principally a
It’s not essentially the most thrilling subject, however an increasing number of corporations are paying consideration. So it’s value digging into which metrics to trace to really measure that efficiency.
It additionally helps to have correct evals in place anytime you push modifications, to verify issues don’t go haywire.
So, for this text I’ve finished some analysis on frequent metrics for multi-turn chatbots, RAG, and agentic purposes.
I’ve additionally included a fast overview of frameworks like DeepEval, RAGAS, and OpenAI’s Evals library, so you already know when to select what.
This text is break up in two. In the event you’re new, Half 1 talks a bit about conventional metrics like BLEU and ROUGE, touches on LLM benchmarks, and introduces the thought of utilizing an LLM as a choose in evals.
If this isn’t new to you, you may skip this. Half 2 digs into evaluations of various sorts of LLM purposes.
What we did earlier than
In the event you’re effectively versed in how we consider NLP duties and the way public benchmarks work, you may skip this primary half.
In the event you’re not, it’s good to know what the sooner metrics like accuracy and BLEU have been initially used for and the way they work, together with understanding how we take a look at for public benchmarks like MMLU.
Evaluating NLP duties
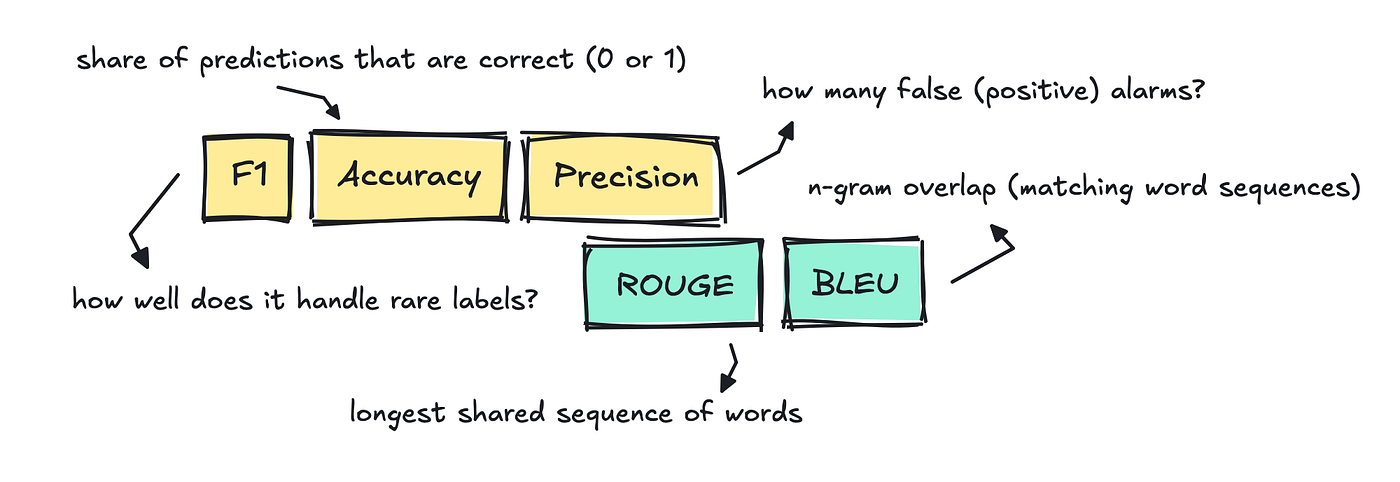
Once we consider conventional NLP duties corresponding to classification, translation, summarization, and so forth, we flip to conventional metrics like accuracy, precision, F1, BLEU, and ROUGE
These metrics are nonetheless used at present, however principally when the mannequin produces a single, simply comparable “proper” reply.
Take classification, for instance, the place the duty is to assign every textual content a single label. To check this, we will use accuracy by evaluating the label assigned by the mannequin to the reference label within the eval dataset to see if it received it proper.
It’s very clear-cut: if it assigns the mistaken label, it will get a 0; if it assigns the right label, it will get a 1.
This implies if we construct a classifier for a spam dataset with 1,000 emails, and the mannequin labels 910 of them accurately, the accuracy could be 0.91.
For textual content classification, we regularly additionally use F1, precision, and recall.
On the subject of NLP duties like summarization and machine translation, individuals typically used ROUGE and BLEU to see how intently the mannequin’s translation or abstract strains up with a reference textual content.
Each scores depend overlapping n-grams, and whereas the route of the comparability is completely different, basically it simply means the extra shared phrase chunks, the upper the rating.
That is fairly simplistic, since if the outputs use completely different wording, it’s going to rating low.
All of those metrics work greatest when there’s a single proper reply to a response and are sometimes not the appropriate selection for the LLM purposes we construct at present.
LLM benchmarks
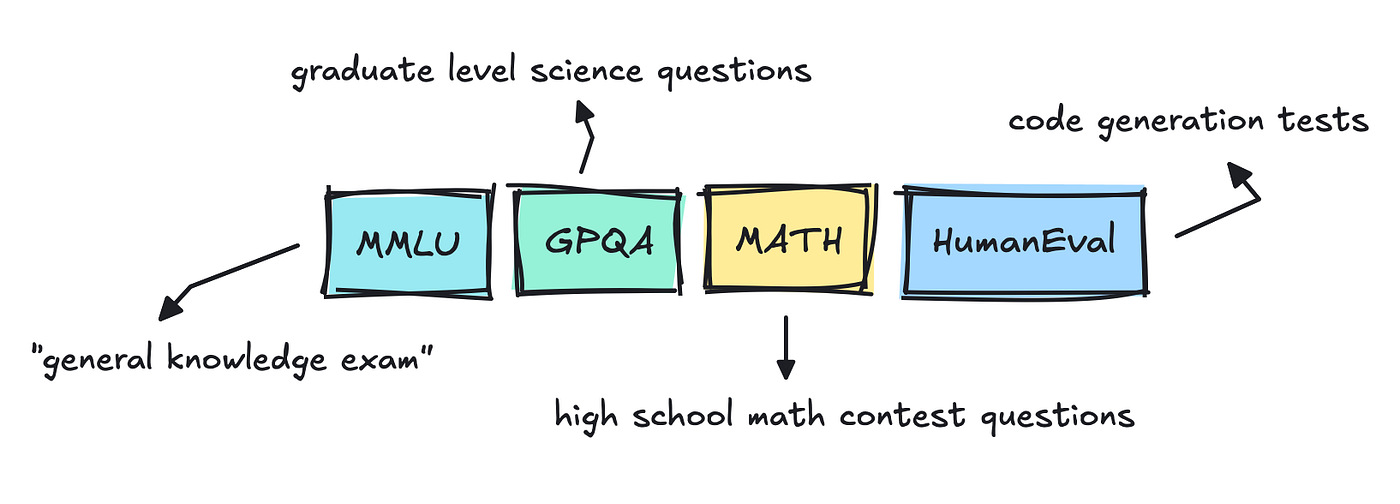
In the event you’ve watched the information, you’ve most likely seen that each time a brand new model of a giant language mannequin will get launched, it follows just a few benchmarks: MMLU Professional, GPQA, or Huge-Bench.
