Adobe Inc. excels in offering a complete suite of artistic instruments that empower artists, designers, and builders throughout numerous digital disciplines. Their product panorama is the spine of numerous artistic tasks worldwide, starting from internet design and picture modifying to vector graphics and video manufacturing.
Adobe’s inner builders use an enormous array of wiki pages, software program tips, and troubleshooting guides. Recognizing the problem builders confronted in effectively discovering the correct info for troubleshooting, software program upgrades, and extra, Adobe’s Developer Platform staff sought to construct a centralized system. This led to the initiative Unified Assist, designed to assist 1000’s of the corporate’s inner builders get instant solutions to questions from a centralized place and cut back time and value spent on developer help. As an illustration, a developer organising a steady integration and supply (CI/CD) pipeline in a brand new AWS Area or operating a pipeline on a dev department can rapidly entry Adobe-specific tips and finest practices by this centralized system.
The preliminary prototype for Adobe’s Unified Assist offered useful insights and confirmed the potential of the strategy. This early section highlighted key areas requiring additional improvement to function successfully at Adobe’s scale, together with addressing scalability wants, simplifying useful resource onboarding, enhancing content material synchronization mechanisms, and optimizing infrastructure effectivity. Constructing on these learnings, enhancing retrieval precision emerged as the subsequent vital step.
To handle these challenges, Adobe partnered with the AWS Generative AI Innovation Middle, utilizing Amazon Bedrock Information Bases and the Vector Engine for Amazon OpenSearch Serverless. This resolution dramatically improved their developer help system, leading to a 20% enhance in retrieval accuracy. Metadata filtering empowers builders to fine-tune their search, serving to them floor extra related solutions throughout complicated, multi-domain data sources. This enchancment not solely enhanced the developer expertise but in addition contributed to lowered help prices.
On this publish, we talk about the small print of this resolution and the way Adobe enhances their developer productiveness.
Answer overview
Our mission aimed to deal with two key goals:
- Doc retrieval engine enhancement – We developed a sturdy system to enhance search consequence accuracy for Adobe builders. This concerned making a pipeline for information ingestion, preprocessing, metadata extraction, and indexing in a vector database. We evaluated retrieval efficiency in opposition to Adobe’s floor reality information to supply high-quality, domain-specific outcomes.
- Scalable, automated deployment – To help Unified Assist throughout Adobe, we designed a reusable blueprint for deployment. This resolution accommodates large-scale information ingestion of varied sorts and provides versatile configurations, together with embedding mannequin choice and chunk dimension adjustment.
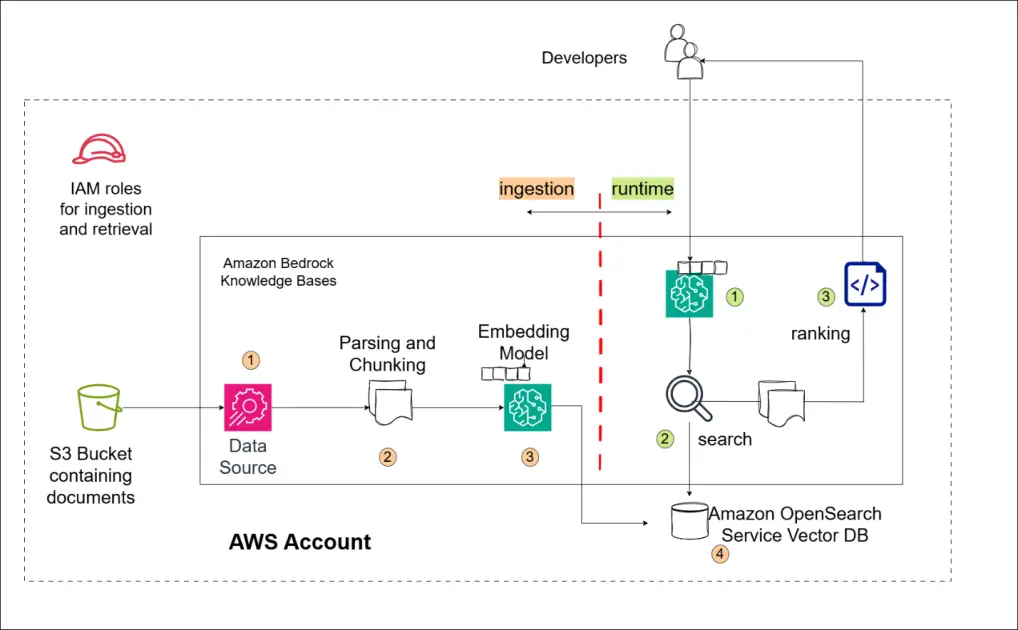
Utilizing Amazon Bedrock Information Bases, we created a custom-made, totally managed resolution that improved the retrieval effectiveness. Key achievements embrace a 20% enhance in accuracy metrics for doc retrieval, seamless doc ingestion and alter synchronization, and enhanced scalability to help 1000’s of Adobe builders. This resolution gives a basis for improved developer help and scalable deployment throughout Adobe’s groups. The next diagram illustrates the answer structure.

