Amazon Bedrock Information Bases has prolonged its vector retailer choices by enabling assist for Amazon OpenSearch Service managed clusters, additional strengthening its capabilities as a totally managed Retrieval Augmented Era (RAG) resolution. This enhancement builds on the core performance of Amazon Bedrock Information Bases , which is designed to seamlessly join basis fashions (FMs) with inner knowledge sources. Amazon Bedrock Information Bases automates essential processes comparable to knowledge ingestion, chunking, embedding era, and vector storage, and the appliance of superior indexing algorithms and retrieval methods, empowering customers to develop clever purposes with minimal effort.
The most recent replace broadens the vector database choices out there to customers. Along with the beforehand supported vector shops comparable to Amazon OpenSearch Serverless, Amazon Aurora PostgreSQL-Suitable Version, Amazon Neptune Analytics, Pinecone, MongoDB, and Redis Enterprise Cloud, customers can now use OpenSearch Service managed clusters. This integration allows using an OpenSearch Service area as a strong backend for storing and retrieving vector embeddings, providing larger flexibility and selection in vector storage options.
To assist customers take full benefit of this new integration, this publish offers a complete, step-by-step information on integrating an Amazon Bedrock information base with an OpenSearch Service managed cluster as its vector retailer.
Why use OpenSearch Service Managed Cluster as a vector retailer?
OpenSearch Service offers two complementary deployment choices for vector workloads: managed clusters and serverless collections. Each harness the highly effective vector search and retrieval capabilities of OpenSearch Service, although every excels in numerous eventualities. Managed clusters provide intensive configuration flexibility, efficiency tuning choices, and scalability that make them significantly well-suited for enterprise-grade AI purposes.Organizations in search of larger management over cluster configurations, compute cases, the flexibility to fine-tune efficiency and price, and assist for a wider vary of OpenSearch options and API operations will discover managed clusters a pure match for his or her use instances. Alternatively, OpenSearch Serverless excels in use instances that require computerized scaling and capability administration, simplified operations with out the necessity to handle clusters or nodes, computerized software program updates, and built-in excessive availability and redundancy. The optimum selection relies upon completely on particular use case, operational mannequin, and technical necessities. Listed below are some key the explanation why OpenSearch Service managed clusters provide a compelling selection for organizations:
- Versatile configuration – Managed clusters present versatile and intensive configuration choices that allow fine-tuning for particular workloads. This consists of the flexibility to pick out occasion varieties, alter useful resource allocations, configure cluster topology, and implement specialised efficiency optimizations. For organizations with particular efficiency necessities or distinctive workload traits, this degree of customization may be invaluable.
- Efficiency and price optimizations to satisfy your design standards – Vector database efficiency is a trade-off between three key dimensions: accuracy, latency, and price. Managed Cluster offers the granular management to optimize alongside one or a mix of those dimensions and meet the precise design standards.
- Early entry to superior ML options – OpenSearch Service follows a structured launch cycle, with new capabilities sometimes launched first within the open supply challenge, then in managed clusters, and later in serverless choices. Organizations that prioritize early adoption of superior vector search capabilities may profit from selecting managed clusters, which regularly present earlier publicity to new innovation. Nevertheless, for purchasers utilizing Amazon Bedrock Information Bases, these options change into useful solely after they’ve been totally built-in into the information bases. Because of this even when a function is offered in a managed OpenSearch Service cluster, it may not be instantly accessible inside Amazon Bedrock Information Bases. Nonetheless, choosing managed clusters positions organizations to reap the benefits of the newest OpenSearch developments extra promptly after they’re supported inside Bedrock Information Bases.
Conditions
Earlier than we dive into the setup, ensure you have the next conditions in place:
- Information supply – An Amazon S3 bucket (or customized supply) with paperwork for information base ingestion. We’ll assume your bucket incorporates supported paperwork varieties (PDFs, TXTs, and so forth.) for retrieval.
- OpenSearch Service area (optionally available) – For current domains, ensure that it’s in the identical Area and account the place you’ll create your Amazon Bedrock information base. As of this writing, Bedrock Information Bases requires OpenSearch Service domains with public entry; digital non-public cloud (VPC)-only domains aren’t supported but. Be sure to have the obligatory permissions to create or configure domains. This information covers setup for each new and current domains.
Resolution overview
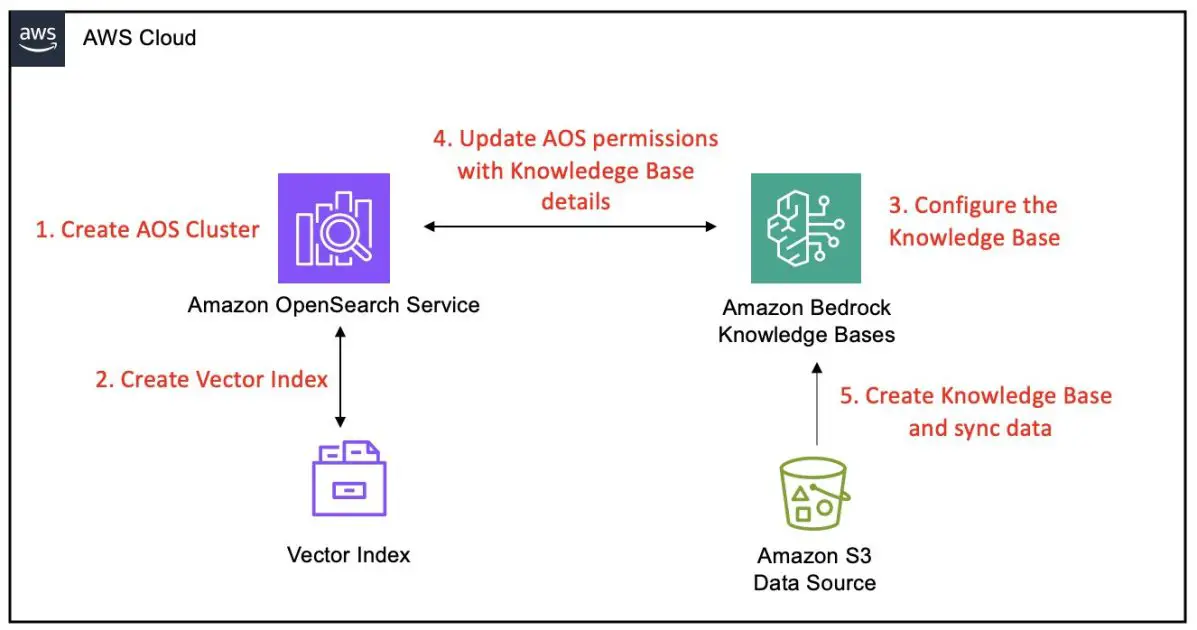
This part covers the next high-level steps to combine an OpenSearch Service managed cluster with Amazon Bedrock Information Bases:
- Create an OpenSearch Service area – Arrange a brand new OpenSearch Service managed cluster with public entry, applicable engine model, and safety settings, together with AWS Identification and Entry Administration (IAM) grasp person function and fine-grained entry management. This step consists of establishing administrative entry by creating devoted IAM sources and configuring Amazon Cognito authentication for safe dashboard entry.
- Configure a vector index in OpenSearch Service – Create a k-nearest neighbors (k-NN) enabled index on the area with the suitable mappings for vector, textual content chunk, and metadata fields to be appropriate with Amazon Bedrock Information Bases.
- Configure the Amazon Bedrock information base – Provoke the creation of an Amazon Bedrock information base, allow your Amazon Easy Storage Service (Amazon S3) knowledge supply, and configure it to make use of your OpenSearch Service area because the vector retailer with all related area particulars.
- Configure fine-grained entry management permissions in OpenSearch Service – Configure fine-grained entry management in OpenSearch Service by creating a task with particular permissions and mapping it to the Amazon Bedrock IAM service function, facilitating safe and managed entry for the information base.
- Full information base creation and ingest knowledge – Provoke a sync operation within the Amazon Bedrock console to course of S3 paperwork, generate embeddings, and retailer them in your OpenSearch Service index.
The next diagram illustrates these steps:

