Constructing AI brokers that keep in mind consumer interactions requires extra than simply storing uncooked conversations. Whereas Amazon Bedrock AgentCore short-term reminiscence captures quick context, the true problem lies in remodeling these interactions into persistent, actionable data that spans throughout classes. That is the data that transforms fleeting interactions into significant, steady relationships between customers and AI brokers. On this put up, we’re pulling again the curtain on how the Amazon Bedrock AgentCore Reminiscence long-term reminiscence system works.
In the event you’re new to AgentCore Reminiscence, we advocate studying our introductory weblog put up first: Amazon Bedrock AgentCore Reminiscence: Constructing context-aware brokers. Briefly, AgentCore Reminiscence is a totally managed service that permits builders to construct context-aware AI brokers by offering each short-term working reminiscence and long-term clever reminiscence capabilities.
The problem of persistent reminiscence
When people work together, we don’t simply keep in mind precise conversations—we extract that means, establish patterns, and construct understanding over time. Educating AI brokers to reply the identical requires fixing a number of advanced challenges:
- Agent reminiscence techniques should distinguish between significant insights and routine chatter, figuring out which utterances deserve long-term storage versus short-term processing. A consumer saying “I’m vegetarian” ought to be remembered, however “hmm, let me suppose” shouldn’t.
- Reminiscence techniques want to acknowledge associated data throughout time and merge it with out creating duplicates or contradictions. When a consumer mentions they’re allergic to shellfish in January and mentions “can’t eat shrimp” in March, these must be acknowledged as associated information and consolidated with current data with out creating duplicates or contradictions.
- Recollections have to be processed so as of temporal context. Preferences that change over time (for instance, the consumer liked spicy hen in a restaurant final 12 months, however in the present day, they like delicate flavors) require cautious dealing with to ensure the newest choice is revered whereas sustaining historic context.
- As reminiscence shops develop to include hundreds or tens of millions of data, discovering related reminiscences shortly turns into a big problem. The system should steadiness complete reminiscence retention with environment friendly retrieval.
Fixing these issues requires subtle extraction, consolidation, and retrieval mechanisms that transcend easy storage. Amazon Bedrock AgentCore Reminiscence tackles these complexities by implementing a research-backed long-term reminiscence pipeline that mirrors human cognitive processes whereas sustaining the precision and scale required for enterprise functions.
How AgentCore long-term reminiscence works
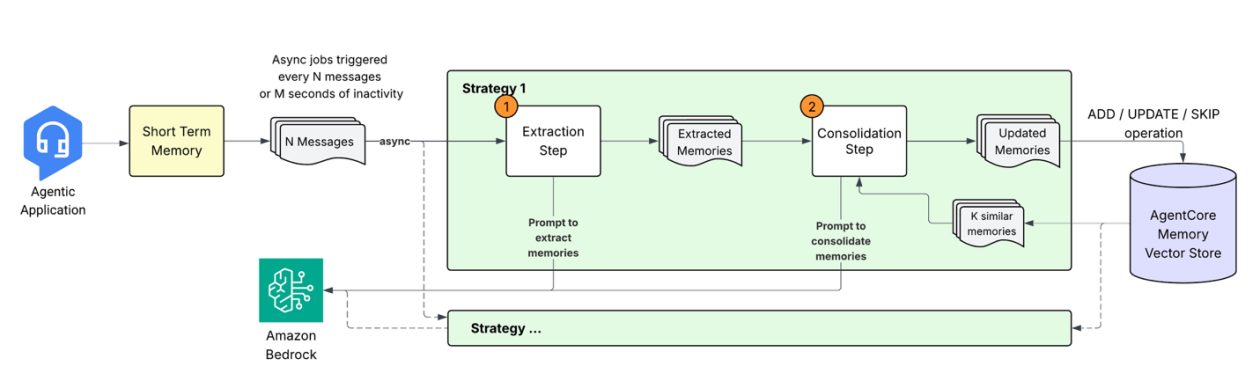
