Within the quickly evolving panorama of synthetic intelligence, Retrieval Augmented Technology (RAG) has emerged as a game-changer, revolutionizing how Basis Fashions (FMs) work together with organization-specific information. As companies more and more depend on AI-powered options, the necessity for correct, context-aware, and tailor-made responses has by no means been extra crucial.
Enter the highly effective trio of Amazon Bedrock, LlamaIndex, and RAGAS– a cutting-edge mixture that’s set to redefine the analysis and optimization of RAG responses. This weblog submit delves into how these modern instruments synergize to raise the efficiency of your AI functions, guaranteeing they not solely meet however exceed the exacting requirements of enterprise-level deployments.
Whether or not you’re a seasoned AI practitioner or a enterprise chief exploring the potential of generative AI, this information will equip you with the data and instruments to:
- Harness the complete potential of Amazon Bedrock sturdy basis fashions
- Make the most of RAGAS’s complete analysis metrics for RAG methods
On this submit, we’ll discover the way to leverage Amazon Bedrock, LlamaIndex, and RAGAS to reinforce your RAG implementations. You’ll be taught sensible strategies to judge and optimize your AI methods, enabling extra correct, context-aware responses that align together with your group’s particular wants. Let’s dive in and uncover how these highly effective instruments might help you construct simpler and dependable AI-powered options.
RAG Analysis
RAG analysis is necessary to make sure that RAG fashions produce correct, coherent, and related responses. By analyzing the retrieval and generator parts each collectively and independently, RAG analysis helps establish bottlenecks, monitor efficiency, and enhance the general system. Present RAG pipelines often make use of similarity-based metrics equivalent to ROUGE, BLEU, and BERTScore to evaluate the standard of the generated responses, which is important for refining and enhancing the mannequin’s capabilities.
Above talked about probabilistic metrics ROUGE, BLEU, and BERTScore have limitations in assessing relevance and detecting hallucinations. Extra subtle metrics are wanted to judge factual alignment and accuracy.
Consider RAG parts with Basis fashions
We will additionally use a Basis Mannequin as a choose to compute numerous metrics for each retrieval and technology. Listed below are some examples of those metrics:
- Retrieval element
- Context precision – Evaluates whether or not the entire ground-truth related objects current within the contexts are ranked increased or not.
- Context recall – Ensures that the context comprises all related info wanted to reply the query.
- Generator element
- Faithfulness – Verifies that the generated reply is factually correct based mostly on the supplied context, serving to to establish errors or “hallucinations.”
- Reply relavancy : Measures how properly the reply matches the query. Larger scores imply the reply is full and related, whereas decrease scores point out lacking or redundant info.

Overview of answer
This submit guides you thru the method of assessing high quality of RAG response with analysis framework equivalent to RAGAS and LlamaIndex with Amazon Bedrock.
On this submit, we’re additionally going to leverage Langchain to create a pattern RAG software.
Amazon Bedrock is a totally managed service that gives a alternative of high-performing Basis Fashions (FMs) from main AI corporations like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon by way of a single API, together with a broad set of capabilities you’ll want to construct generative AI functions with safety, privateness, and accountable AI.
The Retrieval Augmented Technology Evaluation (RAGAS) framework gives a number of metrics to judge every a part of the RAG system pipeline, figuring out areas for enchancment. It makes use of basis fashions to check particular person parts, aiding in pinpointing modules for growth to reinforce total outcomes.
LlamaIndex is a framework for constructing LLM functions. It simplifies information integration from numerous sources and offers instruments for information indexing, engines, brokers, and software integrations. Optimized for search and retrieval, it streamlines querying LLMs and retrieving paperwork. This weblog submit focuses on utilizing its Observability/Analysis modules.
LangChain is an open-source framework that simplifies the creation of functions powered by basis fashions. It offers instruments for chaining LLM operations, managing context, and integrating exterior information sources. LangChain is primarily used for constructing chatbots, question-answering methods, and different AI-driven functions that require advanced language processing capabilities.
