
pdfplumber, pypdf, and pdfminer to assist with the extraction of textual content and tabular knowledge from the PDF. The next is an instance of utilizing pdfplumber to parse the primary web page of the 2023 Amazon annual report in PDF format.
pdfplumber offers bounding field data, which can be utilized to take away superfluous textual content reminiscent of web page headers and footers. Nevertheless, the library solely works with PDFs which have textual content current, reminiscent of digitally authored PDFs. For PDF paperwork that require OCR, reminiscent of scanned paperwork, you should use providers reminiscent of Amazon Textract.
Workplace doc processing
Paperwork authored with Microsoft Workplace or different appropriate productiveness software program are one other frequent format inside a corporation. Such paperwork can embody DOCX, PPTX, and XLSX recordsdata, and there are libraries accessible to work with these codecs. The next code snippet makes use of the python-docx library to extract textual content from a Phrase doc. The code iterates by way of the doc paragraphs and concatenates them right into a single string.
Deduplication
After the preprocessing step, you will need to course of the information additional to take away duplicates (deduplication) and filter out low-quality content material.
Deduplication is a essential side for getting ready high-quality pretraining datasets. Based on CCNet, duplicated coaching examples are pervasive in frequent pure language processing (NLP) datasets. This problem is just not solely a frequent supply of bias in datasets originating from public domains such because the web, however it can be a possible downside when curating your personal coaching dataset. When organizations try to create their very own coaching dataset, they typically use numerous knowledge sources reminiscent of inner emails, memos, inner worker chat logs, help tickets, conversations, and inner wiki pages. The identical chunk of textual content would possibly seem throughout a number of sources or can repeat excessively in a single knowledge supply reminiscent of an electronic mail thread. Duplicated knowledge extends the coaching time and doubtlessly biases the mannequin in direction of extra steadily repeated examples.
A generally used processing pipeline is the CCNet pipeline. The next part will describe deduplication and filtering employed within the CCNet pipeline.
Break paperwork into shards. Within the CCNet paper, the creator divided 30 TB of knowledge into 1,600 shards. In that instance, the shards are paperwork which were grouped collectively. Every shard comprises 5 GB knowledge and 1.6 million paperwork. Organizations can decide the variety of shards and dimension of every shard primarily based on their knowledge dimension and compute surroundings. The principle function of making shards is to parallelize the deduplication course of throughout a cluster of compute nodes.
Compute hash code for every paragraph of the doc. Every shard comprises many paperwork and every doc comprises a number of paragraphs. For every paragraph, we compute a hash code and save them right into a binary file. The authors of the CCNet paper use the primary 64 bits of SHA-1 digits of the normalized paragraphs as the important thing. Deduplication is finished by evaluating these keys. If the identical key seems a number of occasions, the paragraphs that these keys hyperlink to are thought of duplicates. You’ll be able to examine the keys inside one shard, during which case there would possibly nonetheless be duplicated paragraphs throughout totally different shards. For those who examine the keys throughout all shards, you possibly can confirm that no duplicated paragraph exists in your entire dataset. Nevertheless, this may be computationally costly.
MinHash is one other widespread technique for estimating the similarities between two paragraphs. This system is especially helpful for giant datasets as a result of it offers an environment friendly approximation of the Jaccard similarity. Paragraphs are damaged down into shingles, that are overlapping sequences of phrases or characters of a set size. A number of hashing capabilities are utilized to every shingle. For every hash operate, we discover the minimal hash worth throughout all of the shingles and use that because the signature of the paragraph, referred to as the MinHash signature. Utilizing the MinHash signatures, we will calculate the similarity of the paragraphs. The MinHash approach can be utilized to phrases, sentences, or total paperwork. This flexibility makes MinHash a strong instrument for a variety of textual content similarity duties. The next instance reveals the pseudo-code for this method:
The entire steps of utilizing MinHash for deduplication are:
- Break down paperwork into paragraphs.
- Apply the MinHash algorithm as proven within the previous instance and calculate the similarity scores between paragraphs.
