting climate data
- stat_pull – Customized instrument for figuring out stats
- text_to_sql – Customized text-to-SQL instrument
- terminal – Device for executing scripts in a terminal
- wikipidea – Wikipedia API instrument to look via Wikipedia pages
- duckduckgo_results_json – Web search instrument that executes a DuckDuckGo search
- youtube_search – YouTube API search instrument that searches video listings
- pubmed_search – PubMed search instrument that searches PubMed abstracts
The next code is an instance of what a instrument configuration for terminal may appear like:
Dataset
The dataset is an artificial instrument calling dataset created with help from a basis mannequin (FM) from Amazon Bedrock and manually validated and adjusted. This dataset was created for our set of eight instruments as mentioned within the earlier part, with the purpose of making a various set of questions and gear invocations that permit one other mannequin to study from these examples and generalize to unseen instrument invocations.
Every entry within the dataset is structured as a JSON object with key-value pairs that outline the query (a pure language consumer question for the mannequin), the bottom reality instrument required to reply the consumer question, its arguments (dictionary containing the parameters required to execute the instrument), and extra constraints like order_matters: boolean, indicating if argument order is crucial, and arg_pattern: non-compulsory, an everyday expression (regex) for argument validation or formatting. Later on this put up, we use these floor reality labels to oversee the coaching of pre-trained Amazon Nova fashions, adapting them for instrument use. This course of, often known as supervised fine-tuning, can be explored intimately within the following sections.
The dimensions of the coaching set is 560 questions and the check set is 120 questions. The check set consists of 15 questions per instrument class, totaling 120 questions. The next are some examples from the dataset:
Put together the dataset for Amazon Nova
To make use of this dataset with Amazon Nova fashions, we have to moreover format the info primarily based on a specific chat template. Native instrument calling has a translation layer that codecs the inputs to the suitable format earlier than passing the mannequin. Right here, we make use of a DIY instrument use strategy with a customized immediate template. Particularly, we have to add the system immediate, the consumer message embedded with the instrument config, and the bottom reality labels because the assistant message. The next is a coaching instance formatted for Amazon Nova. Because of area constraints, we solely present the toolspec for one instrument.
Add dataset to Amazon S3
This step is required later for the fine-tuning for Amazon Bedrock to entry the coaching information. You’ll be able to add your dataset both via the Amazon Easy Storage Service (Amazon S3) console or via code.
Device calling with base fashions via the Amazon Bedrock API
Now that we now have created the instrument use dataset and formatted it as required, let’s use it to check out the Amazon Nova fashions. As talked about beforehand, we will use each the Converse and Invoke APIs for instrument use in Amazon Bedrock. The Converse API allows dynamic, context-aware conversations, permitting fashions to interact in multi-turn dialogues, and the Invoke API permits the consumer to name and work together with the underlying fashions inside Amazon Bedrock.
To make use of the Converse API, you merely ship the messages, system immediate (if any), and the instrument config instantly within the Converse API. See the next instance code:
To parse the instrument and arguments from the LLM response, you need to use the next instance code:
For the query: “Hey, what is the temperature in Paris proper now?”, you get the next output:
To execute instrument use via the Invoke API, first you have to put together the request physique with the consumer query in addition to the instrument config that was ready earlier than. The next code snippet exhibits learn how to convert the instrument config JSON to string format, which can be utilized within the message physique:
Utilizing both of the 2 APIs, you possibly can check and benchmark the bottom Amazon Nova fashions with the instrument use dataset. Within the subsequent sections, we present how one can customise these base fashions particularly for the instrument use area.
Supervised fine-tuning utilizing the Amazon Bedrock console
Amazon Bedrock gives three completely different customization methods: supervised fine-tuning, mannequin distillation, and continued pre-training. On the time of writing, the primary two strategies can be found for customizing Amazon Nova fashions. Supervised fine-tuning is a well-liked technique in switch studying, the place a pre-trained mannequin is customized to a selected job or area by coaching it additional on a smaller, task-specific dataset. The method makes use of the representations discovered throughout pre-training on giant datasets to enhance efficiency within the new area. Throughout fine-tuning, the mannequin’s parameters (both all or chosen layers) are up to date utilizing backpropagation to reduce the loss.
On this put up, we use the labeled datasets that we created and formatted beforehand to run supervised fine-tuning to adapt Amazon Nova fashions for the instrument use area.
Create a fine-tuning job
Full the next steps to create a fine-tuning job:
- Open the Amazon Bedrock console.
- Select
us-east-1because the AWS Area. - Below Basis fashions within the navigation pane, select Customized fashions.
- Select Create Fantastic-tuning job underneath Customization strategies.
On the time of writing, Amazon Nova mannequin fine-tuning is completely out there within the us-east-1 Area.

- Select Choose mannequin and select Amazon because the mannequin supplier.
- Select your mannequin (for this put up, Amazon Nova Micro) and select Apply.

