individuals! In case you have ever wished to grasp how linear regression works or simply refresh the primary concepts with out leaping between a lot of totally different sources – this text is for you. It’s an additional lengthy learn that took me greater than a yr to put in writing. It’s constructed round 5 key concepts:
- Visuals first. This can be a comic-style article: studying the textual content helps, however it’s not required. A fast run via the pictures and animations can nonetheless offer you a stable understanding of how issues work. There are 100+ visuals in complete;
- Animations the place they may assist (33 complete). Laptop science is greatest understood in movement, so I exploit animations to clarify key concepts;
- Newbie-friendly. I stored the fabric so simple as potential, to make the article straightforward for freshmen to observe.
- Reproducible. Most visuals have been generated in Python, and the code is open supply.
- Deal with follow. Every subsequent step solves an issue that reveals up within the earlier step, so the entire article stays linked.
Another factor: the submit is simplified on function, so some wording and examples could also be a bit tough or not completely exact. Please don’t simply take my phrase for it – assume critically and double-check my factors. For crucial elements, I present hyperlinks to the supply code so you possibly can confirm every part your self.
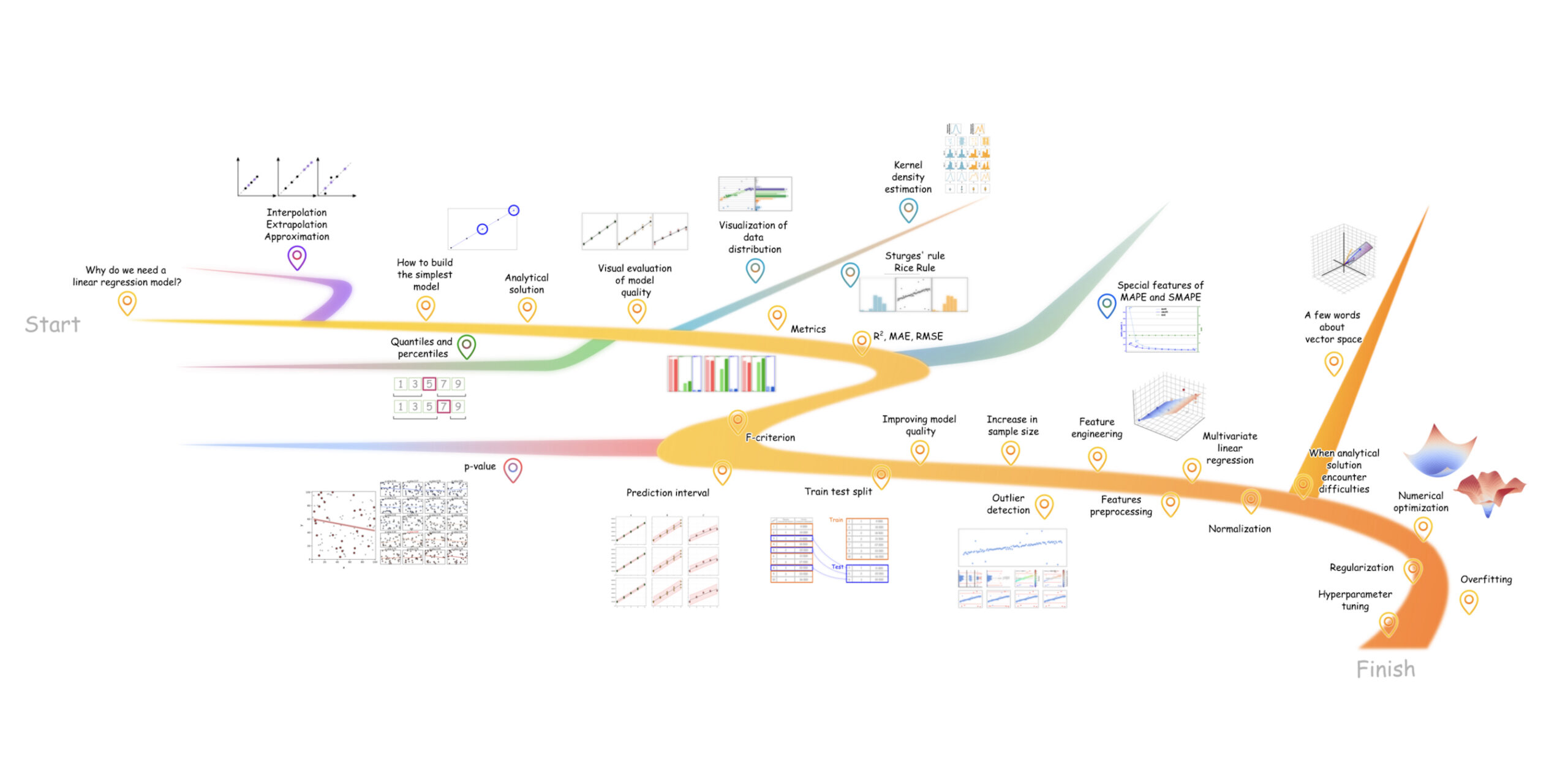
Desk of contents
Who’s this text for
Skip this paragraph, simply scroll via the article for 2 minutes and have a look at the visuals. You’ll instantly know if you wish to learn it correctly (the primary concepts are proven within the plots and animations). This submit is for freshmen and for anybody working with information – and likewise for skilled individuals who need a fast refresh.
What this submit covers
The article is structured in three acts:
- Linear regression: what it’s, why we use it, and how you can match a mannequin;
- Learn how to consider the mannequin’s efficiency;
- Learn how to enhance the mannequin when the outcomes are usually not adequate.
At a excessive stage, this text covers:
- data-driven modeling;
- analytical resolution for linear regression, and why it’s not all the time sensible;
- methods to guage mannequin high quality, each visually and with metrics;
- A number of linear regression, the place predictions are based mostly on many options;
- the probabilistic aspect of linear regression, since predictions are usually not precise and it is very important quantify uncertainty;
- methods to enhance mannequin high quality, from including complexity to simplifying the mannequin with regularization.
Extra particularly, it walks via:
- the least squares methodology for easy linear regression;
- regression metrics equivalent to R², RMSE, MAE, MAPE, SMAPE, together with the Pearson correlation coefficient and the coefficient of dedication, plus visible diagnostics like residual plots;
- most chance and prediction intervals;
- prepare/take a look at splits, why they matter and how you can do them;
- outlier dealing with strategies, together with RANSAC, Mahalanobis distance, Native Outlier Issue (LOF), and Cook dinner’s distance;
- information preprocessing, together with normalization, standardization, and categorical encoding;
- the linear algebra behind least squares, and the way it extends to multivariate regression;
