Amazon Bedrock Data Bases is a completely managed functionality that helps implement whole Retrieval Augmented Technology (RAG) workflows from ingestion to retrieval and immediate augmentation with out having to construct customized integrations to information sources and handle information flows.
There is no such thing as a single technique to optimize information base efficiency: every use case is impacted otherwise by configuration parameters. As such, it’s necessary to check usually and iterate rapidly to determine the perfect configuration for every use case.
On this publish, we focus on learn how to consider the efficiency of your information base, together with the metrics and information to make use of for analysis. We additionally handle a number of the ways and configuration modifications that may enhance particular metrics.
Measure the efficiency of your information base
RAG is a fancy AI system, combining a number of vital steps. With a purpose to determine what’s impacting the efficiency of the pipeline, it’s necessary to judge every step independently. The information base analysis framework decomposes the analysis into the next phases:
- Retrieval – The method of retrieving related components of paperwork primarily based on a question and including the retrieved parts as context to the ultimate immediate for the information base
- Technology – Sending the consumer’s immediate and the retrieved context to a big language mannequin (LLM) after which sending the output from the LLM again to the consumer
The next diagram illustrates the usual steps in a RAG pipeline.

To see this analysis framework in motion, open the Amazon Bedrock console, and within the navigation pane, select Evaluations. Select the Data Bases tab to evaluation the analysis.

Consider the retrieval
We suggest initially evaluating the retrieval course of independently, as a result of the accuracy and high quality of this foundational stage can considerably influence downstream efficiency metrics within the RAG workflow, doubtlessly introducing errors or biases that propagate via subsequent pipeline phases.

There are two metrics used to judge retrieval:
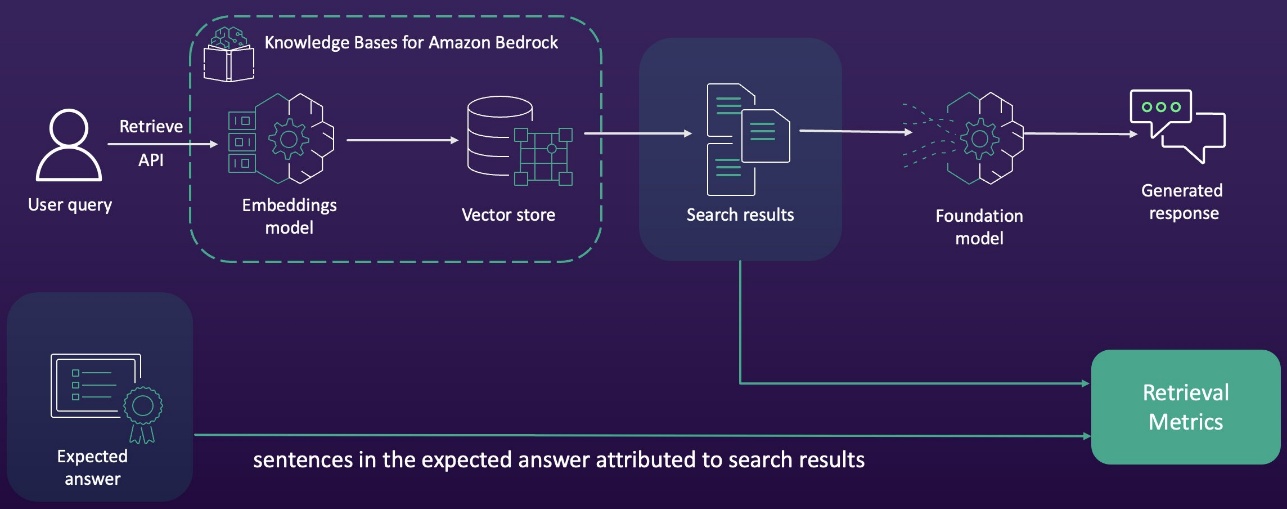
- Context relevance – Evaluates whether or not the retrieved data straight addresses the question’s intent. It focuses on precision of the retrieval system.
- Context protection – Measures how comprehensively the retrieved texts cowl the anticipated floor reality. It requires floor reality texts for comparability to evaluate recall and completeness of retrieved data.
