Massive language fashions (LLMs) have exceptional capabilities. Nonetheless, utilizing them in customer-facing functions usually requires tailoring their responses to align together with your group’s values and model id. On this submit, we reveal the right way to use direct desire optimization (DPO), a way that permits you to fine-tune an LLM with human desire knowledge, along with Amazon SageMaker Studio and Amazon SageMaker Floor Reality to align the Meta Llama 3 8B Instruct mannequin responses to your group’s values.
Utilizing SageMaker Studio and SageMaker Floor Reality for DPO
With DPO, you may fine-tune an LLM with human desire knowledge comparable to scores or rankings in order that it generates outputs that align to end-user expectations. DPO is computationally environment friendly and helps improve a mannequin’s helpfulness, honesty, and harmlessness, divert the LLM from addressing particular topics, and mitigate biases. On this method, you sometimes begin with choosing an present or coaching a brand new supervised fine-tuned (SFT) mannequin. You utilize the mannequin to generate responses and also you collect human suggestions on these responses. After that, you employ this suggestions to carry out DPO fine-tuning and align the mannequin to human preferences.
Whether or not you might be fine-tuning a pre-trained LLM with supervised fine-tuning (SFT) or loading an present fine-tuned mannequin for DPO, you sometimes want highly effective GPUs. The identical applies throughout DPO fine-tuning. With Amazon SageMaker, you will get began shortly and experiment quickly through the use of managed Jupyter notebooks outfitted with GPU cases. You may shortly get began by making a JupyterLab house in SageMaker Studio, the built-in growth atmosphere (IDE) purpose-built for machine studying (ML), launch a JupyterLab software that runs on a GPU occasion.
Orchestrating the end-to-end knowledge assortment workflow and growing an software for annotators to fee or rank mannequin responses for DPO fine-tuning will be time-consuming. SageMaker Floor Reality presents human-in-the-loop capabilities that enable you arrange workflows, handle annotators, and gather constant, high-quality suggestions.
This submit walks you thru the steps of utilizing DPO to align an SFT mannequin’s responses to the values of a fictional digital financial institution referred to as Instance Financial institution. Your pocket book runs in a JupyterLab house in SageMaker Studio powered by a single ml.g5.48xlarge occasion (8 A10G GPUs). Optionally, you may select to run this pocket book inside a smaller occasion sort comparable to ml.g5.12xlarge (4 A10G GPUs) or ml.g6.12xlarge (4 L4 GPUs) with bitsandbytes quantization. You utilize Meta Llama 3 8B Instruct (the Meta Llama 3 instruction tuned mannequin optimized for dialogue use circumstances from the Hugging Face Hub) to generate responses, SageMaker Floor Reality to gather desire knowledge, and the DPOTrainer from the HuggingFace TRL library for DPO fine-tuning along with Parameter-Environment friendly Tremendous-Tuning (PEFT). You additionally deploy the aligned mannequin to a SageMaker endpoint for real-time inference. You should use the identical strategy with different fashions.
Resolution overview
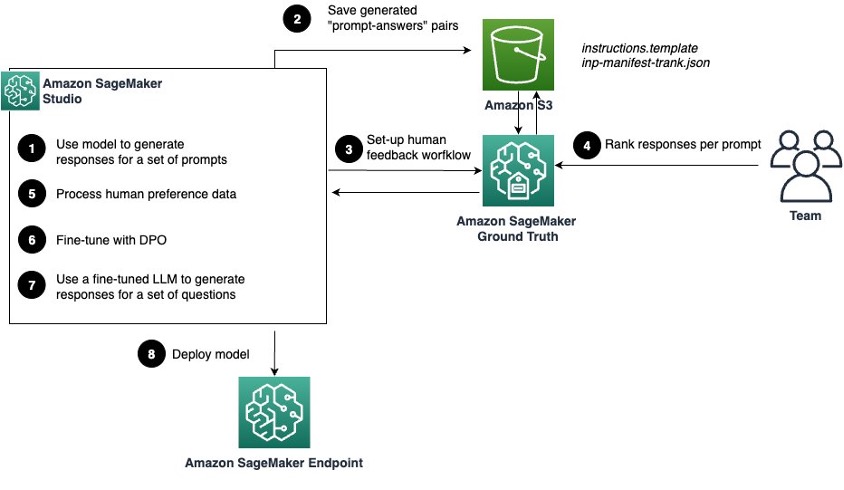
The next diagram illustrates the strategy.