Let’s take a better have a look at our resolution:
- Amazon Bedrock Information Bases index – The spine of our system is Amazon Bedrock Information Bases. Information is listed by the next levels:
- Information ingestion – We begin by pulling information from Amazon Easy Storage Service (Amazon S3) buckets. This might be something from resolutions to previous points or wiki pages.
- Chunking – Amazon Bedrock Information Bases breaks information down into smaller items, or chunks, defining the precise models of knowledge that may be retrieved. This chunking course of is configurable, permitting for optimization primarily based on the precise wants of the enterprise.
- Vectorization – Every chunk is handed by an embedding mannequin (on this case, Amazon Titan V2 on Amazon Bedrock) making a 1,024-dimension numerical vector. This vector represents the semantic which means of the chunk, permitting for similarity searches
- Storage – These vectors are saved within the Amazon OpenSearch Serverless vector database, making a searchable repository of knowledge.
- Runtime – When a consumer poses a query, our system competes the next steps:
- Question vectorization – With the Amazon Bedrock Information Bases Retrieve API, the consumer’s query is robotically embedded utilizing the identical embedding mannequin used for the chunks throughout information ingestion.
- Similarity search and retrieval – The system retrieves probably the most related chunks within the vector database primarily based on similarity scores to the question.
- Rating and presentation – The corresponding paperwork are ranked primarily based on the sematic similarity of their modest related chunks to the question, and the top-ranked info is offered to the consumer.
Multi-tenancy by metadata filtering
As builders, we regularly discover ourselves looking for assist throughout numerous domains. Whether or not it’s tackling CI/CD points, organising mission environments, or adopting new libraries, the panorama of developer challenges is huge and different. Typically, our questions even span a number of domains, making it essential to have a system for retrieving related info. Metadata filtering empowers builders to retrieve not simply semantically related info, however a well-defined subset of that info primarily based on particular standards. This highly effective software allows you to apply filters to your retrievals, serving to builders slim the search outcomes to a restricted set of paperwork primarily based on the filter, thereby enhancing the relevancy of the search.
To make use of this function, metadata information are offered alongside the supply information information in an S3 bucket. To allow metadata-based filtering, every supply information file must be accompanied by a corresponding metadata file. These metadata information used the identical base identify because the supply file, with a .metadata.json suffix. Every metadata file included related attributes—akin to area, 12 months, or sort—to help multi-tenancy and fine-grained filtering in OpenSearch Service. The next code reveals what an instance metadata file seems to be like:
Retrieve API
The Retrieve API permits querying a data base to retrieve related info. You need to use it as follows:
- Ship a POST request to
/knowledgebases/knowledgeBaseId/retrieve. - Embrace a JSON physique with the next:
- retrievalQuery – Incorporates the textual content question.
- retrievalConfiguration – Specifies search parameters, akin to variety of outcomes and filters.
- nextToken – For pagination (elective).
The next is an instance request syntax:
Moreover, you’ll be able to arrange the retriever with ease utilizing the langchain-aws package deal:
This strategy allows semantic querying of the data base to retrieve related paperwork primarily based on the offered question, simplifying the implementation of search.
Experimentation
To ship probably the most correct and environment friendly data retrieval system, the Adobe and AWS groups put the answer to the check. The staff performed a collection of rigorous experiments to fine-tune the system and discover the optimum settings.
Earlier than we dive into our findings, let’s talk about the metrics and analysis course of we used to measure success. We used the open supply mannequin analysis framework Ragas to guage the retrieval system throughout two metrics: doc relevance and imply reciprocal rank (MRR). Though Ragas comes with many metrics for evaluating mannequin efficiency out of the field, we would have liked to implement these metrics by extending the Ragas framework with customized code.
- Doc relevance – Doc relevance provides a qualitative strategy to assessing retrieval accuracy. This metric makes use of a big language mannequin (LLM) as an neutral choose to match retrieved chunks in opposition to consumer queries. It evaluates how successfully the retrieved info addresses the developer’s query, offering a rating between 1–10.
- Imply reciprocal rank – On the quantitative facet, we now have the MRR metric. MRR evaluates how effectively a system ranks the primary related merchandise for a question. For every question, discover the rank ok of the highest-ranked related doc. The rating for that question is 1/ok. MRR is the common of those 1/ok scores over your entire set of queries. The next rating (nearer to 1) signifies that the primary related result’s sometimes ranked excessive.