When the agentic software sends conversational occasions to AgentCore Reminiscence, it initiates a pipeline to remodel uncooked conversational information into structured, searchable data by a multi-stage course of. Let’s discover every part of this technique. 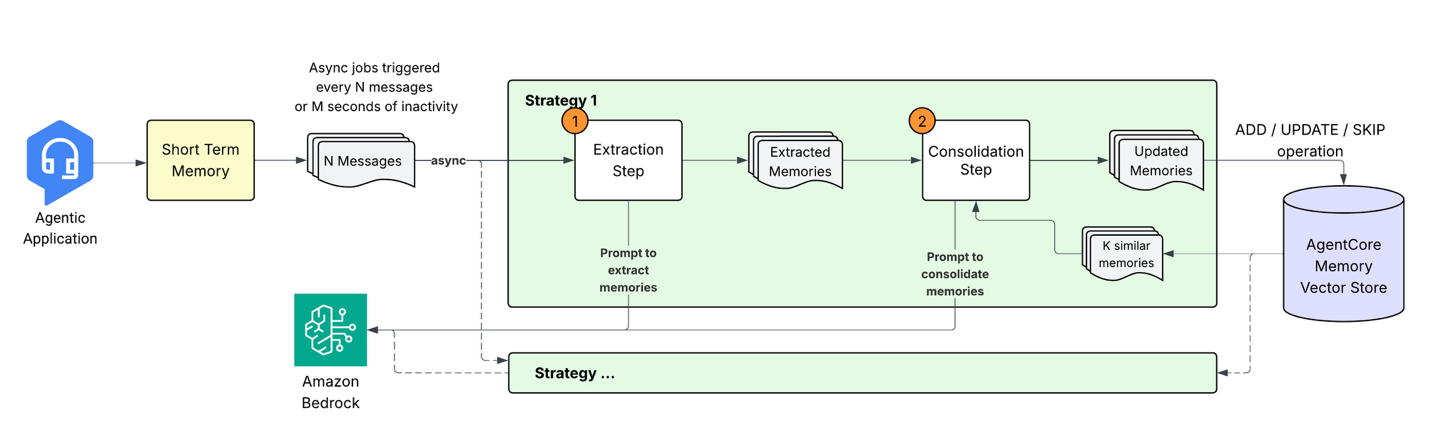
1. Reminiscence extraction: From dialog to insights
When new occasions are saved in short-term reminiscence, an asynchronous extraction course of analyzes the conversational content material to establish significant data. This course of leverages massive language fashions (LLMs) to know context and extract related particulars that ought to be preserved in long-term reminiscence. The extraction engine processes incoming messages alongside prior context to generate reminiscence data in a predefined schema. As a developer, you may configure a number of Reminiscence methods to extract solely the data sorts related to your software wants. The extraction course of helps three built-in reminiscence methods:
- Semantic reminiscence: Extracts information and data. Instance:
- Consumer preferences: Captures express and implicit preferences given context. Instance:
- Abstract reminiscence: Creates working narratives of conversations underneath completely different matters scoped to classes and preserves the important thing data in a structured XML format. Instance:
For every technique, the system processes occasions with timestamps for sustaining the continuity of context and battle decision. A number of reminiscences may be extracted from a single occasion, and every reminiscence technique operates independently, permitting parallel processing.
2. Reminiscence consolidation
Quite than merely including new reminiscences to current storage, the system performs clever consolidation to merge associated data, resolve conflicts, and decrease redundancies. This consolidation makes certain the agent’s reminiscence stays coherent and updated as new data arrives.
The consolidation course of works as follows:
- Retrieval: For every newly extracted reminiscence, the system retrieves the highest most semantically comparable current reminiscences from the identical namespace and technique.
- Clever processing: The brand new reminiscence and retrieved reminiscences are despatched to the LLM with a consolidation immediate. The immediate preserves the semantic context, thus avoiding pointless updates (for instance, “loves pizza” and “likes pizza” are thought of primarily the identical data). Preserving these core rules, the immediate is designed to deal with numerous situations:
Based mostly on this immediate, the LLM determines the suitable motion:
- ADD: When the brand new data is distinct from current reminiscences
- UPDATE: Improve current reminiscences when the brand new data enhances or updates the present reminiscences
- NO-OP: When the data is redundant
- Vector retailer updates: The system applies the decided actions, sustaining an immutable audit path by marking the outdated reminiscences as INVALID as a substitute of immediately deleting them.
This strategy makes certain that contradictory data is resolved (prioritizing current data), duplicates are minimized, and associated reminiscences are appropriately merged.
