This put up was co-written with Jerry Liu from LlamaIndex.
Retrieval Augmented Technology (RAG) has emerged as a strong method for enhancing the capabilities of huge language fashions (LLMs). By combining the huge information saved in exterior information sources with the generative energy of LLMs, RAG allows you to sort out advanced duties that require each information and creativity. Immediately, RAG strategies are utilized in each enterprise, small and enormous, the place generative synthetic intelligence (AI) is used as an enabler for fixing document-based query answering and different varieties of evaluation.
Though constructing a easy RAG system is easy, constructing manufacturing RAG methods utilizing superior patterns is difficult. A manufacturing RAG pipeline usually operates over a bigger information quantity and bigger information complexity, and should meet the next high quality bar in comparison with constructing a proof of idea. A common broad problem that builders face is low response high quality; the RAG pipeline will not be in a position to sufficiently reply numerous questions. This may be resulting from a wide range of causes; the next are a number of the commonest:
- Dangerous retrievals – The related context wanted to reply the query is lacking.
- Incomplete responses – The related context is partially there however not utterly. The generated output doesn’t totally reply the enter query.
- Hallucinations – The related context is there however the mannequin will not be in a position to extract the related data as a way to reply the query.
This necessitates extra superior RAG strategies on the question understanding, retrieval, and technology parts as a way to deal with these failure modes.
That is the place LlamaIndex is available in. LlamaIndex is an open supply library with each easy and superior strategies that allows builders to construct manufacturing RAG pipelines. It offers a versatile and modular framework for constructing and querying doc indexes, integrating with varied LLMs, and implementing superior RAG patterns.
Amazon Bedrock is a managed service offering entry to high-performing basis fashions (FMs) from main AI suppliers via a unified API. It gives a variety of huge fashions to select from, together with capabilities to securely construct and customise generative AI functions. Key superior options embrace mannequin customization with fine-tuning and continued pre-training utilizing your personal information, in addition to RAG to reinforce mannequin outputs by retrieving context from configured information bases containing your personal information sources. You can too create clever brokers that orchestrate FMs with enterprise methods and information. Different enterprise capabilities embrace provisioned throughput for assured low-latency inference at scale, mannequin analysis to match efficiency, and AI guardrails to implement safeguards. Amazon Bedrock abstracts away infrastructure administration via a totally managed, serverless expertise.
On this put up, we discover find out how to use LlamaIndex to construct superior RAG pipelines with Amazon Bedrock. We focus on find out how to arrange the next:
- Easy RAG pipeline – Arrange a RAG pipeline in LlamaIndex with Amazon Bedrock fashions and top-k vector search
- Router question – Add an automatic router that may dynamically do semantic search (top-k) or summarization over information
- Sub-question question – Add a question decomposition layer that may decompose advanced queries into a number of less complicated ones, and run them with the related instruments
- Agentic RAG – Construct a stateful agent that may do the previous parts (instrument use, question decomposition), but additionally keep state-like dialog historical past and reasoning over time
Easy RAG pipeline
At its core, RAG includes retrieving related data from exterior information sources and utilizing it to reinforce the prompts fed to an LLM. This permits the LLM to generate responses which can be grounded in factual information and tailor-made to the precise question.
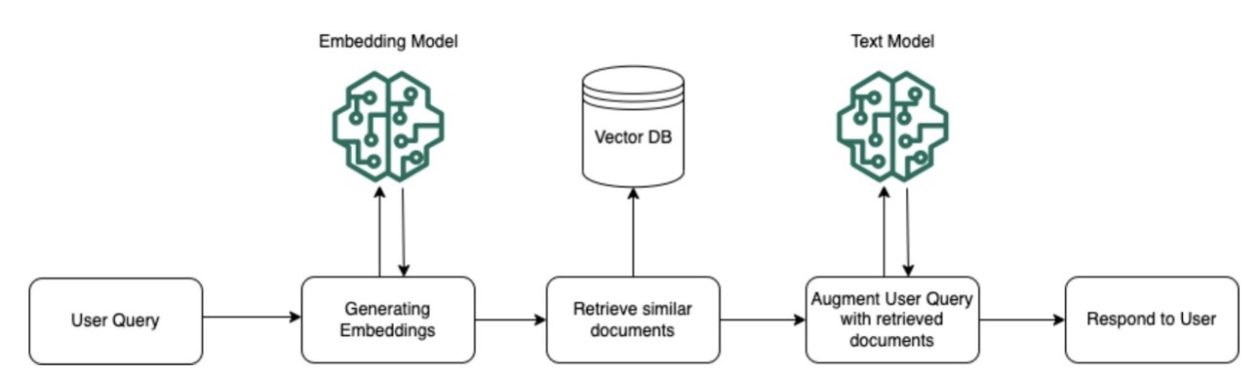
For RAG workflows in Amazon Bedrock, paperwork from configured information bases undergo preprocessing, the place they’re cut up into chunks, embedded into vectors, and listed in a vector database. This permits environment friendly retrieval of related data at runtime. When a person question is available in, the identical embedding mannequin is used to transform the question textual content right into a vector illustration. This question vector is in contrast in opposition to the listed doc vectors to determine probably the most semantically related chunks from the information base. The retrieved chunks present further context associated to the person’s question. This contextual data is appended to the unique person immediate earlier than being handed to the FM to generate a response. By augmenting the immediate with related information pulled from the information base, the mannequin’s output is ready to use and learn by a company’s proprietary data sources. This RAG course of may also be orchestrated by brokers, which use the FM to find out when to question the information base and find out how to incorporate the retrieved context into the workflow.
The next diagram illustrates this workflow.

