Enterprises in industries like manufacturing, finance, and healthcare are inundated with a relentless movement of paperwork—from monetary studies and contracts to affected person data and provide chain paperwork. Traditionally, processing and extracting insights from these unstructured information sources has been a guide, time-consuming, and error-prone job. Nevertheless, the rise of clever doc processing (IDP), which makes use of the facility of synthetic intelligence and machine studying (AI/ML) to automate the extraction, classification, and evaluation of knowledge from numerous doc varieties is remodeling the sport. For producers, this implies streamlining processes like buy order administration, bill processing, and provide chain documentation. Monetary companies corporations can speed up workflows round mortgage functions, account openings, and regulatory reporting. And in healthcare, IDP revolutionizes affected person onboarding, claims processing, and medical file maintaining.
By integrating IDP into their operations, organizations throughout these key industries expertise transformative advantages: elevated effectivity and productiveness by the discount of guide information entry, improved accuracy and compliance by decreasing human errors, enhanced buyer experiences on account of sooner doc processing, better scalability to deal with rising volumes of paperwork, and decrease operational prices related to doc administration.
This put up demonstrates the way to construct an IDP pipeline for routinely extracting and processing information from paperwork utilizing Amazon Bedrock Immediate Flows, a completely managed service that allows you to construct generative AI workflow utilizing Amazon Bedrock and different companies in an intuitive visible builder. Amazon Bedrock Immediate Flows lets you rapidly replace your pipelines as your online business modifications, scaling your doc processing workflows to assist meet evolving calls for.
Resolution overview
To be scalable and cost-effective, this resolution makes use of serverless applied sciences and managed companies. Along with Amazon Bedrock Immediate Flows, the answer makes use of the next companies:
- Amazon Textract – Routinely extracts printed textual content, handwriting, and information from
- Amazon Easy Storage Service (Amazon S3) – Object storage constructed to retrieve information from anyplace.
- Amazon Easy Notification Service (Amazon SNS) – A extremely accessible, sturdy, safe, and totally managed publish-subscribe (pub/sub) messaging service to decouple microservices, distributed programs, and serverless functions.
- AWS Lambda – A compute service that runs code in response to triggers corresponding to modifications in information, modifications in software state, or consumer actions. As a result of companies corresponding to Amazon S3 and Amazon SNS can straight set off an AWS Lambda operate, you possibly can construct a wide range of real-time serverless data-processing programs.
- Amazon DynamoDB – a serverless, NoSQL, fully-managed database with single-digit millisecond efficiency at
Resolution structure
The answer proposed incorporates the next steps:
- Customers add a PDF for evaluation to Amazon S3.
- The Amazon S3 add triggers an AWS Lambda operate execution.
- The operate invokes Amazon Textract to extract textual content from the PDF in batch mode.
- Amazon Textract sends an SNS notification when the job is full.
- An AWS Lambda operate reads the Amazon Textract response and calls an Amazon Bedrock immediate movement to categorise the doc.
- Outcomes of the classification are saved in Amazon S3 and despatched to a vacation spot AWS Lambda operate.
- The vacation spot AWS Lambda operate calls an Amazon Bedrock immediate movement to extract and analyze information based mostly on the doc class offered.
- Outcomes of the extraction and evaluation are saved in Amazon S3.
This workflow is proven within the following diagram.

Within the following sections, we dive deep into the way to construct your IDP pipeline with Amazon Bedrock Immediate Flows.
Conditions
To finish the actions described on this put up, be sure that you full the next stipulations in your native surroundings:
Implementation time and price estimation
| Time to finish | ~ 60 minutes |
| Price to run 1000 pages | Beneath $25 |
| Time to cleanup | ~20 minutes |
| Studying stage | Superior (300) |
Deploy the answer
To deploy the answer, observe these steps:
- Clone the GitHub repository
- Use the shell script to construct and deploy the answer by operating the next instructions out of your mission root listing:
- This can set off the AWS CloudFormation template in your AWS account.
Check the answer
As soon as the template is deployed efficiently, observe these steps to check the answer:
- On the AWS CloudFormation console, choose the stack that was deployed
- Choose the Sources tab
- Find the assets labeled SourceS3Bucket and DestinationS3Bucket, as proven within the following screenshot. Choose the hyperlink to open the SourceS3Bucket in a brand new tab

