
Your AI agent labored within the demo, impressed stakeholders, dealt with take a look at situations, and appeared prepared for manufacturing. Then you definately deployed it, and the image modified. Actual customers skilled incorrect software calls, inconsistent responses, and failure modes no person anticipated throughout testing.
The result’s a spot between anticipated agent conduct and precise person expertise in manufacturing. Agent analysis introduces challenges that conventional software program testing wasn’t designed to deal with. As a result of massive language fashions (LLMs) are non-deterministic, the identical person question can produce totally different software alternatives, reasoning paths, and outputs throughout a number of runs. Because of this you have to take a look at every situation repeatedly to grasp your agent’s precise conduct patterns. A single take a look at move tells you what can occur, not what usually occurs. With out systematic measurement throughout these variations, groups are trapped in cycles of handbook testing and reactive debugging. This burns by means of API prices with out clear perception into whether or not adjustments enhance agent efficiency. This uncertainty makes each immediate modification dangerous and leaves a elementary query unanswered: “Is that this agent really higher now?”
On this publish, we introduce Amazon Bedrock AgentCore Evaluations, a totally managed service for assessing AI agent efficiency throughout the event lifecycle. We stroll by means of how the service measures agent accuracy throughout a number of high quality dimensions. We clarify the 2 analysis approaches for growth and manufacturing and share sensible steerage for constructing brokers you possibly can deploy with confidence.
Why agent analysis requires a brand new strategy
When a person sends a request to an agent, a number of selections occur in sequence. The agent determines which instruments (if any) to name, executes these calls, and generates a response primarily based on the outcomes. Every step introduces potential failure factors: deciding on the incorrect software, calling the fitting software with incorrect parameters, or synthesizing software outputs into an inaccurate last reply. In contrast to conventional purposes the place you take a look at a single operate’s output, agent analysis requires measuring high quality throughout this whole interplay circulation.
This creates particular challenges for agent builders that may be addressed by doing the next:
- Outline analysis standards on what constitutes an accurate software choice, legitimate software parameters, an correct response, and a useful person expertise.
- Construct take a look at datasets that signify actual person requests and anticipated behaviors.
- Select scoring strategies that may assess high quality constantly throughout repeated runs.
Every of those definitions immediately determines what your analysis system measures and getting them incorrect means optimizing for the incorrect outcomes. With out this foundational work, the hole between what groups hope their brokers do and what they’ll show their brokers do turns into an actual enterprise danger.Bridging this hole requires a steady analysis cycle, as proven in Determine 1. Groups construct take a look at circumstances, run them towards the agent, rating the outcomes, analyze failures, and implement enhancements. Every failure turns into a brand new take a look at case, and the cycle continues by means of each iteration of the agent.
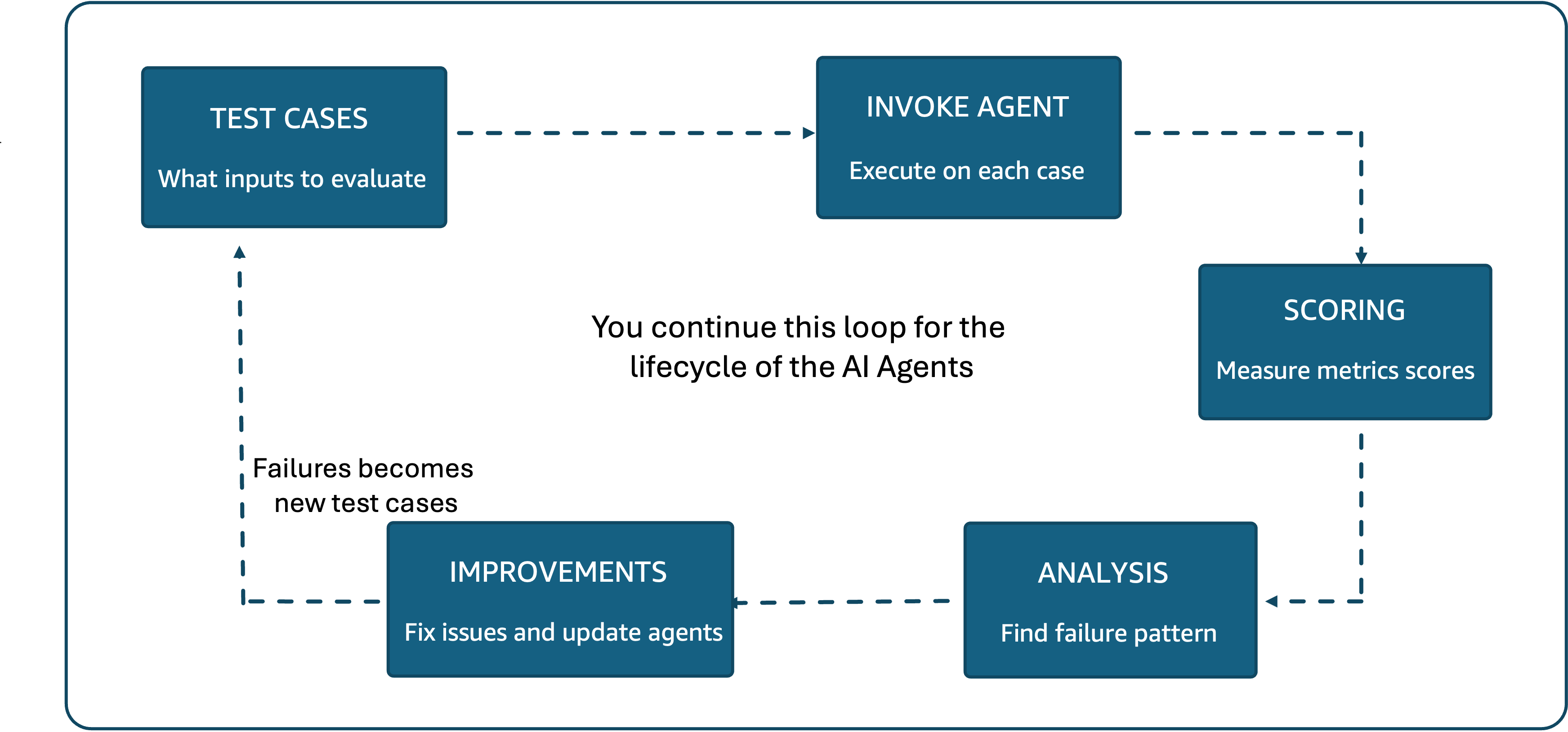
Determine 1: The agent analysis course of follows a steady cycle of take a look at circumstances, agent execution, scoring, evaluation, and enhancements. Failures turn into new take a look at circumstances.