Context relevance and context protection metrics are compiled by evaluating search outcomes from the RAG pipeline with anticipated solutions within the check dataset. The next diagram illustrates this workflow.
Operating the analysis requires you to convey a dataset that adheres to particular formatting pointers. The dataset have to be in JSON Strains format, with every line representing a sound JSON object. To take care of optimum efficiency, the dataset needs to be restricted to a most of 1,000 prompts per analysis. Every particular person immediate inside the dataset have to be a well-structured, legitimate JSON object that may be correctly parsed and processed by the analysis system.
In case you select to judge for context protection, you have to to supply a floor reality, which is textual content that serves because the baseline for measuring protection. The bottom reality should embody referenceContexts, and every immediate within the floor reality should have corresponding reference contexts for correct analysis.
The next instance code exhibits the required fields:
For extra particulars, see Making a immediate dataset for Retrieve solely analysis jobs.
Consider the era
After validating that your RAG workflow efficiently retrieves related context out of your vector database and aligns together with your predefined efficiency requirements, you may proceed to judge the era stage of your pipeline. The Amazon Bedrock analysis instrument offers a complete evaluation framework with eight metrics that cowl each response high quality and accountable AI concerns.
Response high quality contains the next metrics:
- Helpfulness – Evaluates how helpful and complete the generated responses are in answering questions
- Correctness – Assesses the accuracy of responses to questions
- Logical coherence – Examines responses for logical gaps, inconsistencies, or contradictions
- Completeness – Evaluates whether or not responses handle all points of the questions
- Faithfulness – Measures factual accuracy and resistance to hallucinations
Accountable AI contains the next metrics:
- Harmfulness – Evaluates responses for the presence of hate, insult, or violent content material
- Stereotyping – Assesses for generalized statements about teams or people
- Refusal – Measures how appropriately the system declines to reply inappropriate questions
Response high quality and accountable AI metrics are compiled by evaluating search outcomes and the generated response from the RAG pipeline with floor reality solutions. The next diagram illustrates this workflow.

The dataset for analysis should adhere to particular structural necessities, utilizing JSON Strains format with a most of 1,000 prompts per analysis. Every immediate is required to be a sound JSON object with a well-defined construction. Inside this construction, two vital fields play important roles: the immediate area accommodates the question textual content used for mannequin analysis, and the referenceResponses area shops the anticipated floor reality responses in opposition to which the mannequin’s efficiency might be measured. This format promotes a standardized, constant method to evaluating mannequin outputs throughout totally different check eventualities.
The next instance code exhibits the required fields:
For extra particulars, see Making a immediate dataset for Retrieve and generate analysis jobs.
The next screenshot exhibits an Amazon Bedrock analysis outcomes pattern dashboard.

After processing, the analysis offers complete insights, delivering each mixture metrics and granular efficiency breakdowns for every particular person metric. These detailed outcomes embody pattern conversations that illustrate efficiency nuances. To derive most worth, we suggest conducting a qualitative evaluation, significantly specializing in conversations that acquired low scores throughout any metrics. This deep-dive evaluation will help you perceive the underlying components contributing to poor efficiency and inform strategic enhancements to your RAG workflow.
Constructing a complete check dataset: Methods and concerns
Creating a strong check dataset is essential for significant analysis. On this part, we focus on three main approaches to dataset improvement.
Human-annotated information assortment
Human annotation stays the gold customary for domain-specific, high-quality datasets. You’ll be able to:
- Use your group’s proprietary paperwork and solutions
- Use open-source doc collections like Clueweb (a 10-billion internet doc repository)
- Make use of skilled information labeling providers comparable to Amazon SageMaker Floor Fact
- Use a crowdsourcing market like Amazon Mechanical Turk for distributed annotation
Human information annotation is beneficial for domain-specific, high-quality, and nuanced outcomes. Nonetheless, producing and sustaining giant datasets utilizing human annotators is a time-consuming and dear method.