Diagram Structure
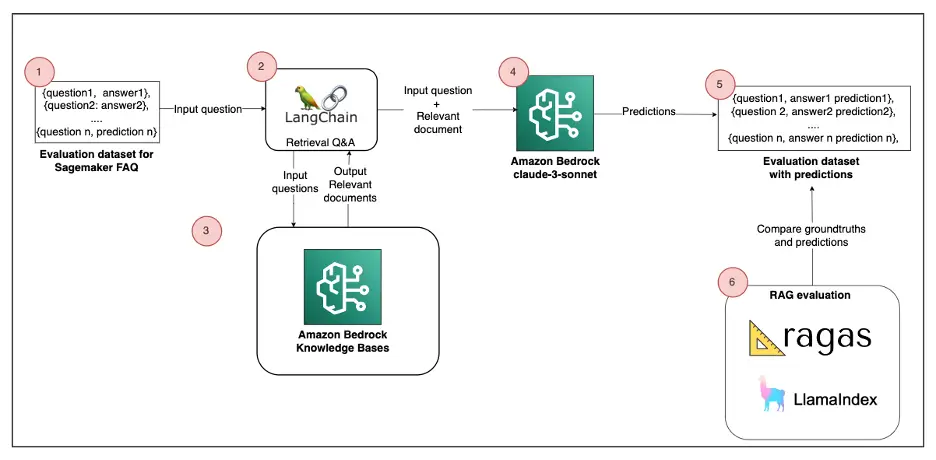
The next diagram is a high-level reference structure that explains how one can consider the RAG answer with RAGAS or LlamaIndex.
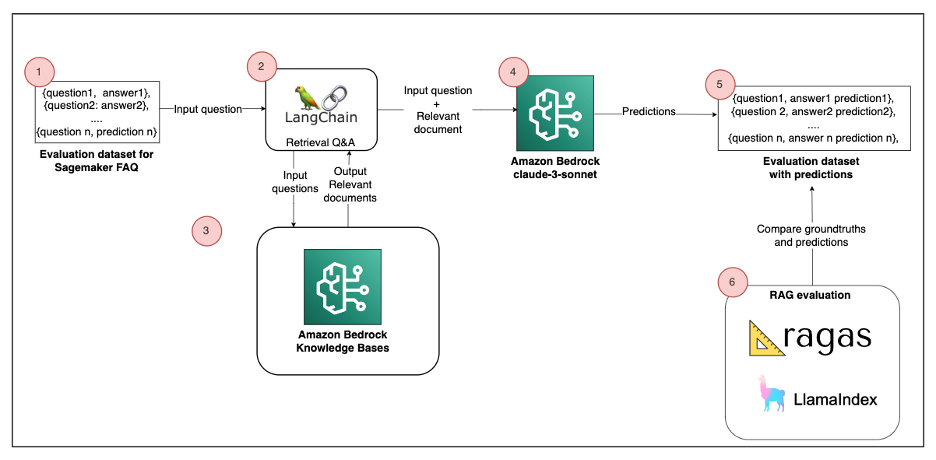
The answer consists of the next parts:
- Analysis dataset – The supply information for the RAG comes from the Amazon SageMaker FAQ, which represents 170 question-answer pairs. This corresponds to Step 1 within the structure diagram.
- Construct pattern RAG – Paperwork are segmented into chunks and saved in an Amazon Bedrock Information Bases (Steps 2–4). We use Langchain Retrieval Q&A to reply person queries. This course of retrieves related information from an index at runtime and passes it to the Basis Mannequin (FM).
- RAG analysis – To evaluate the standard of the Retrieval-Augmented Technology (RAG) answer, we are able to use each RAGAS and LlamaIndex. An LLM performs the analysis by evaluating its predictions with floor truths (Steps 5–6).
It’s essential to observe the supplied pocket book to breed the answer. We elaborate on the principle code parts on this submit.
Conditions
To implement this answer, you want the next:
- An AWS accountwith privileges to create AWS Id and Entry Administration (IAM) roles and insurance policies. For extra info, see Overview of entry administration: Permissions and insurance policies.
- Entry enabled for the Amazon Titan Embeddings G1 – Textual content mannequin and Anthropic Claude 3 Sonnet on Amazon Bedrock. For directions, see Mannequin entry.