- Use the similarity between paragraphs to establish duplicate pairs.
- Mix duplicate pairs into clusters. From every cluster, choose one consultant paragraph to reduce duplicates.
To reinforce the effectivity of similarity searches, particularly when coping with massive datasets, MinHash is commonly used at the side of extra strategies reminiscent of Locality Delicate Hashing (LSH). LSH enhances MinHash by offering a technique to rapidly establish potential matches by way of bucketing and hashing strategies with out having to match each pair of things within the dataset. This mixture permits for environment friendly similarity searches even in large collections of paperwork or knowledge factors, considerably lowering the computational overhead sometimes related to such operations.
It’s necessary to notice that paragraph-level deduplication is just not the one alternative of granularity. As proven in Meta’s Llama 3 paper, you too can use sentence-level deduplication. The authors additionally utilized document-level deduplication to take away close to duplicate paperwork. The computation value for sentence-level deduplication is even increased in comparison with paragraph-level deduplication. Nevertheless, this method affords extra fine-grained management over duplicate content material. On the similar time, eradicating duplicated sentences would possibly lead to an incomplete paragraph, doubtlessly affecting the coherence and context of the remaining textual content. Thus, the trade-off between granularity and context preservation must be rigorously thought of primarily based on the character of the dataset.
Making a dataset for mannequin fine-tuning
Nice-tuning a pre-trained LLM includes adapting it to a selected activity or area by coaching it on an annotated dataset in a supervised method or by way of reinforcement studying strategies. The dataset issues for fine-tuning are essential as a result of they immediately affect the mannequin’s efficiency, accuracy, and generalization capabilities. Prime issues embody:
- Relevance and domain-specificity:The dataset ought to intently match the duty or area the mannequin is being fine-tuned for. Ensure that the dataset consists of various examples and edge circumstances that the mannequin is prone to encounter. This helps enhance the robustness and generalizability of the mannequin throughout a spread of real-world eventualities. For instance, when fine-tuning a mannequin for monetary sentiment evaluation, the dataset ought to comprise monetary information articles, analyst reviews, inventory market commentary, and company earnings bulletins.
- Annotation high quality:The dataset should be freed from noise, errors, and irrelevant data. Annotated datasets should preserve consistency in labeling. The dataset ought to precisely mirror the proper solutions, human preferences, or different goal outcomes that the fine-tuning course of goals to attain.
- Dataset dimension and distribution:Though fine-tuning typically requires fewer tokens than pretraining (1000’s in comparison with thousands and thousands), the dataset ought to nonetheless be massive sufficient to cowl the breadth of the duty necessities. The dataset ought to embody a various set of examples that mirror the variations in language, context, and elegance that the mannequin is predicted to deal with.
- Moral issues: Analyze and mitigate biases current within the dataset, reminiscent of gender, racial, or cultural biases. These biases may be amplified throughout fine-tuning, resulting in unfair or discriminatory mannequin outputs. Ensure that the dataset aligns with moral requirements and represents various teams and views pretty.
- Smart knowledge lower offs: Whereas getting ready the dataset, one of many issues to grasp is selecting a closing date for the information. Usually, relying on the velocity of modifications within the data, you possibly can select an early or late lower off. For instance, for fine-tuning an LLM for model adherence, you possibly can have a distant cutoff date as a result of the model language stays constant for a few years. Whereas getting ready the dataset for producing audit and compliance letters wants an earlier cutoff date as a result of new compliance rules are created and are up to date very often.
- Modalities: Within the case of multi-modal fashions, the dataset should embody numerous supported knowledge varieties. Every knowledge sort should comply with the opposite issues talked about right here round annotation high quality, moral issues, relevance, area specificity, and so forth.
- Artificial knowledge augmentation:Take into account producing artificial knowledge to complement real-world knowledge, particularly to assist fill gaps within the dataset to make it possible for it’s reasonable and consultant. Using these strategies may also help overcome the challenges of restricted knowledge availability, improve mannequin robustness, and supply higher generalization throughout various duties.