These are generic evals for which the right time period is admittedly “benchmark” and never evals (which we’ll cowl later).
Though there’s a wide range of different evaluations finished for every mannequin, together with for toxicity, hallucination, and bias, those that get many of the consideration are extra like exams or leaderboards.
Datasets like MMLU are multiple-choice and have been round for fairly a while. I’ve truly skimmed by way of it earlier than and seen how messy it’s.
Some questions and solutions are fairly ambiguous, which makes me assume that LLM suppliers will attempt to practice their fashions on these datasets simply to verify they get them proper.
This creates some worry in most of the people that the majority LLMs are simply overfitting once they do effectively on these benchmarks and why there’s a necessity for newer datasets and unbiased evaluations.
LLM scorers
To run evaluations on these datasets, you may often use accuracy and unit assessments. Nonetheless, what’s completely different now’s the addition of one thing known as LLM-as-a-judge.
To benchmark the fashions, groups will principally use conventional strategies.
So so long as it’s a number of selection or there’s only one proper reply, there’s no want for the rest however to check the reply to the reference for a precise match.
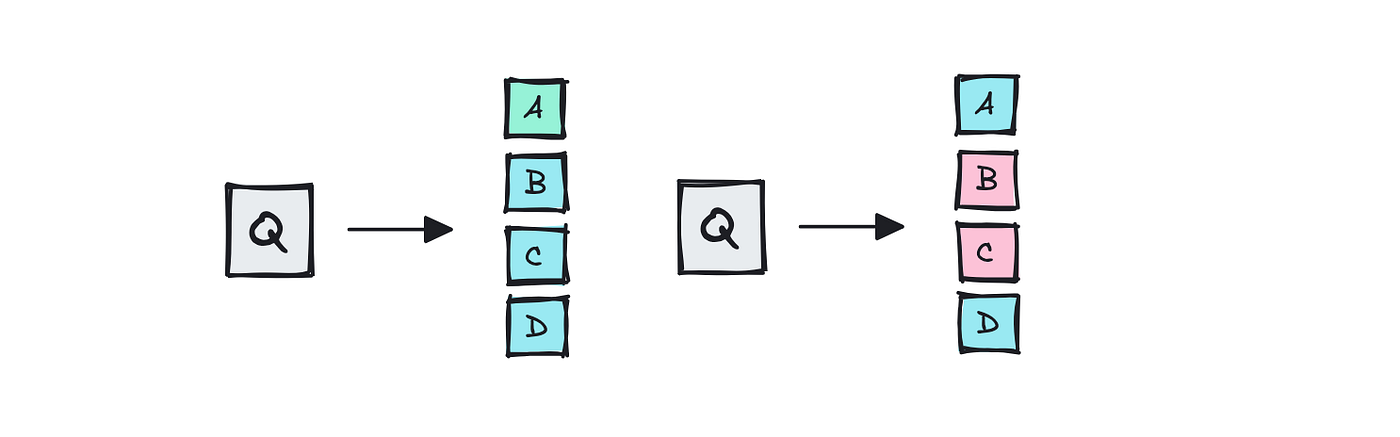
That is the case for datasets corresponding to MMLU and GPQA, which have a number of selection solutions.
For the coding assessments (HumanEval, SWE-Bench), the grader can merely run the mannequin’s patch or operate. If each take a look at passes, the issue counts as solved, and vice versa.
Nonetheless, as you may think about, if the questions are ambiguous or open-ended, the solutions could fluctuate. This hole led to the rise of “LLM-as-a-judge,” the place a big language mannequin like GPT-4 scores the solutions.
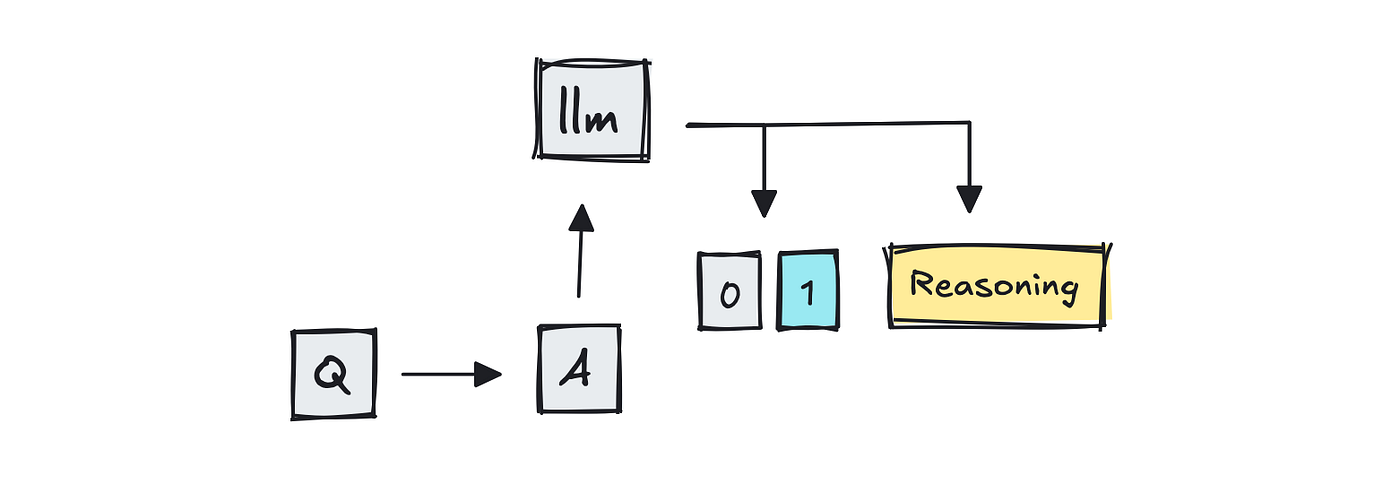
MT-Bench is without doubt one of the benchmarks that makes use of LLMs as scorers, because it feeds GPT-4 two competing multi-turn solutions and asks which one is healthier.
Chatbot Area, which use human raters, I feel now scales up by additionally incorporating the usage of an LLM-as-a-judge.
For transparency, you may as well use semantic rulers corresponding to BERTScore to check for semantic similarity. I’m glossing over what’s on the market to maintain it condensed.
So, groups should still use overlap metrics like BLEU or ROUGE for fast sanity checks, or depend on exact-match parsing when potential, however what’s new is to have one other massive language mannequin choose the output.
What we do with LLM apps
The first factor that modifications now’s that we’re not simply testing the LLM itself however your complete system.
Once we can, we nonetheless use programmatic strategies to judge, similar to earlier than.
For extra nuanced outputs, we will begin with one thing low-cost and deterministic like BLEU or ROUGE to take a look at n-gram overlap, however most trendy frameworks on the market will now use LLM scorers to judge.