Resolution walkthrough
Listed below are the steps to comply with within the AWS console to combine Amazon Bedrock Information Bases with OpenSearch Service Managed Cluster.
Set up administrative entry with IAM grasp person and function
Earlier than creating an OpenSearch Service area, it’s essential create two key IAM sources: a devoted IAM admin person and a grasp function. This method facilitates correct entry administration to your OpenSearch Service area, significantly when implementing fine-grained entry management, which is strongly beneficial for manufacturing environments. This person and function may have the required permissions to create, configure, and handle the OpenSearch Service area and its integration with Amazon Bedrock Information Bases.
Create an IAM admin person
The executive person serves because the principal account for managing the OpenSearch Service configuration. To create an IAM admin person, comply with these steps:
- Open the IAM console in your AWS account
- Within the left navigation pane, select Customers after which select Create person
- Enter a descriptive username like
- On the permissions configuration web page, select Connect insurance policies immediately
- Seek for and fasten the
AmazonOpenSearchServiceFullAccessmanaged coverage, which grants complete permissions for OpenSearch Service operations - Evaluate your settings and select Create person
After creating the person, copy and save the person’s Amazon Useful resource title (ARN) for later use in area configuration, changing
The ARN will seem like this:
arn:aws:iam::
Create an IAM function to behave because the OpenSearch Service grasp person
With OpenSearch Service, you may assign a grasp person for domains with fine-grained entry management. By configuring an IAM function because the grasp person, you may handle entry utilizing trusted rules and keep away from static usernames and passwords. To create the IAM function, comply with these steps:
- On the IAM console, within the left-hand navigation pane, select Roles after which select Create function
- Select Customized belief coverage because the trusted entity kind to exactly management which principals can assume this function
- Within the JSON editor, paste the next belief coverage that enables entities, comparable to your
opensearch-adminperson, to imagine this function
- Proceed to the Add permissions web page and fasten the identical
AmazonOpenSearchServiceFullAccessmanaged coverage you used to your admin person - Present a descriptive title comparable to
OpenSearchMasterRoleand select Create function
After the function is created, navigate to its abstract web page and replica the function’s ARN. You’ll want this ARN when configuring your OpenSearch Service area’s grasp person.
arn:aws:iam::
Create an OpenSearch Service area for vector search
With the executive IAM function established, the subsequent step is to create the OpenSearch Service area that may function the vector retailer to your Amazon Bedrock information base. This includes configuring the area’s engine, community entry, and, most significantly, its safety settings utilizing fine-grained entry management.
- Within the OpenSearch Service console, choose Managed clusters as your deployment kind. Then select Create area.
- Configure your area particulars:
- Present a site title comparable to
bedrock-kb-domain. - For a fast and simple setup, select Simple create, as proven within the following screenshot. This feature robotically selects appropriate occasion varieties and default configurations optimized for growth or small-scale workloads. This manner, you may shortly deploy a useful OpenSearch Service area with out handbook configuration. Many of those settings may be modified later as your wants evolve, making this method ultimate for experimentation or nonproduction use instances whereas nonetheless offering a strong basis.
- Present a site title comparable to

