
machine studying successfully implies that merely coaching a mannequin is not sufficient; strong, automated, and reproducible coaching pipelines are quick turning into commonplace necessities in MLOps. Many groups battle to combine machine studying experimentation with production-grade CI/CD practices, usually turning into entangled in guide processes or advanced container configurations. What when you might streamline the containerization of your coaching workflows and orchestrate them with out ever needing to put in writing a Dockerfile?
On this tutorial, I’ll present how one can automate coaching a GPT-2 mannequin utilizing open-source Tekton pipelines and Buildpacks. We’ll containerize a coaching workflow with out writing a Dockerfile, and use Tekton to orchestrate the construct and coaching steps.
I’ll reveal this with a light-weight GPT-2 tuning instance, exhibiting the mannequin’s output earlier than versus after coaching, and supply step-by-step directions to recreate the pipeline.
Overview of the toolkit: Tekton, Buildpacks, and GPT-2
Tekton Pipelines: Cloud-Native CI/CD for ML
Tekton Pipelines is an open-source CI/CD framework that runs natively on Kubernetes. It lets you outline pipelines as Kubernetes assets, enabling cloud-native construct, take a look at, and deploy workflows. In a Tekton pipeline, every step runs in a container, making it a super match for ML workflows that require isolation and reproducibility.
Buildpacks: skipping Dockerfiles
Keep in mind the final time you wrestled with a posh Dockerfile, attempting to get all dependencies and configurations excellent? Paketo Buildpacks (an implementation of Cloud Native Buildpacks) provide a refreshing different. They automate the creation of container pictures straight out of your supply code. Buildpacks analyze your undertaking, detect the language and dependencies, after which construct an optimized, safe container picture for you. This not solely saves time but additionally incorporates finest practices into your image-building course of, usually leading to safer and environment friendly pictures than these created manually with Dockerfiles.
GPT-2: light-weight mannequin
We’ll be utilizing GPT-2 as our instance mannequin. It’s a well known transformer mannequin, and crucially, it’s light-weight sufficient for us to tune rapidly on a small, customized dataset. This makes it good for demonstrating the mechanics of our coaching pipeline with out requiring huge compute assets or hours of ready. We’ll tune it on a tiny set of question-answer pairs, permitting us to see a transparent distinction in its outputs after our pipeline works its magic.
The aim right here isn’t to attain groundbreaking NLP outcomes with GPT-2. As a substitute, we’re focusing squarely on showcasing an environment friendly and automatic CI/CD pipeline for mannequin coaching. The mannequin is our payload.
Peeking Contained in the Venture: Code, Knowledge, and Pipeline Construction
I’ve arrange an instance repository on GitHub that incorporates every little thing you’ll have to observe alongside. Let’s take a fast tour of the important thing elements:
training_process/prepare.py– the mannequin coaching script. It makes use of HuggingFace Transformers with PyTorch to fine-tune GPT-2 on a customized Q&A dataset. It reads a small textual content file of question-answer pairs (see under), fine-tunes GPT-2 on this information, and saves the educated mannequin to an output listing.
training_process/necessities.txt– Python dependencies wanted for coaching. Buildpacks will auto-install these into the picture.training_process/prepare.txt– A small dataset of Q&A pairs. Be happy to customise it 🙂untrained_model.py– A helper script to check GPT-2 earlier than fine-tuning.
Tekton Pipeline Recordsdata:
model-training-pipeline.yaml– defines the Tekton pipeline with two duties (defined within the subsequent part).source-pv-pvc.yaml– defines a PersistentVolume and PersistentVolumeClaim for sharing the supply code and information with the Tekton duties (used as a workspace).kind-config.yaml– a Variety cluster configuration to mount the nativetraining_process/listing into the Kubernetes cluster.sa.yml– a ServiceAccount and secret configuration for pushing the constructed picture to a container registry (Docker Hub on this case).
With these items, we have now our code, information, and pipeline definitions prepared. Now, let’s study the construction of the Tekton pipeline.
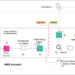
Anatomy of Our Tekton Pipeline: Constructing and Coaching
At its core, a Tekton Pipeline useful resource is what orchestrates your CI/CD workflow by defining a sequence of Duties. You possibly can consider these Duties as reusable constructing blocks, every composed of a number of Steps the place your precise instructions and scripts execute — all neatly packaged inside containers.
For our particular MLOps aim of automating the GPT-2 mannequin coaching, the Pipeline (outlined in model-training-pipeline.yaml) is designed with a transparent, sequential construction. It would execute two main Duties, one after the opposite: first, to construct and containerize our coaching code, and second, to run the coaching course of utilizing that recent container picture.