The workflow incorporates the next key steps:
- Load the Meta Llama 3 8B Instruct mannequin into SageMaker Studio and generate responses for a curated set of frequent and poisonous questions. The dataset serves because the preliminary benchmark for the mannequin’s efficiency.
- The generated question-answer pairs are saved in Amazon Easy Storage Service (Amazon S3). These shall be offered to the human annotators later to allow them to rank the mannequin responses.
- Create a workflow in SageMaker Floor Reality to collect human desire knowledge for the responses. This entails creating a piece workforce, designing a UI for suggestions assortment, and establishing a labeling job.
- Human annotators work together with the labeling portal to judge and rank the mannequin’s responses primarily based on their alignment to the group’s values.
- The collected knowledge is processed to stick to the
DPOTraineranticipated format. - Utilizing the Hugging Face TRL library and the
DPOTrainer, fine-tune the Llama 3 mannequin utilizing the processed knowledge from the earlier step. - Check the fine-tuned mannequin on a holdout analysis dataset to evaluate its efficiency and confirm it meets the specified requirements.
- While you’re glad with the mannequin efficiency, you may deploy it to a SageMaker endpoint for real-time inference at scale.
Conditions
To run the answer described on this submit, you have to have an AWS account arrange, together with an AWS Id and Entry Administration (IAM) function that grants you the mandatory permissions to create and entry the answer sources. In case you are new to AWS and haven’t created an account but, seek advice from Create a standalone AWS account.
To make use of SageMaker Studio, that you must have a SageMaker area arrange with a person profile that has the mandatory permissions to launch the SageMaker Studio software. In case you’re new to SageMaker Studio, the Fast Studio setup is the quickest solution to get began. With a single click on, SageMaker provisions the required area with default presets, together with establishing the person profile, IAM function, IAM authentication, and public web entry. The pocket book related to this submit assumes the usage of an ml.g5.48xlarge occasion sort. To overview or improve your quota limits, navigate to the AWS Service Quotas console, select AWS Companies within the navigation pane, select Amazon SageMaker, and seek advice from the worth for Studio JupyterLab Apps working on ml.g5.48xlarge cases.

Request a rise in quota worth better than or equal to 1 for experimentation.

Meta Llama 3 8B Instruct is accessible beneath the Llama 3 license. To obtain the mannequin from Hugging Face, you want an entry token. In case you don’t have already got one, navigate to the Settings web page on the Hugging Face web site to acquire it.
Be sure that the SageMaker Studio function has the mandatory permissions for SageMaker Floor Reality and Amazon S3 entry. While you’re working in SageMaker Studio, you’re already utilizing an IAM function, which you’ll want to change for launching SageMaker Floor Reality labeling jobs. To allow SageMaker Floor Reality performance, it’s best to connect the AWS managed coverage AmazonSageMakerGroundTruthExecution to your SageMaker Studio function. This coverage supplies the important permissions for creating and managing labeling jobs.
For Amazon S3 entry, scoping permissions to particular buckets and actions enhances safety and aligns with greatest practices. This strategy adheres to the precept of least privilege, decreasing potential dangers related to overly permissive insurance policies. The next is an instance of a restricted Amazon S3 coverage that grants solely the mandatory permissions:
So as to add these insurance policies to your SageMaker Studio function, full the next steps:
- On the IAM console, discover and select your SageMaker Studio function (it often begins with
AmazonSageMaker-ExecutionRole-). - On the Permissions tab, select Add permissions after which Connect insurance policies.
- Seek for and fix
AmazonSageMakerGroundTruthExecution. - Create and fix the customized Amazon S3 inline coverage as proven within the previous instance, if wanted.
Keep in mind to comply with the precept of least privilege, granting solely the permissions obligatory on your particular use case. Commonly overview your IAM roles and insurance policies to validate their alignment together with your safety necessities. For extra particulars on IAM insurance policies for SageMaker Floor Reality, seek advice from Use IAM Managed Insurance policies with Floor Reality.
Arrange the pocket book and atmosphere
To get began, open SageMaker Studio and create a JupyterLab house. For Occasion, select ml.g5.48xlarge. Run the house, open JupyterLab, and clone the code within the following GitHub repository. You may configure the JupyterLab house to make use of as much as 100 GB in your Amazon Elastic Block Retailer (Amazon EBS) quantity. As well as, the ml.g5 occasion household comes with NVMe SSD native storage, which you should utilize within the JupyterLab software. The NVMe occasion retailer listing is mounted to the applying container in /mnt/sagemaker-nvme. For this submit, you employ the NVMe storage obtainable within the ml.g5.48xlarge occasion.
When your house is prepared, clone the GitHub repo and open the pocket book llama3/rlhf-genai-studio/RLHF-with-Llama3-on-Studio-DPO.ipynb, which incorporates the answer code. Within the pop-up, be sure that the Python 3 kernel is chosen.