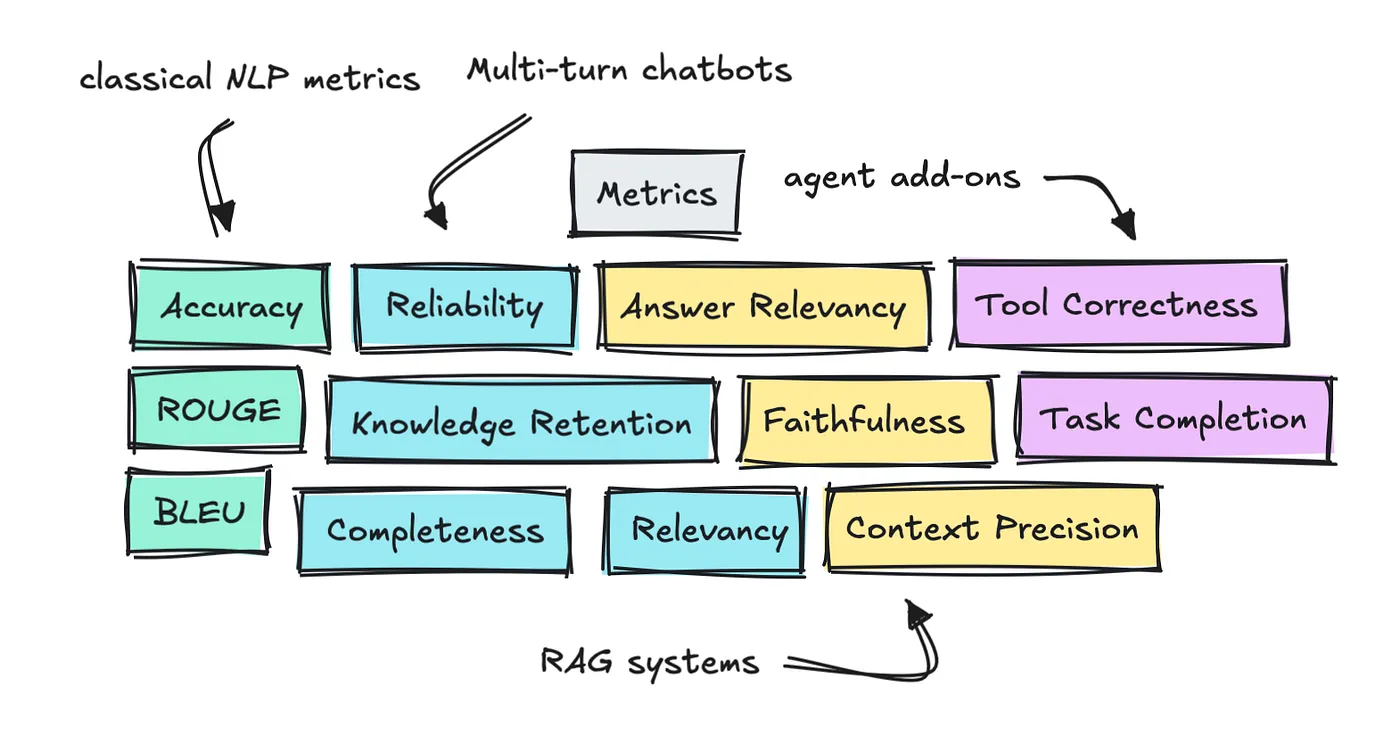
There are three areas value speaking about: how one can consider multi-turn conversations, RAG, and brokers, by way of the way it’s finished and what sorts of metrics we will flip to.
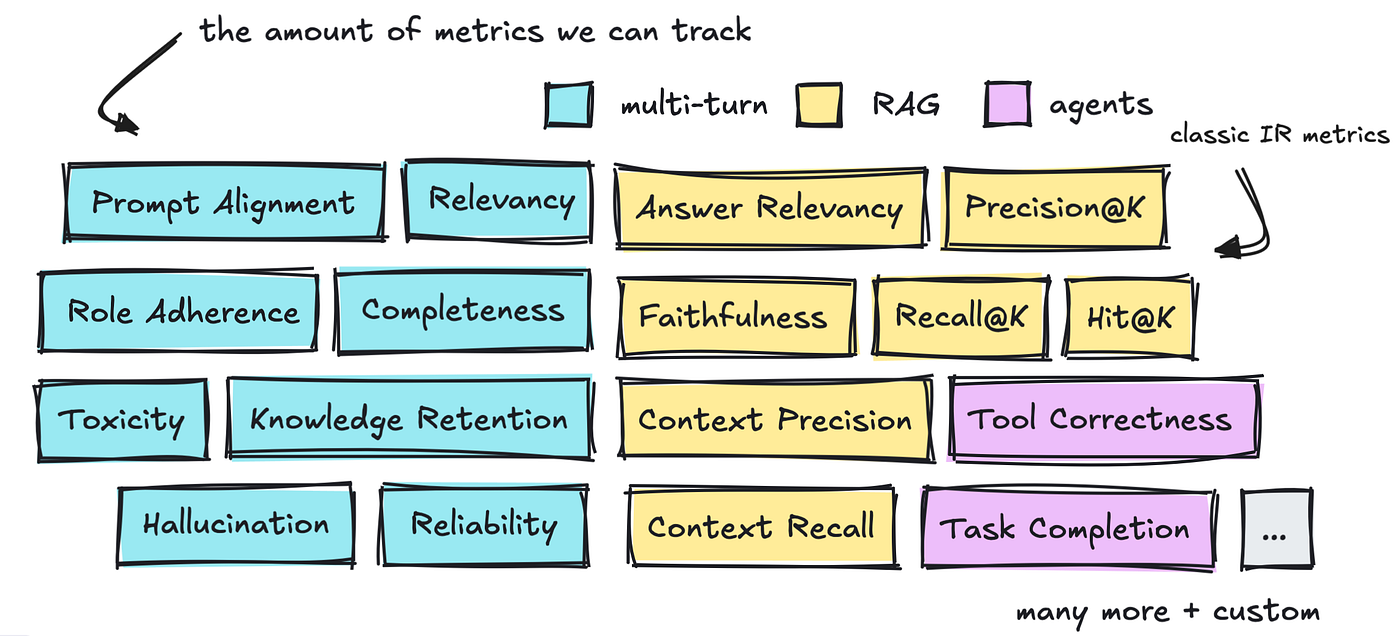
We’ll speak about all of those metrics which have already been outlined briefly earlier than shifting on to the completely different frameworks that assist us out.
Multi-turn conversations
The primary a part of that is about constructing evals for multi-turn conversations, those we see in chatbots.
Once we work together with a chatbot, we wish the dialog to really feel pure, skilled, and for it to recollect the appropriate bits. We would like it to remain on subject all through the dialog and truly reply the factor we requested.
There are fairly just a few commonplace metrics which have already been outlined right here. The primary we will speak about are Relevancy/Coherence and Completeness.
Relevancy is a metric that ought to monitor if the LLM appropriately addresses the consumer’s question and stays on subject, whereas Completeness is excessive if the ultimate consequence truly addresses the consumer’s objective.