In case your workload calls for larger enter/output operations per second (IOPS) or throughput or includes managing substantial volumes of knowledge, choosing Normal create is beneficial. With this feature enabled, you may customise occasion varieties, storage configurations, and superior safety settings to optimize the pace and effectivity of knowledge storage and retrieval operations, making it well-suited for manufacturing environments. For instance, you may scale the baseline GP3 quantity efficiency from 3,000 IOPS and 125 MiB/s throughput as much as 16,000 IOPS and 1,000 MiB/s throughput for each 3 TiB of storage provisioned per knowledge node. This flexibility means that you may align your OpenSearch Service area efficiency with particular workload calls for, facilitating environment friendly indexing and retrieval operations for high-throughput or large-scale purposes. These settings needs to be fine-tuned primarily based on the scale and complexity of your OpenSearch Service workload to optimize each efficiency and price.
Nevertheless, though rising your area’s throughput and storage settings might help enhance area efficiency—and may assist mitigate ingestion errors attributable to storage or node-level bottlenecks—it doesn’t improve the ingestion pace into Amazon Bedrock Information Bases as of this writing. Information base ingestion operates at a hard and fast throughput charge for purchasers and vector databases, no matter underlying area configuration. AWS continues to spend money on scaling and evolving the ingestion capabilities of Bedrock Information Bases, and future enhancements may provide larger flexibility.
- For engine model, select OpenSearch model 2.13 or larger. When you plan to retailer binary embeddings, choose model 2.16 or above as a result of it’s required for binary vector indexing. It’s beneficial to make use of the newest out there model to learn from efficiency enhancements and have updates.
- For community configuration, beneath Community, select Public entry, as proven within the following screenshot. That is essential as a result of, as of this writing, Amazon Bedrock Information Bases doesn’t assist connecting to OpenSearch Service domains which might be behind a VPC. To keep up safety, we implement IAM insurance policies and fine-grained entry controls to handle entry at a granular degree. Utilizing these controls, you may outline who can entry your sources and what actions they’ll carry out, adhering to the precept of least privilege. Choose Twin-stack mode for community settings if prompted. This allows assist for each IPv4 and IPv6, providing larger compatibility and accessibility.

- For safety, allow High quality-grained entry management to safe your area by defining detailed, role-based permissions on the index, doc, and area ranges. This function affords extra exact management in comparison with resource-based insurance policies, which function solely on the area degree.
Within the fine-grained entry management implementation part, we information you thru making a customized OpenSearch Service function with particular index and cluster permissions, then authorizing Amazon Bedrock Information Bases by associating its service function with this practice function. This mapping establishes a belief relationship that restricts Bedrock Information Bases to solely the operations you’ve explicitly permitted when accessing your OpenSearch Service area with its service credentials, facilitating safe and managed integration.
When enabling fine-grained entry management, you could choose a grasp person to handle the area. You have got two choices:
-
- Create grasp person (Username and Password) – This feature establishes credentials in OpenSearch Service inner person database, offering fast setup and direct entry to OpenSearch Dashboards utilizing primary authentication. Though handy for preliminary configuration or growth environments, it requires cautious administration of those credentials as a separate identification out of your AWS infrastructure.
- Set IAM ARN as grasp person – This feature integrates with the AWS identification panorama, permitting IAM primarily based authentication. That is strongly beneficial for manufacturing environments the place purposes and providers already depend on IAM for safe entry and the place you want auditability and integration along with your current AWS safety posture.
For this walkthrough, we select Set IAM ARN as grasp person. That is the beneficial method for manufacturing environments as a result of it integrates along with your current AWS identification framework, offering higher auditability and safety administration.
Within the textual content field, paste the ARN of the OpenSearchMasterRole that you just created in step one, as proven within the following screenshot. This designates the IAM function because the superuser to your OpenSearch Service area, granting it full permissions to handle customers, roles, and permissions inside OpenSearch Dashboards.