Let’s undergo the pocket book. First, set up the mandatory Python libraries:
The next line units the default path the place you retailer short-term artifacts to the situation within the NVMe storage:
cache_dir = "/mnt/sagemaker-nvme"
That is native storage, which signifies that your knowledge shall be misplaced when the JupyterLab software is deleted, restarted, or patched. Alternatively, you may improve your EBS quantity of your SageMaker Studio house to better than or equal to 100 GB to supply enough storage for the Meta Llama 3 base mannequin, PEFT adapter, and new merged fine-tuned mannequin.
Load Meta Llama 3 8B Instruct within the pocket book
After you’ve got imported the mandatory libraries, you may obtain the Meta Llama 3 8B Instruct mannequin and its related tokenizers from Hugging Face:
Accumulate preliminary mannequin responses for frequent and poisonous questions
The example_bank_questions.txt file incorporates a listing of frequent questions acquired by name facilities in monetary organizations mixed with a listing of poisonous and off-topic questions.
Earlier than you ask the mannequin to generate solutions to those questions, that you must specify the model and core values of Instance Financial institution. You’ll embody these values within the immediate as context later so the mannequin has the suitable info it wants to reply.
Now you’re able to invoke the mannequin. For every query within the file, you assemble a immediate that incorporates the context and the precise query. You ship the immediate to the mannequin 4 occasions to generate 4 totally different outputs and save the leads to the llm_responses.json file.
The next is an instance entry from llm_reponses.json.

Arrange the SageMaker Floor Reality labeling job and human desire knowledge
To fine-tune the mannequin utilizing DPO, that you must collect human desire knowledge for the generated responses. SageMaker Floor Reality helps orchestrate the information assortment course of. It presents customizable labeling workflows and sturdy workforce administration options for rating duties. This part exhibits you the right way to arrange a SageMaker Floor Reality labeling job and invite a human workforce with requisite experience to overview the LLM responses and rank them.
Arrange the workforce
A non-public workforce in SageMaker Floor Reality consists of people who’re particularly invited to carry out knowledge labeling duties. These people will be workers or contractors who’ve the required experience to judge the mannequin’s responses. Organising a non-public workforce helps obtain knowledge safety and high quality by limiting entry to trusted people for knowledge labeling.
For this use case, the workforce consists of the group of people that will rank the mannequin responses. You may arrange a non-public workforce utilizing the SageMaker console by creating a non-public workforce and alluring members via e mail. For detailed directions, seek advice from Create a Non-public Workforce (Amazon SageMaker Console).
Create the instruction template
With the instruction template, you may handle the UI and information human annotators in reviewing mannequin outputs. It wants to obviously current the mannequin responses and supply an easy manner for the annotators to rank them. Right here, you employ the textual content rating template. This template permits you to show the directions for the human reviewer and the prompts with the pregenerated LLM responses. The annotator evaluations the immediate and responses and ranks the latter primarily based on their alignment to the group’s model.
The definition of the template is as follows. The template exhibits a pane on the left with directions from the job requester, a immediate on the high, and three LLM responses in the principle physique. The appropriate aspect of the UI is the place the annotator ranks the responses from most to least preferable.
The template is saved domestically in your Studio JupyterLab house EBS quantity as directions.template in a brief listing. Then you definitely add this template file to your designated S3 bucket utilizing s3.upload_file(), inserting it within the specified bucket and prefix. This Amazon S3 hosted template shall be referenced if you create the SageMaker Floor Reality labeling job, so employees see the right interface for the textual content rating job.
Preprocess the enter knowledge
Earlier than you create the labeling job, confirm that the enter knowledge matches the format anticipated by SageMaker Floor Reality and is saved as a JSON file in Amazon S3. You should use the prompts and responses within the llm_responses.json file to create the manifest file inp-manifest-trank.json. Every row within the manifest file incorporates a JSON object (source-responses pair). The earlier entry now seems like the next code.

