With latest advances in giant language fashions (LLMs), a wide selection of companies are constructing new chatbot purposes, both to assist their exterior clients or to assist inner groups. For a lot of of those use circumstances, companies are constructing Retrieval Augmented Technology (RAG) model chat-based assistants, the place a robust LLM can reference company-specific paperwork to reply questions related to a selected enterprise or use case.
In the previous couple of months, there was substantial development within the availability and capabilities of multimodal basis fashions (FMs). These fashions are designed to grasp and generate textual content about photographs, bridging the hole between visible info and pure language. Though such multimodal fashions are broadly helpful for answering questions and deciphering imagery, they’re restricted to solely answering questions based mostly on info from their very own coaching doc dataset.
On this put up, we present tips on how to create a multimodal chat assistant on Amazon Internet Companies (AWS) utilizing Amazon Bedrock fashions, the place customers can submit photographs and questions, and textual content responses shall be sourced from a closed set of proprietary paperwork. Such a multimodal assistant could be helpful throughout industries. For instance, retailers can use this technique to extra successfully promote their merchandise (for instance, HDMI_adaptor.jpeg, “How can I join this adapter to my good TV?”). Tools producers can construct purposes that permit them to work extra successfully (for instance, broken_machinery.png, “What sort of piping do I want to repair this?”). This strategy is broadly efficient in eventualities the place picture inputs are vital to question a proprietary textual content dataset. On this put up, we show this idea on an artificial dataset from a automotive market, the place a person can add an image of a automotive, ask a query, and obtain responses based mostly on the automotive market dataset.
Resolution overview
For our customized multimodal chat assistant, we begin by making a vector database of related textual content paperwork that shall be used to reply person queries. Amazon OpenSearch Service is a robust, extremely versatile search engine that enables customers to retrieve knowledge based mostly on quite a lot of lexical and semantic retrieval approaches. This put up focuses on text-only paperwork, however for embedding extra advanced doc varieties, similar to these with photographs, see Discuss to your slide deck utilizing multimodal basis fashions hosted on Amazon Bedrock and Amazon SageMaker.
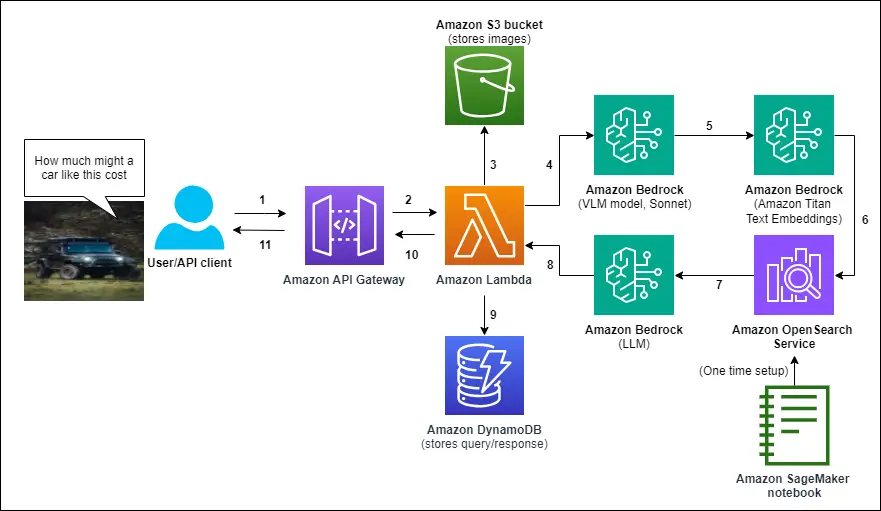
After the paperwork are ingested in OpenSearch Service (it is a one-time setup step), we deploy the complete end-to-end multimodal chat assistant utilizing an AWS CloudFormation template. The next system structure represents the logic circulate when a person uploads a picture, asks a query, and receives a textual content response grounded by the textual content dataset saved in OpenSearch.

The logic circulate for producing a solution to a text-image response pair routes as follows:
- Steps 1 and a couple of – To start out, a person question and corresponding picture are routed via an Amazon API Gateway connection to an AWS Lambda perform, which serves because the processing and orchestrating compute for the general course of.
- Step 3 – The Lambda perform shops the question picture in Amazon S3 with a specified ID. This can be helpful for later chat assistant analytics.
- Steps 4–8 – The Lambda perform orchestrates a collection of Amazon Bedrock calls to a multimodal mannequin, an LLM, and a text-embedding mannequin:
- Question the Claude V3 Sonnet mannequin with the question and picture to supply a textual content description.
- Embed a concatenation of the unique query and the textual content description with the Amazon Titan Textual content Embeddings
- Retrieve related textual content knowledge from OpenSearch Service.
- Generate a grounded response to the unique query based mostly on the retrieved paperwork.
- Step 9 – The Lambda perform shops the person question and reply in Amazon DynamoDB, linked to the Amazon S3 picture ID.
- Steps 10 and 11 – The grounded textual content response is distributed again to the shopper.
There may be additionally an preliminary setup of the OpenSearch Index, which is finished utilizing an Amazon SageMaker pocket book.
Stipulations
To make use of the multimodal chat assistant answer, you want to have a handful of Amazon Bedrock FMs accessible.
- On the Amazon Bedrock console, select Mannequin entry within the navigation pane.
- Select Handle mannequin entry.
- Activate all of the Anthropic fashions, together with Claude 3 Sonnet, in addition to the Amazon Titan Textual content Embeddings V2 mannequin, as proven within the following screenshot.
For this put up, we suggest activating these fashions within the us-east-1 or us-west-2 AWS Area. These ought to develop into instantly lively and accessible.