Artificial information era utilizing LLMs
Artificial information era gives a extra automated, doubtlessly cost-effective different with two main methodologies:
- Self-instruct method:
- Iterative course of utilizing a single goal mannequin
- Mannequin generates a number of responses to queries
- Gives steady suggestions and refinement
- Data distillation method:
- Makes use of a number of fashions
- Generates responses primarily based on preexisting mannequin coaching
- Permits quicker dataset creation through the use of beforehand skilled fashions
Artificial information era requires cautious navigation of a number of key concerns. Organizations should usually safe Finish Consumer License Agreements and would possibly want entry to a number of LLMs. Though the method calls for minimal human knowledgeable validation, these strategic necessities underscore the complexity of producing artificial datasets effectively. This method gives a streamlined different to conventional information annotation strategies, balancing authorized compliance with technical innovation.
Steady dataset enchancment: The suggestions loop technique
Develop a dynamic, iterative method to dataset enhancement that transforms consumer interactions into invaluable studying alternatives. Start together with your current information as a foundational baseline, then implement a strong consumer suggestions mechanism that systematically captures and evaluates real-world mannequin interactions. Set up a structured course of for reviewing and integrating flagged responses, treating each bit of suggestions as a possible refinement level in your dataset. For an instance of such a suggestions loop applied in AWS, check with Enhance LLM efficiency with human and AI suggestions on Amazon SageMaker for Amazon Engineering.
This method transforms dataset improvement from a static, one-time effort right into a residing, adaptive system. By repeatedly increasing and refining your dataset via user-driven insights, you create a self-improving mechanism that progressively enhances mannequin efficiency and analysis metrics. Bear in mind: dataset evolution isn’t a vacation spot, however an ongoing journey of incremental optimization.
When creating your check dataset, try for a strategic stability that exactly represents the vary of eventualities your customers will encounter. The dataset ought to comprehensively span potential use instances and edge instances, whereas avoiding pointless repetition. As a result of every analysis instance incurs a price, concentrate on making a dataset that maximizes insights and efficiency understanding, deciding on examples that reveal distinctive mannequin behaviors reasonably than redundant iterations. The purpose is to craft a focused, environment friendly dataset that gives significant efficiency evaluation with out losing assets on superfluous testing.
Efficiency enchancment instruments
Complete analysis metrics are extra than simply efficiency indicators—they’re a strategic roadmap for steady enchancment in your RAG pipeline. These metrics present vital insights that remodel summary efficiency information into actionable intelligence, enabling you to do the next:
- Diagnose particular pipeline weaknesses
- Prioritize enchancment efforts
- Objectively assess information base readiness
- Make data-driven optimization choices
By systematically analyzing your metrics, you may definitively reply key questions: Is your information base sturdy sufficient for deployment? What particular elements require refinement? The place do you have to focus your optimization efforts for optimum influence?
Consider metrics as a diagnostic instrument that illuminates the trail from present efficiency to distinctive AI system reliability. They don’t simply measure—they information, offering a transparent, quantitative framework for strategic enhancement.
Though a very complete exploration of RAG pipeline optimization would require an in depth treatise, this publish gives a scientific framework for transformative enhancements throughout vital dimensions.
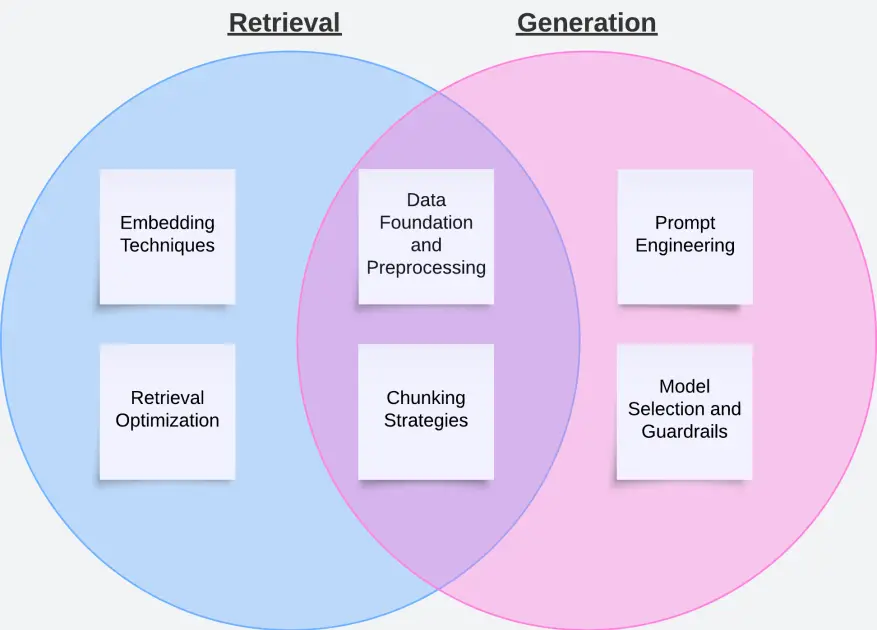
Knowledge basis and preprocessing
Knowledge basis and preprocessing consists of the next finest practices:
- Clear and preprocess supply paperwork to enhance high quality, eradicating noise, standardizing codecs, and sustaining information consistency
- Increase coaching information with related exterior sources, increasing dataset variety and protection
- Implement named entity recognition and linking to enhance retrieval, enhancing semantic understanding and context identification
- Use textual content summarization methods to condense lengthy paperwork, lowering complexity whereas preserving key data
Chunking methods
Take into account the next chunking methods:
- Use semantic chunking as a substitute of fixed-size chunking to protect context, sustaining significant data boundaries.
