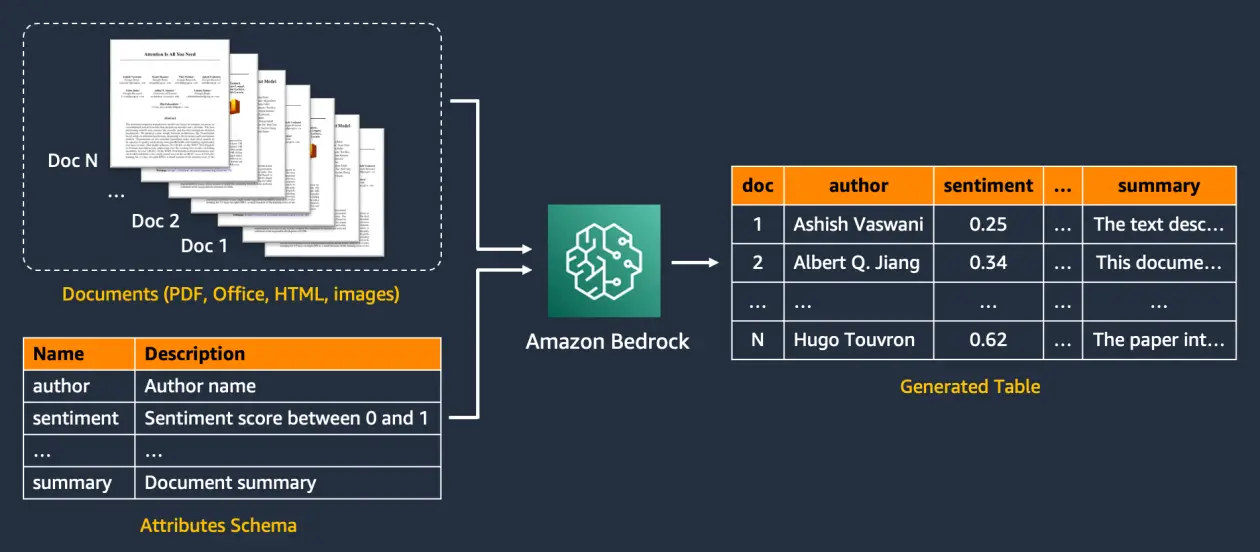
Extracting info from unstructured paperwork at scale is a recurring enterprise process. Widespread use instances embody creating product function tables from descriptions, extracting metadata from paperwork, and analyzing authorized contracts, buyer evaluations, information articles, and extra. A basic strategy to extracting info from textual content is known as entity recognition (NER). NER identifies entities from predefined classes, comparable to individuals and organizations. Though numerous AI providers and options assist NER, this strategy is proscribed to textual content paperwork and solely helps a set set of entities. Moreover, basic NER fashions can’t deal with different knowledge varieties comparable to numeric scores (comparable to sentiment) or free-form textual content (comparable to abstract). Generative AI unlocks these potentialities with out pricey knowledge annotation or mannequin coaching, enabling extra complete clever doc processing (IDP).
AWS not too long ago introduced the final availability of Amazon Bedrock Knowledge Automation, a function of Amazon Bedrock that automates the technology of priceless insights from unstructured multimodal content material comparable to paperwork, pictures, video, and audio. This service gives pre-built capabilities for IDP and knowledge extraction by a unified API, assuaging the necessity for complicated immediate engineering or fine-tuning, and making it a superb alternative for doc processing workflows at scale. To study extra about Amazon Bedrock Knowledge Automation, seek advice from Simplify multimodal generative AI with Amazon Bedrock Knowledge Automation.
Amazon Bedrock Knowledge Automation is the really helpful strategy for IDP use case because of its simplicity, industry-leading accuracy, and managed service capabilities. It handles the complexity of doc parsing, context administration, and mannequin choice mechanically, so builders can deal with their enterprise logic fairly than IDP implementation particulars.
Though Amazon Bedrock Knowledge Automation meets most IDP wants, some organizations require further customization of their IDP pipelines. For instance, corporations would possibly want to make use of self-hosted basis fashions (FMs) for IDP because of regulatory necessities. Some clients have builder groups who would possibly want to take care of full management over the IDP pipeline as a substitute of utilizing a managed service. Lastly, organizations would possibly function in AWS Areas the place Amazon Bedrock Knowledge Automation isn’t accessible (accessible in us-west-2 and us-east-1 as of June 2025). In such instances, builders would possibly use Amazon Bedrock FMs immediately or carry out optical character recognition (OCR) with Amazon Textract.
This submit presents an end-to-end IDP software powered by Amazon Bedrock Knowledge Automation and different AWS providers. It offers a reusable AWS infrastructure as code (IaC) that deploys an IDP pipeline and offers an intuitive UI for reworking paperwork into structured tables at scale. The applying solely requires the consumer to offer the enter paperwork (comparable to contracts or emails) and a listing of attributes to be extracted. It then performs IDP with generative AI.
The applying code and deployment directions are accessible on GitHub underneath the MIT license.
Answer overview
The IDP resolution introduced on this submit is deployed as IaC utilizing the AWS Cloud Improvement Equipment (AWS CDK). Amazon Bedrock Knowledge Automation serves as the first engine for info extraction. For instances requiring additional customization, the answer additionally offers different processing paths utilizing Amazon Bedrock FMs and Amazon Textract integration.
We use AWS Step Features to orchestrate the IDP workflow and parallelize processing for a number of paperwork. As a part of the workflow, we use AWS Lambda capabilities to name Amazon Bedrock Knowledge Automation or Amazon Textract and Amazon Bedrock (relying on the chosen parsing mode). Processed paperwork and extracted attributes are saved in Amazon Easy Storage Service (Amazon S3).
A Step Features workflow with the enterprise logic is invoked by an API name carried out utilizing an AWS SDK. We additionally construct a containerized internet software working on Amazon Elastic Container Service (Amazon ECS) that’s accessible to end-users by Amazon CloudFront to simplify their interplay with the answer. We use Amazon Cognito for authentication and safe entry to the APIs.
The next diagram illustrates the structure and workflow of the IDP resolution.