- For Fantastic-tuned mannequin identify, enter a novel identify.
- For Job identify¸ enter a reputation for the fine-tuning job.
- Within the Enter information part, enter following particulars:
- For S3 location, enter the supply S3 bucket containing the coaching information.
- For Validation dataset location, optionally enter the S3 bucket containing a validation dataset.

- Within the Hyperparameters part, you possibly can customise the next hyperparameters:
- For Epochs¸ enter a worth between 1–5.
- For Batch measurement, the worth is fastened at 1.
- For Studying charge multiplier, enter a worth between 0.000001–0.0001
- For Studying charge warmup steps, enter a worth between 0–100.
We advocate beginning with the default parameter values after which altering the settings iteratively. It’s a great observe to vary just one or a few parameters at a time, with a purpose to isolate the parameter results. Bear in mind, hyperparameter tuning is mannequin and use case particular.
- Within the Output information part, enter the goal S3 bucket for mannequin outputs and coaching metrics.
- Select Create fine-tuning job.
Run the fine-tuning job
After you begin the fine-tuning job, it is possible for you to to see your job underneath Jobs and the standing as Coaching. When it finishes, the standing modifications to Full.

Now you can go to the coaching job and optionally entry the training-related artifacts which can be saved within the output folder.

You’ll find each coaching and validation (we extremely advocate utilizing a validation set) artifacts right here.

You need to use the coaching and validation artifacts to evaluate your fine-tuning job via loss curves (as proven within the following determine), which monitor coaching loss (orange) and validation loss (blue) over time. A gentle decline in each signifies efficient studying and good generalization. A small hole between them suggests minimal overfitting, whereas a rising validation loss with lowering coaching loss alerts overfitting. If each losses stay excessive, it signifies underfitting. Monitoring these curves helps you rapidly diagnose mannequin efficiency and regulate coaching methods for optimum outcomes.

Host the fine-tuned mannequin and run inference
Now that you’ve got accomplished the fine-tuning, you possibly can host the mannequin and use it for inference. Comply with these steps:
- On the Amazon Bedrock console, underneath Basis fashions within the navigation pane, select Customized fashions
- On the Fashions tab, select the mannequin you fine-tuned.

- Select Buy provisioned throughput.

- Specify a dedication time period (no dedication, 1 month, 6 months) and evaluate the related value for internet hosting the fine-tuned fashions.
After the custom-made mannequin is hosted via provisioned throughput, a mannequin ID can be assigned, which can be used for inference. For inference with fashions hosted with provisioned throughput, we now have to make use of the Invoke API in the identical approach we described beforehand on this put up—merely change the mannequin ID with the custom-made mannequin ID.
The aforementioned fine-tuning and inference steps will also be completed programmatically. Confer with the next GitHub repo for extra element.
Analysis framework
Evaluating fine-tuned instrument calling LLMs requires a complete strategy to evaluate their efficiency throughout varied dimensions. The first metric to judge instrument calling is accuracy, together with each instrument choice and argument era accuracy. This measures how successfully the mannequin selects the right instrument and generates legitimate arguments. Latency and token utilization (enter and output tokens) are two different vital metrics.
Device name accuracy evaluates if the instrument predicted by the LLM matches the bottom reality instrument for every query; a rating of 1 is given in the event that they match and 0 after they don’t. After processing the questions, we will use the next equation: Device Name Accuracy=∑(Appropriate Device Calls)/(Whole variety of check questions).
Argument name accuracy assesses whether or not the arguments supplied to the instruments are right, primarily based on both precise matches or regex sample matching. For every instrument name, the mannequin’s predicted arguments are extracted. It makes use of the next argument matching strategies:
- Regex matching – If the bottom reality contains regex patterns, the expected arguments are matched in opposition to these patterns. A profitable match will increase the rating.
- Inclusive string matching – If no regex sample is supplied, the expected argument is in comparison with the bottom reality argument. Credit score is given if the expected argument incorporates the bottom reality argument. That is to permit for arguments, like search phrases, to not be penalized for including extra specificity.
The rating for every argument is normalized primarily based on the variety of arguments, permitting partial credit score when a number of arguments are required. The cumulative right argument scores are averaged throughout all questions: Argument Name Accuracy = ∑Appropriate Arguments/(Whole Variety of Questions).
Under we present some instance questions and accuracy scores:
Instance 1:
Instance 2:
Outcomes
We at the moment are prepared to visualise the outcomes and examine the efficiency of base Amazon Nova fashions to their fine-tuned counterparts.
Base fashions
The next figures illustrate the efficiency comparability of the bottom Amazon Nova fashions.

The comparability reveals a transparent trade-off between accuracy and latency, formed by mannequin measurement. Amazon Nova Professional, the biggest mannequin, delivers the very best accuracy in each instrument name and argument name duties, reflecting its superior computational capabilities. Nonetheless, this comes with elevated latency.
In distinction, Amazon Nova Micro, the smallest mannequin, achieves the bottom latency, which splendid for quick, resource-constrained environments, although it sacrifices some accuracy in comparison with its bigger counterparts.
Fantastic-tuned fashions vs. base fashions
The next determine visualizes accuracy enchancment after fine-tuning.