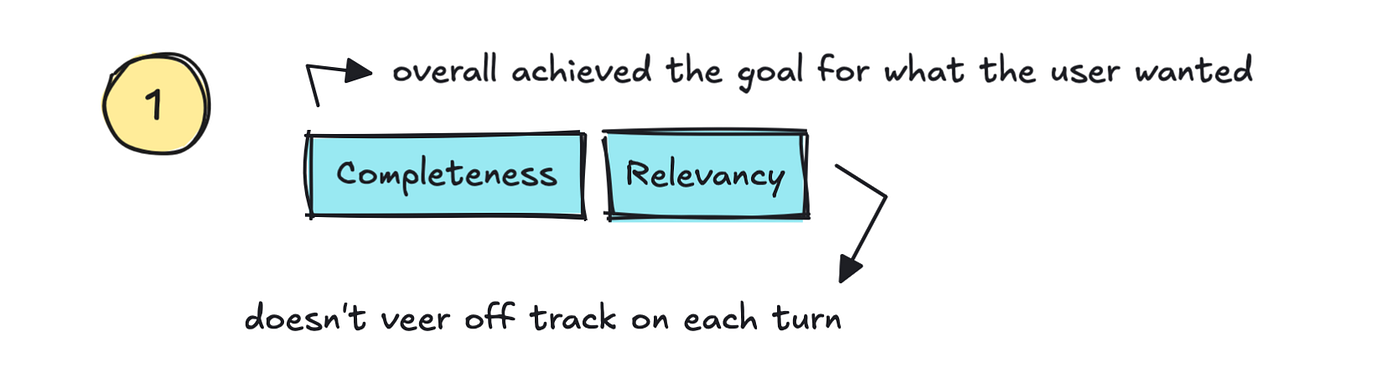
That’s, if we will monitor satisfaction throughout your complete dialog, we will additionally monitor whether or not it actually does “scale back assist prices” and improve belief, together with offering excessive “self-service charges.”
The second half is Data Retention and Reliability.
That’s: does it keep in mind key particulars from the dialog, and may we belief it to not get “misplaced”? It’s not simply sufficient that it remembers particulars. It additionally wants to have the ability to appropriate itself.
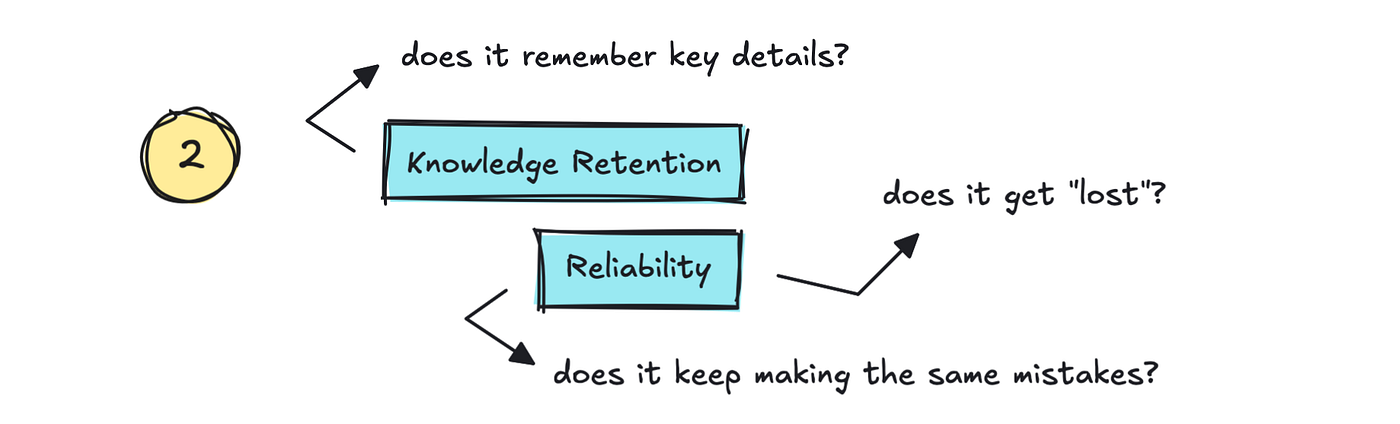
That is one thing we see in vibe coding instruments. They overlook the errors they’ve made after which maintain making them. We must be monitoring this as low Reliability or Stability.
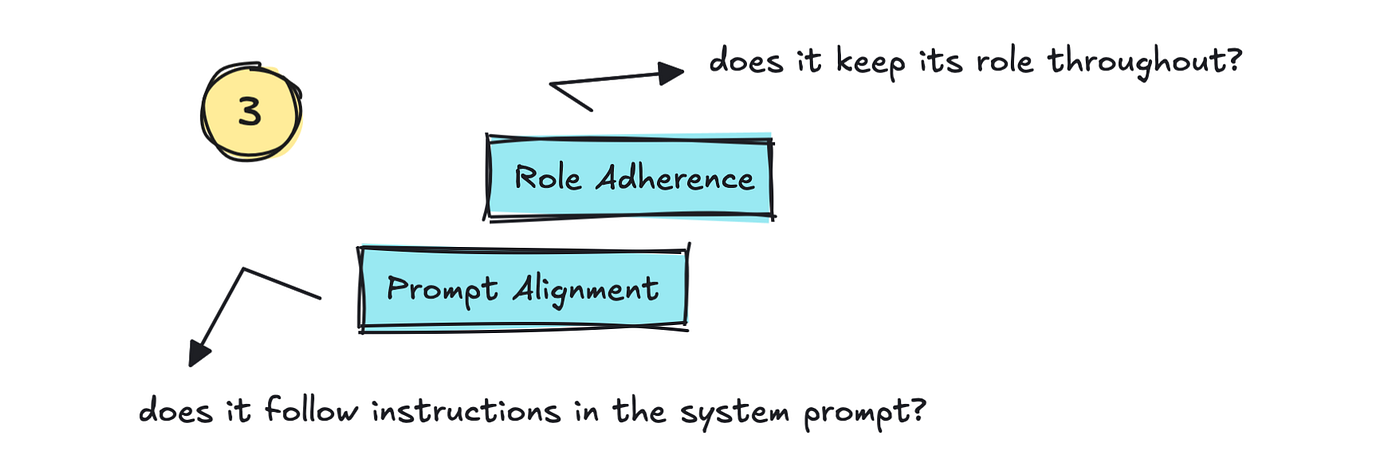
The third half we will monitor is Function Adherence and Immediate Alignment. This tracks whether or not the LLM sticks to the function it’s been given and whether or not it follows the directions within the system immediate.
Subsequent are metrics round security, corresponding to Hallucination and Bias/Toxicity.
Hallucination is necessary to trace but additionally fairly tough. Individuals could attempt to arrange internet search to judge the output, or they break up the output into completely different claims which might be evaluated by a bigger mannequin (LLM-as-a-judge type).
There are additionally different strategies, corresponding to SelfCheckGPT, which checks the mannequin’s consistency by calling it a number of instances on the identical immediate to see if it sticks to its authentic reply and what number of instances it diverges.
For Bias/Toxicity, you should use different NLP strategies, corresponding to a fine-tuned classifier.
Different metrics chances are you’ll wish to monitor might be customized to your software, for instance, code correctness, safety vulnerabilities, JSON correctness, and so forth.
As for how one can do the evaluations, you don’t all the time have to make use of an LLM, though in most of those circumstances the usual options do.
In circumstances the place we will extract the right reply, corresponding to parsing JSON, we naturally don’t want to make use of an LLM. As I stated earlier, many LLM suppliers additionally benchmark with unit assessments for code-related metrics.