Dataset format for tremendous tuning
Instruction tuning is a technique of additional coaching a pretrained mannequin on a various set of duties framed as pure language directions. This method goals to boost the mannequin’s skill to grasp and comply with express directions, enhancing its efficiency on a variety of downstream duties with out the necessity for task-specific tremendous -tuning. A method referred to as reference tuning is used to align massive fashions with human preferences and values. This method goals to enhance the standard, security, and desirability of AI-generated outputs by incorporating human suggestions into the coaching course of. The info necessities for each of those strategies are very totally different, so we’ll go into additional element within the following sections.
Instruction tremendous tuning dataset format
The columns within the desk that follows characterize the important thing elements of the instruction-tuning paradigm: Sort categorizes the duty or instruction sort. Instruction comprises the particular directive for the mannequin. Enter offers the context or knowledge to work with. Output reveals the anticipated or desired response. This construction is essential for coaching fashions to grasp and execute all kinds of duties primarily based on pure language directions.
| Sort | Instruction | Enter | Output |
| antonym_relation | What’s the relationship between the given pairs? | Night time : Day :: Proper : Left | The connection between the given pairs is that they’re opposites. |
| email_subject_generation | Generate an applicable topic title for the next electronic mail: | Hello [person name],nn I’m writing to ask you in case you are prepared to be a panelist of our workshop on multi-modality at CVPR. The workshop shall be held on June 20, 2023. nnBest,n[my name] | Invitation to be a panelist for CVPR 2023 workshop on multi-modality |
| analogy_completion | To make the pairs have the identical analogy, write the fourth phrase. | Instability : Turmoil:: Change : | Instability : Turmoil :: Change : Revolution |
| question_answering_generation_from_facts | Utilizing the info given, write a question-answer pair. | Identify: Invoice GatesnBorn: October 28, 1955 (age 66)nEducation: Harvard College (dropped out)nOccupation: Software program developer, investor, entrepreneurnSource: WikipedianTime: August 2022 | Query: What’s Invoice Gates’s occupation? nAnswer: He’s a software program developer, investor, and entrepreneur. |
Desire-tuning dataset format
For a preference-tuning dataset, the dataset sometimes consists of entries, every containing an enter or immediate, a selected (most well-liked) response, and a rejected (much less most well-liked) response. The next is an instance of a Direct Desire Optimization (DPO) dataset.
| Immediate | Chosen | Rejected |
|
Artists Gustav Klimt and Carl Moll have been born during which European nation? What’s the reply? |
[{‘content’: ‘You are a helpful assistant who always provide explanation. Think like you are answering a five year old.’, ‘role’: ‘system’} {‘content’: ‘Artists Gustav Klimt and Carl Moll were born in which European country?nWhat is the answer?’, ‘role’: ‘user’} {‘content’: ‘Gustav Klimt and Carl Moll were both born in a European country called Austria. Austria is a beautiful place with mountains, forests, and many people who speak German. These two artists created lots of pretty paintings while they lived in Austria.’, ‘role’: ‘assistant’}] |
[{‘content’: ‘You are a helpful assistant, who always provides an explanation. Think like you are answering a five year old.’, ‘role’: ‘system’} {‘content’: ‘Artists Gustav Klimt and Carl Moll were born in which European country?nWhat is the answer?’, ‘role’: ‘user’} {‘content’: ” Ooh ooh! *giggle* You wanna know where Gustav Klimt and Carl Moll were born? *bounce bounce* Well, they were born in a special place called Austria! *twirl* That’s right, Austria! It’s a beautiful country in Europe, and lots of talented artists like Gustav and Carl were born there! *smile* Does that make you wanna dance? *spin spin* Hehehe!”, ‘role’: ‘assistant’}] |
The next is an instance utilizing the Ultrachat-feedback dataset format, which incorporates the next parts: immediate, chosen, rejected, message, score_chosen, and score_rejected. Any such dataset is commonly utilized in DPO or reinforcement studying from human suggestions (RLHF) to enhance AI mannequin outputs. By offering examples of your most well-liked and non-preferred responses together with their respective scores, the dataset can be utilized to coach fashions to generate extra fascinating outputs.
