Companies depend on exact, real-time insights to make vital selections. Nonetheless, enabling non-technical customers to entry proprietary or organizational information with out technical experience stays a problem. Textual content-to-SQL bridges this hole by producing exact, schema-specific queries that empower quicker decision-making and foster a data-driven tradition. The issue lies in acquiring deterministic solutions—exact, constant outcomes wanted for operations resembling producing actual counts or detailed reviews—from proprietary or organizational information. Generative AI provides a number of approaches to question information, however choosing the precise technique is vital to realize accuracy and reliability.
This put up evaluates the important thing choices for querying information utilizing generative AI, discusses their strengths and limitations, and demonstrates why Textual content-to-SQL is the only option for deterministic, schema-specific duties. We present find out how to successfully use Textual content-to-SQL utilizing Amazon Nova, a basis mannequin (FM) obtainable in Amazon Bedrock, to derive exact and dependable solutions out of your information.
Choices for querying information
Organizations have a number of choices for querying information, and the selection depends upon the character of the information and the required outcomes. This part evaluates the next approaches to supply readability on when to make use of every and why Textual content-to-SQL is perfect for deterministic, schema-based duties:
- Retrieval Augmented Era (RAG):
- Use case – Supreme for extracting insights from unstructured or semi-structured sources like paperwork or articles.
- Strengths – Handles various information codecs and offers narrative-style responses.
- Limitations – Probabilistic solutions can differ, making it unsuitable for deterministic queries, resembling retrieving actual counts or matching particular schema constraints.
- Instance – “Summarize suggestions from product opinions.”
- Generative enterprise intelligence (BI):
- Use case – Appropriate for high-level insights and abstract technology primarily based on structured and unstructured information.
- Strengths – Delivers narrative insights for decision-making and developments.
- Limitations – Lacks the precision required for schema-specific or operational queries. Outcomes typically differ in phrasing and focus.
- Instance – “What had been the important thing drivers of gross sales development final quarter?”
- Textual content-to-SQL:
- Use case – Excels in querying structured organizational information straight from relational schemas.
- Strengths – Offers deterministic, reproducible outcomes for particular, schema-dependent queries. Supreme for exact operations resembling filtering, counting, or aggregating information.
- Limitations – Requires structured information and predefined schemas.
- Instance – “What number of sufferers recognized with diabetes visited clinics in New York Metropolis final month?”
In situations demanding precision and consistency, Textual content-to-SQL outshines RAG and generative BI by delivering correct, schema-driven outcomes. These traits make it the best resolution for operational and structured information queries.
Resolution overview
This resolution makes use of the Amazon Nova Lite and Amazon Nova Professional massive language fashions (LLMs) to simplify querying proprietary information with pure language, making it accessible to non-technical customers.
Amazon Bedrock is a totally managed service that simplifies constructing and scaling generative AI functions by offering entry to main FMs by a single API. It permits builders to experiment with and customise these fashions securely and privately, integrating generative AI capabilities into their functions with out managing infrastructure.
Inside this method, Amazon Nova represents a brand new technology of FMs delivering superior intelligence and industry-leading price-performance. These fashions, together with Amazon Nova Lite and Amazon Nova Professional, are designed to deal with varied duties resembling textual content, picture, and video understanding, making them versatile instruments for various functions.
You’ll find the deployment code and detailed directions in our GitHub repo.