It goes with out saying that utilizing an LLM as a choose isn’t all the time tremendous dependable, similar to the purposes they measure, however I don’t have any numbers for you right here, so that you’ll should hunt for that by yourself.
Retrieval Augmented Era (RAG)
To proceed constructing on what we will monitor for multi-turn conversations, we will flip to what we have to measure when utilizing Retrieval Augmented Era (RAG).
With RAG programs, we have to break up the method into two: measuring retrieval and era metrics individually.
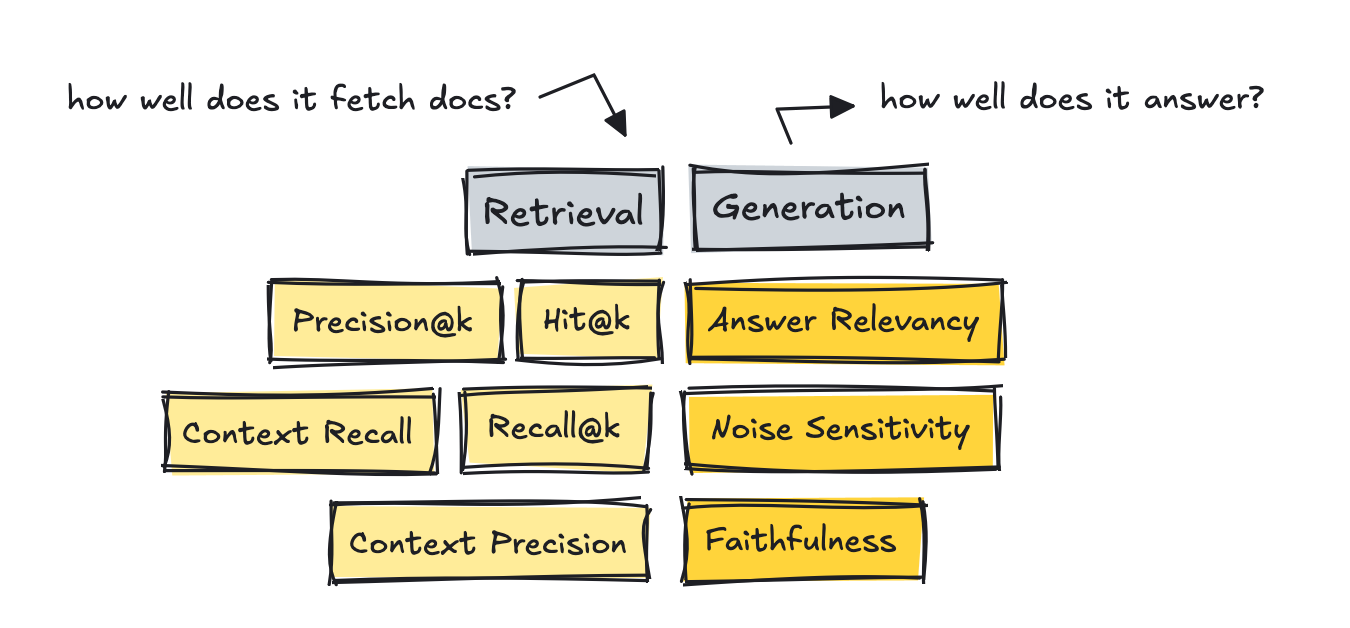
The primary half to measure is retrieval and whether or not the paperwork which might be fetched are the right ones for the question.
If we get low scores on the retrieval aspect, we will tune the system by organising higher chunking methods, altering the embedding mannequin, including strategies corresponding to hybrid search and re-ranking, filtering with metadata, and related approaches.
To measure retrieval, we will use older metrics that depend on a curated dataset, or we will use reference-free strategies that use an LLM as a choose.
I would like to say the traditional IR metrics first as a result of they have been the primary on the scene. For these, we want “gold” solutions, the place we arrange a question after which rank every doc for that individual question.
Though you should use an LLM to construct these datasets, we don’t use an LLM to measure, since we have already got scores within the dataset to check in opposition to.
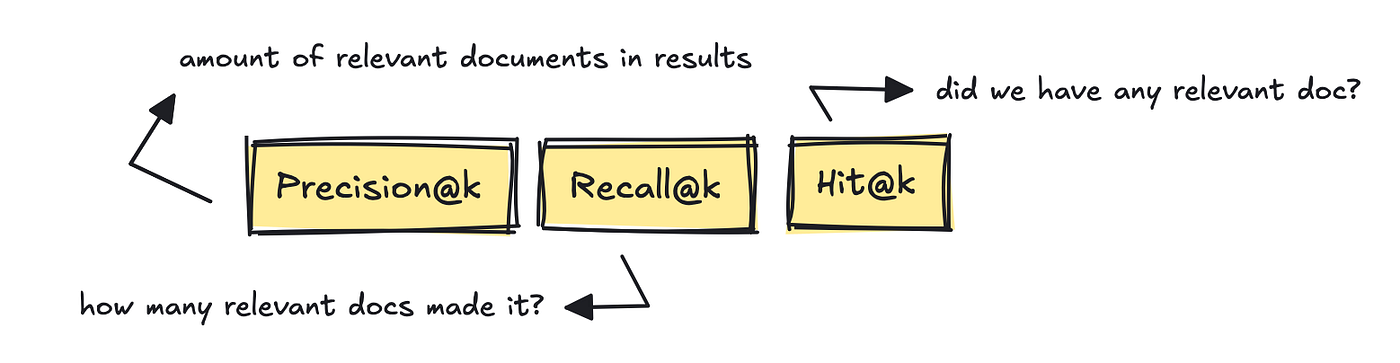
Probably the most well-known IR metrics are Precision@ok, Recall@ok, and Hit@ok.
These measure the quantity of related paperwork within the outcomes, what number of related paperwork have been retrieved based mostly on the gold reference solutions, and whether or not at the very least one related doc made it into the outcomes.
The newer frameworks corresponding to RAGAS and DeepEval introduces reference-free, LLM-judge type metrics like Context Recall and Context Precision.
These depend how most of the really related chunks made it into the highest Ok listing based mostly on the question, utilizing an LLM to guage.
That’s, based mostly on the question, did the system truly return any related paperwork based mostly on the reply, or are there too many irrelevant ones to reply the query correctly?
To construct datasets for evaluating retrieval, you may mine questions from actual logs after which use a human to curate them.
You may as well use dataset turbines with the assistance of an LLM, which exist in most frameworks or as standalone instruments like YourBench.
In the event you have been to arrange your personal dataset generator utilizing an LLM, you possibly can do one thing like beneath.
# Immediate to generate questions
qa_generate_prompt_tmpl = """
Context info is beneath.
---------------------
{context_str}
---------------------
Given the context info and no prior data
generate solely {num} questions and {num} solutions based mostly on the above context.
...
"""But it surely must be a bit extra superior.
If we flip to the era a part of the RAG system, we at the moment are measuring how effectively it solutions the query utilizing the offered docs.
