
Substitute conventional NLP approaches with immediate engineering and Giant Language Fashions (LLMS) for Jira ticket textual content classification. A code pattern walkthrough
Keep in mind the times when classifying textual content meant embarking on a machine studying journey? For those who’ve been within the ML house lengthy sufficient, you’ve most likely witnessed at the least one workforce disappear down the rabbit gap of constructing the “good” textual content classification system. The story normally goes one thing like this:
- Month 1: “We’ll simply shortly practice a NLP mannequin!”
- Month 2: “We’d like extra coaching information…”
- Month 3: “That is ok”
For years, textual content classification has fallen into the realm of traditional ML. Early in my profession, I keep in mind coaching a assist vector machine (SVM) for e mail classification. Numerous preprocessing, iteration, information assortment, and labeling.
However right here’s the twist: it’s 2024, and generative AI fashions can “typically” classify textual content out of the field! You may construct a sturdy ticket classification system with out, gathering hundreds of labeled coaching examples, managing ML coaching pipelines, or sustaining customized fashions.
On this publish, we’ll go over the way to setup a Jira ticket classification system utilizing giant language fashions on Amazon Bedrock and different AWS providers.
DISCLAIMER: I’m a GenAI Architect at AWS and my opinions are my very own.
Why Classify Jira Tickets?
A typical ask from firms is to know how groups spend their time. Jira has tagging options, however it will probably typically fall quick by human error or lack of granularity. By doing this train, organizations can get higher insights into their workforce actions, enabling data-driven selections about useful resource allocation, challenge funding, and deprecation.
Why Not Use Different NLP Approaches?
Conventional ML fashions and smaller transformers like BERT want tons of (or hundreds) of labeled examples, whereas LLMs can classify textual content out of the field. In our Jira ticket classification exams, a prompt-engineering strategy matched or beat conventional ML fashions, processing 10k+ annual tickets for ~$10/yr utilizing Claude Haiku (excluding different AWS Service prices). Additionally, prompts are simpler to replace than retraining fashions.
This github repo incorporates a pattern utility that connects to Jira Cloud, classifies tickets, and outputs them in a format that may be consumed by your favourite dashboarding device (Tableu, Quicksight, or every other device that helps CSVs).
Essential Discover: This challenge deploys assets in your AWS surroundings utilizing Terraform. You’ll incur prices for the AWS assets used. Please concentrate on the pricing for providers like Lambda, Bedrock, Glue, and S3 in your AWS area.
Pre Requisites
You’ll must have terraform put in and the AWS CLI put in within the surroundings you wish to deploy this code from
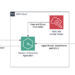
The structure is fairly straight ahead. Yow will discover particulars under.

Step 1: An AWS Lambda perform is triggered on a cron job to fetch jira tickets primarily based on a time window. These tickets are then formatted and pushed to an S3 bucket underneath the /unprocessed prefix.
Step 2: A Glue job is triggered off /unprocessed object places. This runs a PySpark deduplication job to make sure no duplicate tickets make their method to the dashboard. The deduplicated tickets are then put to the /staged prefix. That is helpful for instances the place you manually add tickets in addition to depend on the automated fetch. For those who can guarantee no duplicates, you possibly can take away this step.
Step 3: A classification job is kicked off on the brand new tickets by calling Amazon Bedrock to categorise the tickets primarily based on a immediate to a big language mannequin (LLM). After classification, the completed outcomes are pushed to the /processed prefix. From right here, you possibly can decide up the processed CSV utilizing any dashboarding device you’d like that may devour a CSV.
To get began, clone the github repo above and transfer to the /terraform listing
$ git clone https://github.com/aws-samples/jira-ticket-classification.git$ cd jira-ticket-classification/terraform
Run terraform init, plan, & apply. Ensure you have terraform put in in your pc and the AWS CLI configured.
$ terraform init$ terraform plan
$ terraform apply
As soon as the infrastructure is deployed into your account, you possibly can navigate to AWS Secrets and techniques Supervisor and replace the key along with your Jira Cloud credentials. You’ll want an API key, base url, and e mail to allow the automated pull

And that’s it!
You may (1) await the Cron to kick off an automated fetch, (2) export the tickets to CSV and add them to the /unprocessed S3 bucket prefix, or (3) manually set off the Lambda perform utilizing a take a look at.
