Organizations throughout numerous sectors face important challenges when changing assembly recordings or recorded shows into structured documentation. The method of making handouts from shows requires numerous handbook effort, similar to reviewing recordings to establish slide transitions, transcribing spoken content material, capturing and organizing screenshots, synchronizing visible parts with speaker notes, and formatting content material. These challenges impression productiveness and scalability, particularly when coping with a number of presentation recordings, convention classes, coaching supplies, and academic content material.
On this put up, we present how one can construct an automatic, serverless answer to remodel webinar recordings into complete handouts utilizing Amazon Bedrock Information Automation for video evaluation. We stroll you thru the implementation of Amazon Bedrock Information Automation to transcribe and detect slide adjustments, in addition to the usage of Amazon Bedrock basis fashions (FMs) for transcription refinement, mixed with customized AWS Lambda capabilities orchestrated by AWS Step Capabilities. By means of detailed implementation particulars, architectural patterns, and code, you’ll discover ways to construct a workflow that automates the handout creation course of.
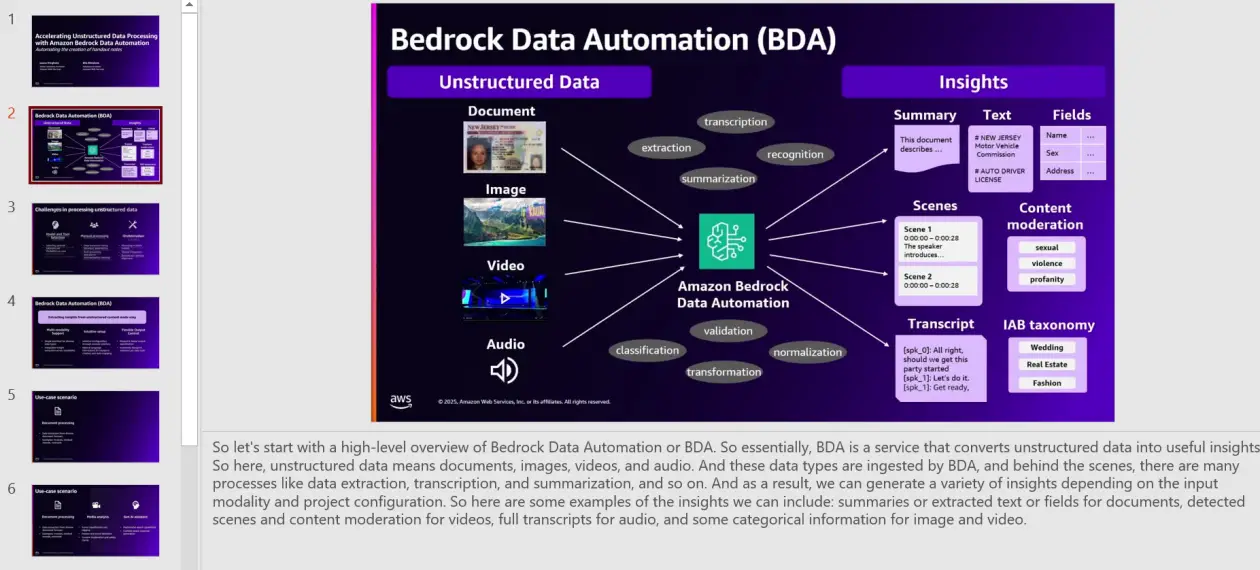
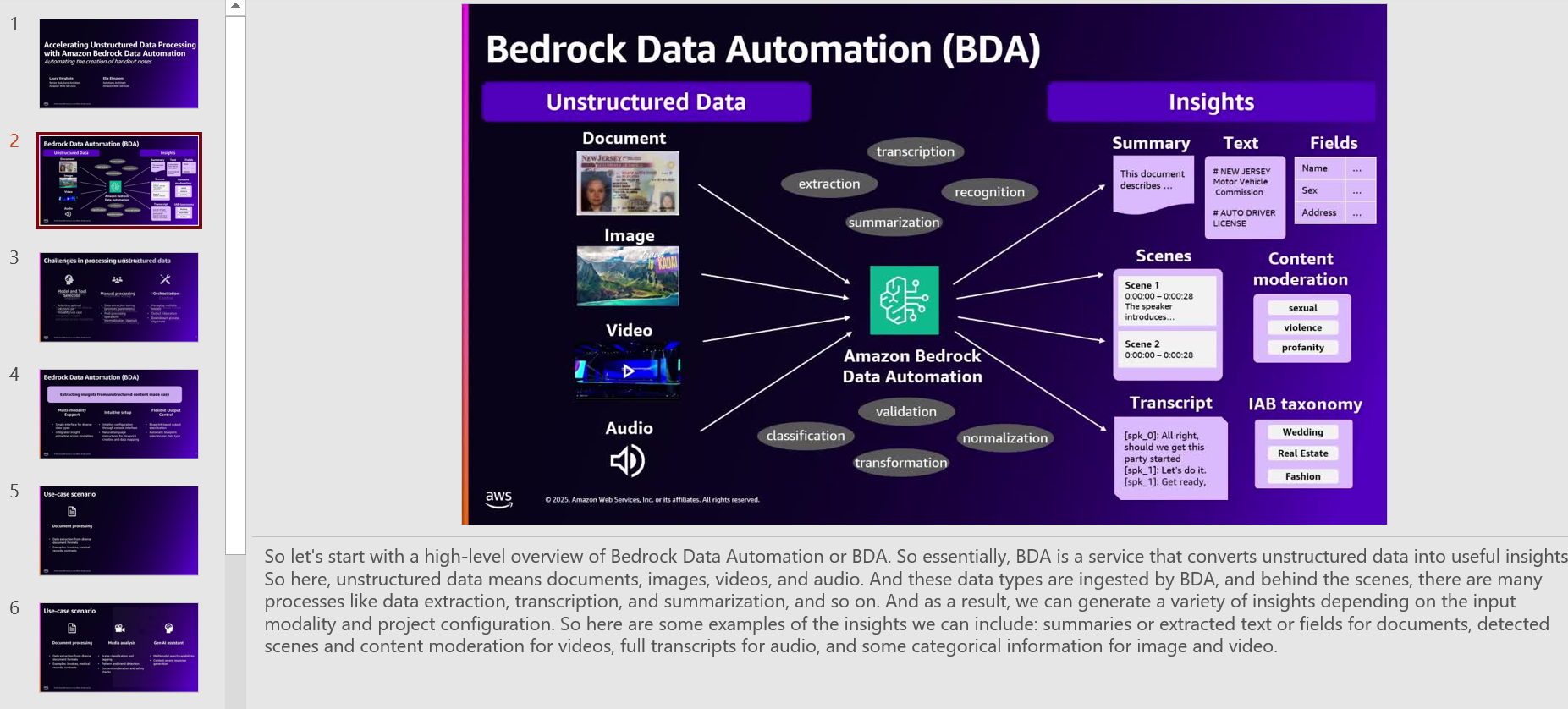
Amazon Bedrock Information Automation
Amazon Bedrock Information Automation makes use of generative AI to automate the transformation of multimodal knowledge (similar to photos, movies and extra) right into a customizable structured format. Examples of structured codecs embody summaries of scenes in a video, unsafe or express content material in textual content and pictures, or organized content material based mostly on ads or manufacturers. The answer offered on this put up makes use of Amazon Bedrock Information Automation to extract audio segments and completely different photographs in movies.