Let’s go over every intimately.
Construct The Picture: Containerize the Coaching Code
This activity makes use of Paketo Buildpacks to create a Docker picture that incorporates our coaching code and all its dependencies. Importantly, no Dockerfile is required: the Buildpacks builder will robotically detect the Python app and set up PyTorch, Transformers, and different dependencies as specified within the necessities.txt file. Within the pipeline, this activity is known as build-image. It runs the Paketo Buildpacks builder (paketobuildpacks/builder:full) with the supply code workspace mounted. Below the hood, it invokes the Cloud Native Buildpacks lifecycle creator:
/cnb/lifecycle/creator -skip-restore -app "$(workspaces.supply.path)" "$(params.APP_IMAGE)"
This command tells Buildpacks to create a container picture from the app supply within the workspace and tag it as $(params.APP_IMAGE). By default, APP_IMAGE is ready to a Docker Hub repository (e.g., sylvainkalache/automate-pytorch-model-training-with-tekton-and-buildpacks:newest).
Be aware that you simply’ll have to substitute together with your registry. I exploit Docker Hub on this instance. After this step, our coaching code is packaged right into a container picture and pushed to the registry.
Practice the Mannequin
The second activity, run-training, will depend on the primary. This activity pulls and runs the picture produced by the construct step to execute the mannequin coaching. Primarily, it begins a container from the picture (which has Python, GPT-2 code, and so on. put in) and runs the prepare.py script inside that container.
The Shared Workspace: Connecting the Dots
Let’s go over why we’d like a shared workspace in our Tekton pipeline. On this automated workflow composed of a number of phases, the construct stage and coaching stage require a shared place to change recordsdata or information. Our build-image activity wants entry to our native supply code to containerize it. Later, the run-training activity wants entry to the coaching information. Lastly, when the coaching activity efficiently generates a fine-tuned mannequin, we’d like a solution to save and retrieve that useful output.
Each duties share a Tekton Workspace named “supply”. This workspace is backed by a PersistentVolumeClaim (source-pvc), which is ready as much as mount our native code. That is how the pipeline accesses the coaching script and information: the identical recordsdata you could have in training_process/ in your machine are mounted into the Tekton activity pods at /workspace/supply.

The Buildpacks builder reads the code from there to construct the picture, and the coaching container later reads the information and writes outputs there as effectively. Utilizing a shared workspace ensures that the mannequin saved throughout coaching persists after the duty completes (so we are able to retrieve it) and that each duties function on the identical code base. Be aware that this setup is appropriate for this tutorial, however it’s unlikely to be one thing you’d need for manufacturing.
Now, merging the 2 sections, that is what the complete coaching pipeline seems to be like.

