AI brokers are shortly turning into an integral a part of buyer workflows throughout industries by automating complicated duties, enhancing decision-making, and streamlining operations. Nonetheless, the adoption of AI brokers in manufacturing techniques requires scalable analysis pipelines. Strong agent analysis allows you to gauge how nicely an agent is performing sure actions and achieve key insights into them, enhancing AI agent security, management, belief, transparency, and efficiency optimization.
Amazon Bedrock Brokers makes use of the reasoning of basis fashions (FMs) accessible on Amazon Bedrock, APIs, and knowledge to interrupt down person requests, collect related data, and effectively full duties—liberating groups to deal with high-value work. You’ll be able to allow generative AI purposes to automate multistep duties by seamlessly connecting with firm techniques, APIs, and knowledge sources.
Ragas is an open supply library for testing and evaluating giant language mannequin (LLM) purposes throughout varied LLM use circumstances, together with Retrieval Augmented Era (RAG). The framework allows quantitative measurement of the effectiveness of the RAG implementation. On this submit, we use the Ragas library to guage the RAG functionality of Amazon Bedrock Brokers.
LLM-as-a-judge is an analysis strategy that makes use of LLMs to evaluate the standard of AI-generated outputs. This technique employs an LLM to behave as an neutral evaluator, to research and rating outputs. On this submit, we make use of the LLM-as-a-judge approach to guage the text-to-SQL and chain-of-thought capabilities of Amazon Bedrock Brokers.
Langfuse is an open supply LLM engineering platform, which gives options equivalent to traces, evals, immediate administration, and metrics to debug and enhance your LLM utility.
Within the submit Speed up evaluation and discovery of most cancers biomarkers with Amazon Bedrock Brokers, we showcased analysis brokers for most cancers biomarker discovery for pharmaceutical firms. On this submit, we prolong the prior work and showcase Open Supply Bedrock Agent Analysis with the next capabilities:
- Evaluating Amazon Bedrock Brokers on its capabilities (RAG, text-to-SQL, customized instrument use) and general chain-of-thought
- Complete analysis outcomes and hint knowledge despatched to Langfuse with built-in visible dashboards
- Hint parsing and evaluations for varied Amazon Bedrock Brokers configuration choices
First, we conduct evaluations on quite a lot of completely different Amazon Bedrock Brokers. These embody a pattern RAG agent, a pattern text-to-SQL agent, and pharmaceutical analysis brokers that use multi-agent collaboration for most cancers biomarker discovery. Then, for every agent, we showcase navigating the Langfuse dashboard to view traces and analysis outcomes.
Technical challenges
At the moment, AI agent builders typically face the next technical challenges:
- Finish-to-end agent analysis – Though Amazon Bedrock gives built-in analysis capabilities for LLM fashions and RAG retrieval, it lacks metrics particularly designed for Amazon Bedrock Brokers. There’s a want for evaluating the holistic agent objective, in addition to particular person agent hint steps for particular duties and gear invocations. Assist can also be wanted for each single and multi-agents, and each single and multi-turn datasets.
- Difficult experiment administration – Amazon Bedrock Brokers presents quite a few configuration choices, together with LLM mannequin choice, agent directions, instrument configurations, and multi-agent setups. Nonetheless, conducting fast experimentation with these parameters is technically difficult because of the lack of systematic methods to trace, evaluate, and measure the influence of configuration adjustments throughout completely different agent variations. This makes it troublesome to successfully optimize agent efficiency via iterative testing.