Answer overview
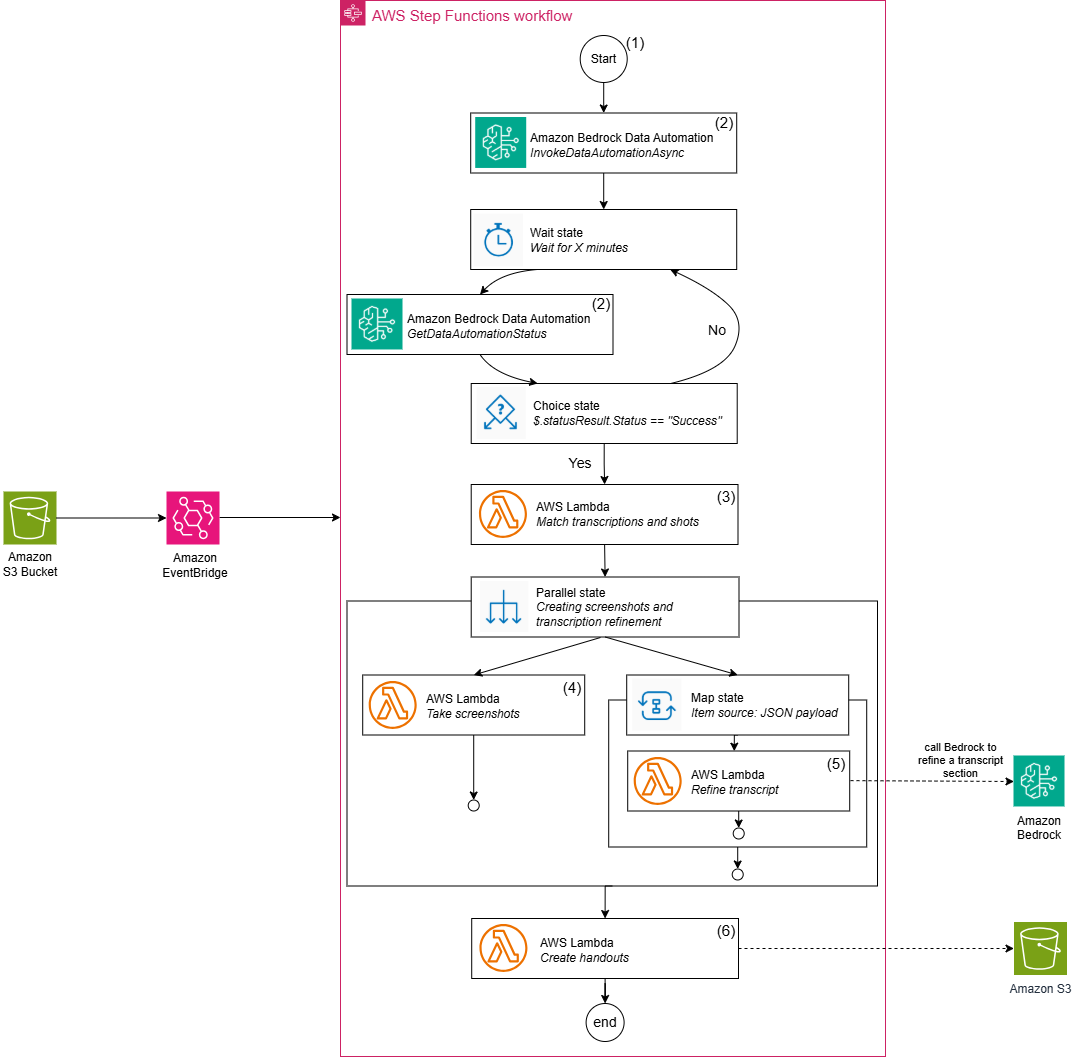
Our answer makes use of a serverless structure orchestrated by Step Capabilities to course of presentation recordings into complete handouts. The workflow consists of the next steps:
- The workflow begins when a video is uploaded to Amazon Easy Storage Service (Amazon S3), which triggers an occasion notification by means of Amazon EventBridge guidelines that initiates our video processing workflow in Step Capabilities.
- After the workflow is triggered, Amazon Bedrock Information Automation initiates a video transformation job to establish completely different photographs within the video. In our case, that is represented by a change of slides. The workflow strikes right into a ready state, and checks for the transformation job progress. If the job is in progress, the workflow returns to the ready state. When the job is full, the workflow continues, and we now have extracted each visible photographs and spoken content material.