The next is a simplified instance of a RAG pipeline utilizing LlamaIndex:
The pipeline consists of the next steps:
- Use the
SimpleDirectoryReaderto load paperwork from the “information/” - Create a
VectorStoreIndexfrom the loaded paperwork. This kind of index converts paperwork into numerical representations (vectors) that seize their semantic that means. - Question the index with the query “What’s the capital of France?” The index makes use of similarity measures to determine the paperwork most related to the question.
- The retrieved paperwork are then used to reinforce the immediate for the LLM, which generates a response based mostly on the mixed data.
LlamaIndex goes past easy RAG and allows the implementation of extra refined patterns, which we focus on within the following sections.
Router question
RouterQueryEngine lets you route queries to totally different indexes or question engines based mostly on the character of the question. For instance, you may route summarization inquiries to a abstract index and factual inquiries to a vector retailer index.
The next is a code snippet from the instance notebooks demonstrating RouterQueryEngine:
Sub-question question
SubQuestionQueryEngine breaks down advanced queries into less complicated sub-queries after which combines the solutions from every sub-query to generate a complete response. That is notably helpful for queries that span throughout a number of paperwork. It first breaks down the advanced question into sub-questions for every related information supply, then gathers the intermediate responses and synthesizes a ultimate response that integrates the related data from every sub-query. For instance, if the unique question was “What’s the inhabitants of the capital metropolis of the nation with the very best GDP in Europe,” the engine would first break it down into sub-queries like “What’s the highest GDP nation in Europe,” “What’s the capital metropolis of that nation,” and “What’s the inhabitants of that capital metropolis,” after which mix the solutions to these sub-queries right into a ultimate complete response.
The next is an instance of utilizing SubQuestionQueryEngine:
Agentic RAG
An agentic method to RAG makes use of an LLM to cause in regards to the question and decide which instruments (comparable to indexes or question engines) to make use of and in what sequence. This permits for a extra dynamic and adaptive RAG pipeline. The next structure diagram reveals how agentic RAG works on Amazon Bedrock.

Agentic RAG in Amazon Bedrock combines the capabilities of brokers and information bases to allow RAG workflows. Brokers act as clever orchestrators that may question information bases throughout their workflow to retrieve related data and context to reinforce the responses generated by the FM.
After the preliminary preprocessing of the person enter, the agent enters an orchestration loop. On this loop, the agent invokes the FM, which generates a rationale outlining the following step the agent ought to take. One potential step is to question an connected information base to retrieve supplemental context from the listed paperwork and information sources.
If a information base question is deemed helpful, the agent invokes an InvokeModel name particularly for information base response technology. This fetches related doc chunks from the information base based mostly on semantic similarity to the present context. These retrieved chunks present further data that’s included within the immediate despatched again to the FM. The mannequin then generates an remark response that’s parsed and may invoke additional orchestration steps, like invoking exterior APIs (via motion group AWS Lambda capabilities) or present a ultimate response to the person. This agentic orchestration augmented by information base retrieval continues till the request is totally dealt with.
One instance of an agent orchestration loop is the ReAct agent, which was initially launched by Yao et al. ReAct interleaves chain-of-thought and power use. At each stage, the agent takes within the enter process together with the earlier dialog historical past and decides whether or not to invoke a instrument (comparable to querying a information base) with the suitable enter or not.
The next is an instance of utilizing the ReAct agent with the LlamaIndex SDK:
The ReAct agent will analyze the question and determine whether or not to make use of the Lyft 10K instrument or one other instrument to reply the query. To check out agentic RAG, confer with the GitHub repo.
LlamaCloud and LlamaParse
LlamaCloud represents a big development within the LlamaIndex panorama, providing a complete suite of managed companies tailor-made for enterprise-grade context augmentation inside LLM and RAG functions. This service empowers AI engineers to focus on growing core enterprise logic by streamlining the intricate course of of information wrangling.
One key element is LlamaParse, a proprietary parsing engine adept at dealing with advanced, semi-structured paperwork replete with embedded objects like tables and figures, seamlessly integrating with LlamaIndex’s ingestion and retrieval pipelines. One other key element is the Managed Ingestion and Retrieval API, which facilitates easy loading, processing, and storage of information from numerous sources, together with LlamaParse outputs and LlamaHub’s centralized information repository, whereas accommodating varied information storage integrations.
Collectively, these options allow the processing of huge manufacturing information volumes, culminating in enhanced response high quality and unlocking unprecedented capabilities in context-aware query answering for RAG functions. To study extra about these options, confer with Introducing LlamaCloud and LlamaParse.
For this put up, we use LlamaParse to showcase the mixing with Amazon Bedrock. LlamaParse is an API created by LlamaIndex to effectively parse and signify information for environment friendly retrieval and context augmentation utilizing LlamaIndex frameworks. What is exclusive about LlamaParse is that it’s the world’s first generative AI native doc parsing service, which permits customers to submit paperwork together with parsing directions. The important thing perception behind parsing directions is that what sort of paperwork you might have, so that you already know what sort of output you need. The next determine reveals a comparability of parsing a posh PDF with LlamaParse vs. two common open supply PDF parsers.