Operating this cycle finish to finish, nonetheless, requires important infrastructure past the analysis logic itself. Groups should curate datasets, choose and host scoring fashions, handle inference capability and API fee limits, construct information pipelines that remodel agent traces into evaluation-ready codecs, and create dashboards to visualise developments. For organizations working a number of brokers, this overhead multiplies with every one. The result’s that agent developer groups find yourself spending extra time sustaining analysis tooling than performing on what it tells them. That is the issue Amazon Bedrock AgentCore Evaluations was constructed to deal with.
Introducing Amazon Bedrock AgentCore Evaluations
First launched in public preview at AWS re:Invent 2025, the service is now typically accessible. It handles the analysis fashions, inference infrastructure, information pipelines, and scaling so groups can give attention to enhancing agent high quality fairly than constructing and sustaining analysis techniques. For built-in evaluators, mannequin quota and inference capability are absolutely managed. Because of this organizations evaluating many brokers aren’t consuming their very own quotas or provisioning separate infrastructure for analysis workloads.
AgentCore Evaluations look at agent conduct end-to-end utilizing OpenTelemetry (OTEL) traces with generative AI semantic conventions. OTEL is an open supply observability normal for amassing distributed traces from purposes. The generative AI semantic conventions lengthen it with fields particular to language mannequin interactions, together with prompts, completions, software calls, and mannequin parameters. By constructing on this normal, the service works constantly throughout brokers constructed with any Strands Brokers or LangGraph, and instrumented with OpenTelemetry and OpenInference, capturing the total context wanted for significant analysis.
The evaluations may be configured with totally different approaches:
- LLM-as-a-Choose the place an LLM evaluates every agent interplay towards structured rubrics with clearly outlined standards.
- Floor Reality primarily based analysis can be utilized to check the agent responses towards pre-defined or simulated datasets.
- Customized code evaluators the place you possibly can herald a Lambda as a evaluator with your individual customized code.
Within the LLM-as-a-Choose strategy, the Choose mannequin examines the total interplay context, together with dialog historical past, accessible instruments, instruments used, parameters handed, and system directions, then gives detailed reasoning earlier than assigning a rating. Each rating comes with an evidence. Groups can use these scores to confirm judgments, perceive precisely why an interplay acquired a specific score, and determine what ought to have occurred in another way. This strategy goes past easy move/fail judgments, offering the structured analysis and clear reasoning that allow high quality evaluation at a scale that handbook assessment can not match.
Three ideas information how the service approaches analysis. Proof-driven growth replaces instinct with quantitative metrics, so groups can measure the precise influence of adjustments fairly than debating whether or not a immediate modification “feels higher.” Multi-dimensional evaluation evaluates totally different features of agent conduct independently. This makes it attainable to pinpoint precisely the place enhancements are wanted fairly than counting on a single combination rating. Steady measurement connects the efficiency baselines established throughout growth on to manufacturing monitoring, ensuring that high quality holds up as real-world situations evolve. These ideas apply all through the agent lifecycle, from the primary spherical of growth testing by means of ongoing manufacturing monitoring.
Analysis throughout the agent lifecycle
An agent’s journey from prototype to manufacturing creates two distinct analysis wants. Throughout growth, groups want managed environments the place they’ll evaluate alternate options, take a look at the agent on curated datasets, reproduce outcomes, and validate adjustments earlier than they attain customers. After the agent is reside, the problem shifts to monitoring real-world interactions at scale, the place customers encounter edge circumstances and interplay patterns that no quantity of pre-deployment testing anticipated. Determine 2 illustrates how analysis helps every stage of this journey, from preliminary proof of idea by means of shadow testing, A/B testing, and steady manufacturing monitoring.
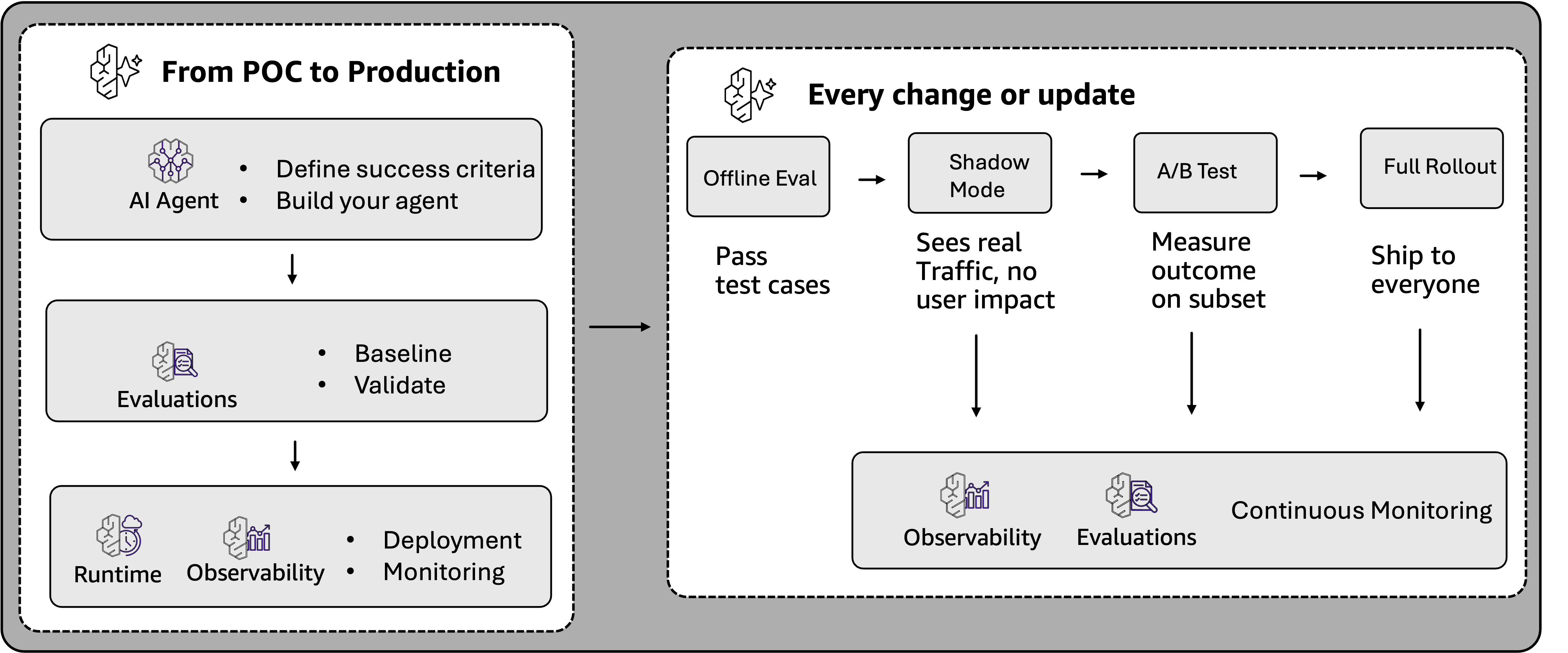
Determine 2: From POC to manufacturing, analysis validates brokers earlier than deployment. As brokers mature, analysis helps shadow testing, A/B testing, and steady monitoring at scale.