Dealing with edge circumstances
The consolidation course of gracefully handles a number of difficult situations:
- Out-of-order occasions: Though the system processes occasions in temporal order inside classes, it may well deal with late-arriving occasions by cautious timestamp monitoring and consolidation logic.
- Conflicting data: When new data contradicts current reminiscences, the system prioritizes recency whereas sustaining a file of earlier states:
- Reminiscence failures: If consolidation fails for one reminiscence, it doesn’t impression others. The system makes use of exponential backoff and retry mechanisms to deal with transient failures. If consolidation in the end fails, the reminiscence is added to the system to assist stop potential lack of data.
Superior customized reminiscence technique configurations
Whereas built-in reminiscence methods cowl widespread use circumstances, AgentCore Reminiscence acknowledges that completely different domains require tailor-made approaches for reminiscence extraction and consolidation. The system helps built-in methods with overrides for customized prompts that stretch the built-in extraction and consolidation logic, letting groups adapt reminiscence dealing with to their particular necessities. To keep up system compatibility and give attention to standards and logic moderately than output codecs, customized prompts assist builders customise what data will get extracted or filtered out, how reminiscences ought to be consolidated, and tips on how to resolve conflicts between contradictory data.
AgentCore Reminiscence additionally helps customized mannequin choice for reminiscence extraction and consolidation. This flexibility helps builders steadiness accuracy and latency based mostly on their particular wants. You’ll be able to outline them through the APIs if you create the memory_resource as a method override or through the console (as proven beneath within the console screenshot).
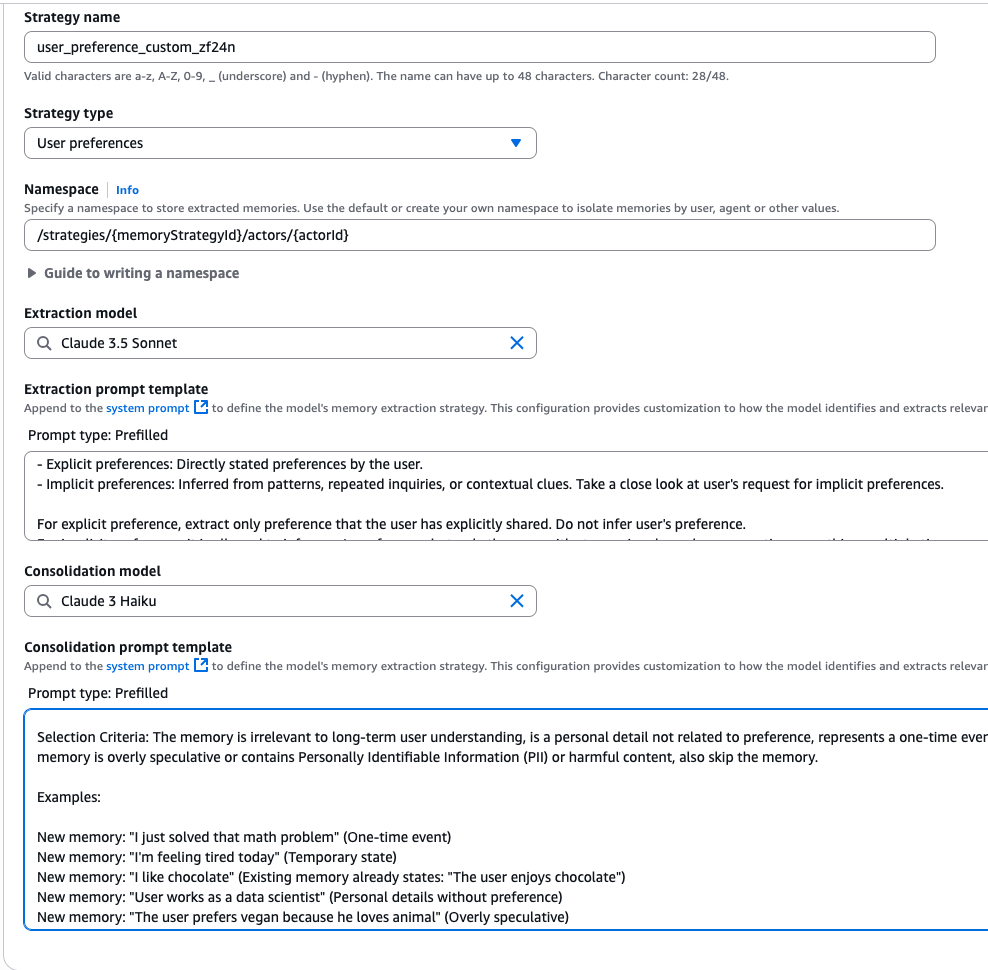
Aside from override performance, we additionally supply self-managed methods that present full management over your reminiscence processing pipeline. With self-managed methods, you may implement customized extraction and consolidation algorithms utilizing any fashions or prompts whereas leveraging AgentCore Reminiscence for storage and retrieval. Additionally, utilizing the Batch APIs, you may immediately ingest extracted data into AgentCore Reminiscence whereas sustaining full possession of the processing logic.