Though setting an IAM grasp person is good for programmatic entry, it’s not handy for permitting customers to log in to the OpenSearch Dashboards. In a subsequent step, after the area is created and we’ve configured Cognito sources, we’ll revisit this safety configuration to allow Amazon Cognito authentication. Then you definately’ll be capable of create a user-friendly login expertise for the OpenSearch Dashboards, the place customers can check in via a hosted UI and be robotically mapped to IAM roles (such because the MasterUserRole or extra restricted roles), combining ease of use with sturdy, role-based safety. For now, proceed with the IAM ARN because the grasp person to finish the preliminary area setup.
- Evaluate your settings and select Create to launch the area. The initialization course of sometimes takes round 10–quarter-hour. Throughout this time, OpenSearch Service will arrange the area and apply your configurations.
After your area turns into lively, navigate to its element web page to retrieve the next info:
- Area endpoint – That is the HTTPS URL the place your OpenSearch Service is accessible, sometimes following the format:
https://search-- . .es.amazonaws.com - Area ARN – This uniquely identifies your area and follows the construction:
arn:aws:es:: :area/
Make certain to repeat and securely retailer each these particulars since you’ll want them when configuring your Amazon Bedrock information base in subsequent steps. With the OpenSearch Service area up and working, you now have an empty cluster able to retailer your vector embeddings. Subsequent, we transfer on to configuring a vector index inside this area.
Create an Amazon Cognito person pool
Following the creation of your OpenSearch Service area, the subsequent step is to configure an Amazon Cognito person pool. This person pool will present a safe and user-friendly authentication layer for accessing the OpenSearch Dashboards. Comply with these steps:
- Navigate to the Amazon Cognito console and select Consumer swimming pools from the principle dashboard. Select Create person pool to start the configuration course of. The most recent developer-focused console expertise presents a unified utility setup interface relatively than the normal step-by-step wizard.
- For OpenSearch Dashboards integration, select Conventional net utility. This utility kind helps the authentication stream required for dashboard entry and might securely deal with the OAuth flows wanted for the mixing.
- Enter a descriptive title within the Identify your utility area, comparable to
opensearch-kb-app. This title will robotically change into your app consumer title. - Configure how customers will authenticate along with your system. For OpenSearch integration, choose E mail as the first sign-in choice. This enables customers to enroll and check in utilizing their electronic mail addresses, offering a well-recognized authentication technique. Further choices embody Telephone quantity and Username in case your use case requires different sign-in strategies.
- Specify the person info that should be collected throughout registration. At minimal, ensure that E mail is chosen as a required attribute. That is important for account verification and restoration processes.
- This step is a essential safety configuration that specifies the place Cognito can redirect customers after profitable authentication. Within the Add a return URL area, enter your OpenSearch Dashboards URL within the following format:
https://search-.- .aos. .on.aws/_dashboards - Select Create person listing to provision your person pool and its related app consumer.
The simplified interface robotically configures optimum settings to your chosen utility kind, together with applicable safety insurance policies, OAuth flows, and hosted UI area era. Copy and save the Consumer pool ID and App consumer ID values. You’ll want them to configure the Cognito identification pool and replace the OpenSearch Service area’s safety settings.
Add an admin person to the person pool
After creating your Amazon Cognito person pool, it’s essential add an administrator person who may have entry to OpenSearch Dashboards. Comply with these steps:
- Within the Amazon Cognito console, choose your newly created person pool
- Within the left navigation pane, select Customers
- Select Create person
- Choose Ship an electronic mail invitation
- Enter an E mail deal with for the administrator, for instance,
admin@instance.com - Select whether or not to set a Momentary password or have Cognito generate one
- Select Create person