- numerical optimization strategies, together with gradient descent;
- L1 and L2 regularization for linear fashions;
- cross-validation and hyperparameter optimization.
Though this text focuses on linear regression, some elements – particularly the part on mannequin analysis, apply to different regression algorithms as effectively. The identical goes for the characteristic preprocessing chapters.
Since that is meant as an introductory, ML-related information to linear regression, I’ll principally keep away from vector notation (the place formulation use vectors as an alternative of scalars). In different phrases, you’ll hardly see vectors and matrices within the equations, besides in just a few locations the place they’re really crucial. Needless to say many of the formulation proven right here do have a vector kind, and fashionable libraries implement the algorithms in precisely that means. These implementations are environment friendly and dependable, so should you resolve to code issues up, don’t reinvent the wheel – use well-tested libraries or instruments with UI when it is sensible.
All animations and pictures within the article are unique and created by the writer.
A quick literary evaluate
This matter isn’t new, so there’s loads of materials on the market. Beneath is a brief checklist of direct predecessors, comparable in platform (principally In the direction of Information Science) and viewers, that means browser-first readers fairly than textbook readers. The checklist is ordered by rising subjective complexity:
- What’s Linear Regression? – A beginner-friendly overview of what linear regression is, what the road represents, how predictions are made, with easy visuals and code;
- A Sensible Information to Linear Regression – Represents linear mannequin becoming as machine studying pipeline: EDA, characteristic dealing with, mannequin becoming, and analysis on an actual Kaggle dataset;
- Mastering the Fundamentals: How Linear Regression Unlocks the Secrets and techniques of Advanced Fashions – Straightforward to observe information with step-by-step calculations memorable and good visuals;
- Predict Housing Worth utilizing Linear Regression in Python – implementation-oriented article constructed across the Boston Housing dataset, with code examples for calculations from scratch;
- A number of Linear Regression Evaluation – An article with extra mathematical element, centered on multicollinearity;
- Mastering Linear Regression: The Definitive Information For Aspiring Information Scientists – A protracted, multi function information, concept plus Python;
- Linear Regression In Depth (Half 1) and Linear Regression In Depth (Half 2) – Deeper concept plus implementation articles that focuses on easy linear regression and units up the transition to a number of regression;
And naturally, don’t ignore the basic papers if you wish to learn extra about this matter. I’m not itemizing them as a separate bibliography on this part, however you’ll discover hyperlinks to them later within the textual content. Every reference seems proper after the fragment it pertains to, in sq. brackets, within the format: [Author(s). Title. Year. Link to the original source]
A superb mannequin begins with information
Let’s assume we’ve got tabular information with two columns:
- Variety of rooms within the house;
- The value of the house, $