Answer overview
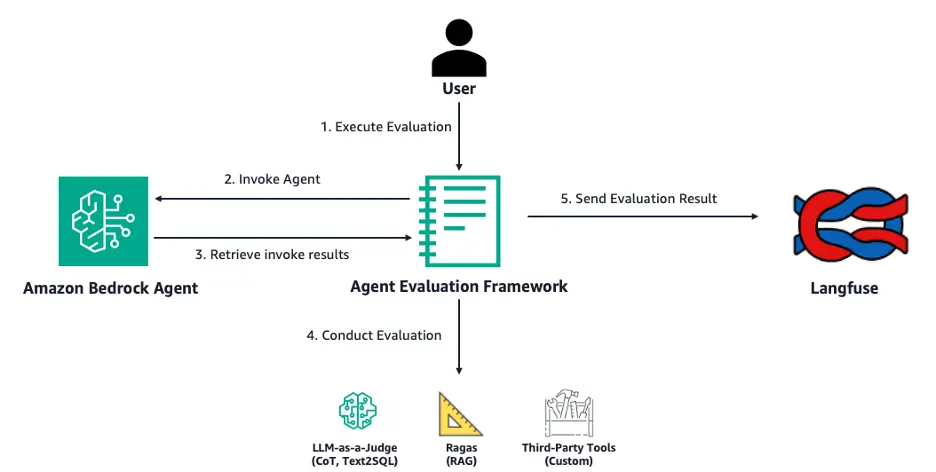
The next determine illustrates how Open Supply Bedrock Agent Analysis works on a excessive degree. The framework runs an analysis job that can invoke your individual agent in Amazon Bedrock and consider its response.

The workflow consists of the next steps:
- The person specifies the agent ID, alias, analysis mannequin, and dataset containing query and floor reality pairs.
- The person executes the analysis job, which is able to invoke the desired Amazon Bedrock agent.
- The retrieved agent invocation traces are run via a customized parsing logic within the framework.
- The framework conducts an analysis based mostly on the agent invocation outcomes and the query sort:
- Chain-of-thought – LLM-as-a-judge with Amazon Bedrock LLM calls (performed for each analysis run for several types of questions)
- RAG – Ragas analysis library
- Textual content-to-SQL – LLM-as-a-judge with Amazon Bedrock LLM calls
- Analysis outcomes and parsed traces are gathered and despatched to Langfuse for analysis insights.
Conditions
To deploy the pattern RAG and text-to-SQL brokers and comply with together with evaluating them utilizing Open Supply Bedrock Agent Analysis, comply with the directions in Deploying Pattern Brokers for Analysis.
To carry your individual agent to guage with this framework, confer with the next README and comply with the detailed directions to deploy the Open Supply Bedrock Agent Analysis framework.
Overview of analysis metrics and enter knowledge
First, we create pattern Amazon Bedrock brokers to display the capabilities of Open Supply Bedrock Agent Analysis. The text-to-SQL agent makes use of the BirdSQL Mini-Dev dataset, and the RAG agent makes use of the Hugging Face rag-mini-wikpedia dataset.
Analysis metrics
The Open Supply Bedrock Agent Analysis framework conducts evaluations on two broad sorts of metrics:
- Agent objective – Chain-of-thought (run on each query)
- Activity accuracy – RAG, text-to-SQL (run solely when the precise instrument is used to reply query)
Agent objective metrics measure how nicely an agent identifies and achieves the targets of the person. There are two principal sorts: reference-based analysis and no reference analysis. Examples could be present in Agent Objective accuracy as outlined by Ragas:
- Reference-based analysis – The person gives a reference that can be used as the perfect end result. The metric is computed by evaluating the reference with the objective achieved by the tip of the workflow.
- Analysis with out reference – The metric evaluates the efficiency of the LLM in figuring out and attaining the targets of the person with out reference.
We are going to showcase analysis with out reference utilizing chain-of-thought analysis. We conduct evaluations by evaluating the agent’s reasoning and the agent’s instruction. For this analysis, we use some metrics from the evaluator prompts for Amazon Bedrock LLM-as-a-judge. On this framework, the chain-of-thought evaluations are run on each query that the agent is evaluated in opposition to.
Activity accuracy metrics measure how nicely an agent calls the required instruments to finish a given process. For the 2 process accuracy metrics, RAG and text-to-SQL, evaluations are performed based mostly on evaluating the precise agent reply in opposition to the bottom reality dataset that should be offered within the enter dataset. The duty accuracy metrics are solely evaluated when the corresponding instrument is used to reply the query.
The next is a breakdown of the important thing metrics utilized in every analysis sort included within the framework:
- RAG:
- Faithfulness – How factually constant a response is with the retrieved context
- Reply relevancy – How instantly and appropriately the unique query is addressed
- Context recall – How most of the related items of data have been efficiently retrieved
- Semantic similarity – The evaluation of the semantic resemblance between the generated reply and the bottom reality
- Textual content-to-SQL:
- Chain-of-thought:
- Helpfulness – How nicely the agent satisfies specific and implicit expectations
- Faithfulness – How nicely the agent sticks to accessible data and context
- Instruction following – How nicely the agent respects all specific instructions
Consumer-agent trajectories
The enter dataset is within the type of trajectories, the place every trajectory consists of a number of inquiries to be answered by the agent. The trajectories are supposed to simulate how a person may work together with the agent. Every trajectory consists of a novel question_id, question_type, query, and ground_truth data. The next are examples of precise trajectories used to guage every sort of agent on this submit.