Add the structured knowledge to the S3 bucket in order that it may be ingested by SageMaker Floor Reality.
Create the labeling job
Now you’re able to configure and launch the labeling job utilizing the SageMaker API from throughout the pocket book. This entails specifying the work workforce, UI template, and knowledge saved within the S3 bucket. By setting applicable parameters comparable to job closing dates and the variety of employees per knowledge object, you may run jobs effectively and successfully. The next code exhibits the right way to begin the labeling job:
Because the job is launched, it’s important to observe its progress intently, ensuring duties are being distributed and accomplished as anticipated.
Collect human suggestions via the labeling portal
When the job setup is full, annotators can log in to the labeling portal and begin rating the mannequin responses.

Employees can first seek the advice of the Directions pane to grasp the duty, then use the principle interface to judge and rank the mannequin’s responses based on the given standards. The next screenshot illustrates the UI.

The human suggestions is collected and saved in an S3 bucket. This suggestions would be the foundation for DPO. With this knowledge, you’ll fine-tune the Meta Llama 3 mannequin and align its responses with the group’s values, bettering its total efficiency.
Align Meta Llama 3 8B Instruct with the DPOTrainer
On this part, we present the right way to use the desire dataset that you simply ready utilizing SageMaker Floor Reality to fine-tune the mannequin utilizing DPO. DPO explicitly optimizes the mannequin’s output primarily based on human evaluations. It aligns the mannequin’s conduct extra intently with human expectations and improves its efficiency on duties requiring nuanced understanding and contextual appropriateness. By integrating human preferences, DPO enhances the mannequin’s relevance, coherence, and total effectiveness in producing desired responses.
DPO makes it extra easy to preference-tune a mannequin compared to different widespread methods comparable to Proximal Coverage Optimization (PPO). DPO eliminates the need for a separate rewards mannequin, thereby avoiding the price related to coaching it. Moreover, DPO requires considerably much less knowledge to realize efficiency akin to PPO.
Tremendous-tuning a language mannequin utilizing DPO consists of two steps:
- Collect a desire dataset with optimistic and destructive chosen pairs of era, given a immediate.
- Maximize the log-likelihood of the DPO loss straight.
To be taught extra in regards to the DPO algorithm, seek advice from the next whitepaper.

Anticipated knowledge format
The DPO coach expects a really particular format for the dataset, which incorporates sentence pairs the place one sentence is a selected response and the opposite is a rejected response. That is represented as a Python dictionary with three keys:
- immediate – Consists of the context immediate given to a mannequin at inference time for textual content era
- chosen – Incorporates the popular generated response to the corresponding immediate
- rejected – Incorporates the response that isn’t most well-liked or shouldn’t be the sampled response for the given immediate
The next operate definition illustrates the right way to course of the information saved in Amazon S3 to create a DPO dataset utilizing with pattern pairs and a immediate:
Right here is an instance sentence pair:

You cut up the DPO coach dataset into practice and check samples utilizing an 80/20 cut up and tokenize the dataset in preparation for DPO fine-tuning:
Supervised fine-tuning utilizing DPO
Now that the dataset is formatted for the DPO coach, you should utilize the practice and check datasets ready earlier to provoke the DPO mannequin fine-tuning. Meta Llama 3 8B belongs to a class of small language fashions, however even Meta Llama 3 8B barely matches right into a SageMaker ML occasion like ml.g5.48xlarge in fp16 or fp32, leaving little room for full fine-tuning. You should use PEFT with DPO to fine-tune Meta Llama 3 8B’s responses primarily based on human preferences. PEFT is a technique of fine-tuning that focuses on coaching solely a subset of the pre-trained mannequin’s parameters. This strategy entails figuring out a very powerful parameters for the brand new job and updating solely these parameters throughout coaching. By doing so, PEFT can considerably scale back the computation required for fine-tuning. See the next code:
For a full checklist of LoraConfig coaching arguments, seek advice from LoRA. At a excessive stage, that you must initialize the DPOTrainer with the next elements: the mannequin you need to practice, a reference mannequin (ref_model) used to calculate the implicit rewards of the popular and rejected responses, the beta hyperparameter that controls the steadiness between the implicit rewards assigned to the popular and rejected responses, and a dataset containing immediate, chosen, and rejected responses. If ref_model=None, the coach will create a reference mannequin with the identical structure because the enter mannequin to be optimized. See the next code:
When you begin the coaching, you may see the standing within the pocket book:

When mannequin fine-tuning is full, save the PEFT adapter mannequin to disk and merge it with the bottom mannequin to create a newly tuned mannequin. You should use the saved mannequin for native inference and validation or deploy it as a SageMaker endpoint after you’ve got gained enough confidence within the mannequin’s responses.
Consider the fine-tuned mannequin inside a SageMaker Studio pocket book
Earlier than you host your mannequin for inference, confirm that its response optimization aligns with person preferences. You may gather the mannequin’s response each earlier than and after DPO fine-tuning and examine them aspect by aspect, as proven within the following desk.