These metrics present complementary insights: doc relevance provides a content-based evaluation, and MRR gives a ranking-based analysis. Collectively, they provide a complete view of the retrieval system’s effectiveness to find and prioritizing related info.In our latest experiments, we explored numerous information chunking methods to optimize the efficiency of retrieval. We examined a number of approaches, together with fixed-size chunking in addition to extra superior semantic chunking and hierarchical chunking.Semantic chunking focuses on preserving the contextual relationships inside the information by segmenting it primarily based on semantic which means. This strategy goals to enhance the relevance and coherence of retrieved outcomes.Hierarchical chunking organizes information right into a hierarchical parent-child construction, permitting for extra granular and environment friendly retrieval primarily based on the inherent relationships inside your information.
For extra info on the right way to arrange totally different chunking methods, confer with Amazon Bedrock Information Bases now helps superior parsing, chunking, and question reformulation giving larger management of accuracy in RAG primarily based functions.
We examined the next chunking strategies with Amazon Bedrock Information Bases:
- Fastened-size quick chunking – 400-token chunks with a 20% overlap (proven because the blue variant within the following determine)
- Fastened-size lengthy chunking – 1,000-token chunks with a 20% overlap
- Hierarchical chunking – Mum or dad chunks of 1,500 tokens and baby chunks of 300 tokens, with a 60-token overlap
- Semantic chunking – 400-token chunks with a 95% similarity percentile threshold
For reference, a paragraph of roughly 1,000 characters sometimes interprets to round 200 tokens. To evaluate efficiency, we measured doc relevance and MRR throughout totally different context sizes, starting from 1–5. This comparability goals to supply insights into the best chunking technique for organizing and retrieving info for this use case.The next figures illustrate the MRR and doc relevance metrics, respectively.


Because of these experiments, we discovered that MRR is a extra delicate metric for evaluating the influence of chunking methods, notably when various the variety of retrieved chunks (top-k from 1 to five). Among the many approaches examined, the fixed-size 400-token technique—proven in blue—proved to be the only and only, persistently yielding the best accuracy throughout totally different retrieval sizes.
Conclusion
Within the journey to design Adobe’s developer Unified Assist search and retrieval system, we’ve efficiently harnessed the ability of Amazon Bedrock Information Bases to create a sturdy, scalable, and environment friendly resolution. By configuring fixed-size chunking and utilizing the Amazon Titan V2 embedding mannequin, we achieved a outstanding 20% enhance in accuracy metrics for doc retrieval in comparison with Adobe’s current resolution, by operating evaluations on the shopper’s testing system and offered dataset.The mixing of metadata filtering emerged as a recreation altering function, permitting for seamless navigation throughout numerous domains and enabling custom-made retrieval. This functionality proved invaluable for Adobe, given the complexity and breadth of their info panorama. Our complete comparability of retrieval accuracy for various configurations of the Amazon Bedrock Information Bases index has yielded useful insights. The metrics we developed present an goal framework for assessing the standard of retrieved context, which is essential for functions demanding high-precision info retrieval. As we glance to the long run, this custom-made, totally managed resolution lays a strong basis for steady enchancment in developer help at Adobe, providing enhanced scalability and seamless help infrastructure in tandem with evolving developer wants.
For these all for working with AWS on comparable tasks, go to Generative AI Innovation Middle. To be taught extra about Amazon Bedrock Information Bases, see Retrieve information and generate AI responses with data bases.
In regards to the Authors
 Kamran Razi is a Information Scientist on the Amazon Generative AI Innovation Middle. With a ardour for delivering cutting-edge generative AI options, Kamran helps prospects unlock the total potential of AWS AI/ML providers to resolve real-world enterprise challenges. With over a decade of expertise in software program improvement, he focuses on constructing AI-driven options, together with AI brokers. Kamran holds a PhD in Electrical Engineering from Queen’s College.
Kamran Razi is a Information Scientist on the Amazon Generative AI Innovation Middle. With a ardour for delivering cutting-edge generative AI options, Kamran helps prospects unlock the total potential of AWS AI/ML providers to resolve real-world enterprise challenges. With over a decade of expertise in software program improvement, he focuses on constructing AI-driven options, together with AI brokers. Kamran holds a PhD in Electrical Engineering from Queen’s College.
 Nay Doummar is an Engineering Supervisor on the Unified Assist staff at Adobe, the place she’s been since 2012. Over time, she has contributed to tasks in infrastructure, CI/CD, identification administration, containers, and AI. She began on the CloudOps staff, which was liable for migrating Adobe’s infrastructure to the AWS Cloud, marking the start of her long-term collaboration with AWS. In 2020, she helped construct a help chatbot to simplify infrastructure-related help, sparking her ardour for consumer help. In 2024, she joined a mission to Unify Assist for the Developer Platform, aiming to streamline help and enhance productiveness.
