Recordings of enterprise conferences, interviews, and buyer interactions have grow to be important for preserving vital data. Nonetheless, transcribing and summarizing these recordings manually is commonly time-consuming and labor-intensive. With the progress in generative AI and automated speech recognition (ASR), automated options have emerged to make this course of sooner and extra environment friendly.
Defending personally identifiable data (PII) is an important side of knowledge safety, pushed by each moral obligations and authorized necessities. On this put up, we reveal the best way to use the Open AI Whisper basis mannequin (FM) Whisper Giant V3 Turbo, accessible in Amazon Bedrock Market, which provides entry to over 140 fashions by way of a devoted providing, to provide close to real-time transcription. These transcriptions are then processed by Amazon Bedrock for summarization and redaction of delicate data.
Amazon Bedrock is a totally managed service that gives a selection of high-performing FMs from main AI firms like AI21 Labs, Anthropic, Cohere, DeepSeek, Luma, Meta, Mistral AI, poolside (coming quickly), Stability AI, and Amazon Nova by way of a single API, together with a broad set of capabilities to construct generative AI functions with safety, privateness, and accountable AI. Moreover, you should utilize Amazon Bedrock Guardrails to robotically redact delicate data, together with PII, from the transcription summaries to help compliance and knowledge safety wants.
On this put up, we stroll by way of an end-to-end structure that mixes a React-based frontend with Amazon Bedrock, AWS Lambda, and AWS Step Capabilities to orchestrate the workflow, facilitating seamless integration and processing.
Resolution overview
The answer highlights the facility of integrating serverless applied sciences with generative AI to automate and scale content material processing workflows. The person journey begins with importing a recording by way of a React frontend software, hosted on Amazon CloudFront and backed by Amazon Easy Storage Service (Amazon S3) and Amazon API Gateway. When the file is uploaded, it triggers a Step Capabilities state machine that orchestrates the core processing steps, utilizing AI fashions and Lambda capabilities for seamless knowledge circulate and transformation. The next diagram illustrates the answer structure.

The workflow consists of the next steps:
- The React software is hosted in an S3 bucket and served to customers by way of CloudFront for quick, international entry. API Gateway handles interactions between the frontend and backend providers.
- Customers add audio or video recordsdata instantly from the app. These recordings are saved in a chosen S3 bucket for processing.
- An Amazon EventBridge rule detects the S3 add occasion and triggers the Step Capabilities state machine, initiating the AI-powered processing pipeline.
- The state machine performs audio transcription, summarization, and redaction by orchestrating a number of Amazon Bedrock fashions in sequence. It makes use of Whisper for transcription, Claude for summarization, and Guardrails to redact delicate knowledge.
- The redacted abstract is returned to the frontend software and exhibited to the person.
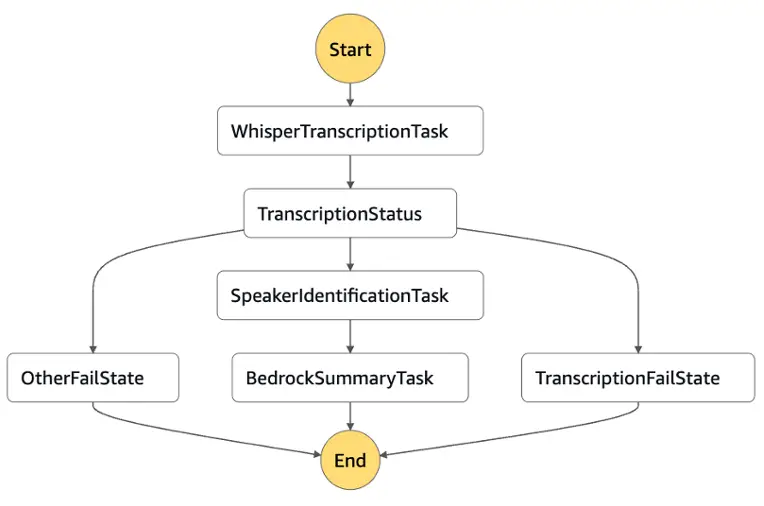
The next diagram illustrates the state machine workflow.