Upon the administrator’s first login, they’ll be prompted to create a everlasting password. When all the following setup steps are full, this admin person will be capable of authenticate to OpenSearch Dashboards.
Configure app consumer settings
Along with your Amazon Cognito person pool created, the subsequent step is to configure app consumer parameters that may allow seamless integration along with your OpenSearch dashboard. The app consumer configuration defines how OpenSearch Dashboards will work together with the Cognito authentication system, together with callback URLs, OAuth flows, and scope permissions. Comply with these steps:
- Navigate to your created person pool on the Amazon Cognito console and find your app consumer within the purposes record. Choose your app consumer to entry its configuration dashboard.
- Select the Login tab from the app consumer interface. This part shows your present managed login pages configuration, together with callback URLs, identification suppliers, and OAuth settings.
- To open the OAuth configuration interface, within the Managed login pages configuration part, select Edit.
- Add your OpenSearch Dashboards URL within the Allowed callback URLs part from the Create an Amazon Cognito person pool part.
- To permit authentication utilizing your person pool credentials, within the Identification suppliers dropdown record, choose Cognito person pool.
- Choose Authorization code grant from the OAuth 2.0 grant varieties dropdown record. This offers essentially the most safe OAuth stream for net purposes by exchanging authorization codes for entry tokens server-side.
- Configure OpenID Join scopes by choosing the suitable scopes from the out there choices:
- E mail: Allows entry to person electronic mail addresses for identification.
- OpenID: Gives primary OpenID Join (OIDC) performance.
- Profile: Permits entry to person profile info.
Save the configuration by selecting Save adjustments on the backside of the web page to use the OAuth settings to your app consumer. The system will validate your configuration and ensure the updates have been efficiently utilized.
Replace grasp function belief coverage for Cognito integration
Earlier than creating the Cognito identification pool, you could first replace your current OpenSearchMasterRoleto belief the Cognito identification service. That is required as a result of solely IAM roles with the correct belief coverage for cognito-identity.amazonaws.com will seem within the Identification pool function choice dropdown record. Comply with these steps:
- Navigate to IAM on the console.
- Within the left navigation menu, select Roles.
- Discover and choose OpenSearchMasterRole from the record of roles.
- Select the Belief relationships tab.
- Select Edit belief coverage.
- Exchange the present belief coverage with the next configuration that features each your IAM person entry and Cognito federated entry. Exchange
YOUR_ACCOUNT_IDalong with your AWS account quantity. DepartPLACEHOLDER_IDENTITY_POOL_IDas is for now. You’ll replace this in Step 6 after creating the identification pool:
- Select Replace coverage to avoid wasting the belief relationship configuration.
Create and configure Amazon Cognito identification pool
The identification pool serves as a bridge between your Cognito person pool authentication and AWS IAM roles in order that authenticated customers can assume particular IAM permissions when accessing your OpenSearch Service area. This configuration is important for mapping Cognito authenticated customers to the suitable OpenSearch Service entry permissions. This step primarily configures administrative entry to the OpenSearch Dashboards, permitting area directors to handle customers, roles, and area settings via a safe net interface. Comply with these steps:
- Navigate to Identification swimming pools on the Amazon Cognito console and select Create identification pool to start the configuration course of.
- Within the Authentication part, configure the sorts of entry your identification pool will assist:
- Choose Authenticated entry to allow your identification pool to problem credentials to customers who’ve efficiently authenticated via your configured identification suppliers. That is important for Cognito authenticated customers to have the ability to entry AWS sources.
- Within the Authenticated identification sources part, select Amazon Cognito person pool because the authentication supply to your identification pool.
- Select Subsequent to proceed to the permissions configuration.
- For the Authenticated function, choose Use an current function and select the
OpenSearchMasterRolethat you just created in Set up administrative entry with IAM grasp person and function. This project grants authenticated customers the excellent permissions outlined in your grasp function in order that they’ll:- Entry and handle your OpenSearch Service area via the dashboards interface.
- Configure safety settings and person permissions.
- Handle indices and carry out administrative operations.
- Create and modify OpenSearch Service roles and function mappings.

This configuration offers full administrative entry to your OpenSearch Service area. Customers who authenticate via this Cognito setup may have master-level permissions, making this appropriate for area directors who must configure safety settings, handle customers, and carry out upkeep duties.
- Select Subsequent to proceed with identification supplier configuration.
- From the dropdown record, select the Consumer pool you created in Create an Amazon Cognito person pool.
- Select the app consumer you configured within the earlier step from the out there choices within the App consumer dropdown record.
- Preserve the default function setting, which is able to assign the
OpenSearchMasterRoleto authenticated customers from this person pool. - Select Subsequent.
- Present a descriptive title comparable to
OpenSearchIdentityPool. - Evaluate all configuration settings and select Create identification pool. Amazon Cognito will provision the identification pool and set up the required belief relationships. After creation, copy the identification pool ID.
To replace your grasp function’s belief coverage with the identification pool ID, comply with these steps:
- On the IAM console within the left navigation menu, select Roles
- From the record of roles, discover and choose OpenSearchMasterRole
- Select the Belief relationships tab and select Edit belief coverage
- Exchange
PLACEHOLDER_IDENTITY_POOL_IDalong with your identification pool ID from the earlier step - To finalize the configuration, select Replace coverage
Your authentication infrastructure is now configured to offer safe, administrative entry to OpenSearch Dashboards via Amazon Cognito authentication. Customers who authenticate via the Cognito person pool will assume the grasp function and achieve full administrative capabilities to your OpenSearch Service area.
Allow Amazon Cognito authentication for OpenSearch Dashboards
After organising your Cognito person pool, app consumer, and identification pool, the subsequent step is to configure your OpenSearch Service area to make use of Cognito authentication for OpenSearch Dashboards. Comply with these steps:
- Navigate to the Amazon OpenSearch Service console
- Choose the title of the area that you just beforehand created
- Select the Safety configuration tab and select Edit
- Scroll to the Amazon Cognito authentication part and choose Allow Amazon Cognito authentication, as proven within the following screenshot
- You’ll be prompted to offer the next:
- Cognito person pool ID: Enter the person pool ID you created in a earlier step
- Cognito identification pool ID: Enter the identification pool ID you created
- Evaluate your settings and select Save adjustments