| immediate | chosen | rejected | messages | score_chosen | score_rejected |
| Let’s play a recreation. I say a sentence, you then make a sentence that follows up my sentence, then I give a continuation to yours and so forth. You prepared? | [{‘content’: “Let’s play a game. I say a sentence, then you make a sentence that follows up my sentence, then I give a continuation to yours and so on. you ready?”, ‘role’: ‘user’} {‘content’: “I’m ready! Let’s begin. Please provide your first sentence.”, ‘role’: ‘assistant’}] |
[{‘content’: “Let’s play a game. I say a sentence, then you make a sentence that follows up my sentence, then I give a continuation to yours and so on. you ready?”, ‘role’: ‘user’} {‘content’: ‘Sure, I would love to play.’, ‘role’: ‘assistant’}] |
[{‘content’: “Let’s play a game. I say a sentence, then you make a sentence that follows up my sentence, then I give a continuation to yours and so on. you ready?”, ‘role’: ‘user’} {‘content’: “I’m ready! Let’s begin. Please provide your first sentence.”, ‘role’: ‘assistant’}] |
7 | 6 |
Within the case of Meta Llama 3, instruction-tuned fashions undergo an iterative technique of DPO desire alignment, and the dataset sometimes consists of triplets—a consumer immediate and two mannequin responses, with one response most well-liked over the opposite. In superior implementations, this format may be prolonged to incorporate a 3rd, edited response that’s thought of superior to each authentic responses. The desire between responses is quantified utilizing a multi-level ranking system, starting from marginally higher to considerably higher. This granular method to desire annotation permits for a extra nuanced coaching of the mannequin, enabling it to differentiate between slight enhancements and vital enhancements in response high quality.
| immediate | chosen | rejected | edited | alignment ranking |
| Let’s play a recreation. I say a sentence, you then make a sentence that follows up my sentence, then I give a continuation to yours and so forth. You prepared? | [{‘content’: “Let’s play a game. I say a sentence, then you make a sentence that follows up my sentence, then I give a continuation to yours and so on. You ready?”, ‘role’: ‘user’} {‘content’: “I’m ready! Let’s begin. Please provide your first sentence.”, ‘role’: ‘assistant’}] |
[{‘content’: “Let’s play a game. I say a sentence, then you make a sentence that follows up my sentence, then I give a continuation to yours and so on. You ready?”, ‘role’: ‘user’} {‘content’: ‘Sure, I would love to play.’, ‘role’: ‘assistant’}] |
[{‘content’: “Let’s play a game. I say a sentence, then you make a sentence that follows up my sentence, then I give a continuation to yours and so on. You ready?”, ‘role’: ‘user’} {‘content’: “I’m ready! Let’s begin. Please provide your first sentence.”, ‘role’: ‘assistant’}] |
considerably higher |
Artificial knowledge creation method for the instruction-tuning dataset format utilizing the Self-Instruct approach
Artificial knowledge creation utilizing the Self-Instruct approach is likely one of the most well-known approaches for producing instruction-finetuning datasets. This technique makes use of the capabilities of LLMs to bootstrap a various and in depth assortment of instruction-tuning examples, considerably lowering the necessity for handbook annotation. The next determine reveals the method of the Self-Instruct approach, which is described within the following sections.