- These visible photographs and spoken content material feed right into a synchronization step. On this Lambda operate, we use the output of the Amazon Bedrock Information Automation job to match the spoken content material to the correlating photographs based mostly on the matching of timestamps.
- After operate has matched the spoken content material to the visible photographs, the workflow strikes right into a parallel state. One of many steps of this state is the technology of screenshots. We use a FFmpeg-enabled Lambda operate to create photos for every recognized video shot.
- The opposite step of the parallel state is the refinement of our transformations. Amazon Bedrock processes and improves every uncooked transcription part by means of a Map state. This helps us take away speech disfluencies and enhance the sentence construction.
- Lastly, after the screenshots and refined transcript are created, the workflow makes use of a Lambda operate to create handouts. We use the Python-PPTX library, which generates the ultimate presentation with synchronized content material. These last handouts are saved in Amazon S3 for distribution.
The next diagram illustrates this workflow.
If you wish to check out this answer, we’ve created an AWS Cloud Improvement Package (AWS CDK) stack accessible within the accompanying GitHub repo you could deploy in your account. It deploys the Step Capabilities state machine to orchestrate the creation of handout notes from the presentation video recording. It additionally gives you with a pattern video to check out the outcomes.
To deploy and check the answer in your individual account, observe the directions within the GitHub repository’s README file. The next sections describe in additional element the technical implementation particulars of this answer.
Video add and preliminary processing
The workflow begins with Amazon S3, which serves because the entry level for our video processing pipeline. When a video is uploaded to a devoted S3 bucket, it triggers an occasion notification that, by means of EventBridge guidelines, initiates our Step Capabilities workflow.
Shot detection and transcription utilizing Amazon Bedrock Information Automation
This step makes use of Amazon Bedrock Information Automation to detect slide transitions and create video transcriptions. To combine this as a part of the workflow, you should create an Amazon Bedrock Information Automation mission. A mission is a grouping of output configurations. Every mission can comprise commonplace output configurations in addition to customized output blueprints for paperwork, photos, video, and audio. The mission has already been created as a part of the AWS CDK stack. After you arrange your mission, you possibly can course of content material utilizing the InvokeDataAutomationAsync API. In our answer, we use the Step Capabilities service integration to execute this API name and begin the asynchronous processing job. A job ID is returned for monitoring the method.
The workflow should now examine the standing of the processing job earlier than persevering with with the handout creation course of. That is carried out by polling Amazon Bedrock Information Automation for the job standing utilizing the GetDataAutomationStatus API frequently. Utilizing a mix of the Step Capabilities Wait and Selection states, we will ask the workflow to ballot the API on a set interval. This not solely provides you the power to customise the interval relying in your wants, but it surely additionally helps you management the workflow prices, as a result of each state transition is billed in Commonplace workflows, which this answer makes use of.
When the GetDataAutomationStatus API output reveals as SUCCESS, the loop exits and the workflow continues to the following step, which is able to match transcripts to the visible photographs.
Matching audio segments with corresponding photographs
To create complete handouts, you should set up a mapping between the visible photographs and their corresponding audio segments. This mapping is essential to verify the ultimate handouts precisely characterize each the visible content material and the spoken narrative of the presentation.
A shot represents a collection of interrelated consecutive frames captured throughout the presentation, sometimes indicating a definite visible state. In our presentation context, a shot corresponds to both a brand new slide or a major slide animation that provides or modifies content material.
An audio section is a particular portion of an audio recording that comprises uninterrupted spoken language, with minimal pauses or breaks. This section captures a pure movement of speech. The Amazon Bedrock Information Automation output gives an audio_segments array, with every section containing exact timing info similar to the beginning and finish time of every section. This enables for correct synchronization with the visible photographs.
The synchronization between photographs and audio segments is important for creating correct handouts that protect the presentation’s narrative movement. To attain this, we implement a Lambda operate that manages the matching course of in three steps:
- The operate retrieves the processing outcomes from Amazon S3, which comprises each the visible photographs and audio segments.
