(AWS) are the world’s two largest cloud computing platforms, offering database, community, and compute assets at world scale. Collectively, they maintain about 50% of the worldwide enterprise cloud infrastructure companies market—AWS at 30% and Azure at 20%. Azure ML and AWS SageMaker are machine studying companies that allow knowledge scientists and ML engineers to develop and handle your complete ML lifecycle, from knowledge preprocessing and have engineering to mannequin coaching, deployment, and monitoring. You possibly can create and handle these ML companies in AWS and Azure by console interfaces, or cloud CLI, or software program improvement kits (SDK) in your most well-liked programming language – the method mentioned on this article.
Azure ML & AWS SageMaker Coaching Jobs
Whereas they provide comparable high-level functionalities, Azure ML and AWS SageMaker have basic variations that decide which platform most accurately fits you, your workforce, or your organization. Firstly, think about the ecosystem of the present knowledge storage, compute assets, and monitoring companies. As an example, if your organization’s knowledge primarily sits in an AWS S3 bucket, then SageMaker might turn out to be a extra pure alternative for creating your ML companies, because it reduces the overhead of connecting to and transferring knowledge throughout totally different cloud suppliers. Nevertheless, this doesn’t imply that different components should not price contemplating, and we are going to dive into the main points of how Azure ML differs from AWS SageMaker in a standard ML state of affairs—coaching and constructing fashions at scale utilizing jobs.
Though Jupyter notebooks are worthwhile for experimentation and exploration in an interactive improvement workflow on a single gadget, they don’t seem to be designed for productionization or distribution. Coaching jobs (and different ML jobs) turn out to be important within the ML workflow at this stage by deploying the duty to a number of cloud situations so as to run for an extended time, and course of extra knowledge. This requires organising the information, code, compute situations and runtime environments to make sure constant outputs when it’s not executed on one native machine. Consider it just like the distinction between creating a dinner recipe (Jupyter pocket book) and hiring a catering workforce to prepare dinner it for 500 clients (ML job). It wants everybody within the catering workforce to entry the identical elements, recipe and instruments, following the identical cooking process.
Now that we perceive the significance of coaching jobs, let’s have a look at how they’re outlined in Azure ML vs. SageMaker in a nutshell.
Outline Azure ML coaching job
from azure.ai.ml import command
job = command(
code=...
command=...
setting=...
compute=...
)
ml_client.jobs.create_or_update(job)Create SageMaker coaching job estimator
from sagemaker.estimator import Estimator
estimator = Estimator(
image_uri=...
position=...
instance_type=...
)
estimator.match(training_data_s3_location)We’ll break down the comparability into following dimensions:
- Undertaking and Permission Administration
- Information storage
- Compute
- Surroundings
Partially 1, we are going to begin with evaluating the high-level challenge setup and permission administration, then discuss storing and accessing the information required for mannequin coaching. Half 2 will talk about varied compute choices underneath each cloud platforms, and create and handle runtime environments for coaching jobs.