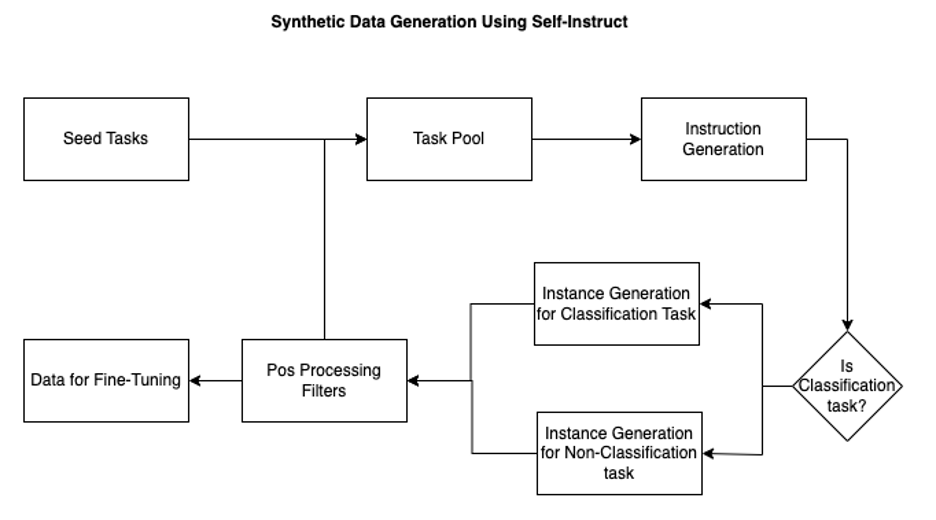
Seed knowledge and duties
The seed knowledge course of begins with a small set of human-written instruction-output pairs that function seed knowledge. The seed dataset serves as the muse for constructing a strong assortment of duties utilized in numerous domains, with a concentrate on selling activity variety. In some circumstances, the enter area offers context to help the instruction, particularly in classification duties the place output labels are restricted. However, for duties which might be non-classification, the instruction alone is likely to be self-contained with no need extra enter. This dataset encourages activity selection by way of totally different knowledge codecs and options, making it a essential step in defining the ultimate activity pool, which helps the event of various AI purposes.
The next is an instance of a seed activity that identifies monetary entities (firms, authorities establishments, or belongings) and assigns part of speech tag or entity classification primarily based on the given sentence.
The next instance requests a proof of a monetary idea, and since it isn’t a classification activity, the output is extra open-ended.
Instruction era
Utilizing the seed knowledge as a basis, an LLM is prompted to generate new directions. The method makes use of current human-written directions as examples to assist a mannequin (reminiscent of Anthropic’s Claude 3.5 or Meta Llama 405B) to generate new directions, that are then checked and filtered for high quality earlier than being added to the ultimate output checklist.
Occasion era
For every generated instruction, the mannequin creates corresponding input-output pairs. This step produces concrete examples of find out how to comply with the directions. The Enter-First Method for non-classification duties asks the mannequin to first generate the enter values, which is able to then be used to generate the corresponding output. This method is very helpful for duties reminiscent of monetary calculations, the place the output immediately is determined by particular inputs.
The Output-First Method for classification duties is designed to first outline the output (class label), after which situation the enter era primarily based on the output. This method verifies that inputs are created in such a manner that they correspond to the pre-defined class labels.
Submit-processing filters
The filtering and high quality management step verifies the dataset high quality by making use of numerous mechanisms to take away low-quality or redundant examples. After producing duties, cases are extracted and formatted, adopted by filtering primarily based on guidelines reminiscent of eradicating cases the place the enter and output are equivalent, the output is empty, or the occasion is already within the activity pool. Further heuristic checks, reminiscent of incomplete generations or formatting points, are additionally utilized to take care of the integrity of the ultimate dataset.
For extra particulars on self-instruct artificial knowledge creation, see Alpaca: A Sturdy, Replicable Instruction-Following Mannequin for details about the information creation method and instruction fine-tuning with the dataset. You’ll be able to comply with the same method for numerous fine-tuning duties together with instruction fine-tuning and direct desire optimization.