- It creates structured JSON arrays from these parts, getting ready them for the matching algorithm.
- It executes an identical algorithm that analyzes the completely different timestamps of the audio segments and the photographs, and matches them based mostly on these timestamps. This algorithm additionally considers timestamp overlaps between photographs and audio segments.
For every shot, the operate examines audio segments and identifies these whose timestamps overlap with the shot’s period, ensuring the related spoken content material is related to its corresponding slide within the last handouts. The operate returns the matched outcomes on to the Step Capabilities workflow, the place it is going to function enter for the following step, the place Amazon Bedrock will refine the transcribed content material and the place we’ll create screenshots in parallel.
Screenshot technology
After you get the timestamps of every shot and related audio section, you possibly can seize the slides of the presentation to create complete handouts. Every detected shot from Amazon Bedrock Information Automation represents a definite visible state within the presentation—sometimes a brand new slide or important content material change. By producing screenshots at these exact moments, we be certain our handouts precisely characterize the visible movement of the unique presentation.
That is carried out with a Lambda operate utilizing the ffmpeg-python library. This library acts as a Python binding for the FFmpeg media framework, so you possibly can run FFmpeg terminal instructions utilizing Python strategies. In our case, we will extract frames from the video at particular timestamps recognized by Amazon Bedrock Information Automation. The screenshots are saved in an S3 bucket for use in creating the handouts, as described within the following code. To make use of ffmpeg-python in Lambda, we created a Lambda ZIP deployment containing the required dependencies to run the code. Directions on tips on how to create the ZIP file may be present in our GitHub repository.
The next code reveals how a screenshot is taken utilizing ffmpeg-python. You’ll be able to view the complete Lambda code on GitHub.
Transcript refinement with Amazon Bedrock
In parallel with the screenshot technology, we refine the transcript utilizing a big language mannequin (LLM). We do that to enhance the standard of the transcript and filter out errors and speech disfluencies. This course of makes use of an Amazon Bedrock mannequin to boost the standard of the matched transcription segments whereas sustaining content material accuracy. We use a Lambda operate that integrates with Amazon Bedrock by means of the Python Boto3 consumer, utilizing a immediate to information the mannequin’s refinement course of. The operate can then course of every transcript section, instructing the mannequin to do the next:
- Repair typos and grammatical errors
- Take away speech disfluencies (similar to “uh” and “um”)
- Preserve the unique that means and technical accuracy
- Protect the context of the presentation
In our answer, we used the next immediate with three instance inputs and outputs:
The next is an instance enter and output:
To optimize processing velocity whereas adhering to the utmost token limits of the Amazon Bedrock InvokeModel API, we use the Step Capabilities Map state. This allows parallel processing of a number of transcriptions, every similar to a separate video section. As a result of these transcriptions should be dealt with individually, the Map state effectively distributes the workload. Moreover, it reduces operational overhead by managing integration—taking an array as enter, passing every aspect to the Lambda operate, and routinely reconstructing the array upon completion.The Map state returns the refined transcript on to the Step Capabilities workflow, sustaining the construction of the matched segments whereas offering cleaner, extra skilled textual content content material for the ultimate handout technology.
Handout technology
The ultimate step in our workflow entails creating the handouts utilizing the python-pptx library. This step combines the refined transcripts with the generated screenshots to create a complete presentation doc.
The Lambda operate processes the matched segments sequentially, creating a brand new slide for every screenshot whereas including the corresponding refined transcript as speaker notes. The implementation makes use of a customized Lambda layer containing the python-pptx bundle. To allow this performance in Lambda, we created a customized layer utilizing Docker. By utilizing Docker to create our layer, we be certain the dependencies are compiled in an atmosphere that matches the Lambda runtime. You could find the directions to create this layer and the layer itself in our GitHub repository.
The Lambda operate implementation makes use of python-pptx to create structured shows:





{kind=link}