Undertaking and Permission Administration
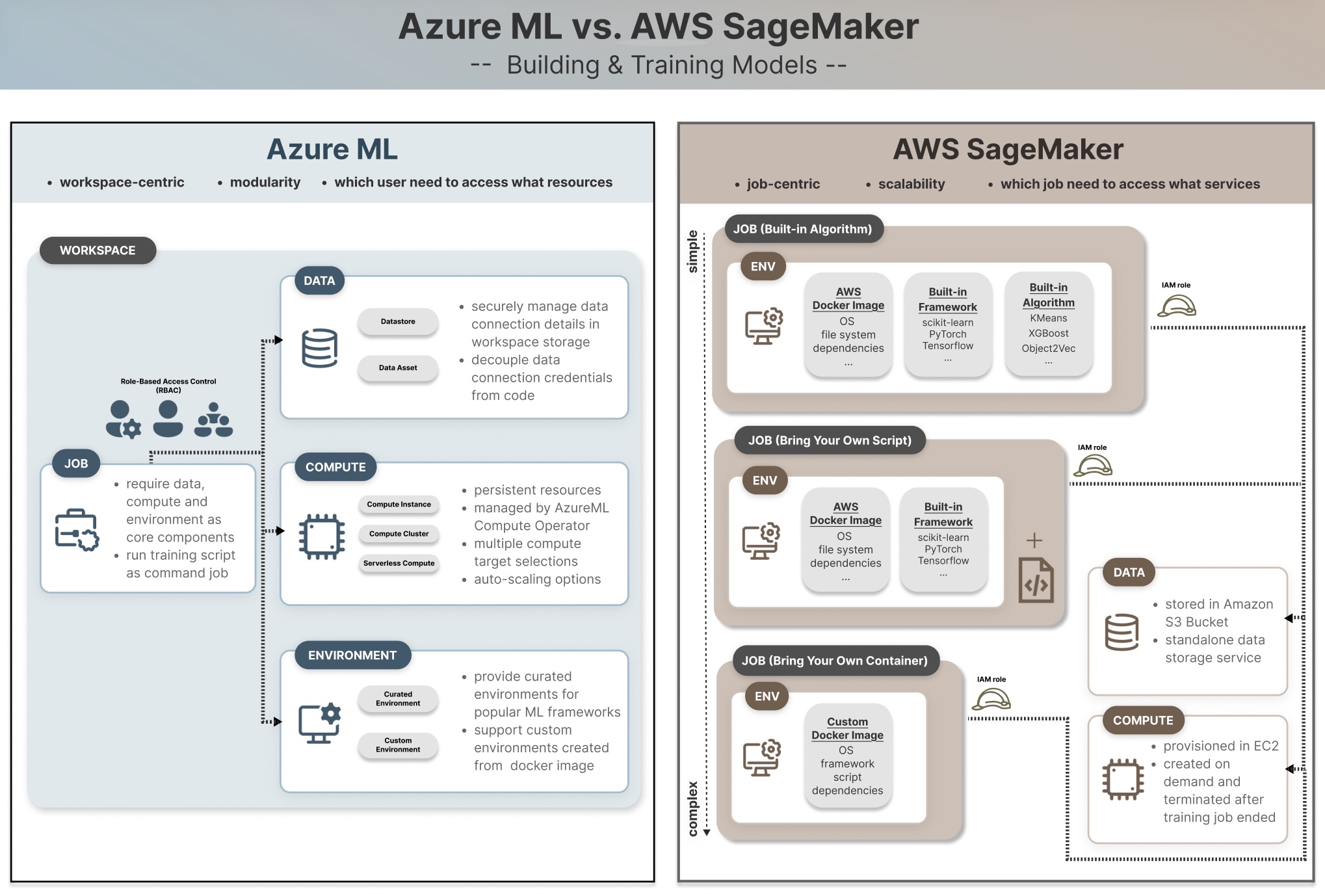
Let’s begin by understanding a typical ML workflow in a medium-to-large workforce of knowledge scientists, knowledge engineers, and ML engineers. Every member might specialise in a particular position and duty, and assigned to a number of tasks. For instance, an information engineer is tasked with extracting knowledge from the supply and storing it in a centralized location for knowledge scientists to course of. They don’t have to spin up compute situations for working coaching jobs. On this case, they could have learn and write entry to the information storage location however don’t essentially want entry to create GPU situations for heavy workloads. Relying on knowledge sensitivity and their position in an ML challenge, workforce members want totally different ranges of entry to the information and underlying cloud infrastructure. We’re going to discover how two cloud platforms construction their assets and companies to steadiness the necessities of workforce collaboration and duty separation.
Azure ML

Undertaking administration in Azure ML is Workspace-centric, beginning by making a Workspace (underneath your Azure subscription ID and useful resource group) for storing related useful resource and property, and shared throughout the challenge workforce for collaboration.
Permissions to entry and handle assets are granted on the user-level primarily based on their roles – i.e. role-based entry management (RBAC). Generic roles in Azure embody proprietor, contributor and reader. ML specialised roles embody AzureML Information Scientist and AzureML Compute Operator, which is accountable for creating and managing compute situations as they’re usually the most important value ingredient in an ML challenge. The targets of organising an Azure ML Workspace is to create a contained environments for storing knowledge, compute, mannequin and different assets, in order that solely customers inside the Workspace are given related entry to learn or edit the information property, use current or create new compute situations primarily based on their duties.