AgentCore Evaluations map two complementary approaches to those lifecycle phases, as proven in Determine 3. On-line analysis handles steady manufacturing monitoring, whereas on-demand analysis helps managed testing throughout growth and steady integration and steady supply (CI/CD) workflows, together with evaluations towards floor fact.
| On-demand Analysis | On-line Analysis | |
| Benefits |
|
|
| Use circumstances |
|
|
Determine 3: On-line analysis displays manufacturing site visitors constantly, whereas on-demand analysis helps managed testing throughout growth.
On-line analysis for manufacturing monitoring
On-line analysis displays reside agent interactions by constantly sampling a configurable share of traces and scoring them towards your chosen evaluators. You outline which evaluators to use, set sampling guidelines that management what fraction of manufacturing site visitors will get evaluated, and arrange applicable filters. The service handles studying traces, working evaluations, and surfacing ends in the AgentCore Observability dashboard powered by Amazon CloudWatch. If you happen to’re already amassing traces for observability, on-line analysis provides high quality scores with rationalization, alongside your present operational metrics with out requiring code adjustments or re-deployments. Determine 4 reveals how this course of works.
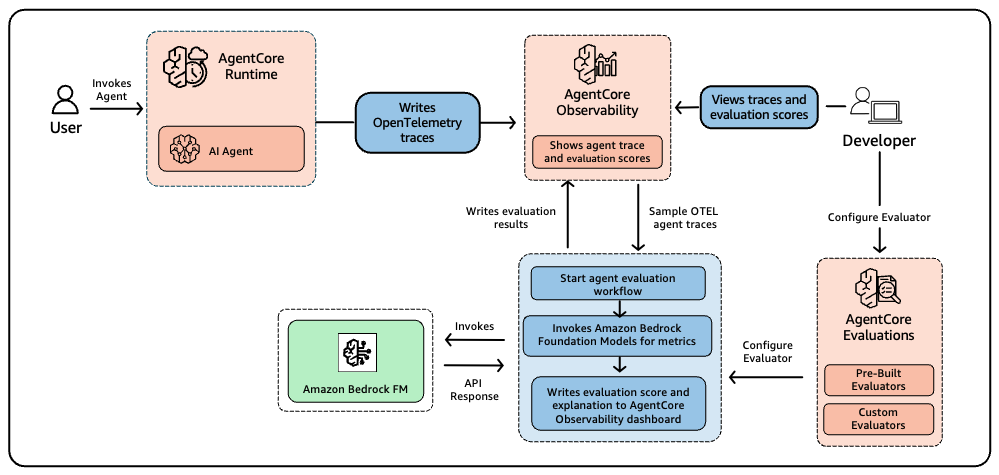
High quality points in manufacturing usually floor in ways in which conventional monitoring misses. Operational dashboards could present inexperienced throughout latency and error charges whereas person expertise quietly degrades as a result of the agent begins deciding on incorrect instruments or offering much less useful responses. Steady high quality scoring catches these silent failures by monitoring analysis metrics alongside operational ones. As a result of AgentCore Observability runs on CloudWatch, you possibly can create customized dashboards and set alarms to get alerted the second scores drop under your thresholds.
On-demand analysis for growth
On-demand analysis is a real-time API designed for growth and CI/CD workflows. Groups use it to check adjustments earlier than deployment, run analysis suites as a part of CI/CD pipelines, carry out regression testing throughout builds, and gate deployments on high quality thresholds. Builders choose a full session and specify actual spans (particular person operations inside a hint) or traces by offering their IDs. The service considers the total session dialog and scores particular person span/traces towards the identical evaluators utilized in manufacturing. Frequent use circumstances embrace validating immediate adjustments, evaluating mannequin efficiency throughout alternate options, and stopping high quality regressions.
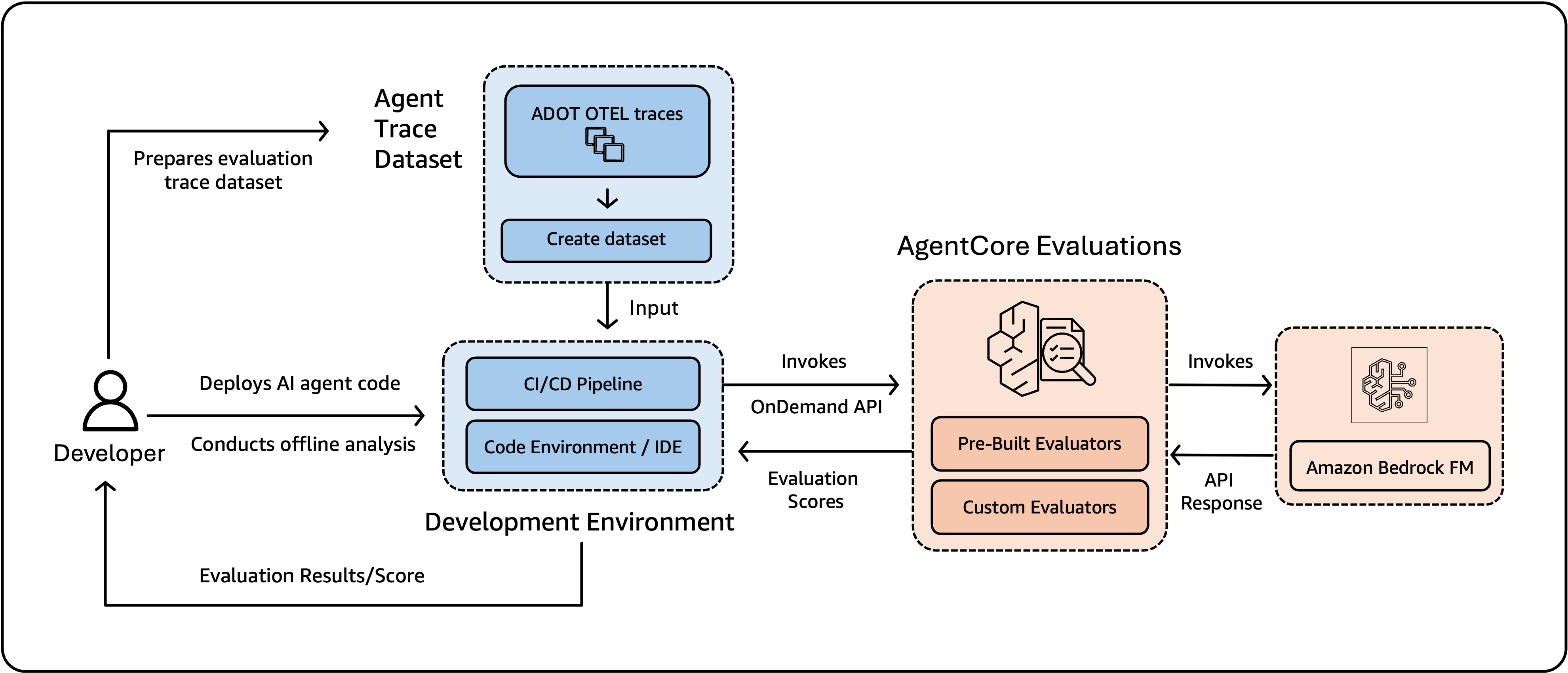
Determine 5: On-demand analysis allows builders to arrange hint datasets, invoke evaluations by means of a CI/CD pipeline or growth atmosphere, and obtain scores utilizing built-in or customized evaluators powered by Amazon Bedrock basis fashions.