The area will replace its configuration, which could take a number of minutes. You’ll obtain a progress pop-up, as proven within the following screenshot.

Create a k-NN vector index in OpenSearch Service
This step includes making a vector search–enabled index in your OpenSearch Service area for Amazon Bedrock to retailer doc embedding vectors, textual content chunks, and metadata. The index should comprise three important fields: an embedding vector area that shops numerical representations of your content material (in floating-point or binary format), a textual content area that holds the uncooked textual content chunks, and a area for Amazon Bedrock managed metadata the place Amazon Bedrock tracks essential info comparable to doc IDs and supply attributions. With correct index mapping, Amazon Bedrock Information Bases can effectively retailer and retrieve the elements of your doc knowledge.
You create this index utilizing the Dev Instruments function in OpenSearch Dashboards. To entry Dev Instruments in OpenSearch Dashboards, comply with these steps:
- Register to your OpenSearch Dashboards account
- Navigate to your OpenSearch Dashboards URL
- You’ll be redirected to the Cognito sign-in web page
- Register utilizing the admin person credentials you created within the Add an admin person to the person pool part
- Enter the e-mail deal with you supplied (
admin@instance.com) - Enter your password (if that is your first sign-in, you’ll be prompted to create a everlasting password)
- After profitable authentication, you’ll be directed to the OpenSearch Dashboards dwelling web page
- Within the left navigation pane beneath the Administration group, select Dev Instruments
- Verify you’re on the Console web page, as proven within the following screenshot, the place you’ll enter API instructions

To outline and create the index copy the next command into the Dev Instruments console and exchange bedrock-kb-index along with your most popular index title if wanted. When you’re organising a binary vector index (for instance, to make use of binary embeddings with Amazon Titan Textual content Embeddings V2), embody the extra required fields in your index mapping:
- Set “
data_type“: “binary” for the vector area - Set “
space_type“: “hamming” (as an alternative of “l2”, which is used for float embeddings)
For extra particulars, consult with the Amazon Bedrock Information Bases setup documentation.
The important thing elements of this index mapping are:
- k-NN enablement – Prompts k-NN performance within the index settings, permitting using
knn_vectorarea kind. - Vector area configuration – Defines the
embeddingsarea for storing vector knowledge, specifying dimension, house kind, and knowledge kind primarily based on the chosen embedding mannequin. It’s essential to match the dimension with the embedding mannequin’s output. Amazon Bedrock Information Bases affords fashions comparable to Amazon Titan Embeddings V2 (with 256, 512, or 1,024 dimensions) and Cohere Embed (1,024 dimensions). For instance, utilizing Amazon Titan Embeddings V2 with 1,024 dimensions requires setting dimension: 1024 within the mapping. A mismatch between the mannequin’s vector dimension and index mapping will trigger ingestion failures, so it’s essential to confirm this worth. - Vector technique setup – Configures the hierarchical navigable small world (HNSW) algorithm with the Faiss engine, setting parameters for balancing index construct pace and accuracy. Amazon Bedrock Information Bases integration particularly requires the Faiss engine for OpenSearch Service k-NN index.
- Textual content chunk storage – Establishes a area for storing uncooked textual content chunks from paperwork, enabling potential full-text queries.
- Metadata area – Creates a area for Amazon Bedrock managed metadata, storing important info with out indexing for direct searches.
After pasting the command into the Dev Instruments console, select Run. If profitable, you’ll obtain a response just like the one proven within the following screenshot.