For extra easy agent setups just like the RAG and text-to-SQL pattern agent, we created trajectories consisting of a single query, as proven within the following examples.
The next is an instance of a RAG pattern agent trajectory:
The next is an instance of a text-to-SQL pattern agent trajectory:
Pharmaceutical analysis agent use case instance
On this part, we display how you should use the Open Supply Bedrock Agent Analysis framework to guage pharmaceutical analysis brokers mentioned within the submit Speed up evaluation and discovery of most cancers biomarkers with Amazon Bedrock Brokers . It showcases quite a lot of specialised brokers, together with a biomarker database analyst, statistician, scientific proof researcher, and medical imaging professional in collaboration with a supervisor agent.
The pharmaceutical analysis agent was constructed utilizing the multi-agent collaboration function of Amazon Bedrock. The next diagram reveals the multi-agent setup that was evaluated utilizing this framework.

As proven within the diagram, the RAG evaluations can be performed on the scientific proof researcher sub-agent. Equally, text-to-SQL evaluations can be run on the biomarker database analyst sub-agent. The chain-of-thought analysis evaluates the ultimate reply of the supervisor agent to test if it correctly orchestrated the sub-agents and answered the person’s query.
Analysis agent trajectories
For a extra complicated setup just like the pharmaceutical analysis brokers, we used a set of business related pregenerated take a look at questions. By creating teams of questions based mostly on their subject whatever the sub-agents that is likely to be invoked to reply the query, we created trajectories that embody a number of questions spanning a number of sorts of instrument use. With related questions already generated, integrating with the analysis framework merely required correctly formatting the bottom reality knowledge into trajectories.
We stroll via evaluating this agent in opposition to a trajectory containing a RAG query and a text-to-SQL query:
Chain-of-thought evaluations are performed for each query, no matter instrument use. This can be illustrated via a set of pictures of agent hint and evaluations on the Langfuse dashboard.
After operating the agent in opposition to the trajectory, the outcomes are despatched to Langfuse to view the metrics. The next screenshot reveals the hint of the RAG query (query ID 3) analysis on Langfuse.

The screenshot shows the next data:
- Hint data (enter and output of agent invocation)
- Hint steps (agent technology and the corresponding sub-steps)
- Hint metadata (enter and output tokens, price, mannequin, agent sort)
- Analysis metrics (RAG and chain-of-thought metrics)
The next screenshot reveals the hint of the text-to-SQL query (query ID 4) analysis on Langfuse, which evaluated the biomarker database analyst agent that generates SQL queries to run in opposition to an Amazon Redshift database containing biomarker data.

The screenshot reveals the next data:
- Hint data (enter and output of agent invocation)
- Hint steps (agent technology and the corresponding sub-steps)
- Hint metadata (enter and output tokens, price, mannequin, agent sort)
- Analysis metrics (text-to-SQL and chain-of-thought metrics)
The chain-of-thought analysis is included in a part of each questions’ analysis traces. For each traces, LLM-as-a-judge is used to generate scores and clarification round an Amazon Bedrock agent’s reasoning on a given query.
General, we ran 56 questions grouped into 21 trajectories in opposition to the agent. The traces, mannequin prices, and scores are proven within the following screenshot.