As a result of each modes use the identical evaluators, what you take a look at in CI/CD is what you monitor in manufacturing, supplying you with constant high quality requirements throughout the whole growth lifecycle. On-demand analysis gives the managed atmosphere wanted for structure selections and systematic enchancment, whereas on-line analysis maintains high quality monitoring continues after the agent is reside. Collectively, the 2 modes type a steady suggestions loop between growth and manufacturing, and each draw from the identical set of evaluators and scoring infrastructure.
How AgentCore evaluates your agent
AgentCore Evaluations organizes agent interactions right into a three-level hierarchy that determines what may be evaluated and at what granularity. A session represents a whole dialog between a person and your agent, grouping all associated interactions from a single person or workflow. Inside every session, a hint captures every part that occurs throughout a single trade. When a person sends a message and receives a response, that spherical journey produces one hint containing each step that the agent took to generate its reply. Every hint in flip comprises particular person operations referred to as spans, representing particular actions your agent carried out, comparable to invoking a software, retrieving data from a data base, or producing textual content.
Completely different evaluators function at totally different ranges of this hierarchy, and issues at one degree can look very totally different from issues at one other. The service gives 13 pre-configured built-in evaluators organized throughout these three ranges, every measuring a definite facet of agent conduct (Determine 6). You’ll be able to outline customized evaluators utilizing LLM-as-a-Choose and customized code evaluators that may work on session, hint and span ranges.
| Degree | Evaluators | Function | Floor Reality Use |
| Session | Objective Success Price | Assesses whether or not all person objectives had been accomplished inside a dialog | Consumer gives free type textual assertions of aim completion, that are in contrast towards system conduct and measured by way of Objective Success Price |
| Hint | Helpfulness, Correctness, Coherence, Conciseness, Faithfulness, Harmfulness, Instruction Following, Response Relevance, Context Relevance, Refusal, Stereotyping | Evaluates response high quality, accuracy, security, and communication effectiveness | Flip degree floor fact (e.g., anticipated reply or attributes per flip) helps analysis of Correctness |
| Instrument | Instrument Choice Accuracy, Instrument Parameter Accuracy | Assesses software choice selections and parameter extraction precision | Instrument name floor fact specifies the right software sequence enabling Trajectory Precise Order Match, Trajectory In-Order Match, and Trajectory Any Order Match |
Determine 6: Constructed-in evaluators function at session, hint, and power ranges. Every degree measures totally different features of agent conduct. Floor Reality may be supplied as assertions, anticipated response and anticipated trajectory for analysis on session, hint and power degree.
Evaluating every degree independently helps groups to diagnose whether or not an issue originates in software choice, response era, or session-level planning. An agent may select the fitting software with correct parameters however then synthesize the software’s output poorly in its last response. This sample solely turns into seen when every degree is assessed by itself. Your agent’s main objective guides which evaluators to prioritize. Customer support brokers ought to give attention to Helpfulness, Objective Success Price, and Instruction Following, since resolving person points inside outlined guardrails immediately impacts satisfaction. Brokers with Retrieval Augmented Era (RAG) parts profit most from Correctness and Faithfulness to make it possible for responses are grounded within the supplied context. Instrument-heavy brokers want sturdy Instrument Choice Accuracy and Instrument Parameter Accuracy scores. It’s really helpful to begin with three or 4 evaluators that align together with your agent’s objective and develop protection as your understanding matures.
Understanding evaluator distinctions
Some evaluators naturally work together with one another, so scores needs to be learn collectively fairly than in isolation. Evaluators that sound related usually measure essentially various things, and understanding these distinctions is essential for prognosis.
- Correctness checks whether or not the response is factually correct, whereas Faithfulness checks whether or not it’s per the dialog historical past. For instance, an agent may be trustworthy to flawed supply materials however nonetheless incorrect.
- Helpfulness asks whether or not the response advances the person towards their aim, whereas Response Relevance asks whether or not it addresses what was initially requested. For instance, an agent can reply the incorrect query completely.
- Coherence checks for inner contradictions in reasoning, whereas Context Relevance checks whether or not the agent had the fitting data accessible. For instance, one reveals a era downside, the opposite a retrieval downside.
Some evaluators additionally rely upon or trade-off towards one another. As an illustration:
- Instrument Parameter Accuracy is significant solely when the agent has chosen the right software, so low Instrument Choice Accuracy needs to be addressed first.
- Correctness usually relies on Context Relevance as a result of an agent can not generate correct solutions with out the fitting data.
- Conciseness and Helpfulness usually battle as a result of temporary responses may omit context that customers want.
Constructed-in evaluators ship with predefined immediate templates, chosen evaluator fashions, and standardized scoring standards, with configurations fastened to protect consistency throughout evaluations. They use cross-Area inference to routinely choose compute from AWS Areas inside your geography, enhancing mannequin availability and throughput whereas preserving information saved within the originating Area. Customized evaluators lengthen this basis with assist on your personal evaluator mannequin, analysis directions, standards, and scoring schema. They’re significantly worthwhile for industry-specific assessments comparable to compliance checking in healthcare or monetary providers, model voice consistency verification, or implementing organizational high quality requirements. Customized code evaluators allow you to herald an AWS Lambda operate to carry out the evaluations. This lets you additionally create deterministic scoring of your brokers.
To be used circumstances requiring all processing inside a single Area, customized evaluators additionally present full management over inference configuration. When constructing a customized evaluator, you outline directions with placeholders that get changed with precise hint data earlier than being despatched to the choose mannequin. The scope of data accessible relies on the evaluator’s degree: a session-level evaluator can entry the total dialog context and accessible instruments, a trace-level evaluator sees earlier turns plus the present assistant response, and a tool-level evaluator focuses on particular software calls inside their surrounding context. The AWS console gives the choice to load the immediate template of any present built-in evaluator as a place to begin, making it easy to create customized variants (Determine 7).