- Choose Add after which Add folder
- Beneath sample_files, choose the folder customer123, then select Add
Alternatively, you possibly can add the folder utilizing the next AWS CLI command from the foundation of the mission:
After a couple of minutes the uploaded information might be processed. To view the outcomes, observe these steps:
- Open the DestinationS3Bucket
- Beneath customer123, it’s best to see a folder for paperwork for the processing jobs. Obtain and overview the information regionally utilizing the console or with the next AWS CLI command
Contained in the folder for customer123 you will notice a number of subfolders, as proven within the following diagram:
The way it works
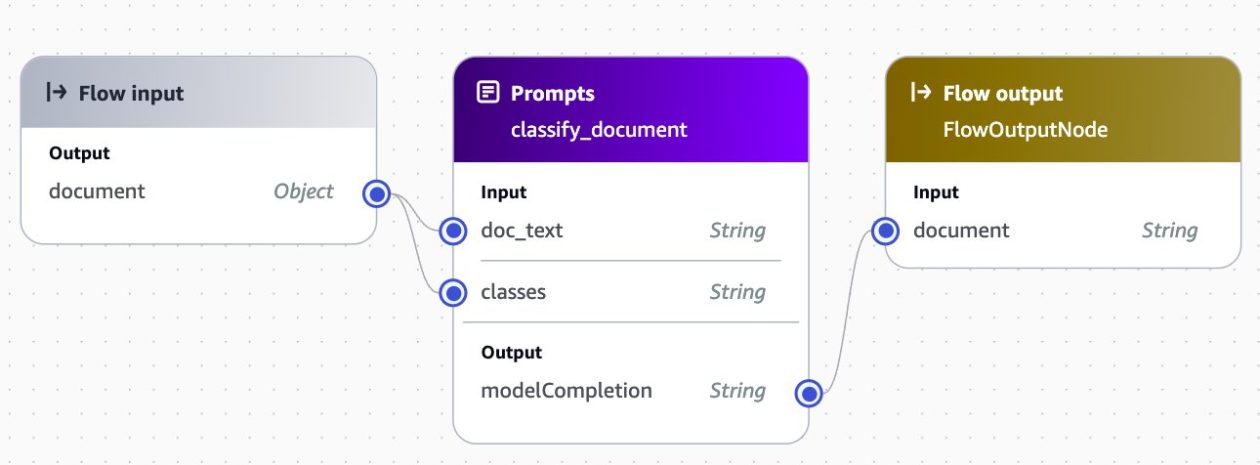
After the doc textual content is extracted, it’s despatched to a classify immediate movement together with an inventory of lessons, as proven within the following screenshot:

The checklist of lessons is generated within the AWS Lambda operate by utilizing the API to establish present immediate flows that comprise class definitions of their description. This strategy permits us to broaden the answer to new doc varieties by including a brand new immediate movement supporting the brand new doc class, as proven within the following screenshot:

For every doc sort, you possibly can implement an extract and analyze movement that’s acceptable to this doc sort. The next screenshot exhibits an instance movement from the URLA_1003 movement. On this case, a immediate is used to transform the textual content to a standardized JSON format, and a second immediate then analyzes that JSON doc to generate a report back to the processing agent.

Increase the answer utilizing Amazon Bedrock Immediate Flows
To adapt to new use instances with out altering the underlying code, use Amazon Bedrock Immediate Flows as described within the following steps.
Create a brand new immediate
From the information you downloaded, search for a folder named FOR_REVIEW. This folder incorporates paperwork that have been processed and didn’t match into an present class. Open report.txt and overview the urged doc class and proposed JSON template.
- Within the navigation pane in Amazon Bedrock, open Immediate administration and choose Create immediate, as proven within the following screenshot:

- Identify the brand new immediate
IDP_PAYSTUB_JSONafter which select Create - Within the Immediate field, enter the next textual content. Substitute
COPY YOUR JSON HEREwith the JSON template out of your txt file
The next screenshot demonstrates this step.