By the point you construct a mannequin, there ought to already be information. Information assortment and the preliminary preparation of the dataset are exterior the scope of this text, particularly for the reason that course of can differ rather a lot relying on the area. The primary precept to bear in mind is “rubbish in, rubbish out,” which applies to supervised machine studying usually. A superb mannequin begins with a very good dataset.
Disclaimer relating to the dataset: The info used on this article is artificial and was generated by the writer. It’s distributed underneath the identical license because the supply code – BSD 3-Clause.
Why do we want a mannequin?
Because the British statistician George Field as soon as mentioned, “All fashions are improper, however some are helpful.” Fashions are helpful as a result of they assist us uncover patterns in information. As soon as these patterns are expressed as a mathematical relationship (a mannequin), we will use it, for instance, to generate predictions (Determine 2).

Modeling relationships in information shouldn’t be a trivial activity. It may be completed utilizing mathematical fashions of many various sorts – from easy ones to fashionable multi-stage approaches equivalent to neural networks. For now, the important thing level is {that a} “mannequin” can imply any type of mapping from one set of information (characteristic columns) to a goal column. I’ll use this definition all through the article.

In linear regression, we mannequin linear relationships between information variables. In pair (one-feature) regression – when there may be one characteristic and one dependent variable – the equation has the shape:
, the place – characteristic, – goal variable [James, G., et al. Linear Regression. An Introduction to Statistical Learning, 2021. Free version https://www.statlearning.com/].
So the expression is a linear regression mannequin. And is one as effectively – the one distinction is the coefficients. For the reason that coefficients are the important thing parameters of the equation, they’ve their very own names:
- b0 – the intercept (additionally known as the bias time period)
- b1 – the slope coefficient
So, after we construct a linear regression mannequin, we make the next assumption:
Assumption 1. The connection between the options (impartial variables) and the response (dependent variable) is linear [Kim, Hae-Young. Statistical notes for clinical researchers: simple linear regression 1 – basic concepts, 2018. https://www.rde.ac/upload/pdf/rde-43-e21.pdf]
An instance of a linear mannequin with the intercept and slope coefficients already fitted (we are going to talk about why they’re known as {that a} bit later) is proven in Determine 4.

For the dataset proven in Determine 1, estimating the house value in {dollars} means multiplying the variety of rooms by 10 000.
Necessary observe: we’re specializing in an approximation – so the mannequin line doesn’t must cross via each information level, as a result of real-world information nearly by no means falls precisely on a single straight line. There may be all the time some noise, and a few components the mannequin doesn’t see. It’s sufficient for the mannequin line to remain as near the noticed information as potential. If you don’t keep in mind effectively the distinction between approximation, interpolation and extrapolation, please test the picture beneath.
Aspect department 1. Distinction between approximation, interpolation and extrapolation

Learn how to construct a easy mannequin
We have to select the coefficients and within the equation beneath in order that the straight line suits the empirical observations (the actual information) as carefully as potential: , the place – variety of rooms, – house value, $.
Why this equation, and why two coefficients
Regardless of its obvious simplicity, the linear regression equation can signify many various linear relationships, as proven in Determine 5. For every dataset, a unique line can be optimum.