The IDP workflow contains the next steps:
- A consumer logs in to the online software utilizing credentials managed by Amazon Cognito, selects enter paperwork, and defines the fields to be extracted from them within the UI. Optionally, the consumer can specify the parsing mode, LLM to make use of, and different settings.
- The consumer begins the IDP pipeline.
- The applying creates a pre-signed S3 URL for the paperwork and uploads them to Amazon S3.
- The applying triggers Step Features to start out the state machine with the S3 URIs and IDP settings as inputs. The Map state begins to course of the paperwork concurrently.
- Relying on the doc sort and the parsing mode, it branches to completely different Lambda capabilities that carry out IDP, save outcomes to Amazon S3, and ship them again to the UI:
- Amazon Bedrock Knowledge Automation – Paperwork are directed to the “Run Knowledge Automation” Lambda operate. The Lambda operate creates a blueprint with the user-defined fields schema and launches an asynchronous Amazon Bedrock Knowledge Automation job. Amazon Bedrock Knowledge Automation handles the complexity of doc processing and attribute extraction utilizing optimized prompts and fashions. When the job outcomes are prepared, they’re saved to Amazon S3 and despatched again to the UI. This strategy offers the perfect steadiness of accuracy, ease of use, and scalability for many IDP use instances.
- Amazon Textract – If the consumer specifies Amazon Textract as a parsing mode, the IDP pipeline splits into two steps. First, the “Carry out OCR” Lambda operate is invoked to run an asynchronous doc evaluation job. The OCR outputs are processed utilizing the amazon-textract-textractor library and formatted as Markdown. Second, the textual content is handed to the “Extract attributes” Lambda operate (Step 6), which invokes an Amazon Bedrock FM given the textual content and the attributes schema. The outputs are saved to Amazon S3 and despatched to the UI.
- Dealing with workplace paperwork – Paperwork with suffixes like .doc, .ppt, and .xls are processed by the “Parse workplace” Lambda operate, which makes use of LangChain doc loaders to extract the textual content content material. The outputs are handed to the “Extract attributes” Lambda operate (Step 6) to proceed with the IDP pipeline.
- If the consumer chooses an Amazon Bedrock FM for IDP, the doc is shipped to the “Extract attributes” Lambda operate. It converts a doc right into a set of pictures, that are despatched to a multimodal FM with the attributes schema as a part of a customized immediate. It parses the LLM response to extract JSON outputs, saves them to Amazon S3, and sends it again to the UI. This move helps .pdf, .png, and .jpg paperwork.
- The online software checks the state machine execution outcomes periodically and returns the extracted attributes to the consumer when they’re accessible.
Stipulations
You possibly can deploy the IDP resolution out of your native laptop or from an Amazon SageMaker pocket book occasion. The deployment steps are detailed within the resolution README file.
In the event you select to deploy utilizing a SageMaker pocket book, which is really helpful, you’ll need entry to an AWS account with permissions to create and launch a SageMaker pocket book occasion.
Deploy the answer
To deploy the answer to your AWS account, full the next steps:
- Open the AWS Administration Console and select the Area wherein you need to deploy the IDP resolution.
- Launch a SageMaker pocket book occasion. Present the pocket book occasion title and pocket book occasion sort, which you’ll set to
ml.m5.giant. Depart different choices as default. - Navigate to the Pocket book occasion and open the IAM position connected tothe pocket book. Open the position on the AWS Identification and Entry Administration (IAM) console.
- Connect an inline coverage to the position and insert the next coverage JSON:
{
"Model": "2012-10-17",
"Assertion": [
{
"Effect": "Allow",
"Action": [
"cloudformation:*",
"s3:*",
"iam:*",
"sts:AssumeRole"
],
"Useful resource": "*"
},
{
"Impact": "Permit",
"Motion": [
"ssm:GetParameter",
"ssm:GetParameters"
],
"Useful resource": "arn:aws:ssm:*:*:parameter/cdk-bootstrap/*"
}
]
}
- When the pocket book occasion standing is marked as InService, select Open JupyterLab.
- Within the JupyterLab surroundings, select File, New, and Terminal.
- Clone the resolution repository by working the next instructions:
cd SageMaker
git clone https://github.com/aws-samples/intelligent-document-processing-with-amazon-bedrock.git- Navigate to the repository folder and run the script to put in necessities:
cd intelligent-document-processing-with-amazon-bedrock
sh install_deps.sh- Run the script to create a digital surroundings and set up dependencies:
sh install_env.sh
supply .venv/bin/activate- Inside the repository folder, copy the
config-example.ymlto aconfig.ymlto specify your stack title. Optionally, configure the providers and point out the modules you need to deploy (for instance, to disable deploying a UI, changedeploy_streamlittoFalse). Ensure you add your consumer e-mail to the Amazon Cognito customers checklist. - Configure Amazon Bedrock mannequin entry by opening the Amazon Bedrock console within the Area specified within the
config.ymlfile. Within the navigation pane, select Mannequin Entry and ensure to allow entry for the mannequin IDs laid out inconfig.yml. - Bootstrap and deploy the AWS CDK in your account:
Be aware that this step might take a while, particularly on the primary deployment. As soon as deployment is full, it is best to see the message as proven within the following screenshot. You possibly can entry the Streamlit frontend utilizing the CloudFront distribution URL supplied within the AWS CloudFormation outputs. The short-term login credentials will probably be despatched to the e-mail laid out in config.yml throughout the deployment.