Within the code snippet beneath, we connect with the Azure ML workspace by MLClient by passing the workspace’s subscription ID, useful resource group and the default credential – Azure follows the hierarchical construction Subscription > Useful resource Group > Workspace.
Upon workspace creation, related companies like an Azure Storage Account (shops metadata and artifacts and may retailer coaching knowledge) and an Azure Key Vault (shops secrets and techniques like usernames, passwords, and credentials) are additionally instantiated mechanically.
from azure.ai.ml import MLClient
from azure.identification import DefaultAzureCredential
subscription_id = ''
resource_group = ''
workspace = ''
# Hook up with the workspace
credential = DefaultAzureCredential()
ml_client = MLClient(credential, subscription, resource_group, workspace) When builders run the code throughout an interactive improvement session, the workspace connection is authenticated by the developer’s private credentials. They might be capable to create a coaching job utilizing the command ml_client.jobs.create_or_update(job) as demonstrated beneath. To detach private account credentials within the manufacturing setting, it’s endorsed to make use of a service principal account to authenticate for automated pipelines or scheduled jobs. Extra info could be discovered on this article “Authenticate in your workspace utilizing a service principal”.
# Outline Azure ML coaching job
from azure.ai.ml import command
job = command(
code=...
command=...
setting=...
compute=...
)
ml_client.jobs.create_or_update(job)AWS SageMaker

Roles and permissions in SageMaker are designed primarily based on a very totally different precept, primarily utilizing “Roles” in AWS Identification Entry Administration (IAM) service. Though IAM permits creating user-level (or account-level) entry just like Azure, AWS recommends granting permissions on the job-level all through the ML lifecycle. On this method, your private AWS permissions are irrelevant at runtime and SageMaker assumes a job (i.e. SageMaker execution position) to entry related AWS companies, akin to S3 bucket, SageMaker Coaching Pipeline, compute situations for executing the job.
For instance, here’s a fast peek of organising an Estimator with the SageMaker execution position for working the Coaching Job.
import sagemaker
from sagemaker.estimator import Estimator
# Get the SageMaker execution position
position = sagemaker.get_execution_role()
# Outline the estimator
estimator = Estimator(
image_uri=image_uri,
position=position, # assume the SageMaker execution position throughout runtime
instance_type="ml.m5.xlarge",
instance_count=1,
)
# Begin coaching
estimator.match("s3://my-training-bucket/prepare/")
It signifies that we will arrange sufficient granularity to grant position permissions to run solely coaching jobs within the improvement setting however not touching the manufacturing setting. For instance, the position is given entry to an S3 bucket that holds take a look at knowledge and is blocked from the one which holds manufacturing knowledge, then the coaching job that assumes this position received’t have the prospect to overwrite the manufacturing knowledge accidentally.
Permission Administration in AWS is a complicated area by itself, and I received’t fake I can absolutely clarify this matter. I like to recommend studying this text for extra finest practices from AWS official documentation “Permissions administration“.
What does this imply in observe?
- Azure ML: Azure’s Function Primarily based Entry Management (RBAC) matches corporations or groups that handle which consumer have to entry what assets. Extra intuitive to know and helpful for centralized consumer entry management.
- AWS SageMaker AI: AWS matches methods that care about which job have to entry what companies. Decouple particular person consumer permissions with job execution for higher automation and MLOps practices. AWS matches for giant knowledge science workforce with granular job and pipeline definitions and remoted environments.
Reference
Information Storage
You’ll have the query — can I retailer the information within the working listing? Not less than that’s been my query for a very long time, and I consider the reply continues to be sure if you’re experimenting or prototyping utilizing a easy script or pocket book in an interactive improvement setting. However knowledge storage location is necessary to contemplate within the context of making ML jobs.
Since code runs in a cloud-managed setting or a docker container separate out of your native listing, any domestically saved knowledge can’t be accessed when executing pipelines and jobs in SageMaker or Azure ML. This requires centralized, managed knowledge storage companies. In Azure, that is dealt with by a storage account inside the Workspace that helps datastores and knowledge property.