Now that we perceive the pipeline, let’s stroll by way of setting it up and working it.
Step-by-Step: Operating the Tekton Pipeline for GPT-2 Coaching
Able to see it in motion? Comply with these steps to arrange your setting, deploy the Tekton assets, and set off the coaching pipeline. This assumes you could have a Kubernetes cluster (for native testing, you need to use Variety with the supplied config) and kubectl entry to it. For those who don’t have such a setup, right here is a tough record of instructions you’ll have to get the required instruments. This tutorial was examined on Ubuntu 22.04.
Clone the Instance Repository
Get the code and pipeline manifests in your machine:
git clone https://github.com/sylvainkalache/Automate-PyTorch-Mannequin-Coaching-with-Tekton-and-Buildpacks.git
cd Automate-PyTorch-Mannequin-Coaching-with-Tekton-and-BuildpacksSet up Tekton Pipelines
If Tekton just isn’t already put in in your cluster, set up it by making use of the official launch YAML:kubectl apply -f https://storage.googleapis.com/tekton-releases/pipeline/newest/launch.yaml
This command will create the Tekton CRDs (Pipeline, Job, PipelineRun, and so on.) in your cluster. You solely want to do that as soon as.
Apply the Pipeline and Quantity Manifests
Deploy the Tekton pipeline definition and supporting Kubernetes assets:
kubectl apply -f model-training-pipeline.yaml
kubectl apply -f source-pv-pvc.yaml
kubectl apply -f sa.yamlLet’s go over the small print of every command:
- The primary command creates the Tekton Pipeline object
model-training-pipelinewithin the cluster. - The second creates a PersistentVolume and Declare. The supplied
source-pv-pvc.yamlassumes you’re utilizing Variety and mounts the nativetraining_process/listing into the cluster. It defines a hostPath quantity at/mnt/training_processon the node, and ties it to a PVC namedsource-pvc. - The third applies a ServiceAccount for Tekton to make use of when working the pipeline. This
sa.ymlought to reference the Docker registry secret created within the subsequent step, permitting Tekton’s construct step to push the picture.
Create Docker Registry Secret
Tekton’s Buildpacks activity will push the constructed picture to a container registry. For this, it’s good to present your registry credentials (e.g., Docker Hub login). Create a Kubernetes secret together with your registry auth particulars:
kubectl create secret docker-registry docker-hub-secret
--docker-username=
--docker-password=
--docker-server=
--namespace default This secret will retailer your auth data. Make sure the ServiceAccount from step 3 is configured to make use of this secret for picture pull and push.
Run the Tekton Pipeline
With every little thing in place, you can begin the pipeline, run:
tkn pipeline begin model-training-pipeline
--workspace title=supply,claimName=source-pvc
-s tekton-pipeline-saRight here we cross the PVC because the supply workspace. Additionally specify the service account (-s) that has the registry secret. It will begin the pipeline. Use tkn pipelinerun logs -f to look at the progress. It’s best to see output from the Buildpacks creator (detecting a Python app, putting in necessities) after which from the coaching script (printing coaching epochs and completion).
After the pipeline finishes efficiently, the fine-tuned mannequin shall be saved within the training_process/output-model listing (because of the PVC workspace, it persists in your native filesystem by way of the Variety mount). We will now examine the GPT-2 mannequin’s output earlier than and after fine-tuning.
The Proof is within the Pudding: GPT-2 Output Earlier than vs. After Coaching
Did our automated pipeline enhance the mannequin? Let’s discover out.
Earlier than The Coaching
What does the off-the-shelf GPT-2 mannequin say? Run untrained_model.py with a query. For instance:

We will see that GPT-2 gave a rambling response that didn’t appropriately reply the query.
After the Coaching Course of
Now let’s see GPT-2 tuned on our Q&A knowledge. We will load the mannequin saved by our pipeline and generate a solution. The script training_process/serve.py does this. For instance:

As a result of we educated on a QA format, the fine-tuned GPT-2 will produce a solution after the | separator. Certainly, after coaching, the mannequin’s reply to “How far is the solar?” was: “150 million kilometers away.” — exactly the reply from our coaching information.
This easy comparability demonstrates that our CI/CD pipeline efficiently took our supply code, constructed it, educated the mannequin, and produced an improved model. Whereas this was a minimal dataset for illustrative functions, think about plugging in your bigger, domain-specific datasets. The pipeline construction stays unchanged, offering a sturdy and automatic path for mannequin updates.
Tekton + Buildpacks: A Successful Combo for Less complicated ML CI/CD
Utilizing Tekton pipelines with Buildpacks provides a chic answer for machine studying CI/CD workflows. Each Tekton and Buildpacks are cloud-native, open-source options that combine effectively with the remainder of your Kubernetes ecosystem.
By automating mannequin coaching on this manner, ML engineers and DevOps groups can collaborate extra successfully. The ML code is handled equally to utility code in CI/CD – each change can set off a pipeline that reliably builds and trains the mannequin. Tekton supplies the pipeline glue with Kubernetes scalability, and Paketo Buildpacks take the trouble out of containerizing ML workloads. The tip result’s sooner experimentation and deployment for ML fashions, achieved with a declarative, easy-to-maintain pipeline. I hope you prefer it!
Thanks For Studying
I’m Sylvain Kalache, main Rootly AI Labs: a fellow-driven group constructing AI-centric prototypes, open-source instruments, and analysis to redefine reliability engineering. Sponsored by Anthropic, Google Cloud, and Google DeepMind, all our work is freely out there on GitHub. For extra of my tales, observe me on LinkedIn or discover my writing in my portfolio.

Sylvain Kalache, the creator, created all the pictures and diagrams on this article.


{kind=link}