Utilizing the answer
This part guides you thru two examples to showcase the IDP capabilities.
Instance 1: Analyzing monetary paperwork
On this state of affairs, we extract key options from a multi-page monetary assertion utilizing Amazon Bedrock Knowledge Automation. We use a pattern doc in PDF format with a mix of tables, pictures, and textual content, and extract a number of monetary metrics. Full the next steps:
- Add a doc by attaching a file by the answer UI.

- On the Describe Attributes tab, both manually checklist the names and descriptions of the attributes or add these fields in JSON format. We need to discover the next metrics:
- Present money in property in 2018
- Present money in property in 2019
- Working revenue in 2018
- Working revenue in 2019

- Select Extract attributes to start out the IDP pipeline.
The supplied attributes are built-in right into a customized blueprint with the inferred attributes checklist, which is then used to invoke an information automation job on the uploaded paperwork.
After the IDP pipeline is full, you will notice a desk of ends in the UI. It contains an index for every doc within the _doc column, a column for every of the attributes you outlined, and a file_name column that comprises the doc title.

From the next assertion excerpts, we are able to see that Amazon Bedrock Knowledge Automation was in a position to accurately extract the values for present property and working revenue.


The IDP resolution can be in a position to do complicated calculations past well-defined entities. Let’s say we need to calculate the next accounting metrics:
- Liquidity ratios (Present property/Present liabilities)
- Working capitals (Present property – Present liabilities)
- Income improve ((Income 12 months 2/Income 12 months 1) – 1)
We outline the attributes and their formulation as elements of the attributes’ schema. This time, we select an Amazon Bedrock LLM as a parsing mode to exhibit how the appliance can use a multimodal FM for IDP. When utilizing an Amazon Bedrock LLM, beginning the IDP pipeline will now mix the attributes and their description right into a customized immediate template, which is shipped to the LLM with the paperwork transformed to pictures. As a consumer, you’ll be able to specify the LLM powering the extraction and its inference parameters, comparable to temperature.

The output, together with the complete outcomes, is proven within the following screenshot.


Instance 2: Processing buyer emails
On this state of affairs, we need to extract a number of options from a listing of emails with buyer complaints because of delays in product shipments utilizing Amazon Bedrock Knowledge Automation. For every e-mail, we need to discover the next:
- Buyer title
- Cargo ID
- Electronic mail language
- Electronic mail sentiment
- Cargo delay (in days)
- Abstract of challenge
- Prompt response
Full the next steps:
- Add enter emails as .txt recordsdata. You possibly can obtain pattern emails from GitHub.

- On the Describe Attributes tab, checklist names and descriptions of the attributes.

You possibly can add few-shot examples for some fields (comparable to delay) to elucidate to the LLM how these fields values ought to be extracted. You are able to do this by including an instance enter and the anticipated output for the attribute to the outline.
- Select Extract attributes to start out the IDP pipeline.
The supplied attributes and their descriptions will probably be built-in right into a customized blueprint with the inferred attributes checklist, which is then used to invoke an information automation job on the uploaded paperwork. When the IDP pipeline is full, you will notice the outcomes.