If this half isn’t performing effectively, we will alter the immediate, tweak the mannequin settings (temperature, and so on.), exchange the mannequin solely, or fine-tune it for area experience. We are able to additionally drive it to “purpose” utilizing CoT-style loops, test for self-consistency, and so forth.
For this half, RAGAS is helpful with its metrics: Reply Relevancy, Faithfulness, and Noise Sensitivity.
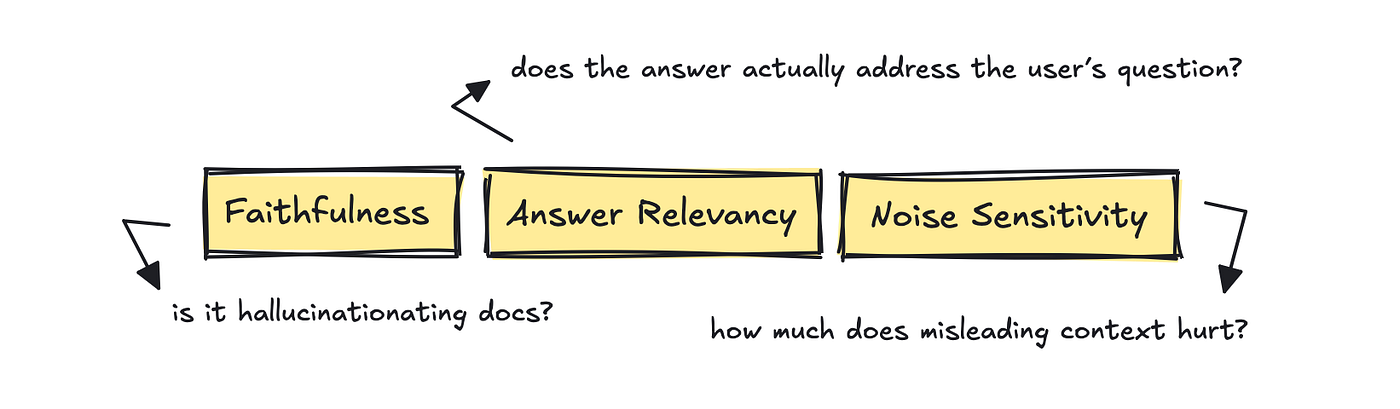
These metrics ask whether or not the reply truly addresses the consumer’s query, whether or not each declare within the reply is supported by the retrieved docs, and whether or not a little bit of irrelevant context throws the mannequin off beam.
If we have a look at RAGAS, what they doubtless do for the primary metric is ask the LLM to “Fee from 0 to 1 how instantly this reply addresses the query,” offering it with the query, reply, and retrieved context. This returns a uncooked 0–1 rating that can be utilized to compute averages.
So, to conclude we break up the system into two to judge, and though you should use strategies that depend on the IR metrics you may as well use reference free strategies that depend on an LLM to attain.
The very last thing we have to cowl is how brokers are increasing the set of metrics we now want to trace, past what we’ve already coated.
Brokers
With brokers, we’re not simply trying on the output, the dialog, and the context.
Now we’re additionally evaluating the way it “strikes”: whether or not it could actually full a job or workflow, how successfully it does so, and whether or not it calls the appropriate instruments on the proper time.
Frameworks will name these metrics otherwise, however basically the highest two you wish to monitor are Process Completion and Device Correctness.
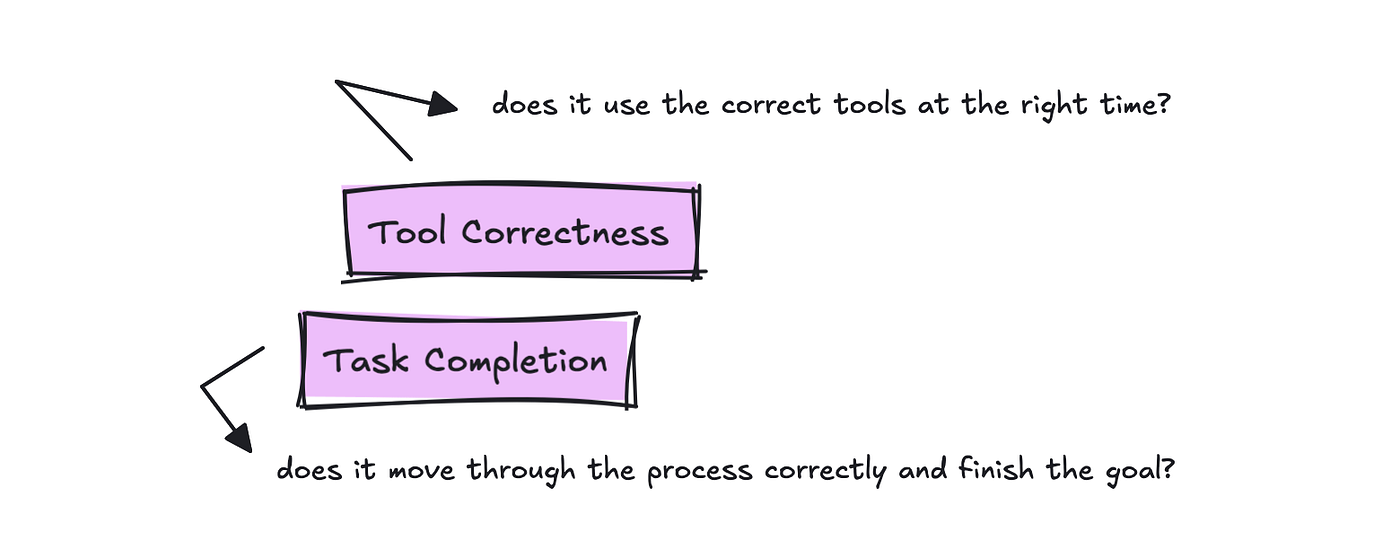
For monitoring device utilization, we wish to know if the right device was used for the consumer’s question.
We do want some sort of gold script with floor fact in-built to check every run, however you may creator that after after which use it every time you make modifications.
For Process Completion, the analysis is to learn your complete hint and the objective, and return a quantity between 0 and 1 with a rationale. This could measure how efficient the agent is at undertaking the duty.
For brokers, you’ll nonetheless want to check different issues we’ve already coated, relying in your software
I simply have to notice: even when there are fairly just a few outlined metrics out there, your use case will differ, so it’s value registering what the frequent ones are however don’t assume they’re the very best ones to trace.
Subsequent, let’s flip to get an outline of the favored frameworks on the market that may allow you to out.