The comparative evaluation of the Amazon Nova mannequin variants reveals substantial efficiency enhancements via fine-tuning, with probably the most vital good points noticed within the smaller Amazon Nova Micro mannequin. The fine-tuned Amazon Nova mannequin confirmed outstanding development in instrument name accuracy, rising from 75.8% to 95%, which is a 25.38% enchancment. Equally, its argument name accuracy rose from 77.8% to 87.7%, reflecting a 12.74% enhance.
In distinction, the fine-tuned Amazon Nova Lite mannequin exhibited extra modest good points, with instrument name accuracy enhancing from 90.8% to 96.66%—a 6.46% enhance—and argument name accuracy rising from 85% to 89.9%, marking a 5.76% enchancment. Each fine-tuned fashions surpassed the accuracy achieved by the Amazon Nova Professional base mannequin.
These outcomes spotlight that fine-tuning can considerably improve the efficiency of light-weight fashions, making them robust contenders for purposes the place each accuracy and latency are crucial.
Conclusion
On this put up, we demonstrated mannequin customization (fine-tuning) for instrument use with Amazon Nova. We first launched a instrument utilization use case, and gave particulars in regards to the dataset. We walked via the small print of Amazon Nova particular information formatting and confirmed learn how to do instrument calling via the Converse and Invoke APIs in Amazon Bedrock. After getting the baseline outcomes from Amazon Nova fashions, we defined intimately the fine-tuning course of, internet hosting fine-tuned fashions with provisioned throughput, and utilizing the fine-tuned Amazon Nova fashions for inference. As well as, we touched upon getting insights from coaching and validation artifacts from a fine-tuning job in Amazon Bedrock.
Take a look at the detailed pocket book for instrument utilization to study extra. For extra data on Amazon Bedrock and the newest Amazon Nova fashions, discuss with the Amazon Bedrock Consumer Information and Amazon Nova Consumer Information. The Generative AI Innovation Middle has a gaggle of AWS science and technique consultants with complete experience spanning the generative AI journey, serving to prospects prioritize use circumstances, construct roadmaps, and transfer options into manufacturing. See Generative AI Innovation Middle for our newest work and buyer success tales.
In regards to the Authors
 Baishali Chaudhury is an Utilized Scientist on the Generative AI Innovation Middle at AWS, the place she focuses on advancing Generative AI options for real-world purposes. She has a robust background in pc imaginative and prescient, machine studying, and AI for healthcare. Baishali holds a PhD in Pc Science from College of South Florida and PostDoc from Moffitt Most cancers Centre.
Baishali Chaudhury is an Utilized Scientist on the Generative AI Innovation Middle at AWS, the place she focuses on advancing Generative AI options for real-world purposes. She has a robust background in pc imaginative and prescient, machine studying, and AI for healthcare. Baishali holds a PhD in Pc Science from College of South Florida and PostDoc from Moffitt Most cancers Centre.
 Isaac Privitera is a Principal Knowledge Scientist with the AWS Generative AI Innovation Middle, the place he develops bespoke generative AI-based options to handle prospects’ enterprise issues. His major focus lies in constructing accountable AI techniques, utilizing methods corresponding to RAG, multi-agent techniques, and mannequin fine-tuning. When not immersed on this planet of AI, Isaac could be discovered on the golf course, having fun with a soccer sport, or climbing trails together with his loyal canine companion, Barry.
Isaac Privitera is a Principal Knowledge Scientist with the AWS Generative AI Innovation Middle, the place he develops bespoke generative AI-based options to handle prospects’ enterprise issues. His major focus lies in constructing accountable AI techniques, utilizing methods corresponding to RAG, multi-agent techniques, and mannequin fine-tuning. When not immersed on this planet of AI, Isaac could be discovered on the golf course, having fun with a soccer sport, or climbing trails together with his loyal canine companion, Barry.
 Mengdie (Flora) Wang is a Knowledge Scientist at AWS Generative AI Innovation Middle, the place she works with prospects to architect and implement scalableGenerative AI options that handle their distinctive enterprise challenges. She focuses on mannequin customization methods and agent-based AI techniques, serving to organizations harness the total potential of generative AI expertise. Previous to AWS, Flora earned her Grasp’s diploma in Pc Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence.
Mengdie (Flora) Wang is a Knowledge Scientist at AWS Generative AI Innovation Middle, the place she works with prospects to architect and implement scalableGenerative AI options that handle their distinctive enterprise challenges. She focuses on mannequin customization methods and agent-based AI techniques, serving to organizations harness the total potential of generative AI expertise. Previous to AWS, Flora earned her Grasp’s diploma in Pc Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence.



{kind=link}