- Run the prerequisite code supplied within the Python
Ingest FAQ information
Step one is to ingest the SageMaker FAQ information. For this function, LangChain offers a WebBaseLoader object to load textual content from HTML webpages right into a doc format. Then we cut up every doc in a number of chunks of two,000 tokens with a 100-token overlap. See the next code beneath:
text_chunks = split_document_from_url(SAGEMAKER_URL, chunck_size= 2000, chunk_overlap=100)
retriever_db= get_retriever(text_chunks, bedrock_embeddings)Arrange embeddings and LLM with Amazon Bedrock and LangChain
In an effort to construct a pattern RAG software, we’d like an LLM and an embedding mannequin:
- LLM – Anthropic Claude 3 Sonnet
- Embedding – Amazon Titan Embeddings – Textual content V2
This code units up a LangChain software utilizing Amazon Bedrock, configuring embeddings with Titan and a Claude 3 Sonnet mannequin for textual content technology with particular parameters for controlling the mannequin’s output. See the next code beneath from the pocket book :
from botocore.consumer import Config
from langchain.llms.bedrock import Bedrock
from langchain_aws import ChatBedrock
from langchain.embeddings import BedrockEmbeddings
from langchain.retrievers.bedrock import AmazonKnowledgeBasesRetriever
from langchain.chains import RetrievalQA
import nest_asyncio
nest_asyncio.apply()
#URL to fetch the doc
SAGEMAKER_URL="https://aws.amazon.com/sagemaker/faqs/"
#Bedrock parameters
EMBEDDING_MODEL="amazon.titan-embed-text-v2:0"
BEDROCK_MODEL_ID="anthropic.claude-3-sonnet-20240229-v1:0"
bedrock_embeddings = BedrockEmbeddings(model_id=EMBEDDING_MODEL,consumer=bedrock_client)
model_kwargs = {
"temperature": 0,
"top_k": 250,
"top_p": 1,
"stop_sequences": ["nnHuman:"]
}
llm_bedrock = ChatBedrock(
model_id=BEDROCK_MODEL_ID,
model_kwargs=model_kwargs
)Arrange Information Bases
We are going to create Amazon Bedrock knowledgebases Internet Crawler datasource and course of Sagemaker FAQ information.
Within the code beneath, we load the embedded paperwork in Information bases and we arrange the retriever with LangChain:
from utils import split_document_from_url, get_bedrock_retriever
from botocore.exceptions import ClientError
text_chunks = split_document_from_url(SAGEMAKER_URL, chunck_size= 2000, chunk_overlap=100)
retriever_db= get_bedrock_retriever(text_chunks, area)Construct a Q&A series to question the retrieval API
After the database is populated, create a Q&A retrieval chain to carry out query answering with context extracted from the vector retailer. You additionally outline a immediate template following Claude immediate engineering pointers. See the next code beneath from the pocket book:
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
system_prompt = (
"Use the given context to reply the query. "
"If you do not know the reply, say you do not know. "
"Use three sentence most and preserve the reply concise and brief. "
"Context: {context}"
)
prompt_template = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}")
]
)
question_answer_chain = create_stuff_documents_chain(llm_bedrock, prompt_template)
chain = create_retrieval_chain(retriever_db, question_answer_chain)Construct Dataset to judge RAG software
To judge a RAG software, we’d like a mixture of the next datasets:
- Questions – The person question that serves as enter to the RAG pipeline
- Context – The data retrieved from enterprise or exterior information sources based mostly on the supplied question
- Solutions – The responses generated by LLMs
- Floor truths – Human-annotated, splendid responses for the questions that can be utilized because the benchmark to check towards the LLM-generated solutions
We’re prepared to judge the RAG software. As describe within the introduction, we choose 3 metrics to evaluate our RAG answer:
- Faithfulness
- Reply Relevancy
- Reply Correctness
For extra info, confer with Metrics.
This step includes defining an analysis dataset with a set of floor fact questions and solutions. For this submit, we select 4 random questions from the SageMaker FAQ. See the next code beneath from the pocket book:
EVAL_QUESTIONS = [
"Can I stop a SageMaker Autopilot job manually?",
"Do I get charged separately for each notebook created and run in SageMaker Studio?",
"Do I get charged for creating and setting up an SageMaker Studio domain?",
"Will my data be used or shared to update the base model that is offered to customers using SageMaker JumpStart?",
]
#Defining the bottom fact solutions for every query
EVAL_ANSWERS = [
"Yes. You can stop a job at any time. When a SageMaker Autopilot job is stopped, all ongoing trials will be stopped and no new trial will be started.",
"""No. You can create and run multiple notebooks on the same compute instance.
You pay only for the compute that you use, not for individual items.
You can read more about this in our metering guide.