The Step Capabilities state machine orchestrates a sequence of duties to transcribe, summarize, and redact delicate data from uploaded audio/video recordings:
- A Lambda perform is triggered to collect enter particulars (for instance, Amazon S3 object path, metadata) and put together the payload for transcription.
- The payload is shipped to the OpenAI Whisper Giant V3 Turbo mannequin by way of the Amazon Bedrock Market to generate a close to real-time transcription of the recording.
- The uncooked transcript is handed to Anthropic’s Claude Sonnet 3.5 by way of Amazon Bedrock, which produces a concise and coherent abstract of the dialog or content material.
- A second Lambda perform validates and forwards the abstract to the redaction step.
- The abstract is processed by way of Amazon Bedrock Guardrails, which robotically redacts PII and different delicate knowledge.
- The redacted abstract is saved or returned to the frontend software by way of an API, the place it’s exhibited to the person.
Stipulations
Earlier than you begin, just be sure you have the next conditions in place:
Create a guardrail within the Amazon Bedrock console
For directions for creating guardrails in Amazon Bedrock, seek advice from Create a guardrail. For particulars on detecting and redacting PII, see Take away PII from conversations by utilizing delicate data filters. Configure your guardrail with the next key settings:
- Allow PII detection and dealing with
- Set PII motion to Redact
- Add the related PII varieties, akin to:
- Names and identities
- Telephone numbers
- E mail addresses
- Bodily addresses
- Monetary data
- Different delicate private data
After you deploy the guardrail, observe the Amazon Useful resource Identify (ARN), and you can be utilizing this when deploys the mannequin.
Deploy the Whisper mannequin
Full the next steps to deploy the Whisper Giant V3 Turbo mannequin:
- On the Amazon Bedrock console, select Mannequin catalog underneath Basis fashions within the navigation pane.
- Seek for and select Whisper Giant V3 Turbo.
- On the choices menu (three dots), select Deploy.

- Modify the endpoint title, variety of cases, and occasion kind to fit your particular use case. For this put up, we use the default settings.
- Modify the Superior settings part to fit your use case. For this put up, we use the default settings.
- Select Deploy.
This creates a brand new AWS Identification and Entry Administration IAM position and deploys the mannequin.
You’ll be able to select Market deployments within the navigation pane, and within the Managed deployments part, you may see the endpoint standing as Creating. Await the endpoint to complete deployment and the standing to vary to In Service, then copy the Endpoint Identify, and you can be utilizing this when deploying the

Deploy the answer infrastructure
Within the GitHub repo, comply with the directions within the README file to clone the repository, then deploy the frontend and backend infrastructure.
We use the AWS Cloud Growth Equipment (AWS CDK) to outline and deploy the infrastructure. The AWS CDK code deploys the next assets:
- React frontend software
- Backend infrastructure
- S3 buckets for storing uploads and processed outcomes
- Step Capabilities state machine with Lambda capabilities for audio processing and PII redaction
- API Gateway endpoints for dealing with requests
- IAM roles and insurance policies for safe entry
- CloudFront distribution for internet hosting the frontend
Implementation deep dive
The backend consists of a sequence of Lambda capabilities, every dealing with a selected stage of the audio processing pipeline:
- Add handler – Receives audio recordsdata and shops them in Amazon S3
- Transcription with Whisper – Converts speech to textual content utilizing the Whisper mannequin
- Speaker detection – Differentiates and labels particular person audio system throughout the audio
- Summarization utilizing Amazon Bedrock – Extracts and summarizes key factors from the transcript
- PII redaction – Makes use of Amazon Bedrock Guardrails to take away delicate data for privateness compliance
Let’s study a few of the key parts:
The transcription Lambda perform makes use of the Whisper mannequin to transform audio recordsdata to textual content:
def transcribe_with_whisper(audio_chunk, endpoint_name):
# Convert audio to hex string format
hex_audio = audio_chunk.hex()
# Create payload for Whisper mannequin
payload = {
"audio_input": hex_audio,
"language": "english",
"activity": "transcribe",
"top_p": 0.9
}
# Invoke the SageMaker endpoint working Whisper
response = sagemaker_runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="software/json",
Physique=json.dumps(payload)
)
# Parse the transcription response
response_body = json.masses(response['Body'].learn().decode('utf-8'))
transcription_text = response_body['text']
return transcription_text
We use Amazon Bedrock to generate concise summaries from the transcriptions:
def generate_summary(transcription):
# Format the immediate with the transcription
immediate = f"{transcription}nnGive me the abstract, audio system, key discussions, and motion objects with house owners"
# Name Bedrock for summarization
response = bedrock_runtime.invoke_model(
modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
physique=json.dumps({
"immediate": immediate,
"max_tokens_to_sample": 4096,
"temperature": 0.7,
"top_p": 0.9,
})
)
# Extract and return the abstract
consequence = json.masses(response.get('physique').learn())
return consequence.get('completion')A important element of our resolution is the automated redaction of PII. We applied this utilizing Amazon Bedrock Guardrails to help compliance with privateness laws:
def apply_guardrail(bedrock_runtime, content material, guardrail_id):
# Format content material based on API necessities
formatted_content = [{"text": {"text": content}}]
# Name the guardrail API
response = bedrock_runtime.apply_guardrail(
guardrailIdentifier=guardrail_id,
guardrailVersion="DRAFT",
supply="OUTPUT", # Utilizing OUTPUT parameter for correct circulate
content material=formatted_content
)
# Extract redacted textual content from response
if 'motion' in response and response['action'] == 'GUARDRAIL_INTERVENED':
if len(response['outputs']) > 0:
output = response['outputs'][0]
if 'textual content' in output and isinstance(output['text'], str):
return output['text']
# Return unique content material if redaction fails
return content materialWhen PII is detected, it’s changed with kind indicators (for instance, {PHONE} or {EMAIL}), ensuring that summaries stay informative whereas defending delicate knowledge.
To handle the complicated processing pipeline, we use Step Capabilities to orchestrate the Lambda capabilities:
{
"Remark": "Audio Summarization Workflow",
"StartAt": "TranscribeAudio",
"States": {
"TranscribeAudio": {
"Sort": "Process",
"Useful resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "WhisperTranscriptionFunction",
"Payload": {
"bucket": "$.bucket",
"key": "$.key"
}
},
"Subsequent": "IdentifySpeakers"
},
"IdentifySpeakers": {
"Sort": "Process",
"Useful resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "SpeakerIdentificationFunction",
"Payload": {
"Transcription.$": "$.Payload"
}
},
"Subsequent": "GenerateSummary"
},
"GenerateSummary": {
"Sort": "Process",
"Useful resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "BedrockSummaryFunction",
"Payload": {
"SpeakerIdentification.$": "$.Payload"
}
},
"Finish": true
}
}
}This workflow makes positive every step completes efficiently earlier than continuing to the subsequent, with automated error dealing with and retry logic in-built.
Check the answer
After you could have efficiently accomplished the deployment, you should utilize the CloudFront URL to check the answer performance.