The applying permits downloading the extraction outcomes as a CSV or a JSON file. This makes it simple to make use of the outcomes for downstream duties, comparable to aggregating buyer sentiment scores.
Pricing
On this part, we calculate price estimates for performing IDP on AWS with our resolution.
Amazon Bedrock Knowledge Automation offers a clear pricing schema relying on the enter doc measurement (variety of pages, pictures, or minutes). When utilizing Amazon Bedrock FMs, pricing is determined by the variety of enter and output tokens used as a part of the knowledge extraction name. Lastly, when utilizing Amazon Textract, OCR is carried out and priced individually based mostly on the variety of pages within the paperwork.
Utilizing the previous situations as examples, we are able to approximate the prices relying on the chosen parsing mode. Within the following desk, we present prices utilizing two datasets: 100 20-page monetary paperwork, and 100 1-page buyer emails. We ignore prices of Amazon ECS and Lambda.
| AWS service |
Use case 1 (100 20-page monetary paperwork) |
Use case 2 (100 1-page buyer emails) |
| IDP choice 1: Amazon Bedrock Knowledge Automation | ||
| Amazon Bedrock Knowledge Automation (customized output) | $20.00 | $1.00 |
| IDP choice 2: Amazon Bedrock FM | ||
| Amazon Bedrock (FM invocation, Anthropic’s Claude 4 Sonnet) | $1.79 | $0.09 |
| IDP choice 3: Amazon Textract and Amazon Bedrock FM | ||
| Amazon Textract (doc evaluation job with structure) | $30.00 | $1.50 |
| Amazon Bedrock (FM invocation, Anthropic’s Claude 3.7 Sonnet) | $1.25 | $0.06 |
| Orchestration and storage (shared prices) | ||
| Amazon S3 | $0.02 | $0.02 |
| AWS CloudFront | $0.09 | $0.09 |
| Amazon ECS | – | – |
| AWS Lambda | – | – |
| Whole price: Amazon Bedrock Knowledge Automation | $20.11 | $1.11 |
| Whole price: Amazon Bedrock FM | $1.90 | $0.20 |
| Whole price: Amazon Textract and Amazon Bedrock FM | $31.36 | $1.67 |
The price evaluation means that utilizing Amazon Bedrock FMs with a customized immediate template is a cheap technique for IDP. Nevertheless, this strategy requires an even bigger operational overhead, as a result of the pipeline must be optimized relying on the LLM, and requires handbook safety and privateness administration. Amazon Bedrock Knowledge Automation gives a managed service that makes use of a alternative of high-performing FMs by a single API.
Clear up
To take away the deployed sources, full the next steps:
- On the AWS CloudFormation console, delete the created stack. Alternatively, run the next command:
- On the Amazon Cognito console, delete the consumer pool.
Conclusion
Extracting info from unstructured paperwork at scale is a recurring enterprise process. This submit mentioned an end-to-end IDP software that performs info extraction utilizing a number of AWS providers. The answer is powered by Amazon Bedrock Knowledge Automation, which offers a completely managed service for producing insights from paperwork, pictures, audio, and video. Amazon Bedrock Knowledge Automation handles the complexity of doc processing and knowledge extraction, optimizing for each efficiency and accuracy with out requiring experience in immediate engineering. For prolonged flexibility and customizability in particular situations, our resolution additionally helps IDP utilizing Amazon Bedrock customized LLM calls and Amazon Textract for OCR.
The answer helps a number of doc varieties, together with textual content, pictures, PDF, and Microsoft Workplace paperwork. On the time of writing, correct understanding of data in paperwork wealthy with pictures, tables, and different visible components is just accessible for PDF and pictures. We suggest changing complicated Workplace paperwork to PDFs or pictures for finest efficiency. One other resolution limitation is the doc measurement. As of June 2025, Amazon Bedrock Knowledge Automation helps paperwork as much as 20 pages for customized attributes extraction. When utilizing customized Amazon Bedrock LLMs for IDP, the 300,000-token context window of Amazon Nova LLMs permits processing paperwork with as much as roughly 225,000 phrases. To extract info from bigger paperwork, you’d presently want to separate the file into a number of paperwork.