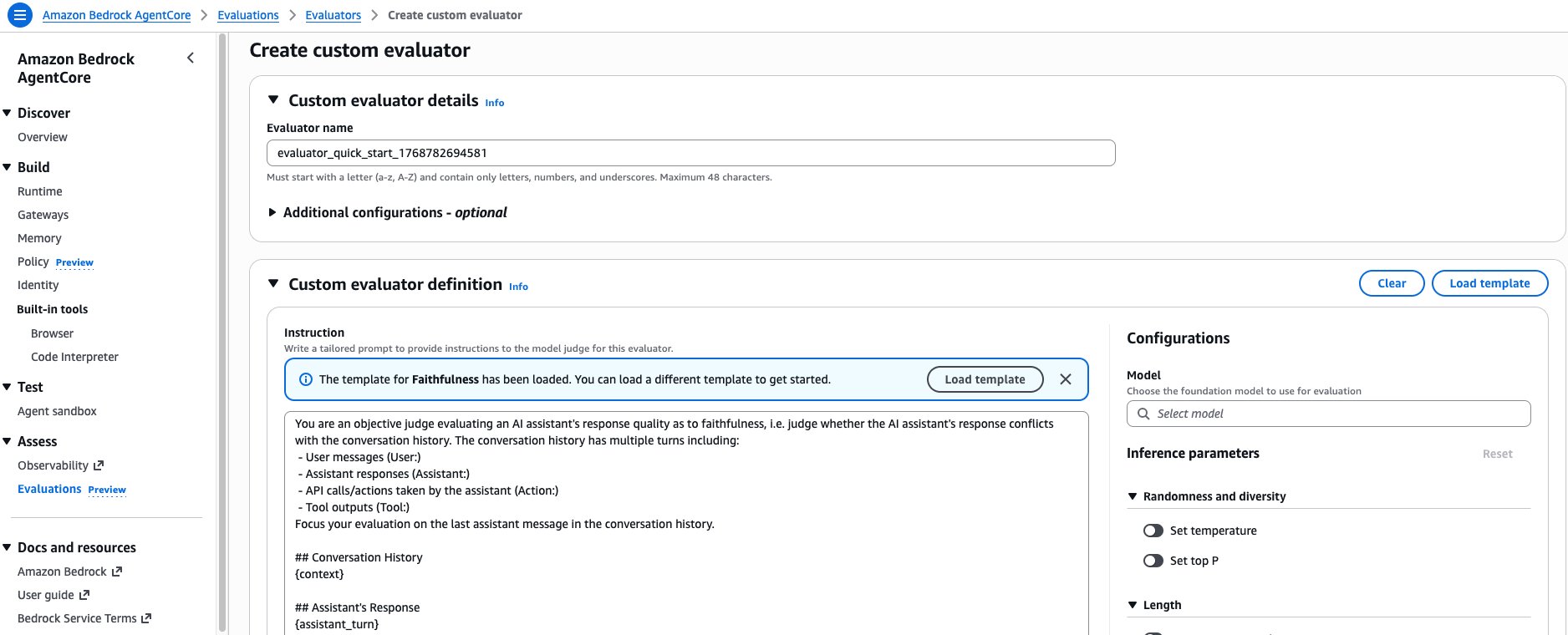
Determine 7: The AgentCore Evaluations console gives the choice to load any built-in evaluator’s immediate template as a place to begin when making a customized evaluator.
When constructing a number of customized evaluators, use the MECE (Mutually Unique, Collectively Exhaustive) precept to design your analysis suite. Every evaluator ought to have a definite, non-overlapping scope whereas collectively overlaying all high quality dimensions you care about. For instance, fairly than creating two evaluators that each partially assess “response high quality,” separate them into one which evaluates factual grounding and one other that evaluates communication readability. Moreover, to write down evaluator directions, set up the choose mannequin’s function as a efficiency evaluator to forestall confusion between analysis and job execution. Use clear, sequential directions with exact language, and contemplate together with one to a few related examples with matching enter/output pairs that signify your anticipated requirements. For scoring, select between binary scales (0/1) for move/fail situations or ordinal scales (comparable to 1–5) for extra nuanced assessments, and begin with binary scoring when unsure. The service standardizes output to incorporate a motive subject adopted by a rating subject, so the choose mannequin all the time presents its reasoning earlier than assigning a quantity. Keep away from together with your individual output formatting directions, as they’ll confuse the Choose mannequin.
Customized Code-based evaluators
Constructed-in and customized evaluators each use an LLM-as-a-Choose. AgentCore Evaluations additionally helps a 3rd strategy: code-based evaluators, the place an AWS Lambda operate can be utilized because the evaluator together with your customized code.
Code-based evaluators are splendid when you might have heuristic scoring strategies that don’t require language understanding to confirm. An LLM evaluator can choose whether or not a response “sounds right,” but it surely can not reliably verify {that a} particular pay stub determine of $8,333.33 seems verbatim in a response, or {that a} generated request ID follows the format PTO-2026-NNN. For these deterministic checks, a customized code is quicker, cheaper, and extra dependable. There are 4 conditions the place code-based evaluators are significantly useful:
- Precise information validation: The agent is predicted to return particular values from an information supply, comparable to account balances, transaction IDs, or costs.
- Format compliance: Responses should conform to structural constraints, comparable to size limits, required phrases, or output schemas.
- Enterprise rule enforcement: Insurance policies that require exact interpretation, comparable to whether or not a response appropriately applies a tiered low cost rule or cites the fitting regulatory clause.
- Excessive-volume manufacturing monitoring: Lambda invocations value a fraction of LLM inference, making code-based evaluators the fitting selection when each manufacturing session must be scored constantly at scale.
Making a code-based evaluator
A code-based evaluator is configured as an AWS Lambda operate together with your customized logic. AgentCore passes the agent’s OTel spans to your operate as a structured occasion and expects a lead to return. Your operate extracts no matter data it wants from the spans and returns a rating, a label, and an evidence.
As soon as your Lambda is deployed and granted permission to be invoked by the AgentCore service principal, you register it as an evaluator for AgentCore. As soon as registered, the evaluator ID can be utilized for on-demand analysis.
Establishing AgentCore Evaluations
Configuring the service includes three steps. Choose your agent, select your evaluators, and set your sampling guidelines. Earlier than you start, deploy your agent utilizing AgentCore Runtime and arrange observability by means of OpenTelemetry or OpenInference instrumentation. The AgentCore samples repository on GitHub gives working examples.
Configuring on-line analysis
Create a brand new on-line analysis configuration by means of the AgentCore Evaluations console. Right here, you specify which evaluators to use, which information supply to observe, and what sampling parameters to make use of. For the information supply, choose both an present AgentCore Runtime endpoint or a CloudWatch log group for brokers not hosted on AgentCore Runtime. Then select your evaluators and outline your sampling guidelines.