In addition to the notebooks, you can also start and run terminals and interactive shells in SageMaker Studio, all on the same compute instance.""",
"No, you don’t get charged for creating or configuring an SageMaker Studio domain, including adding, updating, and deleting user profiles.",
"No. Your inference and training data will not be used nor shared to update or train the base model that SageMaker JumpStart surfaces to customers."
]Analysis of RAG with RAGAS
Evaluating the RAG answer requires to check LLM predictions with floor fact solutions. To take action, we use the batch() perform from LangChain to carry out inference on all questions inside our analysis dataset.
Then we are able to use the consider() perform from RAGAS to carry out analysis on every metric (reply relevancy, faithfulness and reply corectness). It makes use of an LLM to compute metrics. Be at liberty to make use of different Metrics from RAGAS.
See the next code beneath from the pocket book:
from ragas.metrics import answer_relevancy, faithfulness, answer_correctness
from ragas import consider
#Batch invoke and dataset creation
result_batch_questions = chain.batch([{"input": q} for q in EVAL_QUESTIONS])
dataset= build_dataset(EVAL_QUESTIONS,EVAL_ANSWERS,result_batch_questions, text_chunks)
end result = consider(dataset=dataset, metrics=[ answer_relevancy, faithfulness, answer_correctness ],llm=llm_bedrock, embeddings=bedrock_embeddings, raise_exceptions=False )
df = end result.to_pandas()
df.head()
The next screenshot reveals the analysis outcomes and the RAGAS reply relevancy rating.
Reply Relevancy
Within the answer_relevancy_score column, a rating nearer to 1 signifies the response generated is related to the enter question.
Faithfulness
Within the second column, the primary question end result has a decrease faithfulness_score (0.2), which signifies the responses will not be derived from the context and are hallucinations. The remainder of the question outcomes have a better faithfulness_score (1.0), which signifies the responses are derived from the context.
Reply Correctness
Within the final column answer_correctness, the second and final row have excessive reply correctness, which means that reply supplied by the LLM is nearer to to from the groundtruth.
Analysis of RAG with LlamaIndex
LlamaIndex, much like Ragas, offers a complete RAG (Retrieval-Augmented Technology) analysis module. This module gives a wide range of metrics to evaluate the efficiency of your RAG system. The analysis course of generates two key outputs:
- Suggestions: The choose LLM (Language Mannequin) offers detailed analysis suggestions within the type of a string, providing qualitative insights into the system’s efficiency.
- Rating: This numerical worth signifies how properly the reply meets the analysis standards. The scoring system varies relying on the precise metric being evaluated. For instance, metrics like Reply Relevancy and Faithfulness are usually scored on a scale from 0 to 1.
These outputs enable for each qualitative and quantitative evaluation of your RAG system’s efficiency, enabling you to establish areas for enchancment and monitor progress over time.
The next is a code pattern from the pocket book:
from llama_index.llms.bedrock import Bedrock
from llama_index.core.analysis import (
AnswerRelevancyEvaluator,
CorrectnessEvaluator,
FaithfulnessEvaluator
)
from utils import evaluate_llama_index_metric
bedrock_llm_llama = Bedrock(mannequin=BEDROCK_MODEL_ID)
faithfulness= FaithfulnessEvaluator(llm=bedrock_llm_llama)
answer_relevancy= AnswerRelevancyEvaluator(llm=bedrock_llm_llama)
correctness= CorrectnessEvaluator(llm=bedrock_llm_llama)Reply Relevancy
df_answer_relevancy= evaluate_llama_index_metric(answer_relevancy, dataset)
df_answer_relevancy.head()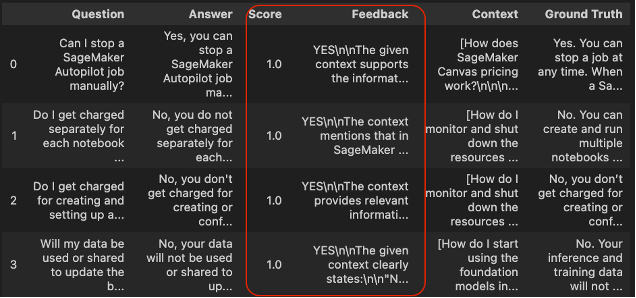
The column Rating defines the end result for the answer_relevancy analysis standards. All passing values are set to 1, which means that every one predictions are related with the context retrieved.