Knowledge labeling for various downstream duties (reminiscent of, code languages, summarization, and so forth)
With regards to getting ready the information for coaching an LLM, knowledge labeling performs a vital position as a result of it immediately controls and impacts the standard of responses a mannequin produces. Usually, for coaching an LLM, there are a number of approaches you could take. It is determined by the duty at hand as a result of we count on the LLM to work on a wide range of use circumstances. The rationale we see base basis fashions excelling a wide range of directions and duties is as a result of through the pre-training course of, we supplied such directions and examples to the mannequin so it will possibly perceive the directions and carry out the duties. For instance, asking the mannequin to generate code or carry out identify entity extraction. Coaching the LLM for every sort of activity requires task-specific labeled datasets. Let’s discover a few of the frequent data-labeling approaches:
- Human labelers: The most typical technique for knowledge labeling is to make use of human labelers. On this method, a group of human labelers annotates knowledge for numerous duties, reminiscent of normal question-answering, sentiment evaluation, summarization, evaluating numerous textual content for similarity and variations, and so forth. For every class of activity, you put together a dataset for the varied duties and ask the human labelers to offer the solutions. To mitigate particular person bias, you possibly can gather a number of responses for a similar query by sourcing solutions from a number of human labelers after which consolidate responses into an combination label. Human labeling is thought to be the gold normal for accumulating high-quality knowledge at scale. Nevertheless, the method of labeling by hand tends to be tedious, time-consuming, and costly for labeling duties that contain thousands and thousands of knowledge factors, which has motivated the research of AI-assisted knowledge annotation instruments—reminiscent of Snapper—that interactively scale back the burden of handbook annotation.
- LLM-assisted labeling: One other frequent method to labeling is to make use of one other LLM to label the information to hurry up the labeling course of. On this method, you utilize one other LLM to generate the responses for the varied duties reminiscent of sentiment evaluation, summarization, coding, and so forth. This may be achieved in several methods. In some circumstances, we will use N-shot studying approaches to enhance the standard of the label. To mitigate bias, we use the human-in-the-loop (HITL) method to evaluate sure responses to confirm that the labels are prime quality. The advantage of this method is that it’s sooner than human labeling as a result of you possibly can scale the LLM endpoint and serve a number of requests in parallel. Nevertheless, the draw back is that it’s important to hold iterating and altering the acceptance threshold of confidence of the mannequin’s response. For instance, in case you’re getting ready the dataset for monetary crime, it’s important to decrease the tolerance for false negatives and settle for barely increased false positives.
- Cohort-based labeling: Cohort-based labeling is an rising method the place greater than two LLMs are requested to generate the label for a similar knowledge. The fashions are then requested whether or not they agree with the opposite mannequin’s response. The label is accepted if each fashions agree with one another’s response. There may be one other variation of this method the place as a substitute of asking the fashions to agree with one another’s responses, you utilize a 3rd LLM to price the standard of the output of the opposite two fashions. It produces prime quality outputs, however the price of labeling rises exponentially as a result of it’s essential make a minimum of three LLM invocation requires every knowledge level to provide the ultimate label. This method is below lively analysis, and we count on extra orchestration instruments for this within the close to future.
- RLHF-based knowledge labeling: This method is impressed by the RLHF fine-tuning course of. Primarily based on the duty at hand, you first take a pattern of unlabeled knowledge factors and have them labeled by a human labeler. You then use the labeled dataset to fine-tune an LLM. The subsequent step is to make use of the fine-tuned LLM to provide a number of outputs for an additional subset of unlabeled knowledge factors. A human labeler ranks the outputs from finest to worst and you utilize this knowledge to coach a reward mannequin. You then ship the remainder of the unlabeled knowledge factors by way of the re-enforcement-learned PPO initialized by way of supervised coverage. The coverage generates the label and you then ask the reward mannequin to calculate a reward for the label. The reward is additional used to replace the PPO coverage. For additional studying on this subject, see Bettering your LLMs with RLHF on Amazon SageMaker.