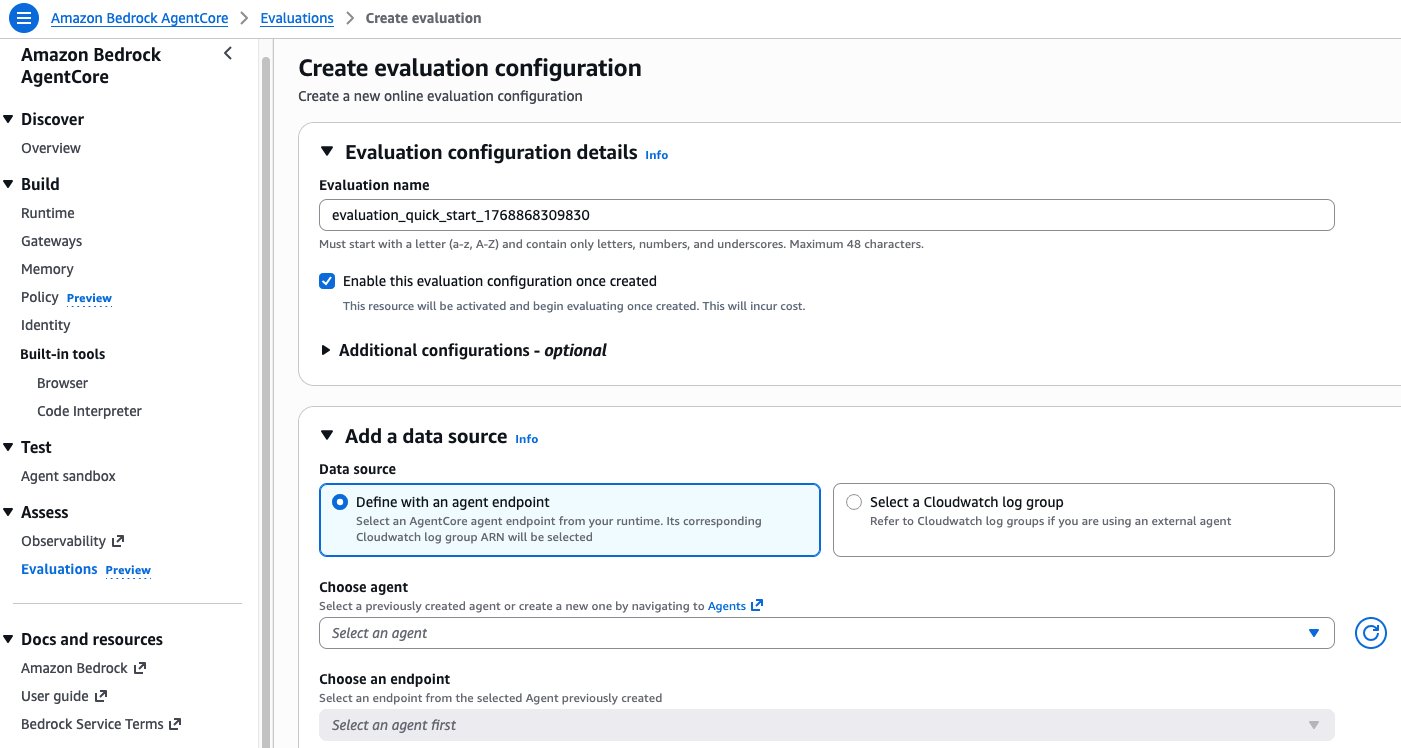
Determine 8: The AgentCore Evaluations console for creating a web-based analysis configuration, together with information supply choice, evaluator task, and sampling guidelines.
You can even create configurations programmatically utilizing the CreateOnlineEvaluationConfig API with a singular configuration title, information supply, listing of evaluators (as much as 10), and IAM service function. The enableOnCreate parameter controls whether or not analysis begins instantly or stays paused, and executionStatus determines whether or not the configuration actively processes traces as soon as enabled. When a configuration is working, any customized evaluators it references turn into locked and can’t be modified or deleted. If it’s essential to change an evaluator, clone it and create a brand new model. On-line analysis outcomes are saved to a devoted CloudWatch log group in JSON format.
Monitoring outcomes
After enabling your configuration, monitor outcomes by means of the AgentCore Observability dashboard in Amazon CloudWatch. Agent-level views show aggregated analysis metrics and developments, and you’ll drill into particular periods and traces to see particular person scores and the reasoning behind every one.
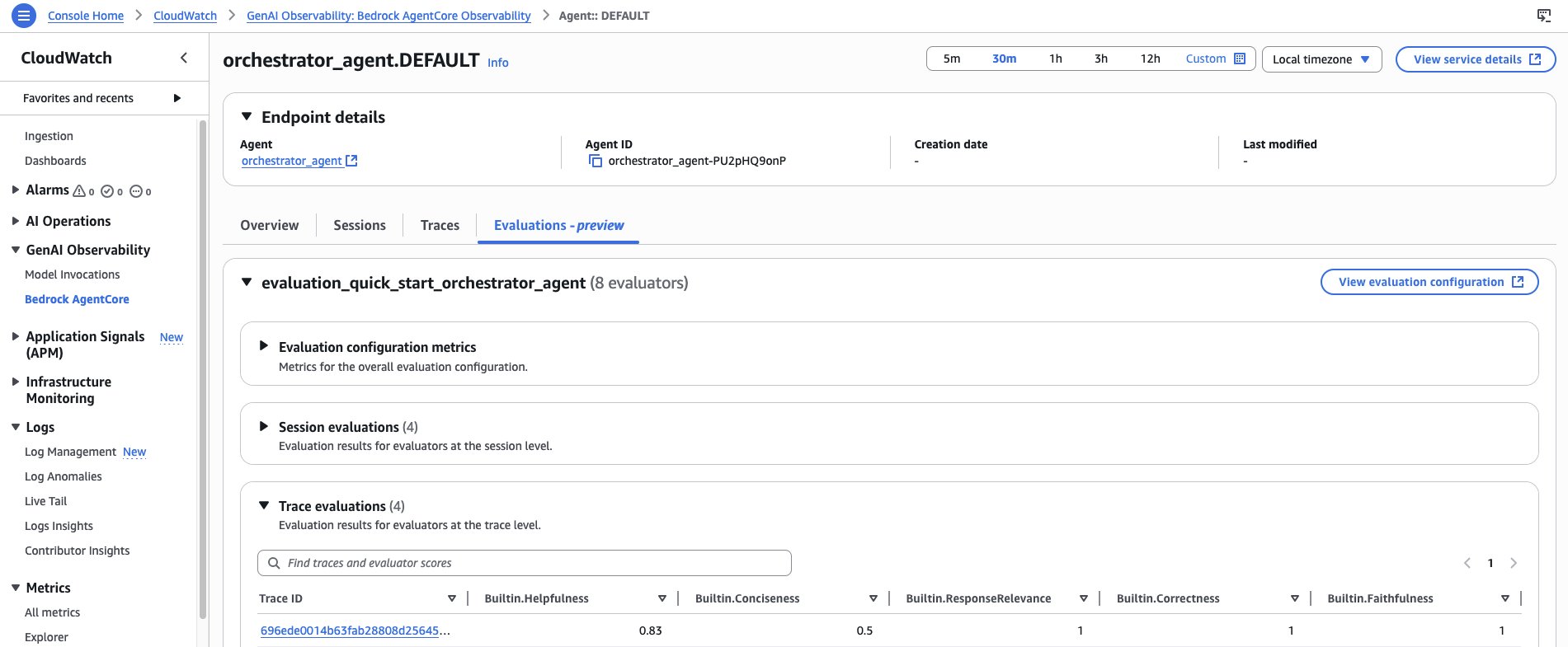
Determine 9: The AgentCore Observability dashboard shows analysis metrics and developments on the agent degree, with drill-down into particular person periods, traces, scores, and choose reasoning.