Jira Fetch:
Jira fetch makes use of a Lambda perform with a Cloudwatch cron occasion to set off it. The Lambda pulls within the AWS Secret and makes use of a get request shortly loop to retrieve paginated outcomes till the JQL question completes:
def fetch_jira_issues(base_url, project_id, e mail, api_key):
url = f"{base_url}/relaxation/api/3/search"# Calculate the date 8 days in the past
eight_days_ago = (datetime.now() - timedelta(days=8)).strftime("%Y-%m-%d")
# Create JQL
jql = f"challenge = {project_id} AND created >= '{eight_days_ago}' ORDER BY created DESC"
# Go into params of request.
params = {
"jql": jql,
"startAt": 0
}
all_issues = []
auth = HTTPBasicAuth(e mail, api_key)
headers = {"Settle for": "utility/json"}
whereas True:
response = requests.get(url, headers=headers, params=params, auth=auth)
if response.status_code != 200:
increase Exception(f"Didn't fetch points for challenge {project_id}: {response.textual content}")
information = json.hundreds(response.textual content)
points = information['issues']
all_issues.prolong(points)
if len(all_issues) >= information['total']:
break
params['startAt'] = len(all_issues)
return all_issues
It then creates a string illustration of a CSV and uploads it into S3:
def upload_to_s3(csv_string, bucket, key):
strive:
s3_client.put_object(
Bucket=bucket,
Key=key,
Physique=csv_string,
ContentType='textual content/csv'
)
besides Exception as e:
increase Exception(f"Didn't add CSV to S3: {str(e)}")
Glue Job
An S3 occasion on the /unprocessed prefix kicks off a second lambda that begins an AWS Glue job. That is helpful when there’s a number of entry factors that Jira tickets can enter the system by. For instance, if you wish to do a backfill.
import boto3 # Initialize Boto3 Glue shopper
glue_client = boto3.shopper('glue')
def handler(occasion, context):
# Print occasion for debugging
print(f"Obtained occasion: {json.dumps(occasion)}")
# Get bucket title and object key (file title) from the S3 occasion
strive:
s3_event = occasion['Records'][0]['s3']
s3_bucket = s3_event['bucket']['name']
s3_key = s3_event['object']['key']
besides KeyError as e:
print(f"Error parsing S3 occasion: {str(e)}")
increase
response = glue_client.start_job_run(
JobName=glue_job_name,
Arguments={
'--S3_BUCKET': s3_bucket,
'--NEW_CSV_FILE': s3_key
}
)
The Glue job itself is written in PySpark and might be discovered within the code repo right here. The essential take away is that it does a leftanti be a part of utilizing the problem Ids on the objects within the new CSV towards all of the Ids within the /staged CSVs.
The outcomes are then pushed to the /staged prefix.
Classify Jira Tickets:
That is the place it it will get attention-grabbing. Because it seems, utilizing immediate engineering can carry out on par, if not higher, than a textual content classification mannequin utilizing a pair strategies.
- You may outline the classifications and their descriptions in a immediate,
- Ask the mannequin to suppose step-by-step (Chain of Thought).
- After which output the classification with out having to coach a single mannequin. See the immediate under:
Word: It’s essential to validate your immediate utilizing a human curated subset of categorized / labelled tickets. It’s best to run this immediate by the validation dataset to verify it aligns with the way you anticipate the tickets to be categorized
SYSTEM_PROMPT = '''
You're a assist ticket assistant. You might be given fields of a Jira ticket and your job is to categorise the ticket primarily based on these fieldsUnder is the listing of potential classifications together with descriptions of these classifications.
ACCESS_PERMISSIONS_REQUEST: Used when somebody would not have the write permissions or cannot log in to one thing or they cannot get the proper IAM credentials to make a service work.
BUG_FIXING: Used when one thing is failing or a bug is discovered. Typically instances the descriptions embrace logs or technical info.
CREATING_UPDATING_OR_DEPRECATING_DOCUMENTATION: Used when documentation is outdated. Normally references documentation within the textual content.
MINOR_REQUEST: That is hardly ever used. Normally a bug repair however it's very minor. If it appears even remotely difficult use BUG_FIXING.
SUPPORT_TROUBLESHOOTING: Used when asking for assist for some engineering occasion. May also appear like an automatic ticket.
NEW_FEATURE_WORK: Normally describes a brand new function ask or one thing that is not operational.
The fields obtainable and their descriptions are under.