Easy deployment with AWS CloudFormation
To deploy the answer, we offer a easy shell script referred to as deploy.sh, which can be utilized to deploy the end-to-end answer in several Areas. This script could be acquired immediately from Amazon S3 utilizing aws s3 cp s3://aws-blogs-artifacts-public/artifacts/ML-16363/deploy.sh .
Utilizing the AWS Command Line Interface (AWS CLI), you possibly can deploy this stack in numerous Areas utilizing one of many following instructions:
or
The stack might take as much as 10 minutes to deploy. When the stack is full, word the assigned bodily ID of the Amazon OpenSearch Serverless assortment, which you’ll use in additional steps. It ought to look one thing like zr1b364emavn65x5lki8. Additionally, word the bodily ID of the API Gateway connection, which ought to look one thing like zxpdjtklw2, as proven within the following screenshot.

Populate the OpenSearch Service index
Though the OpenSearch Serverless assortment has been instantiated, you continue to must create and populate a vector index with the doc dataset of automotive listings. To do that, you employ an Amazon SageMaker pocket book.
- On the SageMaker console, navigate to the newly created SageMaker pocket book named MultimodalChatbotNotebook (as proven within the following picture), which can come prepopulated with
car-listings.zipandTitan-OS-Index.ipynb.
- After you open the
Titan-OS-Index.ipynbpocket book, change thehost_idvariable to the gathering bodily ID you famous earlier.
- Run the pocket book from prime to backside to create and populate a vector index with a dataset of 10 automotive listings.
After you run the code to populate the index, it might nonetheless take a couple of minutes earlier than the index reveals up as populated on the OpenSearch Service console, as proven within the following screenshot. 
Check the Lambda perform
Subsequent, check the Lambda perform created by the CloudFormation stack by submitting a check occasion JSON. Within the following JSON, change your bucket with the title of your bucket created to deploy the answer, for instance, multimodal-chatbot-deployment-ACCOUNT_NO-REGION.
You may arrange this check by navigating to the Check panel for the created lambda perform and defining a brand new check occasion with the previous JSON. Then, select Check on the highest proper of the occasion definition.
If you’re querying the Lambda perform from one other bucket than these allowlisted within the CloudFormation template, make certain so as to add the related permissions to the Lambda execution position.

The Lambda perform might take between 10–20 seconds to run (largely depending on the scale of your picture). If the perform performs correctly, it’s best to obtain an output JSON just like the next code block. The next screenshot reveals the profitable output on the console.

Notice that if you happen to simply enabled mannequin entry, it might take a couple of minutes for entry to propagate to the Lambda perform.
Check the API
For integration into an utility, we’ve related the Lambda perform to an API Gateway connection that may be pinged from numerous units. We’ve included a pocket book throughout the SageMaker pocket book that lets you question the system with a query and a picture and return a response. To make use of the pocket book, change the API_GW variable with the bodily ID of the API Gateway connection that was created utilizing the CloudFormation stack and the REGION variable with the Area your infrastructure was deployed in. Then, ensuring your picture location and question are set accurately, run the pocket book cell. Inside 10–20 seconds, it’s best to obtain the output of your multimodal question sourced from your personal textual content dataset. That is proven within the following screenshot.

Notice that the API Gateway connection is barely accessible from this particular pocket book, and extra complete safety and permission parts are required to productionize the system.
Qualitative outcomes
A grounded multimodal chat assistant, the place customers can submit photographs with queries, could be helpful in lots of settings. We show this utility with a dataset of automobiles on the market. For instance, a person might have a query a couple of automotive they’re , so that they snap an image and submit a query, similar to “How a lot would possibly a automotive like this price?” Quite than answering the query with generic info that the LLM was educated on (which can be old-fashioned), responses shall be grounded along with your native and particular automotive gross sales dataset. On this use case, we took photographs from Unsplash and used a synthetically created dataset of 10 automotive listings to reply questions. The mannequin and 12 months of the ten automotive listings are proven within the following screenshot.