Moreover, the column Suggestions offers a transparent rationalization of the results of the passing rating. We will observe that every one solutions align with the context extracted from the retriever.
Reply Correctness
df_correctness= evaluate_llama_index_metric(correctness, dataset)
df_correctness.head()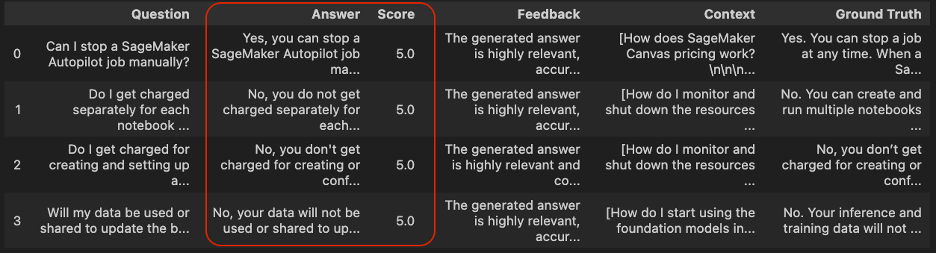
All values from the column Rating are set to five.0, which means that every one predictions are coherent with floor fact solutions.
Faithfulness
The next screenshot reveals the analysis outcomes for reply faithfulness.
df_faithfulness= evaluate_llama_index_metric(faithfulness, dataset)
df_faithfulness.head()
All values from the Rating column are set to 1.0, which suggests all solutions generated by LLM are coherent given the context retrieved.
Conclusion
Whereas Basis Fashions supply spectacular generative capabilities, their effectiveness in addressing organization-specific queries has been a persistent problem. The Retrieval Augmented Technology framework emerges as a robust answer, bridging this hole by enabling LLMs to leverage exterior, organization-specific information sources.
To really unlock the potential of RAG pipelines, the RAGAS framework, together with LlamaIndex, offers a complete analysis answer. By meticulously assessing each retrieval and technology parts, this method empowers organizations to pinpoint areas for enchancment and refine their RAG implementations. The end result? Responses that aren’t solely factually correct but in addition extremely related to person queries.
By adopting this holistic analysis method, enterprises can totally harness the transformative energy of generative AI functions. This not solely maximizes the worth derived from these applied sciences but in addition paves the best way for extra clever, context-aware, and dependable AI methods that may actually perceive and tackle a corporation’s distinctive wants.
As we proceed to push the boundaries of what’s attainable with AI, instruments like Amazon Bedrock, LlamaIndex, and RAGAS will play a pivotal position in shaping the way forward for enterprise AI functions. By embracing these improvements, organizations can confidently navigate the thrilling frontier of generative AI, unlocking new ranges of effectivity, perception, and aggressive benefit.
For additional exploration, readers interested by enhancing the reliability of AI-generated content material might need to look into Amazon Bedrock’s Guardrails function, which gives further instruments just like the Contextual Grounding Verify.
In regards to the authors
 Madhu is a Senior Accomplice Options Architect specializing in worldwide public sector cybersecurity companions. With over 20 years in software program design and growth, he collaborates with AWS companions to make sure prospects implement options that meet strict compliance and safety aims. His experience lies in constructing scalable, extremely accessible, safe, and resilient functions for various enterprise wants.
Madhu is a Senior Accomplice Options Architect specializing in worldwide public sector cybersecurity companions. With over 20 years in software program design and growth, he collaborates with AWS companions to make sure prospects implement options that meet strict compliance and safety aims. His experience lies in constructing scalable, extremely accessible, safe, and resilient functions for various enterprise wants.
 Babu Kariyaden Parambath is a Senior AI/ML Specialist at AWS. At AWS, he enjoys working with prospects in serving to them establish the correct enterprise use case with enterprise worth and clear up it utilizing AWS AI/ML options and companies. Previous to becoming a member of AWS, Babu was an AI evangelist with 20 years of various trade expertise delivering AI pushed enterprise worth for patrons.
Babu Kariyaden Parambath is a Senior AI/ML Specialist at AWS. At AWS, he enjoys working with prospects in serving to them establish the correct enterprise use case with enterprise worth and clear up it utilizing AWS AI/ML options and companies. Previous to becoming a member of AWS, Babu was an AI evangelist with 20 years of various trade expertise delivering AI pushed enterprise worth for patrons.



{kind=link}