Safety issues
Safety is a important side of this resolution, and we’ve applied a number of greatest practices to help knowledge safety and compliance:
- Delicate knowledge redaction – Robotically redact PII to guard person privateness.
- High quality-Grained IAM Permissions – Apply the precept of least privilege throughout AWS providers and assets.
- Amazon S3 entry controls – Use strict bucket insurance policies to restrict entry to licensed customers and roles.
- API safety – Safe API endpoints utilizing Amazon Cognito for person authentication (non-compulsory however advisable).
- CloudFront safety – Implement HTTPS and apply trendy TLS protocols to facilitate safe content material supply.
- Amazon Bedrock knowledge safety – Amazon Bedrock (together with Amazon Bedrock Market) protects buyer knowledge and doesn’t ship knowledge to suppliers or prepare utilizing buyer knowledge. This makes positive your proprietary data stays safe when utilizing AI capabilities.
Clear up
To stop pointless costs, be certain that to delete the assets provisioned for this resolution once you’re performed:
- Delete the Amazon Bedrock guardrail:
- On the Amazon Bedrock console, within the navigation menu, select Guardrails.
- Select your guardrail, then select Delete.
- Delete the Whisper Giant V3 Turbo mannequin deployed by way of the Amazon Bedrock Market:
- On the Amazon Bedrock console, select Market deployments within the navigation pane.
- Within the Managed deployments part, choose the deployed endpoint and select Delete.
- Delete the AWS CDK stack by working the command
cdk destroy, which deletes the AWS infrastructure.
Conclusion
This serverless audio summarization resolution demonstrates the advantages of mixing AWS providers to create a complicated, safe, and scalable software. Through the use of Amazon Bedrock for AI capabilities, Lambda for serverless processing, and CloudFront for content material supply, we’ve constructed an answer that may deal with giant volumes of audio content material effectively whereas serving to you align with safety greatest practices.
The automated PII redaction characteristic helps compliance with privateness laws, making this resolution well-suited for regulated industries akin to healthcare, finance, and authorized providers the place knowledge safety is paramount. To get began, deploy this structure inside your AWS setting to speed up your audio processing workflows.
In regards to the Authors
 Kaiyin Hu is a Senior Options Architect for Strategic Accounts at Amazon Internet Providers, with years of expertise throughout enterprises, startups, {and professional} providers. At present, she helps prospects construct cloud options and drives GenAI adoption to cloud. Beforehand, Kaiyin labored within the Good Residence area, helping prospects in integrating voice and IoT applied sciences.
Kaiyin Hu is a Senior Options Architect for Strategic Accounts at Amazon Internet Providers, with years of expertise throughout enterprises, startups, {and professional} providers. At present, she helps prospects construct cloud options and drives GenAI adoption to cloud. Beforehand, Kaiyin labored within the Good Residence area, helping prospects in integrating voice and IoT applied sciences.
 Sid Vantair is a Options Architect with AWS masking Strategic accounts. He thrives on resolving complicated technical points to beat buyer hurdles. Exterior of labor, he cherishes spending time together with his household and fostering inquisitiveness in his kids.
Sid Vantair is a Options Architect with AWS masking Strategic accounts. He thrives on resolving complicated technical points to beat buyer hurdles. Exterior of labor, he cherishes spending time together with his household and fostering inquisitiveness in his kids.



{kind=link}