Drilling into a person hint reveals the analysis scores and detailed explanations for that particular interplay, so groups can confirm choose reasoning and perceive why the agent acquired a specific score.
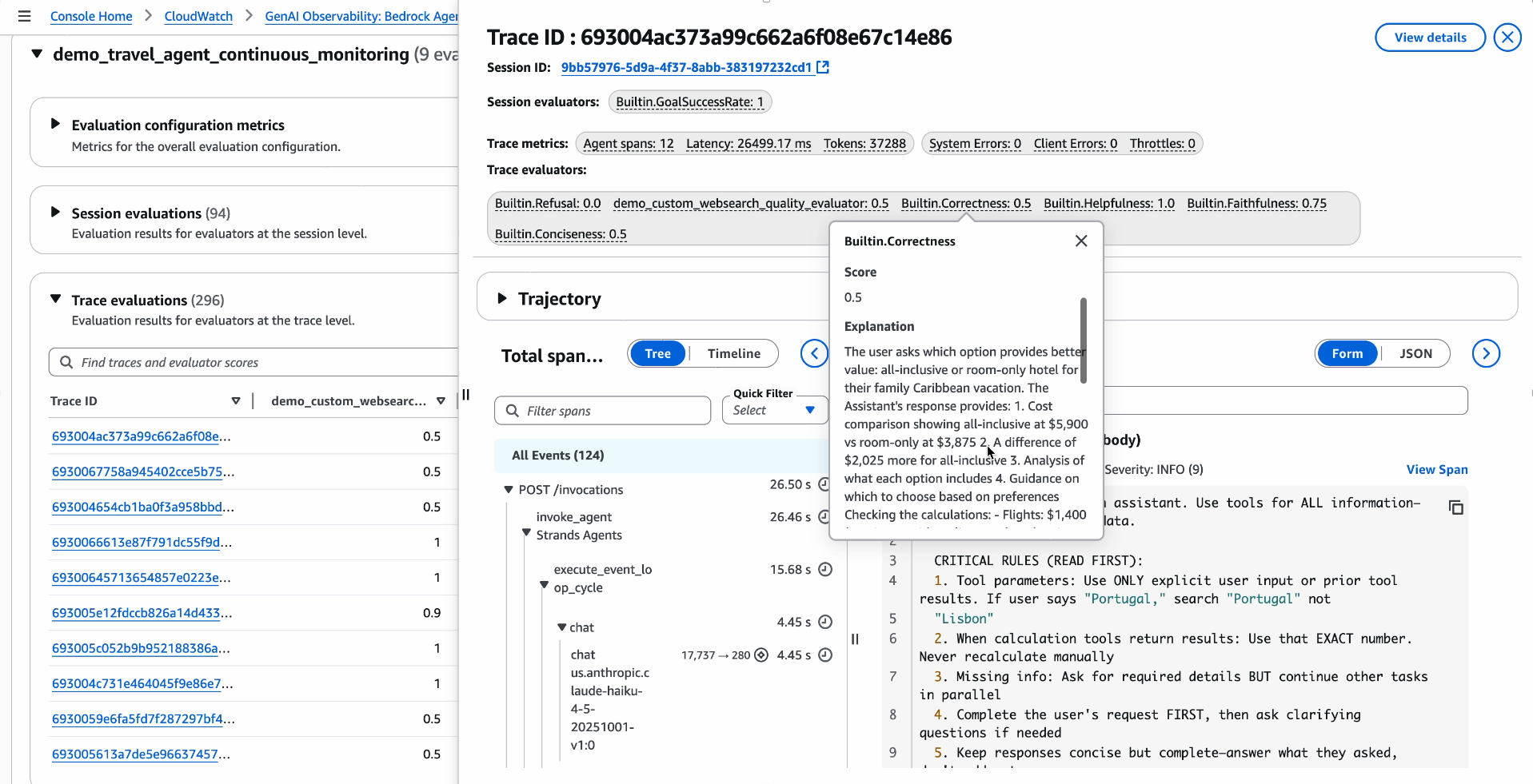
Determine 10: The trace-level view shows analysis scores and explanations immediately on particular person traces, displaying the choose mannequin’s reasoning for every metric.
Utilizing on-demand analysis
For growth and testing, you should utilize on-demand analysis to research particular interactions by deciding on the traces or spans that you just need to look at, making use of your chosen evaluators, and receiving detailed scores with explanations. Outcomes return immediately within the API response, restricted to 10 evaluations per name, with every end result containing the span context, rating, and reasoning. If an analysis partially fails, the response consists of each profitable and failed outcomes with error codes and messages. On-demand analysis works nicely for testing customized evaluators, investigating particular high quality points, and validating fixes earlier than deployment.
Evaluating brokers with floor fact
LLM-as-judge scoring tells you whether or not responses appear right and useful by the requirements of a general-purpose language mannequin. Floor fact analysis takes this additional by letting you specify the reply, the instruments that ought to have been referred to as, and the outcomes the session ought to have achieved. This helps you measure how intently the agent’s precise conduct matches your reference inputs. That is significantly worthwhile throughout growth, when you might have area data about what the fitting conduct is and need to take a look at for particular situations.
AgentCore Evaluations helps three forms of floor fact reference inputs, every consumed by a selected set of evaluators:
| Reference Enter | Evaluator | What it measures |
expected_response |
Builtin.Correctness |
Similarity between the agent’s response and the known-correct reply |
expected_trajectory |
Builtin.TrajectoryExactOrderMatch, Builtin.TrajectoryInOrderMatch, Builtin.TrajectoryAnyOrderMatch |
Whether or not the agent referred to as the fitting instruments in the fitting sequence |
assertions |
Builtin.GoalSuccessRate |
Whether or not the session happy a set of natural-language statements about anticipated outcomes |
These inputs are non-compulsory and impartial. Evaluators that don’t require floor fact comparable to Builtin.Helpfulness and Builtin.ResponseRelevance may be included in the identical name as ground-truth evaluators, and every evaluator reads solely the fields it wants. You’ll be able to provide all three reference inputs concurrently for a complete analysis, or provide solely the subset related to a given situation.