Efficiency traits
We evaluated our built-in reminiscence technique throughout three public benchmarking datasets to evaluate completely different facets of long-term conversational reminiscence:
- LoCoMo: Multi-session conversations generated by a machine-human pipeline with persona-based interactions and temporal occasion graphs. Checks long-term reminiscence capabilities throughout practical dialog patterns.
- LongMemEval: Evaluates reminiscence retention in lengthy conversations throughout a number of classes and prolonged time durations. We randomly sampled 200 QA pairs for analysis effectivity.
- PrefEval: Checks choice reminiscence throughout 20 matters utilizing 21-session situations to judge the system’s capacity to recollect and constantly apply consumer preferences over time.
- PolyBench-QA: A matter-answering dataset containing 807 Query Reply (QA) pairs throughout 80 trajectories, collected from a coding agent fixing duties in PolyBench.
We use two customary metrics: correctness and compression price. LLM-based correctness evaluates whether or not the system can appropriately recall and use saved data when wanted. Compression price is outlined as output reminiscence token rely / full context token rely, and evaluates how successfully the reminiscence system shops data. Greater compression charges point out the system maintains important data whereas decreasing storage overhead. This compression price immediately interprets to sooner inference speeds and decrease token consumption–probably the most essential consideration for deploying brokers at scale as a result of it allows extra environment friendly processing of huge conversational histories and reduces operational prices.
| Reminiscence Kind | Dataset | Correctness | Compression Price |
| RAG baseline (full dialog historical past) |
LoCoMo | 77.73% | 0% |
| LongMemEval-S | 75.2% | 0% | |
| PrefEval | 51% | 0% | |
| Semantic Reminiscence | LoCoMo | 70.58% | 89% |
| LongMemEval-S | 73.60% | 94% | |
| Choice Reminiscence | PrefEval | 79% | 68% |
| Summarization | PolyBench-QA | 83.02% | 95% |
The retrieval-augmented-generation (RAG) baseline performs effectively on factual QA duties because of full dialog historical past entry, however struggles with choice inference. The reminiscence system achieves robust sensible trade-offs: although data compression results in barely decrease correctness on some factual duties, it gives 89-95% compression charges for scalable deployment, sustaining bounded context sizes, and performs successfully at their specialised use circumstances.
For extra advanced duties requiring inference (understanding consumer preferences or behavioral patterns), reminiscence demonstrates clear benefits in each efficiency accuracy and storage effectivity—the extracted insights are extra useful than uncooked conversational information for these use circumstances.
Past accuracy metrics, AgentCore Reminiscence delivers the efficiency traits crucial for manufacturing deployment.
- Extraction and consolidation operations full inside 20-40 seconds for normal conversations after the extraction is triggered.
- Semantic search retrieval (
retrieve_memory_recordsAPI) returns ends in roughly 200 milliseconds. - Parallel processing structure allows a number of reminiscence methods to course of independently; thus, completely different reminiscence sorts may be processed concurrently with out blocking one another.
These latency traits, mixed with the excessive compression charges, allow the system to take care of responsive consumer experiences whereas managing intensive conversational histories effectively throughout large-scale deployments.
Greatest practices for long-term reminiscence
To maximise the effectiveness of long-term reminiscence in your brokers:
- Select the best reminiscence methods: Choose built-in methods that align along with your use case or create customized methods for domain-specific wants. Semantic reminiscence captures factual data, choice reminiscence tailors in direction of particular person choice, and summarization reminiscence distills advanced data for higher context administration. For instance, a buyer help agent may use semantic reminiscence to seize buyer transaction historical past and previous points, whereas summarization reminiscence creates quick narratives of present help conversations and troubleshooting workflows throughout completely different matters.