- Select Choose mannequin and select Anthropic Claude 3 Sonnet
- Save your modifications by selecting Save draft
- To check your immediate, open the pages_[n].txt file FOR_REVIEW folder and duplicate the content material into the doc_text enter field. Select Run and the mannequin ought to return a response
The next screenshot demonstrates this step.

- When you’re glad with the outcomes, select Create Model. Notice the model quantity as a result of you will want it within the subsequent part
Create a immediate movement
Now we are going to create a immediate movement utilizing the immediate you created within the earlier part.
- Within the navigation menu, select Immediate flows after which select Create immediate movement, as proven within the following screenshot:

- Identify the brand new movement
IDP_PAYSTUB - Select Create and use a brand new service position after which select Save
Subsequent, create the movement utilizing the next steps. When you’re executed, the movement ought to resemble the next screenshot.

- Configure the Movement enter node:
- Select the Movement enter node and choose the Configure
- Choose Object because the Kind. Because of this movement invocation will anticipate to obtain a JSON object.
- Add the S3 Retrieval node:
- Within the Immediate movement builder navigation pane, choose the Nodes tab
- Drag an S3 Retrieval node into your movement within the heart pane
- Within the Immediate movement builder pane, choose the Configure tab
- Enter
get_doc_textbecause the Node title - Increase the Inputs Set the enter specific for objectKey to
$.information.doc_text_s3key - Drag a connection from the output of the Movement enter node to the objectKey enter of this node
- Add the Immediate node:
- Drag a Immediate node into your movement within the heart pane
- Within the Immediate movement builder pane, choose the Configure tab
- Enter
map_to_jsonbecause the Node title - Select Use a immediate out of your Immediate Administration
- Choose
IDP_PAYSTUB_JSONfrom the dropdown - Select the model you famous beforehand
- Drag a connection from the output of the get_doc_text node to the doc_text enter of this node
- Add the S3 Storage node:
- Within the Immediate movement builder navigation pane, choose the Nodes tab
- Drag an S3 Storage node into your movement within the heart pane
- Within the Immediate movement builder pane, choose the Configure tab in
- Enter
save_jsonbecause the Node title - Increase the Inputs Set the enter specific for objectKey to
$.information.JSON_s3key - Drag a connection from the output of the Movement enter node to the objectKey enter of this node
- Drag a connection from the output of the map_to_json node to the content material enter of this node
- Configure the Movement output node:
- Drag a connection from the output of the save_json node to the enter of this node
- Select Save to avoid wasting your movement. Your movement ought to now be ready for testing
- To check your movement, within the Check immediate movement pane on the correct, enter the next JSON object. Select Run and the movement ought to return a mannequin response
- When you’re glad with the end result, select Save and exit
To get the trail to your file, observe these steps:
- Navigate to FOR_REVIEW in S3 and select the pages_[n].txt file
- Select the Properties tab
- Copy the important thing path by choosing the copy icon to the left of the important thing worth, as proven within the following screenshot. Make sure to exchange .txt with .json within the second line of enter as famous beforehand.