Within the subsequent variations of the IDP resolution, we plan to maintain including assist for state-of-the-art language fashions accessible by Amazon Bedrock and iterate on immediate engineering to additional enhance the extraction accuracy. We additionally plan to implement strategies for extending the dimensions of supported paperwork and offering customers with a exact indication of the place precisely within the doc the extracted info is coming from.
To get began with IDP with the described resolution, seek advice from the GitHub repository. To study extra about Amazon Bedrock, seek advice from the documentation.
Concerning the authors
 Nikita Kozodoi, PhD, is a Senior Utilized Scientist on the AWS Generative AI Innovation Heart, the place he works on the frontier of AI analysis and enterprise. With wealthy expertise in Generative AI and various areas of ML, Nikita is passionate about utilizing AI to unravel difficult real-world enterprise issues throughout industries.
Nikita Kozodoi, PhD, is a Senior Utilized Scientist on the AWS Generative AI Innovation Heart, the place he works on the frontier of AI analysis and enterprise. With wealthy expertise in Generative AI and various areas of ML, Nikita is passionate about utilizing AI to unravel difficult real-world enterprise issues throughout industries.
 Zainab Afolabi is a Senior Knowledge Scientist on the Generative AI Innovation Centre in London, the place she leverages her intensive experience to develop transformative AI options throughout various industries. She has over eight years of specialized expertise in synthetic intelligence and machine studying, in addition to a ardour for translating complicated technical ideas into sensible enterprise purposes.
Zainab Afolabi is a Senior Knowledge Scientist on the Generative AI Innovation Centre in London, the place she leverages her intensive experience to develop transformative AI options throughout various industries. She has over eight years of specialized expertise in synthetic intelligence and machine studying, in addition to a ardour for translating complicated technical ideas into sensible enterprise purposes.
 Aiham Taleb, PhD, is a Senior Utilized Scientist on the Generative AI Innovation Heart, working immediately with AWS enterprise clients to leverage Gen AI throughout a number of high-impact use instances. Aiham has a PhD in unsupervised illustration studying, and has {industry} expertise that spans throughout numerous machine studying purposes, together with laptop imaginative and prescient, pure language processing, and medical imaging.
Aiham Taleb, PhD, is a Senior Utilized Scientist on the Generative AI Innovation Heart, working immediately with AWS enterprise clients to leverage Gen AI throughout a number of high-impact use instances. Aiham has a PhD in unsupervised illustration studying, and has {industry} expertise that spans throughout numerous machine studying purposes, together with laptop imaginative and prescient, pure language processing, and medical imaging.
 Liza (Elizaveta) Zinovyeva is an Utilized Scientist at AWS Generative AI Innovation Heart and relies in Berlin. She helps clients throughout completely different industries to combine Generative AI into their current purposes and workflows. She is obsessed with AI/ML, finance and software program safety subjects. In her spare time, she enjoys spending time along with her household, sports activities, studying new applied sciences, and desk quizzes.
Liza (Elizaveta) Zinovyeva is an Utilized Scientist at AWS Generative AI Innovation Heart and relies in Berlin. She helps clients throughout completely different industries to combine Generative AI into their current purposes and workflows. She is obsessed with AI/ML, finance and software program safety subjects. In her spare time, she enjoys spending time along with her household, sports activities, studying new applied sciences, and desk quizzes.