- Discover varied chunk sizes (128–1,024 characters), adapting to semantic textual content construction and reserving that means via clever segmentation. For extra particulars on Amazon Bedrock chunking methods, see How content material chunking works for information bases.
- Implement sliding window chunking with overlap, minimizing data loss between chunks, usually 10–20% overlap to supply contextual continuity.
- Take into account hierarchical chunking for lengthy paperwork, capturing each native and world contextual nuances.
Embedding methods
Embedding methods embody the next:
- In case your textual content accommodates a number of languages, you would possibly need to strive utilizing the Cohere Embed (Multilingual) embedding mannequin. This might enhance semantic understanding and retrieval relevance.
- Experiment with embedding dimensions, balancing efficiency and computational effectivity.
- Implement sentence or paragraph embeddings, shifting past word-level representations.
Retrieval optimization
Take into account the next finest practices for retrieval optimization:
- Statically or dynamically modify the variety of retrieved chunks, optimizing data density. In your RetrieveAndGenerate (or Retrieve) request, modify
"retrievalConfiguration": { "vectorSearchConfiguration": { "numberOfResults": NUMBER }}. - Implement metadata filtering, including contextual layers to chunk retrieval. For instance, prioritizing current data in time-sensitive eventualities. For code samples for metadata filtering utilizing Amazon Bedrock Data Bases, check with the next GitHub repo.
- Use hybrid search combining dense and sparse retrieval, mixing semantic and key phrase search approaches.
- Apply reranking fashions to enhance precision, reorganizing retrieved contexts by relevance.
- Experiment with various similarity metrics, exploring past customary cosine similarity.
- Implement question growth methods, remodeling queries for simpler retrieval. One instance is question decomposition, breaking complicated queries into focused sub-questions.
The next screenshot exhibits these choices on the Amazon Bedrock console.

Immediate engineering
After you choose a mannequin, you may edit the immediate template:
- Design context-aware prompts, explicitly guiding fashions to make use of retrieved data
- Implement few-shot prompting, utilizing dynamic, query-matched examples
- Create dynamic prompts primarily based on question and paperwork, adapting instruction technique contextually
- Embrace specific utilization directions for retrieved data, attaining trustworthy and exact response era
The next screenshot exhibits an instance of modifying the immediate template on the Amazon Bedrock console.