Datastores comprise connection info, whereas knowledge property are versioned snapshots of knowledge used for coaching or inference. AWS, then again, depends closely on S3 buckets as centralized storage places that allow safe, sturdy, cross-region entry throughout totally different accounts, and customers can entry knowledge by its distinctive URI path.
Azure ML

Azure ML treats knowledge as connected assets and property within the Workspaces, with one storage account and 4 built-in datastores mechanically created upon the instantiation of every Workspace so as to retailer information (in Azure File Share) and datasets (in Azure Blob Storage).

Since datastores securely preserve knowledge connection info and mechanically deal with the credential/identification behind the scene, it decouples knowledge location and entry permission from the code, in order that the code to stay unchanged even when the underlying knowledge connection adjustments. Datastores could be accessed by their distinctive URI. Right here’s an instance of making an Enter object with the kind uri_file by passing the datastore path.
# create coaching knowledge utilizing Datastore
training_data=Enter(
kind="uri_file",
path="",
) Then this knowledge can be utilized because the coaching knowledge for an AutoML classification job.
classification_job = automl.classification(
compute='aml-cluster',
training_data=training_data,
target_column_name='Survived',
primary_metric='accuracy',
)Information Asset is one other choice to entry knowledge in an ML job, particularly when it’s helpful to maintain monitor of a number of knowledge variations, so knowledge scientists can determine the proper knowledge snapshots getting used for mannequin constructing or experimentations. Right here is an instance code for creating an Enter object with AssetTypes.URI_FILE kind by passing the information asset path “azureml:my_train_data:1” (which incorporates the information asset identify + model quantity) and utilizing the mode InputOutputModes.RO_MOUNT for learn solely entry. You’ll find extra info within the documentation “Entry knowledge in a job”.
# creating coaching knowledge utilizing Information Asset
training_data = Enter(
kind=AssetTypes.URI_FILE,
path="azureml:my_train_data:1",
mode=InputOutputModes.RO_MOUNT
)AWS SageMaker

AWS SageMaker is tightly built-in with Amazon S3 (Easy Storage Service) for ML workflows, in order that SageMaker coaching jobs, inference endpoints, and pipelines can course of enter knowledge from S3 buckets and write output knowledge again to them. It’s possible you’ll discover that making a SageMaker managed job setting (which will likely be mentioned in Half 2) requires S3 bucket location as a key parameter, alternatively a default bucket will likely be created if unspecified.
In contrast to Azure ML’s Workspace-centric datastore method, AWS S3 is a standalone knowledge storage service that gives scalable, sturdy, and safe cloud storage that may be shared throughout different AWS companies and accounts. This provides extra flexibility for permission administration on the particular person folder degree, however on the similar time requires explicitly granting the SageMaker execution position entry to the S3 bucket.
On this code snippet, we use estimator.match(train_data_uri)to suit the mannequin on the coaching knowledge by passing its S3 URI instantly, then generates the output mannequin and shops it on the specified S3 bucket location. Extra situations could be discovered of their documentation: “Amazon S3 examples utilizing SDK for Python (Boto3)”.
import sagemaker
# Outline S3 paths
train_data_uri = ""
output_folder_uri = " What does it imply in observe?
- Azure ML: use Datastore to handle knowledge connections, which handles the credential/identification info behind the scene. Due to this fact, this method decouples knowledge location and entry permission from the code, permitting the code stay unchanged when the underlying connection adjustments.
- AWS SageMaker: use S3 buckets as the first knowledge storage service for managing enter and output knowledge of SageMaker jobs by their URI paths. This method requires express permission administration to grant the SageMaker execution position entry to the required S3 bucket.
Reference
Take-Residence Message
Evaluate Azure ML and AWS SageMaker for scalable mannequin coaching, specializing in challenge setup, permission administration, and knowledge storage patterns, so groups can higher align platform decisions with their current cloud ecosystem and most well-liked MLOps workflows.
Partially 1, we examine the high-level challenge setup and permission administration, storing and accessing the information required for mannequin coaching. Half 2 will talk about varied compute choices underneath each cloud platforms, and the creation and administration of runtime environments for coaching jobs.



{kind=link}