 Nuno Castro is a Sr. Utilized Science Supervisor at AWS Generative AI Innovation Heart. He leads Generative AI buyer engagements, serving to a whole lot of AWS clients discover essentially the most impactful use case from ideation, prototype by to manufacturing. He has 19 years expertise in AI in industries comparable to finance, manufacturing, and journey, main AI/ML groups for 12 years.
Nuno Castro is a Sr. Utilized Science Supervisor at AWS Generative AI Innovation Heart. He leads Generative AI buyer engagements, serving to a whole lot of AWS clients discover essentially the most impactful use case from ideation, prototype by to manufacturing. He has 19 years expertise in AI in industries comparable to finance, manufacturing, and journey, main AI/ML groups for 12 years.
 Ozioma Uzoegwu is a Principal Options Architect at Amazon Internet Companies. In his position, he helps monetary providers clients throughout EMEA to rework and modernize on the AWS Cloud, offering architectural steerage and {industry} finest practices. Ozioma has a few years of expertise with internet growth, structure, cloud and IT administration. Previous to becoming a member of AWS, Ozioma labored with an AWS Superior Consulting Companion because the Lead Architect for the AWS Observe. He’s obsessed with utilizing newest applied sciences to construct a contemporary monetary providers IT property throughout banking, cost, insurance coverage and capital markets.
Ozioma Uzoegwu is a Principal Options Architect at Amazon Internet Companies. In his position, he helps monetary providers clients throughout EMEA to rework and modernize on the AWS Cloud, offering architectural steerage and {industry} finest practices. Ozioma has a few years of expertise with internet growth, structure, cloud and IT administration. Previous to becoming a member of AWS, Ozioma labored with an AWS Superior Consulting Companion because the Lead Architect for the AWS Observe. He’s obsessed with utilizing newest applied sciences to construct a contemporary monetary providers IT property throughout banking, cost, insurance coverage and capital markets.
 Eren Tuncer is a Options Architect at Amazon Internet Companies centered on Serverless and constructing Generative AI purposes. With greater than fifteen years expertise in software program growth and structure, he helps clients throughout numerous industries obtain their enterprise targets utilizing cloud applied sciences with finest practices. As a builder, he’s obsessed with creating options with state-of-the-art applied sciences, sharing data, and serving to organizations navigate cloud adoption.
Eren Tuncer is a Options Architect at Amazon Internet Companies centered on Serverless and constructing Generative AI purposes. With greater than fifteen years expertise in software program growth and structure, he helps clients throughout numerous industries obtain their enterprise targets utilizing cloud applied sciences with finest practices. As a builder, he’s obsessed with creating options with state-of-the-art applied sciences, sharing data, and serving to organizations navigate cloud adoption.
 Francesco Cerizzi is a Options Architect at Amazon Internet Companies exploring tech frontiers whereas spreading generative AI data and constructing purposes. With a background as a full stack developer, he helps clients throughout completely different industries of their journey to the cloud, sharing insights on AI’s transformative potential alongside the way in which. He’s obsessed with Serverless, event-driven architectures, and microservices usually. When not diving into expertise, he’s an enormous F1 fan and loves Tennis.
Francesco Cerizzi is a Options Architect at Amazon Internet Companies exploring tech frontiers whereas spreading generative AI data and constructing purposes. With a background as a full stack developer, he helps clients throughout completely different industries of their journey to the cloud, sharing insights on AI’s transformative potential alongside the way in which. He’s obsessed with Serverless, event-driven architectures, and microservices usually. When not diving into expertise, he’s an enormous F1 fan and loves Tennis.



{kind=link}