For the examples within the following desk, you possibly can observe within the reply, not solely has the imaginative and prescient language mannequin (VLM) system recognized the proper automobiles within the automotive listings which might be most just like the enter picture, but in addition it has answered the questions with particular numbers, prices, and places which might be solely accessible from our closed automobiles dataset car-listings.zip.
| Query | Picture | Reply |
| How a lot would a automotive like this price? |  |
The 2013 Jeep Grand Cherokee SRT8 itemizing is most related, with an asking worth of $17,000 regardless of important physique harm from an accident. Nonetheless, it retains the highly effective 470 hp V8 engine and has been well-maintained with service data. |
| What’s the engine dimension of this automotive? |  |
The automotive itemizing for the 2013 Volkswagen Beetle mentions it has a fuel-efficient 1.8L turbocharged engine. No different engine particulars are offered within the listings. |
| The place on the planet might I buy a used automotive like this? |  |
Based mostly on the automotive listings offered, the 2021 Tesla Mannequin 3 on the market appears most just like the automotive you have an interest in. It’s described as a low mileage, well-maintained Mannequin 3 in pristine situation positioned within the Seattle space for $48,000. |
Latency and quantitative outcomes
As a result of pace and latency are vital for chat assistants and since this answer consists of a number of API calls to FMs and knowledge shops, it’s attention-grabbing to measure the pace of every step within the course of. We did an inner evaluation of the relative speeds of the varied API calls, and the next graph visualizes the outcomes.

From slowest to quickest, we’ve the decision to the Claude V3 Imaginative and prescient FM, which takes on common 8.2 seconds. The ultimate output era step (LLM Gen on the graph within the screenshot) takes on common 4.9 seconds. The Amazon Titan Textual content Embeddings mannequin and OpenSearch Service retrieval course of are a lot sooner, taking 0.28 and 0.27 seconds on common, respectively.
In these experiments, the common time for the complete multistage multimodal chatbot is 15.8 seconds. Nonetheless, the time could be as little as 11.5 seconds total if you happen to submit a 2.2 MB picture, and it might be a lot decrease if you happen to use even lower-resolution photographs.
Clear up
To scrub up the assets and keep away from prices, observe these steps:
- Make sure that all of the vital knowledge from Amazon DynamoDB and Amazon S3 are saved
- Manually empty and delete the 2 provisioned S3 buckets
- To scrub up the assets, delete the deployed useful resource stack from the CloudFormation console.
Conclusion
From purposes starting from on-line chat assistants to instruments to assist gross sales reps shut a deal, AI assistants are a quickly maturing expertise to extend effectivity throughout sectors. Usually these assistants intention to supply solutions grounded in customized documentation and datasets that the LLM was not educated on, utilizing RAG. A remaining step is the event of a multimodal chat assistant that may accomplish that as nicely—answering multimodal questions based mostly on a closed textual content dataset.
On this put up, we demonstrated tips on how to create a multimodal chat assistant that takes photographs and textual content as enter and produces textual content solutions grounded in your personal dataset. This answer could have purposes starting from marketplaces to customer support, the place there’s a want for domain-specific solutions sourced from customized datasets based mostly on multimodal enter queries.
We encourage you to deploy the answer for your self, strive completely different picture and textual content datasets, and discover how one can orchestrate numerous Amazon Bedrock FMs to supply streamlined, customized, multimodal programs.
In regards to the Authors
 Emmett Goodman is an Utilized Scientist on the Amazon Generative AI Innovation Heart. He makes a speciality of pc imaginative and prescient and language modeling, with purposes in healthcare, power, and training. Emmett holds a PhD in Chemical Engineering from Stanford College, the place he additionally accomplished a postdoctoral fellowship targeted on pc imaginative and prescient and healthcare.
Emmett Goodman is an Utilized Scientist on the Amazon Generative AI Innovation Heart. He makes a speciality of pc imaginative and prescient and language modeling, with purposes in healthcare, power, and training. Emmett holds a PhD in Chemical Engineering from Stanford College, the place he additionally accomplished a postdoctoral fellowship targeted on pc imaginative and prescient and healthcare.
 Negin Sokhandan is a Precept Utilized Scientist on the AWS Generative AI Innovation Heart, the place she works on constructing generative AI options for AWS strategic clients. Her analysis background is statistical inference, pc imaginative and prescient, and multimodal programs.
Negin Sokhandan is a Precept Utilized Scientist on the AWS Generative AI Innovation Heart, the place she works on constructing generative AI options for AWS strategic clients. Her analysis background is statistical inference, pc imaginative and prescient, and multimodal programs.
 Yanxiang Yu is an Utilized Scientist on the Amazon Generative AI Innovation Heart. With over 9 years of expertise constructing AI and machine studying options for industrial purposes, he makes a speciality of generative AI, pc imaginative and prescient, and time collection modeling.
Yanxiang Yu is an Utilized Scientist on the Amazon Generative AI Innovation Heart. With over 9 years of expertise constructing AI and machine studying options for industrial purposes, he makes a speciality of generative AI, pc imaginative and prescient, and time collection modeling.



{kind=link}