Nay Doummar is an Engineering Supervisor on the Unified Assist staff at Adobe, the place she’s been since 2012. Over time, she has contributed to tasks in infrastructure, CI/CD, identification administration, containers, and AI. She began on the CloudOps staff, which was liable for migrating Adobe’s infrastructure to the AWS Cloud, marking the start of her long-term collaboration with AWS. In 2020, she helped construct a help chatbot to simplify infrastructure-related help, sparking her ardour for consumer help. In 2024, she joined a mission to Unify Assist for the Developer Platform, aiming to streamline help and enhance productiveness.
 Varsha Chandan Bellara is a Software program Improvement Engineer at Adobe, specializing in AI-driven options to spice up developer productiveness. She leads the event of an AI assistant for the Unified Assist initiative, utilizing Amazon Bedrock, implementing RAG to supply correct, context-aware responses for technical help and challenge decision. With experience in cloud-based applied sciences, Varsha combines her ardour for containers and serverless architectures with superior AI to create scalable, environment friendly options that streamline developer workflows.
Varsha Chandan Bellara is a Software program Improvement Engineer at Adobe, specializing in AI-driven options to spice up developer productiveness. She leads the event of an AI assistant for the Unified Assist initiative, utilizing Amazon Bedrock, implementing RAG to supply correct, context-aware responses for technical help and challenge decision. With experience in cloud-based applied sciences, Varsha combines her ardour for containers and serverless architectures with superior AI to create scalable, environment friendly options that streamline developer workflows.
 Jan Michael Ong is a Senior Software program Engineer at Adobe, the place he helps the developer neighborhood and engineering groups by tooling and automation. At the moment, he’s a part of the Developer Expertise staff at Adobe, engaged on AI tasks and automation contributing to Adobe’s inner Developer Platform.
Jan Michael Ong is a Senior Software program Engineer at Adobe, the place he helps the developer neighborhood and engineering groups by tooling and automation. At the moment, he’s a part of the Developer Expertise staff at Adobe, engaged on AI tasks and automation contributing to Adobe’s inner Developer Platform.
 Justin Johns is a Deep Studying Architect at Amazon Internet Providers who’s enthusiastic about innovating with generative AI and delivering cutting-edge options for patrons. With over 5 years of software program improvement expertise, he focuses on constructing cloud-based options powered by generative AI.
Justin Johns is a Deep Studying Architect at Amazon Internet Providers who’s enthusiastic about innovating with generative AI and delivering cutting-edge options for patrons. With over 5 years of software program improvement expertise, he focuses on constructing cloud-based options powered by generative AI.
 Gaurav Dhamija is a Principal Options Architect at Amazon Internet Providers, the place he helps prospects design and construct scalable, dependable, and safe functions on AWS. He’s enthusiastic about developer expertise, containers, and serverless applied sciences, and works intently with engineering groups to modernize software architectures. Gaurav additionally focuses on generative AI, utilizing AWS generative AI providers to drive innovation and improve productiveness throughout a variety of use instances.
Gaurav Dhamija is a Principal Options Architect at Amazon Internet Providers, the place he helps prospects design and construct scalable, dependable, and safe functions on AWS. He’s enthusiastic about developer expertise, containers, and serverless applied sciences, and works intently with engineering groups to modernize software architectures. Gaurav additionally focuses on generative AI, utilizing AWS generative AI providers to drive innovation and improve productiveness throughout a variety of use instances.
 Sandeep Singh is a Senior Generative AI Information Scientist at Amazon Internet Providers, serving to companies innovate with generative AI. He focuses on generative AI, machine studying, and system design. He has efficiently delivered state-of-the-art AI/ML-powered options to resolve complicated enterprise issues for numerous industries, optimizing effectivity and scalability.
Sandeep Singh is a Senior Generative AI Information Scientist at Amazon Internet Providers, serving to companies innovate with generative AI. He focuses on generative AI, machine studying, and system design. He has efficiently delivered state-of-the-art AI/ML-powered options to resolve complicated enterprise issues for numerous industries, optimizing effectivity and scalability.
 Anila Joshi has greater than a decade of expertise constructing AI options. As a Senior Supervisor, Utilized Science at AWS Generative AI Innovation Middle, Anila pioneers revolutionary functions of AI that push the boundaries of risk and speed up the adoption of AWS providers with prospects by serving to prospects ideate, determine, and implement safe generative AI options.
Anila Joshi has greater than a decade of expertise constructing AI options. As a Senior Supervisor, Utilized Science at AWS Generative AI Innovation Middle, Anila pioneers revolutionary functions of AI that push the boundaries of risk and speed up the adoption of AWS providers with prospects by serving to prospects ideate, determine, and implement safe generative AI options.



{kind=link}