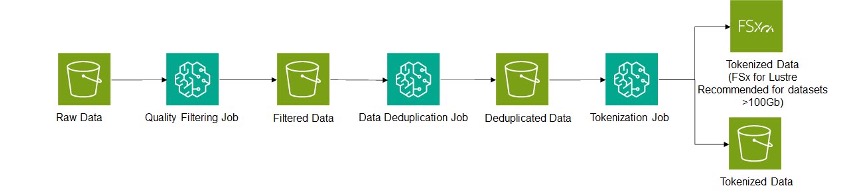
Knowledge processing structure
The complete knowledge processing pipeline may be achieved utilizing a collection of jobs as illustrated within the following structure diagram. Amazon SageMaker is used as a job facility to filter, deduplicate, and tokenize the information. The intermediate outputs of every job may be saved on Amazon Easy Storage Service (Amazon S3). Relying on the dimensions of the ultimate datasets, both Amazon S3 or FSx for Lustre can be utilized for storing the ultimate dataset. For bigger datasets, FSx can present vital enhancements within the coaching throughput by eliminating the necessity to copy or stream knowledge immediately from S3. An instance pipeline utilizing the Hugging Face DataTrove library is supplied on this repo.
Pipeline for fine-tuning
As beforehand mentioned, fine-tuning knowledge is often comprised of an enter instruction and the specified outputs. This knowledge may be sourced utilizing handbook human annotation, artificial era, or a mixture of the 2. The next structure diagram outlines an instance pipeline the place fine-tuning knowledge is generated from an current corpus of domain-specific paperwork. An instance of a fine-tuning dataset would take a supply doc as enter or context and generate task-specific responses reminiscent of a abstract of the doc, key data extracted from the doc, or solutions to questions in regards to the doc.
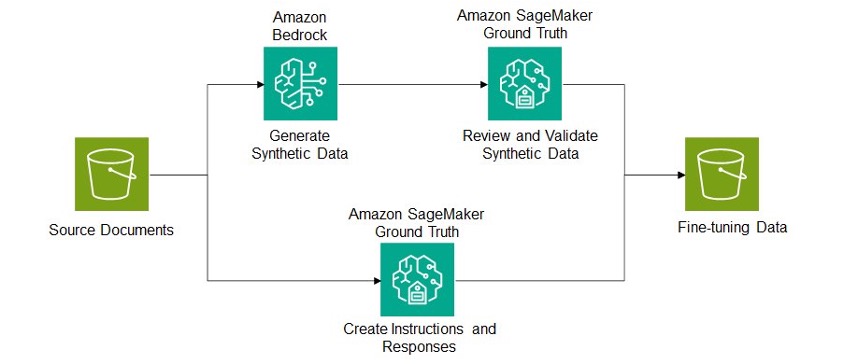
Fashions supplied by Amazon Bedrock can be utilized to generate the artificial knowledge, which may then be validated and modified by a human reviewer utilizing Amazon SageMaker Floor Reality. SageMaker Floor Reality can be used to create human-labeled knowledge fine-tuning from scratch. For artificial knowledge era, remember to evaluate the mannequin supplier’s acceptable utilization phrases to confirm compliance.
Pipeline for DPO
After a mannequin is fine-tuned, it may be deployed on mannequin internet hosting providers reminiscent of Amazon SageMaker. The hosted mannequin can then be used to generate candidate responses to numerous prompts. By way of SageMaker Floor Reality, customers can then present suggestions on which responses they like, leading to a desire dataset. This circulation is printed within the following structure diagram and may be repeated a number of occasions because the mannequin tunes utilizing the most recent desire knowledge.

Conclusion
Getting ready high-quality datasets for LLM coaching is a essential but complicated course of that requires cautious consideration of varied elements. From extracting and cleansing knowledge from various sources to deduplicating content material and sustaining moral requirements, every step performs a vital position in shaping the mannequin’s efficiency. By following the rules outlined on this publish, organizations can curate well-rounded datasets that seize the nuances of their area, resulting in extra correct and dependable LLMs.
Concerning the Authors
 Simon Zamarin is an AI/ML Options Architect whose foremost focus helps clients extract worth from their knowledge belongings. In his spare time, Simon enjoys spending time with household, studying sci-fi, and dealing on numerous DIY home tasks.