Now, it’s best to have a brand new index (for instance, named bedrock-kb-index) in your area with the previous mapping. Make a remark of the index title you created, the vector area title (embeddings), the textual content area title (AMAZON_BEDROCK_TEXT_CHUNK), and the metadata area title (AMAZON_BEDROCK_METADATA). Within the subsequent steps, you’ll grant Amazon Bedrock permission to make use of this index after which plug these particulars into the Amazon Bedrock Information Bases setup.
With the vector index efficiently created, your OpenSearch Service area is now able to retailer and retrieve embedding vectors. Subsequent, you’ll configure IAM roles and entry insurance policies to facilitate safe interplay between Amazon Bedrock and your OpenSearch Service area.
Provoke Amazon Bedrock information base creation
Now that your OpenSearch Service area and vector index are prepared, it’s time to configure an Amazon Bedrock information base to make use of this vector retailer. On this step, you’ll:
- Start creating a brand new information base within the Amazon Bedrock console
- Configure it to make use of your current OpenSearch Service area as a vector retailer
We’ll pause the information base creation halfway to replace OpenSearch Service entry insurance policies earlier than finalizing the setup.
To create the Amazon Bedrock information base within the console, comply with these steps. For detailed directions, consult with Create a information base by connecting to a knowledge supply in Amazon Bedrock Information Bases within the AWS documentation. The next steps present a streamlined overview of the overall course of:
- On the Amazon Bedrock Console, go to Information Bases and select Create with vector retailer.
- Enter a reputation and outline and select Create and use a brand new service function for the runtime function. Select Amazon S3 as the information supply for the information base.
- Present the small print for the information supply, together with knowledge supply title, location, Amazon S3 URI, and maintain the parsing and chunking methods as default.
- Select Amazon Titan Embeddings v2 as your embeddings mannequin to transform your knowledge. Make certain the embeddings dimensions match what you configured in your index mappings within the Create an OpenSearch Service area for vector search part as a result of mismatches will trigger the mixing to fail.
To configure OpenSearch Service Managed Cluster because the vector retailer, comply with these steps:
- Underneath Vector database, choose Use an current vector retailer and for Vector retailer, choose OpenSearch Service Managed Cluster, as proven within the following screenshot

- Enter the small print out of your OpenSearch Service area setup within the following fields, as proven within the following screenshot:
- Area ARN: Present the ARN of your OpenSearch Service area.
- Area endpoint: Enter the endpoint URL of your OpenSearch Service area.
- Vector index title: Specify the title of the vector index created in your OpenSearch Service area.
- Vector area title
- Textual content area title
- Bedrock-managed metadata area title

You need to not select Create but. Amazon Bedrock will likely be able to create the information base, however it’s essential configure OpenSearch Service entry permissions first. Copy the ARN of the brand new IAM service function that Amazon Bedrock will use for this data base (the console will show the function ARN you chose or simply created). Preserve this ARN helpful and depart the Amazon Bedrock console open (pause the creation course of right here).
Configure fine-grained entry management permissions in OpenSearch Service
With the IAM service function ARN copied, configure fine-grained permissions within the OpenSearch dashboard. High quality-grained entry management offers role-based permission administration at a granular degree (indices, paperwork, and fields), in order that your Amazon Bedrock information base has exactly managed entry. Comply with these steps:
- On the OpenSearch Service console, navigate to your OpenSearch Service area.
- Select the URL for OpenSearch Dashboards. It sometimes seems to be like:
https:///_dashboards/ - From the OpenSearch Dashboards interface, within the left navigation pane, select Safety, then select Roles.
- Select Create function and supply a significant title, comparable to
bedrock-knowledgebase-role. - Underneath Cluster Permissions, enter the next permissions obligatory for Amazon Bedrock operations, as proven within the following screenshot:

- Underneath Index permissions:
- Specify the precise vector index title you created beforehand (for instance,
bedrock-kb-index). - Select Create new permission group, then select Create new motion group.
- Add the next particular permissions, important for Amazon Bedrock Information Bases:
- Verify by selecting Create.
- Specify the precise vector index title you created beforehand (for instance,
To map the Amazon Bedrock IAM service function (copied earlier) to the newly created OpenSearch Service function, comply with these steps:
- In OpenSearch Dashboards, navigate to Safety after which Roles.
- Find and open the function you created within the earlier step (
bedrock-knowledgebase-role). - Select the Mapped customers tab and select Handle mapping, as proven within the following screenshot.
- Within the Backend roles part, paste the information base’s service function ARN you copied from Amazon Bedrock (for instance,
arn:aws:iam::). When mapping this IAM function to an OpenSearch Service function, the IAM function doesn’t must exist in your AWS account on the time of mapping. You’re referencing its ARN to determine the affiliation throughout the OpenSearch backend. This enables OpenSearch Service to acknowledge and authorize the function when it’s finally created and used. Make it possible for the ARN is accurately specified to facilitate correct permission mapping.:function/service-role/BedrockKnowledgeBaseRole - Select Map to finalize the connection between the IAM function and OpenSearch Service permissions.