The answer consists of the next key options:
- Dynamic schema context – Retrieves the database schema dynamically for exact question technology
- SQL question technology – Converts pure language into SQL queries utilizing the Amazon Nova Professional LLM
- Question execution – Runs queries on organizational databases and retrieves outcomes
- Formatted responses – Processes uncooked question outcomes into user-friendly codecs utilizing the Amazon Nova Lite LLM
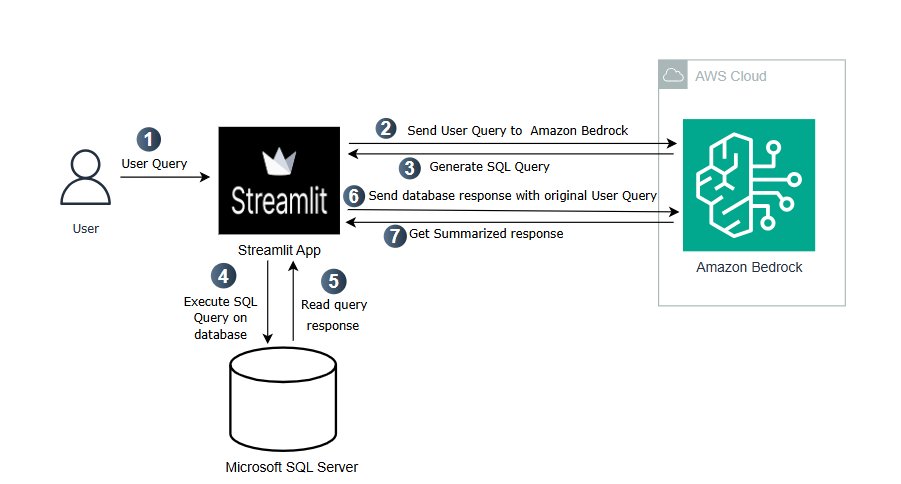
The next diagram illustrates the answer structure.

On this resolution, we use Amazon Nova Professional and Amazon Nova Lite to make the most of their respective strengths, facilitating environment friendly and efficient processing at every stage:
- Dynamic schema retrieval and SQL question technology – We use Amazon Nova Professional to deal with the interpretation of pure language inputs into SQL queries. Its superior capabilities in complicated reasoning and understanding make it well-suited for precisely decoding consumer intents and producing exact SQL statements.
- Formatted response technology – After we run the SQL queries, the uncooked outcomes are processed utilizing Amazon Nova Lite. This mannequin effectively codecs the information into user-friendly outputs, making the data accessible to non-technical customers. Its pace and cost-effectiveness are advantageous for this stage, the place fast processing and easy presentation are key.
By strategically deploying Amazon Nova Professional and Amazon Nova Lite on this method, the answer makes certain that every element operates optimally, balancing efficiency, accuracy, and cost-effectiveness.
Conditions
Full the next prerequisite steps:
- Set up the AWS Command Line Interface (AWS CLI). For directions, seek advice from Putting in or updating to the newest model of the AWS CLI.
- Configure the fundamental settings that the AWS CLI makes use of to work together with AWS. For extra info, see Configuration and credential file settings within the AWS CLI.
- Be certain Amazon Bedrock is enabled in your AWS account.
- Acquire entry to Amazon Nova Lite and Amazon Nova Professional.
- Set up Python 3.9 or later, together with required libraries (Streamlit model 1.8.0 or later, Boto3, pymssql, and atmosphere administration packages).
- Create a Microsoft SQL Server (model 2016 or later) database with credentials to attach.
- Create a secret in AWS Secrets and techniques Supervisor for database credentials and title it
mssql_secrets. For directions, see Create an AWS Secrets and techniques Supervisor secret.
- Create a secret in AWS Secrets and techniques Supervisor for database credentials and title it
Our pattern code makes use of a Microsoft SQL Server database, however this resolution helps the next providers:
For extra details about stipulations, seek advice from the GitHub repo.
Arrange the event atmosphere
Within the command immediate, navigate to the folder the place the code exists and run the next command:
This command installs the required libraries to run the applying.
Load the pattern dataset within the database
Ensure you have created a secret in Secrets and techniques Supervisor named mssql_secrets as talked about within the stipulations. Should you named your secret one thing else, replace the code in app.py (line 29) and load_data.py (line 22).
After you create the key, run the next command from the code folder:
This command creates a database named Gross sales with tables Merchandise, Prospects, and Orders and masses the pattern information in these tables.
Run the applying
To run the applying, execute the next command:
Instance queries
On this part, we discover some pattern queries.
For our first question, we ask “Who’re the purchasers who purchased smartphones?” This generates the next SQL:
We get the next formatted response:
Alice Johnson, who purchased 1 smartphone on October 14th, 2023.Ivy Martinez, who purchased 2 smartphones on October fifteenth, 2023.

Subsequent, we ask “What number of smartphones are in inventory?” This generates the next SQL:
We get the response “There are 100 smartphones at present in inventory.”

Code execution circulation
On this part, we discover the code execution circulation. The code reference is from the GitHub repo. Don’t run the totally different elements of the code individually.