The bedrock-agentcore Python SDK gives two interfaces for floor fact analysis: EvaluationClient for assessing present periods and OnDemandEvaluationRunner for automated dataset analysis.
Analysis Consumer: Evaluating present periods
Analysis Consumer is the fitting selection when you have already got agent periods recorded in CloudWatch and need to consider particular interactions. You present the session ID, the agent ID, your chosen evaluators, a glance again window for CloudWatch span retrieval, and non-compulsory Reference Inputs. The consumer fetches the session’s spans and submits them for analysis. That is nicely suited to growth evaluation, debugging particular agent failures, and validating recognized interactions after immediate or mannequin adjustments.
Analysis Consumer works equally nicely for multi-turn periods. Once you move a session ID from a multi-turn dialog, the consumer fetches all spans for that session and evaluates the whole dialogue. Trajectory evaluators confirm software utilization throughout all turns, aim success assertions apply to the session, and correctness evaluators rating every particular person response towards its corresponding anticipated reply.
On-Demand Analysis Dataset Runner: Automated dataset analysis
On-Demand Analysis Dataset Runner is the fitting selection once you need to consider your agent systematically throughout a curated dataset by invoking the agent for each situation, amassing CloudWatch spans, and scoring ends in a single automated workflow. You outline a Dataset containing multi-turn situations with per-turn and per-scenario floor fact and supply an agent_invoker operate that the runner requires every flip. The runner manages session IDs and handles all coordination between invocation, span assortment, and analysis.
On-Demand Analysis Dataset Runner is nicely suited to CI/CD pipelines the place the identical dataset runs towards each construct, regression testing after immediate or mannequin adjustments, and batch analysis throughout a big corpus of take a look at circumstances earlier than a launch.
The 2 interfaces share the identical evaluators and Reference Inputs schema, so you possibly can develop and validate floor fact take a look at circumstances interactively with Analysis Consumer towards present manufacturing periods, then promote those self same situations into your Analysis Runner dataset for systematic regression testing. The hands-on tutorial within the AgentCore samples repository demonstrates each interfaces end-to-end utilizing an instance agent throughout single-turn and multi-turn situations with all three forms of floor fact reference inputs.
Finest practices
Success standards on your agent usually mix three dimensions: the standard of responses, the latency at which customers obtain them, and the price of inference. AgentCore Evaluations focuses on the standard dimension, whereas operational metrics like latency and value can be found by means of AgentCore Observability in CloudWatch. The next greatest practices are organized across the three analysis ideas described earlier, and mirror patterns that emerge from working with agent analysis at scale.
Proof-driven growth
- Baseline your agent’s efficiency with each artificial and real-world information, and experiment rigorously. Measure earlier than and after each change in order that enhancements are grounded in proof, not instinct. Begin testing early with the take a look at circumstances that you’ve, and construct your corpus constantly. The analysis loop described in Determine 1 makes certain that failures turn into new take a look at circumstances over time.
- Run A/B testing with statistical rigor for each change. Whether or not you’re updating a system immediate, swapping a mannequin, or including a software, evaluate efficiency throughout the identical evaluator set earlier than and after deployment.
- Run repeated trials (no less than 10 per query) organized by class to benchmark reliability and determine specialization alternatives. Variance throughout repeated runs reveals the place your agent is constant and the place it wants work.
Multi-dimensional evaluation
- Outline what success appears like early, utilizing multi-dimensional standards that mirror your agent’s precise objective. Think about which analysis ranges matter most (session, hint, or software) and choose evaluators that map to your online business targets.
- Consider each step within the agent’s workflow, not simply last outcomes. Measuring software choice, parameter accuracy, and response high quality independently offers you the diagnostic precision to repair issues the place they really happen.
- Contain material consultants in designing your metrics, defining job protection, and conducting human-in-the-loop opinions for high quality assurance. SME enter retains your evaluators grounded in real-world expectations and catches blind spots that automated scoring alone can miss.
- Begin with built-in evaluators to ascertain baseline measurements, then create customized evaluators as your wants mature. Calibrate customized evaluator scoring with SMEs for automated judgments align with human expectations in your area.
Steady measurement
- Detect drift by evaluating manufacturing conduct to your take a look at baselines. Arrange CloudWatch alarms on key metrics so that you catch regressions earlier than they attain a broad set of customers.
- Keep in mind that your take a look at dataset evolves together with your agent, your customers, and the adversarial situations you encounter. Replace it repeatedly as edge circumstances emerge in manufacturing and necessities shift.
Troubleshooting frequent Analysis patterns
- The evaluator relationships described earlier helps you interpret scores diagnostically. The next patterns are described for particular situations you might encounter as you scale your software together with steps to resolve them.
- If you happen to discover low scores throughout all evaluators, the difficulty is usually foundational. Begin by reviewing Context Relevance scores to find out whether or not your agent has entry to the knowledge it wants. Verify your agent’s system immediate for readability and completeness; imprecise or contradictory directions have an effect on each downstream conduct. Confirm that software descriptions precisely clarify when and methods to use every software.
- If you happen to discover inconsistent scores for related interactions, it often factors to analysis configuration points fairly than agent issues. If you’re utilizing customized evaluators, examine whether or not your directions are particular sufficient and whether or not every rating degree has clear, distinguishable definitions. Think about reducing the temperature parameter in your customized evaluator’s mannequin configuration to supply extra deterministic scoring.
- If you happen to see excessive Instrument Choice Accuracy however low Objective Success Price, your agent selects applicable instruments however fails to finish person targets. This sample suggests that you just may want extra instruments to deal with sure person requests, or your agent struggles with duties requiring a number of sequential software calls. Verify Helpfulness scores as nicely; the agent may use instruments appropriately however clarify outcomes poorly.
- If evaluations are gradual or failing attributable to throttling, decrease your sampling fee to guage a smaller share of periods. Cut back your evaluator depend. For customized evaluators, request quota will increase on your chosen mannequin, or change to a mannequin with increased default quotas.
Conclusion
On this publish, we confirmed how Amazon Bedrock AgentCore Evaluations helps groups transfer from reactive debugging to systematic high quality administration for AI brokers. As a totally managed service, it handles the analysis fashions, inference infrastructure, and information pipelines that groups would in any other case have to construct and preserve for every agent. With on-demand analysis anchoring the event workflow and on-line analysis offering steady manufacturing perception, high quality turns into a measurable and improvable property all through the agent lifecycle. The evaluator relationships and diagnostic patterns give a framework not simply to attain brokers however for understanding the place and why high quality points happen and the place to focus enchancment efforts.
To discover AgentCore Evaluations intimately, watch the public preview launch session from AWS re:Invent 2025 for a walkthrough with reside demos. Go to the Amazon Bedrock AgentCore samples repository on GitHub for hands-on tutorials. For technical particulars on configuration and API utilization, see the AgentCore Evaluations documentation. You can even assessment service limits and pricing.
In regards to the authors


{kind=link}