Full information base creation and confirm resource-based coverage
With fine-grained permissions in place, return to the paused Amazon Bedrock console to finalize your information base setup. Verify that each one OpenSearch Service area particulars are accurately entered, together with the area endpoint, area ARN, index title, vector area title, textual content area title, and metadata area title. Select Create information base.
Amazon Bedrock will use the configured IAM service function to securely connect with your OpenSearch Service area. After the setup is full, the information base standing ought to change to Out there, confirming profitable integration.
Understanding entry insurance policies
When integrating OpenSearch Service Managed Cluster with Amazon Bedrock Information Bases, it’s essential to grasp how entry management works throughout totally different layers.
For same-account configurations (the place each the information base and OpenSearch Service area are in the identical AWS account), no updates to the OpenSearch Service area’s resource-based coverage are required so long as fine-grained entry management is enabled and your IAM function is accurately mapped. On this case, IAM permissions and fine-grained entry management mappings are enough to authorize entry. Nevertheless, if the area’s resource-based coverage consists of deny statements focusing on your information base service function or principals, entry will likely be blocked—no matter IAM or fine-grained entry management settings. To keep away from unintended failures, ensure that the coverage doesn’t explicitly prohibit entry to the Amazon Bedrock Information Bases service function.
For cross-account entry (when the IAM function utilized by Amazon Bedrock Information Bases belongs to a distinct AWS account than the OpenSearch Service area), you could embody an express permit assertion within the area’s resource-based coverage for the exterior function. With out this, entry will likely be denied even when all different permissions are accurately configured.

To start utilizing your information base, choose your configured knowledge supply and provoke the sync course of. This motion begins the ingestion of your Amazon S3 knowledge. After synchronization is full, your information base is prepared for info retrieval.
Conclusion
Integrating Amazon Bedrock Information Bases with OpenSearch Service Managed Cluster affords a robust resolution for vector storage and retrieval in AI purposes. On this publish, we walked you thru the method of organising an OpenSearch Service area, configuring a vector index, and connecting it to an Amazon Bedrock information base. With this setup, you’re now outfitted to make use of the total potential of vector search capabilities in your AI-driven purposes, enhancing your capability to course of and retrieve info from massive datasets effectively.
Get began with Amazon Bedrock Information Bases and tell us your ideas within the feedback part.
In regards to the authors
 Manoj Selvakumar is a Generative AI Specialist Options Architect at AWS, the place he helps startups design, prototype, and scale clever, agent-driven purposes utilizing Amazon Bedrock. He works carefully with founders to show bold concepts into production-ready options—bridging startup agility with the superior capabilities of AWS’s generative AI ecosystem. Earlier than becoming a member of AWS, Manoj led the event of knowledge science options throughout healthcare, telecom, and enterprise domains. He has delivered end-to-end machine studying programs backed by strong MLOps practices—enabling scalable mannequin coaching, real-time inference, steady analysis, and sturdy monitoring in manufacturing environments.
Manoj Selvakumar is a Generative AI Specialist Options Architect at AWS, the place he helps startups design, prototype, and scale clever, agent-driven purposes utilizing Amazon Bedrock. He works carefully with founders to show bold concepts into production-ready options—bridging startup agility with the superior capabilities of AWS’s generative AI ecosystem. Earlier than becoming a member of AWS, Manoj led the event of knowledge science options throughout healthcare, telecom, and enterprise domains. He has delivered end-to-end machine studying programs backed by strong MLOps practices—enabling scalable mannequin coaching, real-time inference, steady analysis, and sturdy monitoring in manufacturing environments.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, creator of the ebook Utilized Machine Studying and Excessive-Efficiency Computing on AWS, and a member of the Board of Administrators for Girls in Manufacturing Schooling Basis Board. She leads machine studying initiatives in varied domains comparable to laptop imaginative and prescient, pure language processing, and generative AI. She speaks at inner and exterior conferences such AWS re:Invent, Girls in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for lengthy runs alongside the seaside.
Mani Khanuja is a Tech Lead – Generative AI Specialists, creator of the ebook Utilized Machine Studying and Excessive-Efficiency Computing on AWS, and a member of the Board of Administrators for Girls in Manufacturing Schooling Basis Board. She leads machine studying initiatives in varied domains comparable to laptop imaginative and prescient, pure language processing, and generative AI. She speaks at inner and exterior conferences such AWS re:Invent, Girls in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for lengthy runs alongside the seaside.
 Dani Mitchell is a Generative AI Specialist Options Architect at AWS. He’s centered on serving to speed up enterprises the world over on their generative AI journeys with Amazon Bedrock.
Dani Mitchell is a Generative AI Specialist Options Architect at AWS. He’s centered on serving to speed up enterprises the world over on their generative AI journeys with Amazon Bedrock.
 Juan Camilo Del Rio Cuervo is a Software program Developer Engineer at Amazon Bedrock Information Bases group. He’s centered on constructing and bettering RAG experiences for AWS clients.
Juan Camilo Del Rio Cuervo is a Software program Developer Engineer at Amazon Bedrock Information Bases group. He’s centered on constructing and bettering RAG experiences for AWS clients.



{kind=link}