Eval frameworks
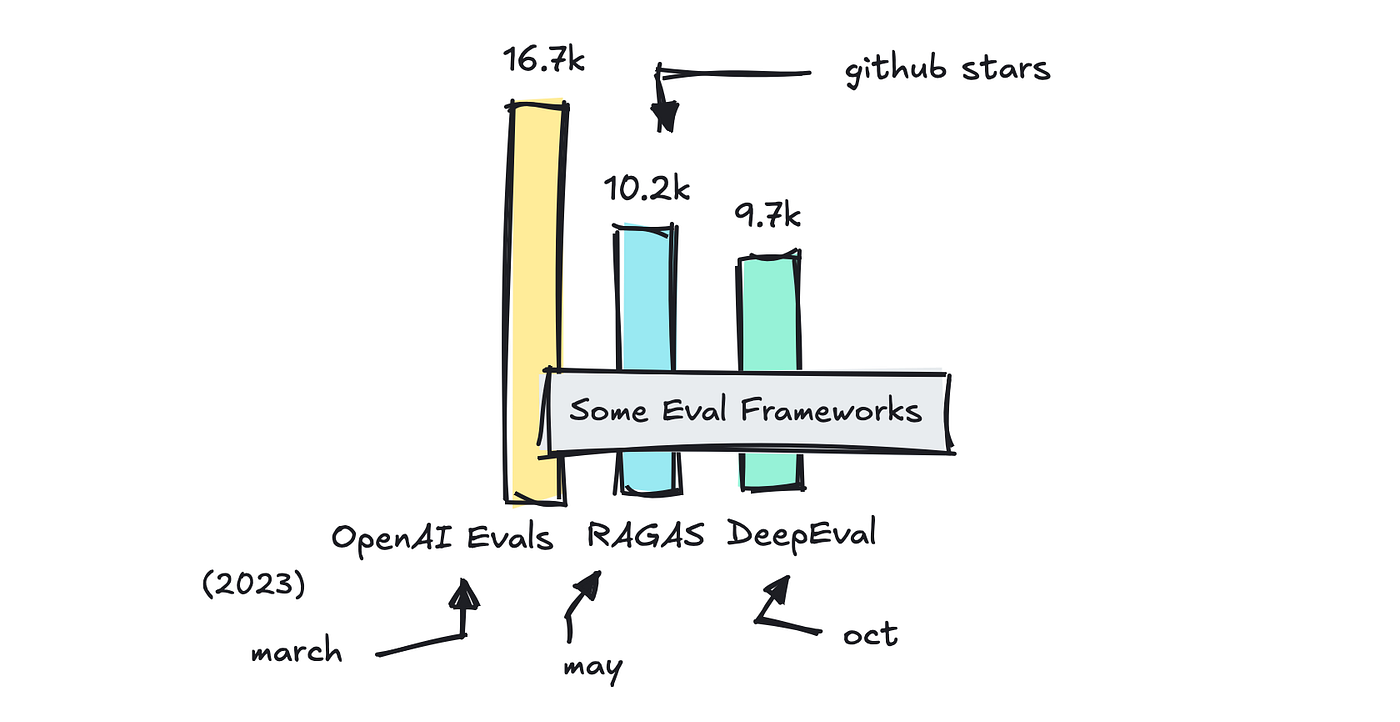
There are fairly just a few frameworks that allow you to out with evals, however I wish to speak about just a few in style ones: RAGAS, DeepEval, OpenAI’s and MLFlow’s Evals, and break down what they’re good at and when to make use of what.
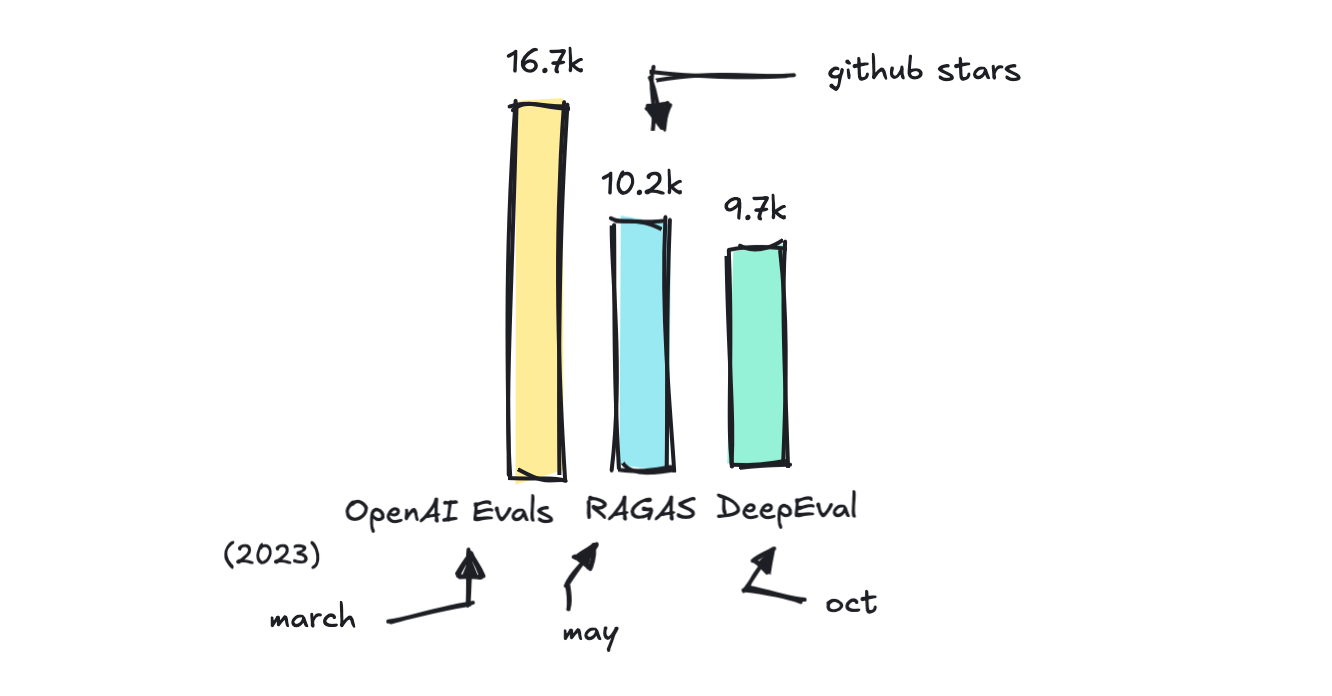
You could find the total listing of various eval frameworks I’ve present in this repository.
You may as well use fairly just a few framework-specific eval programs, corresponding to LlamaIndex, particularly for fast prototyping.
OpenAI and MLFlow’s Evals are add-ons quite than stand-alone frameworks, whereas RAGAS was primarily constructed as a metric library for evaluating RAG purposes (though they provide different metrics as effectively).
DeepEval is presumably essentially the most complete analysis library out of all of them.