Publish a model and alias
- On the movement administration display screen, select Publish model. Successful banner seems on the high
- On the high of the display screen, select Create alias
- Enter
newestfor the Alias title - Select Use an present model to affiliate this alias. From the dropdown menu, select the model that you simply simply printed
- Choose Create alias. Successful banner seems on the high.
- Get the
FlowIdandAliasIdto make use of within the step under- Select the Alias you simply created
- From the ARN, copy the FlowId and AliasId

Add your new class to DynamoDB
- Open the AWS Administration Console and navigate to the DynamoDB service.
- Choose the desk document-processing-bedrock-prompt-flows-IDP_CLASS_LIST
- Select Actions then Create merchandise
- Select JSON view for getting into the merchandise information.
- Paste the next JSON into the editor:
- Evaluate the JSON to make sure all particulars are right.
- Select Create merchandise so as to add the brand new class to your DynamoDB desk.
Check by repeating the add of the check file
Use the console to repeat the add of the paystub.jpg file out of your customer123 folder into Amazon S3. Alternatively, you possibly can enter the next command into the command line:
In a couple of minutes, verify the report within the output location to see that you simply efficiently added help for the brand new doc sort.
Clear up
Use these steps to delete the assets you created to keep away from incurring expenses in your AWS account:
- Empty the SourceS3Bucket and DestinationS3Bucket buckets together with all variations
- Use the next shell script to delete the CloudFormation stack and check assets out of your account:
- Return to the Increase the answer utilizing Amazon Bedrock Immediate Flows part and observe these steps:
- Within the Create a immediate movement part:
- Select the movement
idp_paystubthat you simply created and select Delete - Comply with the directions to completely delete the movement
- Select the movement
- Within the Create a brand new immediate part:
- Select the immediate
paystub_jsonthat you simply created and select Delete - Comply with the directions to completely delete the immediate
- Select the immediate
- Within the Create a immediate movement part:
Conclusion
This resolution demonstrates how prospects can use Amazon Bedrock Immediate Flows to deploy and broaden a scalable, low-code IDP pipeline. By making the most of the pliability of Amazon Bedrock Immediate Flows, organizations can quickly implement and adapt their doc processing workflows to assist meet evolving enterprise wants. The low-code nature of Amazon Bedrock Immediate Flows makes it attainable for enterprise customers and builders alike to create, modify, and lengthen IDP pipelines with out intensive programming information. This considerably reduces the time and assets required to deploy new doc processing capabilities or alter present ones.
By adopting this built-in IDP resolution, companies throughout industries can speed up their digital transformation initiatives, enhance operational effectivity, and improve their potential to extract beneficial insights from document-based processes, driving important aggressive benefits.
Evaluate your present guide doc processing processes and establish the place Amazon Bedrock Immediate Flows will help you automate these workflows for your online business.
For additional exploration and studying, we advocate testing the next assets:
In regards to the Authors
 Erik Cordsen is a Options Architect at AWS serving prospects in Georgia. He’s captivated with making use of cloud applied sciences and ML to resolve actual life issues. When he isn’t designing cloud options, Erik enjoys journey, cooking, and biking.
Erik Cordsen is a Options Architect at AWS serving prospects in Georgia. He’s captivated with making use of cloud applied sciences and ML to resolve actual life issues. When he isn’t designing cloud options, Erik enjoys journey, cooking, and biking.
 Vivek Mittal is a Resolution Architect at Amazon Internet Providers. He’s captivated with serverless and machine studying applied sciences. Vivek takes nice pleasure in aiding prospects with constructing revolutionary options on the AWS cloud.
Vivek Mittal is a Resolution Architect at Amazon Internet Providers. He’s captivated with serverless and machine studying applied sciences. Vivek takes nice pleasure in aiding prospects with constructing revolutionary options on the AWS cloud.
 Brijesh Pati is an Enterprise Options Architect at AWS. His main focus helps enterprise prospects undertake cloud applied sciences for his or her workloads. He has a background in software growth and enterprise structure and has labored with prospects from numerous industries corresponding to sports activities, finance, power, {and professional} companies. His pursuits embody serverless architectures and AI/ML.
Brijesh Pati is an Enterprise Options Architect at AWS. His main focus helps enterprise prospects undertake cloud applied sciences for his or her workloads. He has a background in software growth and enterprise structure and has labored with prospects from numerous industries corresponding to sports activities, finance, power, {and professional} companies. His pursuits embody serverless architectures and AI/ML.



{kind=link}