Simon Zamarin is an AI/ML Options Architect whose foremost focus helps clients extract worth from their knowledge belongings. In his spare time, Simon enjoys spending time with household, studying sci-fi, and dealing on numerous DIY home tasks.
 Vikram Elango is an AI/ML Specialist Options Architect at Amazon Internet Companies, primarily based in Virginia USA. Vikram helps monetary and insurance coverage trade clients with design, thought management to construct and deploy machine studying purposes at scale. He’s at present centered on pure language processing, accountable AI, inference optimization and scaling ML throughout the enterprise. In his spare time, he enjoys touring, mountaineering, cooking and tenting together with his household.
Vikram Elango is an AI/ML Specialist Options Architect at Amazon Internet Companies, primarily based in Virginia USA. Vikram helps monetary and insurance coverage trade clients with design, thought management to construct and deploy machine studying purposes at scale. He’s at present centered on pure language processing, accountable AI, inference optimization and scaling ML throughout the enterprise. In his spare time, he enjoys touring, mountaineering, cooking and tenting together with his household.
 Qingwei Li is a Machine Studying Specialist at Amazon Internet Companies. He obtained his Ph.D. in Operations Analysis after he broke his advisor’s analysis grant account and did not ship the Nobel Prize he promised. At the moment he helps clients within the monetary service and insurance coverage trade construct machine studying options on AWS. In his spare time, he likes studying and educating.
Qingwei Li is a Machine Studying Specialist at Amazon Internet Companies. He obtained his Ph.D. in Operations Analysis after he broke his advisor’s analysis grant account and did not ship the Nobel Prize he promised. At the moment he helps clients within the monetary service and insurance coverage trade construct machine studying options on AWS. In his spare time, he likes studying and educating.
 Vinayak Arannil is a Sr. Utilized Scientist from the AWS Bedrock group. With a number of years of expertise, he has labored on numerous domains of AI like pc imaginative and prescient, pure language processing and many others. Vinayak led the information processing for the Amazon Titan mannequin coaching. At the moment, Vinayak helps construct new options on the Bedrock platform enabling clients to construct cutting-edge AI purposes with ease and effectivity.
Vinayak Arannil is a Sr. Utilized Scientist from the AWS Bedrock group. With a number of years of expertise, he has labored on numerous domains of AI like pc imaginative and prescient, pure language processing and many others. Vinayak led the information processing for the Amazon Titan mannequin coaching. At the moment, Vinayak helps construct new options on the Bedrock platform enabling clients to construct cutting-edge AI purposes with ease and effectivity.
 Vikesh Pandey is a Principal GenAI/ML Specialist Options Architect at AWS, serving to clients from monetary industries design, construct and scale their GenAI/ML workloads on AWS. He carries an expertise of greater than a decade and a half engaged on total ML and software program engineering stack. Outdoors of labor, Vikesh enjoys making an attempt out totally different cuisines and taking part in out of doors sports activities.
Vikesh Pandey is a Principal GenAI/ML Specialist Options Architect at AWS, serving to clients from monetary industries design, construct and scale their GenAI/ML workloads on AWS. He carries an expertise of greater than a decade and a half engaged on total ML and software program engineering stack. Outdoors of labor, Vikesh enjoys making an attempt out totally different cuisines and taking part in out of doors sports activities.
 David Ping is a Sr. Supervisor of AI/ML Options Structure at Amazon Internet Companies. He helps enterprise clients construct and function machine studying options on AWS. David enjoys mountaineering and following the most recent machine studying development.
David Ping is a Sr. Supervisor of AI/ML Options Structure at Amazon Internet Companies. He helps enterprise clients construct and function machine studying options on AWS. David enjoys mountaineering and following the most recent machine studying development.
 Graham Horwood is Sr. Supervisor of Knowledge Science from the AWS Bedrock group.
Graham Horwood is Sr. Supervisor of Knowledge Science from the AWS Bedrock group.



{kind=link}