Mannequin choice and guardrails
When selecting your mannequin and guardrails, take into account the next:
- Select LLMs primarily based on particular job necessities, aligning mannequin capabilities with the use case
- High-quality-tune fashions on domain-specific information, enhancing specialised efficiency
- Experiment with mannequin sizes, balancing efficiency and computational effectivity
- Take into account specialised mannequin configurations, utilizing smaller fashions for retrieval and bigger for era
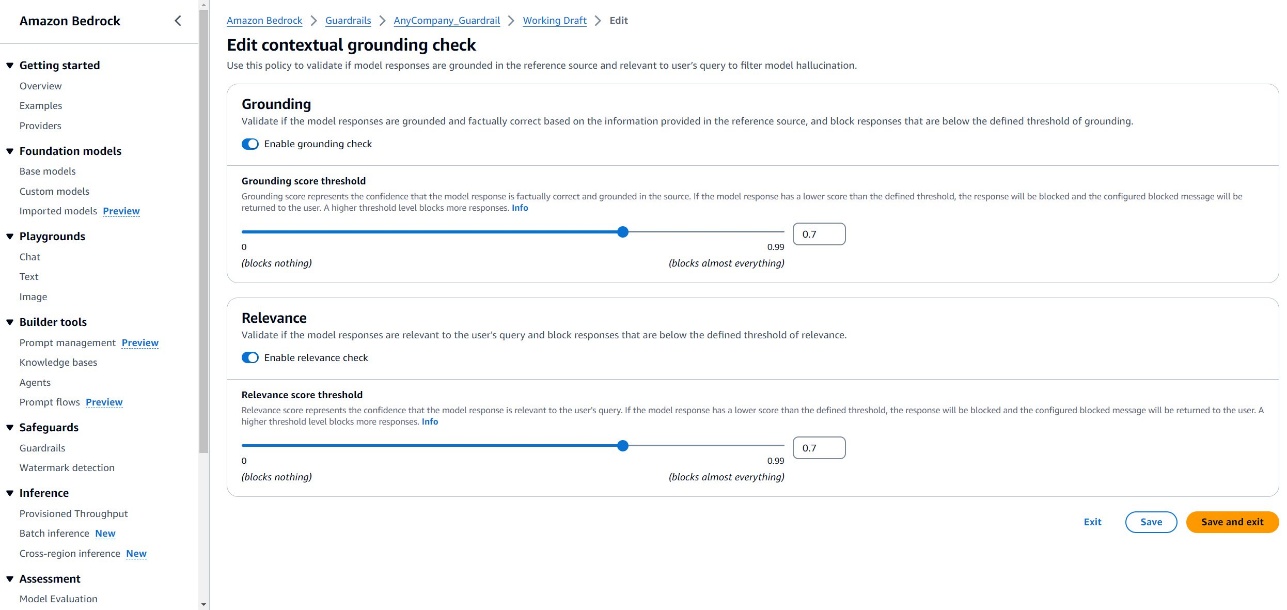
- Implement contextual grounding checks, ensuring responses stay true to supplied data, comparable to contextual grounding with Amazon Bedrock Guardrails (see the next screenshot)
- Discover superior search paradigms, comparable to information graph search (GraphRAG)
Navigating information base enhancements: Key concerns
When optimizing a RAG system, understanding your efficiency necessities is essential. The appropriate efficiency bar relies upon totally in your utility’s context—whether or not it’s an inner instrument, a system augmenting human staff, or a customer-facing service. A 0.95 metric rating is likely to be ample for some functions, the place 1 in 20 solutions might have minor inaccuracies, however doubtlessly unacceptable for high-stakes eventualities. The bottom line is to align your optimization efforts with the particular reliability and precision wants of your specific use case.
One other key’s to prioritize refining the retrieval mechanism earlier than addressing era. Upstream efficiency straight influences downstream metrics, making retrieval optimization vital. Sure methods, significantly chunking methods, have nuanced impacts throughout each phases. As an example, rising chunk measurement can enhance retrieval effectivity by lowering search complexity, however concurrently dangers introducing irrelevant particulars that may compromise the era’s correctness. This delicate stability requires cautious, incremental changes to ensure each retrieval precision and response high quality are systematically enhanced.
The next determine illustrates the aforementioned instruments and the way they relate to retrieval, era, and each.

Diagnose the difficulty
When concentrating on a particular efficiency metric, undertake a forensic, human-centric method to analysis. Deal with your AI system like a colleague whose work requires considerate, constructive suggestions. This contains the next steps:
- Failure sample identification:
- Systematically map query varieties that persistently underperform
- Determine particular traits triggering poor efficiency, comparable to:
- Checklist-based queries
- Specialised vocabulary domains
- Complicated subject intersections
- Contextual retrieval forensics:
- Conduct granular chunk relevance evaluation
- Quantify irrelevant or incorrect retrieved contexts
- Map precision distribution inside the retrieved set (for instance, the primary 5 out of 15 chunks are related, the following 10 will not be)
- Perceive retrieval mechanism’s contextual discrimination capabilities
- Floor reality comparative evaluation:
- Rigorously evaluate generated responses in opposition to reference solutions
- Diagnose potential floor reality limitations
- Develop focused enchancment directions—take into consideration what particular steering would improve response accuracy, and which nuanced context is likely to be lacking
Develop a strategic method to enchancment
When confronting complicated RAG pipeline challenges, undertake a methodical, strategic method that transforms efficiency optimization from a frightening job into a scientific journey of incremental enhancement.