The next desk comprises the typical analysis scores throughout 56 analysis traces.
| Metric Class | Metric Sort | Metric Title | Variety of Traces | Metric Avg. Worth |
| Agent Objective | COT | Helpfulness | 50 | 0.77 |
| Agent Objective | COT | Faithfulness | 50 | 0.87 |
| Agent Objective | COT | Instruction following | 50 | 0.69 |
| Agent Objective | COT | General (common of all metrics) | 50 | 0.77 |
| Activity Accuracy | TEXT2SQL | Reply correctness | 26 | 0.83 |
| Activity Accuracy | TEXT2SQL | SQL semantic equivalence | 26 | 0.81 |
| Activity Accuracy | RAG | Semantic similarity | 20 | 0.66 |
| Activity Accuracy | RAG | Faithfulness | 20 | 0.5 |
| Activity Accuracy | RAG | Reply relevancy | 20 | 0.68 |
| Activity Accuracy | RAG | Context recall | 20 | 0.53 |
Safety concerns
Contemplate the next safety measures:
- Allow Amazon Bedrock agent logging – For safety greatest practices of utilizing Amazon Bedrock Brokers, allow Amazon Bedrock mannequin invocation logging to seize prompts and responses securely in your account.
- Verify for compliance necessities – Earlier than implementing Amazon Bedrock Brokers in your manufacturing setting, ensure that the Amazon Bedrock compliance certifications and requirements align together with your regulatory necessities. Consult with Compliance validation for Amazon Bedrock for extra data and assets on assembly compliance necessities.
Clear up
In the event you deployed the pattern brokers, run the next notebooks to delete the assets created.
In the event you selected the self-hosted Langfuse possibility, comply with these steps to scrub up your AWS self-hosted Langfuse setup.
Conclusion
On this submit, we launched the Open Supply Bedrock Agent Analysis framework, a Langfuse-integrated answer that streamlines the agent improvement course of. The framework comes geared up with built-in analysis logic for RAG, text-to-SQL, chain-of-thought reasoning, and integration with Langfuse for viewing analysis metrics. With the Open Supply Bedrock Agent Analysis agent, builders can shortly consider their brokers and quickly experiment with completely different configurations, accelerating the event cycle and bettering agent efficiency.
We demonstrated how this analysis framework could be built-in with pharmaceutical analysis brokers. We used it to guage agent efficiency in opposition to biomarker questions and despatched traces to Langfuse to view analysis metrics throughout query sorts.
The Open Supply Bedrock Agent Analysis framework allows you to speed up your generative AI utility constructing course of utilizing Amazon Bedrock Brokers. To self-host Langfuse in your AWS account, see Internet hosting Langfuse on Amazon ECS with Fargate utilizing CDK Python. To discover how one can streamline your Amazon Bedrock Brokers analysis course of, get began with Open Supply Bedrock Agent Analysis.
Consult with In the direction of Efficient GenAI Multi-Agent Collaboration: Design and Analysis for Enterprise Purposes from the Amazon Bedrock staff to study extra about multi-agent collaboration and end-to-end agent analysis.
Concerning the authors
 Hasan Poonawala is a Senior AI/ML Options Architect at AWS, working with healthcare and life sciences prospects. Hasan helps design, deploy, and scale generative AI and machine studying purposes on AWS. He has over 15 years of mixed work expertise in machine studying, software program improvement, and knowledge science on the cloud. In his spare time, Hasan likes to discover nature and spend time with family and friends.
Hasan Poonawala is a Senior AI/ML Options Architect at AWS, working with healthcare and life sciences prospects. Hasan helps design, deploy, and scale generative AI and machine studying purposes on AWS. He has over 15 years of mixed work expertise in machine studying, software program improvement, and knowledge science on the cloud. In his spare time, Hasan likes to discover nature and spend time with family and friends.
 Blake Shin is an Affiliate Specialist Options Architect at AWS who enjoys studying about and dealing with new AI/ML applied sciences. In his free time, Blake enjoys exploring town and taking part in music.
Blake Shin is an Affiliate Specialist Options Architect at AWS who enjoys studying about and dealing with new AI/ML applied sciences. In his free time, Blake enjoys exploring town and taking part in music.
 Rishiraj Chandra is an Affiliate Specialist Options Architect at AWS, captivated with constructing modern synthetic intelligence and machine studying options. He’s dedicated to repeatedly studying and implementing rising AI/ML applied sciences. Outdoors of labor, Rishiraj enjoys operating, studying, and taking part in tennis.
Rishiraj Chandra is an Affiliate Specialist Options Architect at AWS, captivated with constructing modern synthetic intelligence and machine studying options. He’s dedicated to repeatedly studying and implementing rising AI/ML applied sciences. Outdoors of labor, Rishiraj enjoys operating, studying, and taking part in tennis.



{kind=link}