- Design significant namespaces: Construction your namespaces to mirror your software’s hierarchy. This additionally allows exact reminiscence isolation and environment friendly retrieval. For instance, use
customer-support/consumer/john-doefor particular person agent reminiscences andcustomer-support/shared/product-knowledgefor team-wide data. - Monitor consolidation patterns: Recurrently evaluate what reminiscences are being created (utilizing
list_memoriesorretrieve_memory_recordsAPI), up to date, or skipped. This helps refine your extraction methods and helps the system seize related data that’s higher fitted to your use case. - Plan for async processing: Do not forget that long-term reminiscence extraction is asynchronous. Design your software to deal with the delay between occasion ingestion and reminiscence availability. Think about using short-term reminiscence for quick retrieval wants whereas long-term reminiscences are being processed and consolidated within the background. You may additionally wish to implement fallback mechanisms or loading states to handle consumer expectations throughout processing delays.
Conclusion
The Amazon Bedrock AgentCore Reminiscence long-term reminiscence system represents a big development in constructing AI brokers. By combining subtle extraction algorithms, clever consolidation processes, and immutable storage designs, it gives a sturdy basis for brokers that study, adapt, and enhance over time.
The science behind this technique, from research-backed prompts to revolutionary consolidation workflow, makes certain that your brokers don’t simply keep in mind, however perceive. This transforms one-time interactions into steady studying experiences, creating AI brokers that change into extra useful and customized with each dialog.
Assets:
– AgentCore Reminiscence Docs
– AgentCore Reminiscence code samples
– Getting began with AgentCore – Workshop
In regards to the authors
 Akarsha Sehwag is a Generative AI Information Scientist for Amazon Bedrock AgentCore GTM crew. With over six years of experience in AI/ML, she has constructed production-ready enterprise options throughout various buyer segments in Generative AI, Deep Studying and Laptop Imaginative and prescient domains. Outdoors of labor, she likes to hike, bike or play Badminton.
Akarsha Sehwag is a Generative AI Information Scientist for Amazon Bedrock AgentCore GTM crew. With over six years of experience in AI/ML, she has constructed production-ready enterprise options throughout various buyer segments in Generative AI, Deep Studying and Laptop Imaginative and prescient domains. Outdoors of labor, she likes to hike, bike or play Badminton.
 Jiarong Jiang is a Principal Utilized Scientist at AWS, driving improvements in Retrieval-Augmented Technology (RAG) and agent reminiscence techniques to enhance the accuracy and intelligence of enterprise AI. She’s captivated with enabling prospects to construct context-aware, reasoning-driven functions that leverage their very own information successfully.
Jiarong Jiang is a Principal Utilized Scientist at AWS, driving improvements in Retrieval-Augmented Technology (RAG) and agent reminiscence techniques to enhance the accuracy and intelligence of enterprise AI. She’s captivated with enabling prospects to construct context-aware, reasoning-driven functions that leverage their very own information successfully.
 Jay Lopez-Braus is a Senior Technical Product Supervisor at AWS. He has over ten years of product administration expertise. In his free time, he enjoys all issues outdoor.
Jay Lopez-Braus is a Senior Technical Product Supervisor at AWS. He has over ten years of product administration expertise. In his free time, he enjoys all issues outdoor.
 Dani Mitchell is a Generative AI Specialist Options Architect at Amazon Net Companies (AWS). He’s targeted on serving to speed up enterprises internationally on their generative AI journeys with Amazon Bedrock and Bedrock AgentCore.
Dani Mitchell is a Generative AI Specialist Options Architect at Amazon Net Companies (AWS). He’s targeted on serving to speed up enterprises internationally on their generative AI journeys with Amazon Bedrock and Bedrock AgentCore.
 Peng Shi is a Senior Utilized Scientist at AWS, the place he leads developments in agent reminiscence techniques to reinforce the accuracy, adaptability, and reasoning capabilities of AI. His work focuses on creating extra clever and context-aware functions that bridge cutting-edge analysis with real-world impression.
Peng Shi is a Senior Utilized Scientist at AWS, the place he leads developments in agent reminiscence techniques to reinforce the accuracy, adaptability, and reasoning capabilities of AI. His work focuses on creating extra clever and context-aware functions that bridge cutting-edge analysis with real-world impression.



{kind=link}