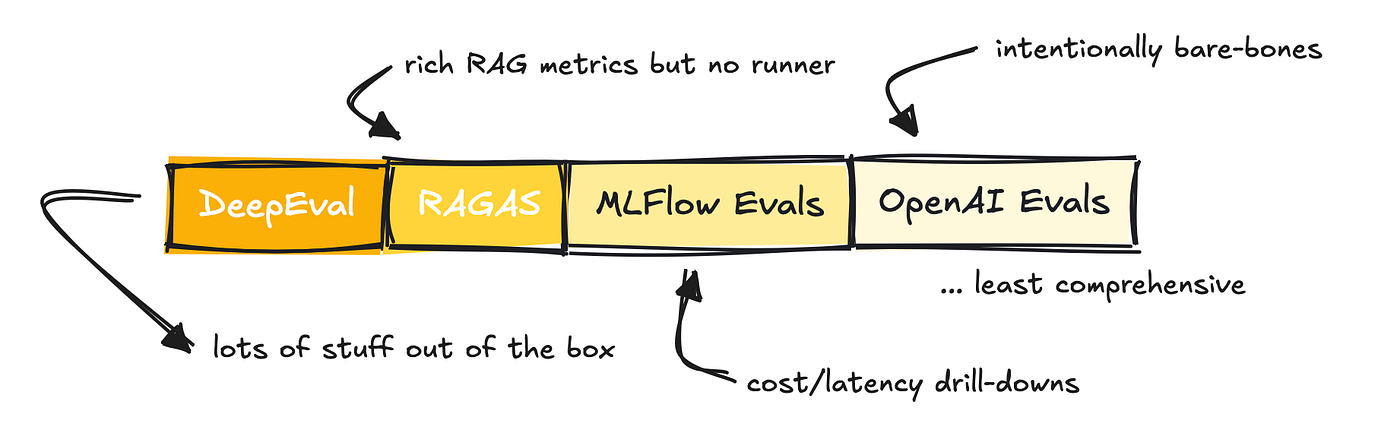
Nonetheless, it’s necessary to say that all of them supply the flexibility to run evals by yourself dataset, work for multi-turn, RAG, and brokers not directly or one other, assist LLM-as-a-judge, permit organising customized metrics, and are CI-friendly.
They differ, as talked about, in how complete they’re.
MLFlow was primarily constructed to judge conventional ML pipelines, so the variety of metrics they provide is decrease for LLM-based apps. OpenAI is a really light-weight answer that expects you to arrange your personal metrics, though they supply an instance library that will help you get began.
RAGAS gives fairly just a few metrics and integrates with LangChain so you may run them simply.
DeepEval gives rather a lot out of the field, together with the RAGAS metrics.
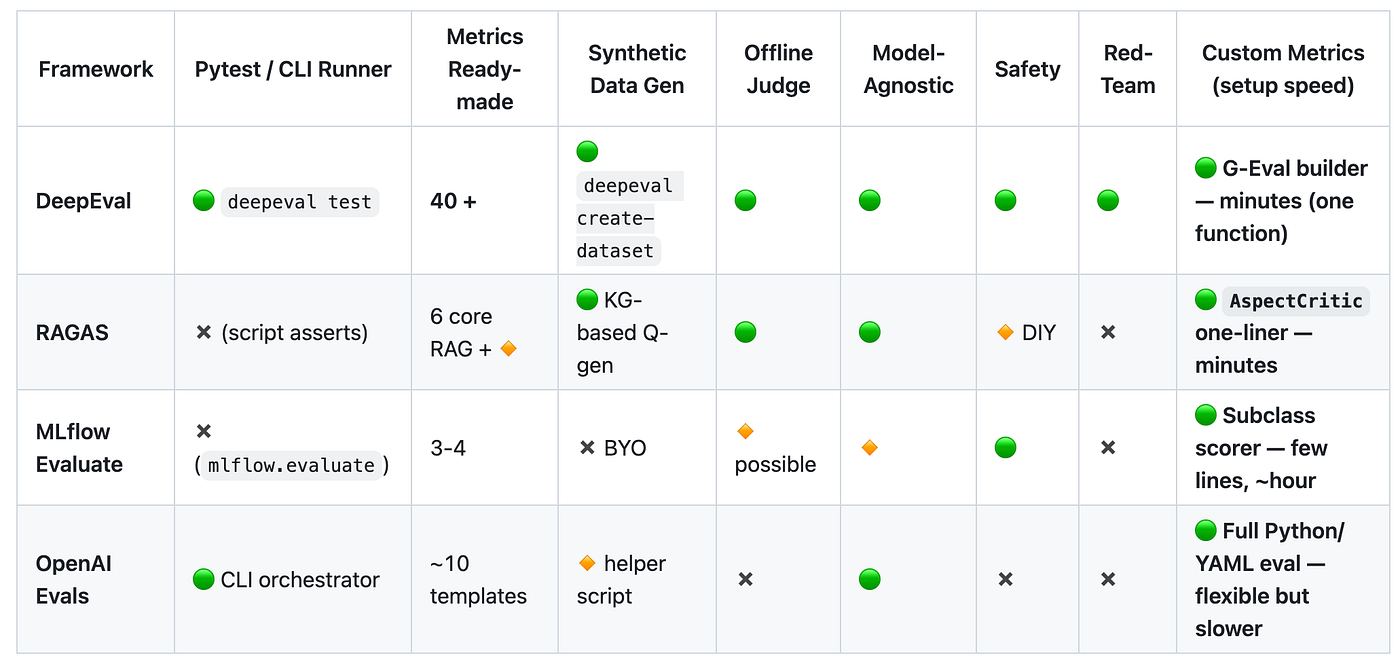
You’ll be able to see the repository with the comparisons right here.
If we have a look at the metrics being supplied, we will get a way of how in depth these options are.
It’s value noting that those providing metrics don’t all the time observe an ordinary in naming. They might imply the identical factor however name it one thing completely different.
For instance, faithfulness in a single could imply the identical as groundedness in one other. Reply relevancy often is the identical as response relevance, and so forth.
This creates numerous pointless confusion and complexity round evaluating programs typically.
Nonetheless, DeepEval stands out with over 40 metrics out there and likewise gives a framework known as G-Eval, which helps you arrange customized metrics rapidly making it the quickest manner from thought to a runnable metric.
OpenAI’s Evals framework is healthier suited once you need bespoke logic, not once you simply want a fast choose.
In response to the DeepEval staff, customized metrics are what builders arrange essentially the most, so don’t get caught on who gives what metric. Your use case shall be distinctive, and so will the way you consider it.
So, which must you use for what state of affairs?
Use RAGAS once you want specialised metrics for RAG pipelines with minimal setup. Decide DeepEval once you need a full, out-of-the-box eval suite.
MLFlow is an effective selection when you’re already invested in MLFlow or want built-in monitoring and UI options. OpenAI’s Evals framework is essentially the most barebones, so it’s greatest when you’re tied into OpenAI infrastructure and wish flexibility.
Lastly, DeepEval additionally gives crimson teaming by way of their DeepTeam framework, which automates adversarial testing of LLM programs. There are different frameworks on the market that do that too, though maybe not as extensively.
I’ll should do one thing on adversarial testing of LLM programs and immediate injections sooner or later. It’s an attention-grabbing subject.
The dataset enterprise is profitable enterprise which is why it’s nice that we’re now at this level the place we will use different LLMs to annotate knowledge, or rating assessments.
Nonetheless, LLM judges aren’t magic and the evals you’ll arrange you’ll most likely discover a bit flaky, simply as with all different LLM software you construct. In response to the world vast internet, most groups and firms sample-audit with people each few weeks to remain actual.
The metrics you arrange in your app will doubtless be customized, so despite the fact that I’ve now put you thru listening to about fairly many you’ll most likely construct one thing by yourself.
It’s good to know what the usual ones are although.
Hopefully it proved academic anyhow.
In the event you appreciated this one, you’ll want to learn a few of my different articles right here on TDS, or on Medium.
You’ll be able to observe me right here, LinkedIn or my web site if you wish to get notified once I launch one thing new.
❤


{kind=link}