Summmary: This can be a abstract or title of the ticket
Description: The outline of the problem in pure language. The vast majority of context wanted to categorise the textual content will come from this subject
* It's doable that some fields could also be empty by which case ignore them when classifying the ticket
* Assume by your reasoning earlier than making the classification and place your thought course of in
* After you have completed considering, classify the ticket utilizing ONLY the classifications listed above and place it in
USER_PROMPT = '''
Utilizing solely the ticket fields under:
{abstract}
{description}
Classify the ticket utilizing ONLY 1 of the classifications listed within the system immediate. Keep in mind to suppose step-by-step earlier than classifying the ticket and place your ideas in
When you find yourself completed considering, classify the ticket and place your reply in
'''
We’ve added a helper class that threads the calls to Bedrock to hurry issues up:
import boto3
from concurrent.futures import ThreadPoolExecutor, as_completed
import re
from typing import Record, Dict
from prompts import USER_PROMPT, SYSTEM_PROMPTclass TicketClassifier:
SONNET_ID = "anthropic.claude-3-sonnet-20240229-v1:0"
HAIKU_ID = "anthropic.claude-3-haiku-20240307-v1:0"
HYPER_PARAMS = {"temperature": 0.35, "topP": .3}
REASONING_PATTERN = r'(.*?) '
CORRECTNESS_PATTERN = r'(.*?) '
def __init__(self):
self.bedrock = boto3.shopper('bedrock-runtime')
def classify_tickets(self, tickets: Record[Dict[str, str]]) -> Record[Dict[str, str]]:
prompts = [self._create_chat_payload(t) for t in tickets]
responses = self._call_threaded(prompts, self._call_bedrock)
formatted_responses = [self._format_results(r) for r in responses]
return [{**d1, **d2} for d1, d2 in zip(tickets, formatted_responses)]
def _call_bedrock(self, message_list: listing[dict]) -> str:
response = self.bedrock.converse(
modelId=self.HAIKU_ID,
messages=message_list,
inferenceConfig=self.HYPER_PARAMS,
system=[{"text": SYSTEM_PROMPT}]
)
return response['output']['message']['content'][0]['text']
def _call_threaded(self, requests, perform):
future_to_position = {}
with ThreadPoolExecutor(max_workers=5) as executor:
for i, request in enumerate(requests):
future = executor.submit(perform, request)
future_to_position[future] = i
responses = [None] * len(requests)
for future in as_completed(future_to_position):
place = future_to_position[future]
strive:
response = future.end result()
responses[position] = response
besides Exception as exc:
print(f"Request at place {place} generated an exception: {exc}")
responses[position] = None
return responses
def _create_chat_payload(self, ticket: dict) -> dict:
user_prompt = USER_PROMPT.format(abstract=ticket['Summary'], description=ticket['Description'])
user_msg = {"position": "person", "content material": [{"text": user_prompt}]}
return [user_msg]
def _format_results(self, model_response: str) -> dict:
reasoning = self._extract_with_regex(model_response, self.REASONING_PATTERN)
correctness = self._extract_with_regex(model_response, self.CORRECTNESS_PATTERN)
return {'Mannequin Reply': correctness, 'Reasoning': reasoning}
@staticmethod
def _extract_with_regex(response, regex):
matches = re.search(regex, response, re.DOTALL)
return matches.group(1).strip() if matches else None
Lastly, the categorized tickets are transformed to a CSV and uploaded to S3
import boto3
import io
import csvs3 = boto3.shopper('s3')
def upload_csv(information: Record[Dict[str, str]]) -> None:
csv_buffer = io.StringIO()
author = csv.DictWriter(csv_buffer, fieldnames=information[0].keys())
author.writeheader()
author.writerows(information)
current_time = datetime.now().strftime("%Ypercentmpercentd_percentHpercentMpercentS")
filename = f"processed/processed_{current_time}.csv"
s3.put_object(
Bucket=self.bucket_name,
Key=filename,
Physique=csv_buffer.getvalue()
)
The challenge is dashboard agnostic. Any in style device/service will work so long as it will probably devour a CSV. Amazon Quicksight, Tableu or something in between will do.
On this weblog we mentioned utilizing Bedrock to mechanically classify Jira tickets. These enriched tickets can then be used to create dashboards utilizing numerous AWS Providers or 3P instruments. The takeaway, is that classifying textual content has grow to be a lot less complicated for the reason that adoption of LLMs and what would have taken weeks can now be accomplished in days.
For those who loved this text be at liberty to attach with me on LinkedIn


{kind=link}