A inexperienced spotlight in a cell signifies that the RAG pipeline appropriately returned the cell worth as the reply to a query over that cell. A purple spotlight signifies that the query was answered incorrectly.
Combine Amazon Bedrock and LlamaIndex to construct an Superior RAG Pipeline
On this part, we present you find out how to construct a sophisticated RAG stack combining LlamaParse and LlamaIndex with Amazon Bedrock companies – LLMs, embedding fashions, and Bedrock Information Base.
To make use of LlamaParse with Amazon Bedrock, you possibly can observe these high-level steps:
- Obtain your supply paperwork.
- Ship the paperwork to LlamaParse utilizing the Python SDK:
- Look ahead to the parsing job to complete and add the ensuing Markdown paperwork to Amazon Easy Storage Service (Amazon S3).
- Create an Amazon Bedrock information base utilizing the supply paperwork.
- Select your most well-liked embedding and technology mannequin from Amazon Bedrock utilizing the LlamaIndex SDK:
- Implement a sophisticated RAG sample utilizing LlamaIndex. Within the following instance, we use
SubQuestionQueryEngineand a retriever specifically created for Amazon Bedrock information bases: - Lastly, question the index together with your query:
We examined Llamaparse on a real-world, difficult instance of asking questions on a doc containing Financial institution of America Q3 2023 monetary outcomes. An instance slide from the full slide deck (48 advanced slides!) is proven under.

Utilizing the process outlined above, we requested “What’s the pattern in digital households/relationships from 3Q20 to 3Q23?”; check out the reply generated utilizing Llamaindex instruments vs. the reference reply from human annotation.
| LlamaIndex + LlamaParse reply | Reference reply |
| The pattern in digital households/relationships reveals a gentle improve from 3Q20 to 3Q23. In 3Q20, the variety of digital households/relationships was 550K, which elevated to 645K in 3Q21, then to 672K in 3Q22, and additional to 716K in 3Q23. This means constant development within the adoption of digital companies amongst households and relationships over the reported quarters. | The pattern reveals a gentle improve in digital households/relationships from 645,000 in 3Q20 to 716,000 in 3Q23. The digital adoption proportion additionally elevated from 76% to 83% over the identical interval. |
The next are instance notebooks to check out these steps by yourself examples. Observe the prerequisite steps and cleanup assets after testing them.
Conclusion
On this put up, we explored varied superior RAG patterns with LlamaIndex and Amazon Bedrock. To delve deeper into the capabilities of LlamaIndex and its integration with Amazon Bedrock, try the next assets:
By combining the ability of LlamaIndex and Amazon Bedrock, you possibly can construct strong and complicated RAG pipelines that unlock the complete potential of LLMs for knowledge-intensive duties.
In regards to the Creator
 Shreyas Subramanian is a Principal information scientist and helps clients through the use of Machine Studying to unravel their enterprise challenges utilizing the AWS platform. Shreyas has a background in giant scale optimization and Machine Studying, and in use of Machine Studying and Reinforcement Studying for accelerating optimization duties.
Shreyas Subramanian is a Principal information scientist and helps clients through the use of Machine Studying to unravel their enterprise challenges utilizing the AWS platform. Shreyas has a background in giant scale optimization and Machine Studying, and in use of Machine Studying and Reinforcement Studying for accelerating optimization duties.
 Jerry Liu is the co-founder/CEO of LlamaIndex, a knowledge framework for constructing LLM functions. Earlier than this, he has spent his profession on the intersection of ML, analysis, and startups. He led the ML monitoring crew at Sturdy Intelligence, did self-driving AI analysis at Uber ATG, and labored on suggestion methods at Quora.
Jerry Liu is the co-founder/CEO of LlamaIndex, a knowledge framework for constructing LLM functions. Earlier than this, he has spent his profession on the intersection of ML, analysis, and startups. He led the ML monitoring crew at Sturdy Intelligence, did self-driving AI analysis at Uber ATG, and labored on suggestion methods at Quora.



{kind=link}