The DPO Mannequin Response column signifies the RLHF aligned mannequin’s response post-fine-tuning, and the Rejected Mannequin Response column refers back to the mannequin’s response to the enter immediate previous to fine-tuning.
Deploy the mannequin to a SageMaker endpoint
After you’ve got gained enough confidence in your mannequin, you may deploy it to a SageMaker endpoint for real-time inference. SageMaker endpoints are totally managed and supply auto scaling capabilities. For this submit, we use DJL Serving to host the fine-tuned, DPO-aligned Meta Llama3 8B mannequin. To be taught extra about internet hosting your LLM utilizing DJL Serving, seek advice from Deploy massive fashions on Amazon SageMaker utilizing DJLServing and DeepSpeed mannequin parallel inference.
To deploy an LLM straight out of your SageMaker Studio pocket book utilizing DJL Serving, full the next steps:
- Add mannequin weights and different mannequin artifacts to Amazon S3.
- Create a meta-model definition file referred to as
serving.properties. This definition file dictates how the DJL Serving container is configured for inference.
engine = DeepSpeedchoice.tensor_parallel_degree = 1choice.s3url = s3://choice.hf_access_token=hf_xx1234
- Create a customized inference file referred to as
mannequin.py, which defines a customized inference logic:
- Deploy the DPO fine-tuned mannequin as a SageMaker endpoint:
- Invoke the hosted mannequin for inference utilizing the
sageMaker.Predictorclass:
Clear up
After you full your duties within the SageMaker Studio pocket book, keep in mind to cease your JupyterLab workspace to stop incurring extra expenses. You are able to do this by selecting Cease subsequent to your JupyterLab house. Moreover, you’ve got the choice to arrange lifecycle configuration scripts that can robotically shut down sources once they’re not in use.

In case you deployed the mannequin to a SageMaker endpoint, run the next code on the finish of the pocket book to delete the endpoint:
Conclusion
Amazon SageMaker presents instruments to streamline the method of fine-tuning LLMs to align with human preferences. With SageMaker Studio, you may experiment interactively with totally different fashions, questions, and fine-tuning methods. With SageMaker Floor Reality, you may arrange workflows, handle groups, and gather constant, high-quality human suggestions.
On this submit, we confirmed the right way to improve the efficiency of Meta Llama 3 8B Instruct by fine-tuning it utilizing DPO on knowledge collected with SageMaker Floor Reality. To get began, launch SageMaker Studio and run the pocket book obtainable within the following GitHub repo. Share your ideas within the feedback part!
In regards to the Authors
 Anastasia Tzeveleka is a GenAI/ML Specialist Options Architect at AWS. As a part of her work, she helps prospects construct basis fashions and create scalable generative AI and machine studying options utilizing AWS companies.
Anastasia Tzeveleka is a GenAI/ML Specialist Options Architect at AWS. As a part of her work, she helps prospects construct basis fashions and create scalable generative AI and machine studying options utilizing AWS companies.
Pra nav Murthy is an AI/ML Specialist Options Architect at AWS. He focuses on serving to prospects construct, practice, deploy and migrate machine studying (ML) workloads to SageMaker. He beforehand labored within the semiconductor trade growing massive pc imaginative and prescient (CV) and pure language processing (NLP) fashions to enhance semiconductor processes. In his free time, he enjoys taking part in chess and touring.
nav Murthy is an AI/ML Specialist Options Architect at AWS. He focuses on serving to prospects construct, practice, deploy and migrate machine studying (ML) workloads to SageMaker. He beforehand labored within the semiconductor trade growing massive pc imaginative and prescient (CV) and pure language processing (NLP) fashions to enhance semiconductor processes. In his free time, he enjoys taking part in chess and touring.
 Sundar Raghavan is an AI/ML Specialist Options Architect at AWS, serving to prospects construct scalable and cost-efficient AI/ML pipelines with Human within the Loop companies. In his free time, Sundar loves touring, sports activities and having fun with out of doors actions along with his household.
Sundar Raghavan is an AI/ML Specialist Options Architect at AWS, serving to prospects construct scalable and cost-efficient AI/ML pipelines with Human within the Loop companies. In his free time, Sundar loves touring, sports activities and having fun with out of doors actions along with his household.



{kind=link}