The bottom line is to determine ways with direct, measurable influence in your particular goal metric, concentrating on optimization factors that supply the best potential return on effort. This implies fastidiously analyzing every potential technique via the lens of its possible efficiency enchancment, specializing in methods that may ship significant beneficial properties with minimal systemic disruption. The next determine illustrates which units of methods to prioritize when working to enhance metrics.

Moreover, you must prioritize low-friction optimization ways, comparable to configurable parameters in your information base, or implementations which have minimal infrastructure disruption. It’s beneficial to keep away from full vector database reimplementation except needed.
It’s best to take a lean method—make your RAG pipeline enchancment right into a methodical, scientific means of steady refinement. Embrace an method of strategic incrementalism: make purposeful, focused changes which might be sufficiently small to be exactly measured, but significant sufficient to drive efficiency ahead.
Every modification turns into an experimental intervention, rigorously examined to know its particular influence. Implement a complete model monitoring system that captures not simply the modifications made, however the rationale behind every adjustment, the efficiency metrics earlier than and after, and the insights gained.
Lastly, method efficiency analysis with a holistic, empathetic methodology that transcends mere quantitative metrics. Deal with the evaluation course of as a collaborative dialogue of development and understanding, mirroring the nuanced method you’ll take when teaching a proficient workforce member. As an alternative of lowering efficiency to chilly, numerical indicators, search to uncover the underlying dynamics, contextual challenges, and potential for improvement. Acknowledge that significant analysis goes past surface-level measurements, requiring deep perception into capabilities, limitations, and the distinctive context of efficiency.
Conclusion
Optimizing Amazon Bedrock Data Bases for RAG is an iterative course of that requires systematic testing and refinement. Success comes from methodically utilizing methods like immediate engineering and chunking to enhance each the retrieval and era phases of RAG. By monitoring key metrics all through this course of, you may measure the influence of your optimizations and guarantee they meet your utility’s necessities.
To study extra about optimizing your Amazon Bedrock Data Bases, see our information on learn how to Consider the efficiency of Amazon Bedrock assets.
Concerning the Authors
 Clement Perrot is a Senior Options Architect and AI/ML Specialist at AWS, the place he helps early-stage startups construct and use AI on the AWS platform. Previous to AWS, Clement was an entrepreneur, whose final two AI and shopper {hardware} startups had been acquired.
Clement Perrot is a Senior Options Architect and AI/ML Specialist at AWS, the place he helps early-stage startups construct and use AI on the AWS platform. Previous to AWS, Clement was an entrepreneur, whose final two AI and shopper {hardware} startups had been acquired.
 Miriam Lebowitz is a Options Architect targeted on empowering early-stage startups at AWS. She makes use of her expertise with AI/ML to information corporations to pick and implement the best applied sciences for his or her enterprise targets, setting them up for scalable development and innovation within the aggressive startup world.
Miriam Lebowitz is a Options Architect targeted on empowering early-stage startups at AWS. She makes use of her expertise with AI/ML to information corporations to pick and implement the best applied sciences for his or her enterprise targets, setting them up for scalable development and innovation within the aggressive startup world.
 Tamil Sambasivam is a Options Architect and AI/ML Specialist at AWS. She helps enterprise clients to resolve their enterprise issues by recommending the best AWS options. Her sturdy again floor in Data Expertise (24+ years of expertise) helps clients to strategize, develop and modernize their enterprise issues in AWS cloud. Within the spare time, Tamil prefer to journey and gardening.
Tamil Sambasivam is a Options Architect and AI/ML Specialist at AWS. She helps enterprise clients to resolve their enterprise issues by recommending the best AWS options. Her sturdy again floor in Data Expertise (24+ years of expertise) helps clients to strategize, develop and modernize their enterprise issues in AWS cloud. Within the spare time, Tamil prefer to journey and gardening.



{kind=link}