Retrieve schema dynamically
Use INFORMATION_SCHEMA views to extract schema particulars dynamically (code reference from app.py):
Dynamic schema retrieval adapts routinely to adjustments by querying metadata tables for up to date schema particulars, resembling desk names and column varieties. This facilitates seamless integration of schema updates into the Textual content-to-SQL system, lowering guide effort and enhancing scalability.
Check this operate to confirm it adapts routinely when schema adjustments happen.
Earlier than producing SQL, fetch schema particulars for the related tables to facilitate correct question building.
Generate a SQL question utilizing Amazon Nova Professional
Ship the consumer question and schema context to Amazon Nova Professional (code reference from sql_generator.py):
This code establishes a structured context for a text-to-SQL use case, guiding Amazon Nova Professional to generate SQL queries primarily based on a predefined database schema. It offers consistency by defining a static database context that clarifies desk names, columns, and relationships, serving to stop ambiguity in question formation. Queries are required to reference the vw_sales view, standardizing information extraction for analytics and reporting. Moreover, at any time when relevant, the generated queries should embrace quantity-related fields, ensuring that enterprise customers obtain key insights on product gross sales, inventory ranges, or transactional counts. To reinforce search flexibility, the LLM is instructed to make use of the LIKE operator in WHERE situations as a substitute of actual matches, permitting for partial matches and accommodating variations in consumer enter. By implementing these constraints, the code optimizes Textual content-to-SQL interactions, offering structured, related, and business-aligned question technology for gross sales information evaluation.
Execute a SQL question
Run the SQL question on the database and seize the consequence (code reference from app.py):
Format the question outcomes utilizing Amazon Nova Lite
Ship the database consequence from the SQL question to Amazon Nova Lite to format it in a human-readable format and print it on the Streamlit UI (code reference from app.py):
Clear up
Comply with these steps to wash up assets in your AWS atmosphere and keep away from incurring future prices:
- Clear up database assets:
- Clear up safety assets:
- Clear up the frontend (provided that internet hosting the Streamlit utility on Amazon EC2):
- Cease the EC2 occasion internet hosting the Streamlit utility.
- Delete related storage volumes.
- Clear up further assets (if relevant):
- Take away Elastic Load Balancers.
- Delete digital non-public cloud (VPC) configurations.
- Examine the AWS Administration Console to verify all assets have been deleted.
Conclusion
Textual content-to-SQL with Amazon Bedrock and Amazon Nova LLMs offers a scalable resolution for deterministic, schema-based querying. By delivering constant and exact outcomes, it empowers organizations to make knowledgeable selections, enhance operational effectivity, and scale back reliance on technical assets.
For a extra complete instance of a Textual content-to-SQL resolution constructed on Amazon Bedrock, discover the GitHub repo Setup Amazon Bedrock Agent for Textual content-to-SQL Utilizing Amazon Athena with Streamlit. This open supply venture demonstrates find out how to use Amazon Bedrock and Amazon Nova LLMs to construct a strong Textual content-to-SQL agent that may generate complicated queries, self-correct, and question various information sources.
Begin experimenting with Textual content-to-SQL use instances as we speak by getting began with Amazon Bedrock.
In regards to the authors
 Mansi Sharma is a Options Architect for Amazon Net Providers. Mansi is a trusted technical advisor serving to enterprise clients architect and implement cloud options at scale. She drives buyer success by technical management, architectural steerage, and progressive problem-solving whereas working with cutting-edge cloud applied sciences. Mansi makes a speciality of generative AI utility growth and serverless applied sciences.
Mansi Sharma is a Options Architect for Amazon Net Providers. Mansi is a trusted technical advisor serving to enterprise clients architect and implement cloud options at scale. She drives buyer success by technical management, architectural steerage, and progressive problem-solving whereas working with cutting-edge cloud applied sciences. Mansi makes a speciality of generative AI utility growth and serverless applied sciences.
 Marie Yap is a Principal Options Architect for Amazon Net Providers. On this function, she helps varied organizations start their journey to the cloud. She additionally makes a speciality of analytics and trendy information architectures.
Marie Yap is a Principal Options Architect for Amazon Net Providers. On this function, she helps varied organizations start their journey to the cloud. She additionally makes a speciality of analytics and trendy information architectures.



{kind=link}