Analytical resolution
To search out the optimum coefficient values, we are going to use an analytical resolution: plug the empirical information from the earlier part into a well known components derived way back (by Carl Gauss and Adrien-Marie Legendre). The analytical resolution could be written as 4 easy steps (Determine 6) [Hastie, T., et al. Linear Methods for Regression (Chapter 3 in The Elements of Statistical Learning: Data Mining, Inference, and Prediction). 2009. https://hastie.su.domains/ElemStatLearn].

Error can be a part of the mannequin
Earlier, I famous that linear regression is an approximation algorithm. This implies we don’t require the road to cross precisely via the observations. In different phrases, even at this stage we enable the mannequin’s predictions to vary from the noticed house costs. And it is very important emphasize: this type of mismatch is totally regular. In the actual world, it is vitally laborious to discover a course of that generates information mendacity completely on a straight line (Determine 7).

So, the mannequin wants yet one more element to be life like: an error time period. With actual information, error evaluation is important – it helps spot issues and repair them early. Most significantly, it gives a approach to quantify how good the mannequin actually is.
Learn how to measure mannequin high quality
Mannequin high quality could be assessed utilizing two major approaches:
- Visible analysis
- Metric-based analysis
Earlier than we dive into each, it’s a good second to outline what we imply by “high quality” right here. On this article, we are going to contemplate a mannequin a very good one when the error time period is as small as potential.
Utilizing the unique dataset (see Determine 1), totally different coefficient values could be plugged into the linear regression equation. Predictions are then generated for the identified examples, and the distinction between predicted and precise values is in contrast (Desk 1). Amongst all mixtures of the intercept and slope, one pair yields the smallest error.
| Variety of rooms | Mannequin (b0 + b1 x rooms quantity) | Prediction | Floor reality (commentary) | Error (commentary – predicted) |
| 2 | 20 000 | 20 000 | 0 | |
| 2 | 10 000 | 20 000 | 10 000 | |
| 2 | 2 500 | 20 000 | 17 500 |
The desk instance above is straightforward to observe as a result of it’s a small, toy setup. It solely reveals how totally different fashions predict the worth of a two-room house, and within the unique dataset every “variety of rooms” worth maps to a single value. As soon as the dataset will get bigger, this type of handbook comparability turns into impractical. That’s why mannequin high quality is often assessed with analysis instruments (visuals, metrics and statistical checks) fairly than hand-made tables.
To make issues a bit extra life like, the dataset can be expanded in three variations: one straightforward case and two which can be tougher to suit. The identical analysis will then be utilized to those datasets.

Determine 8 is nearer to actual life: flats differ, and even when the variety of rooms are the identical, the worth throughout totally different properties doesn’t must be an identical.
Visible analysis
Utilizing the components from the Analytic Answer part (Determine 6), the information could be plugged in to acquire the next fashions for every dataset:
- A: , the place x is rooms quantity
- B: , the place x is rooms quantity
- C: , the place x is rooms quantity
A helpful first plot to indicate right here is the scatter plot: the characteristic values are positioned on the x-axis, whereas the y-axis reveals each the expected values and the precise observations, in several colours. This sort of determine is simple to interpret – the nearer the mannequin line is to the actual information, the higher the mannequin. It additionally makes the connection between the variables simpler to see, for the reason that characteristic itself is proven on the plot [Piñeiro, G., et al. How to evaluate models: Observed vs. predicted or predicted vs. observed? 2008. https://doi.org/10.1016/j.ecolmodel.2008.05.006].

One draw back of this plot is that it turns into laborious to introduce extra options after you have a couple of or two – for instance, when value relies upon not solely on the variety of rooms, but in addition on the space to the closest metro station, the ground stage, and so forth. One other concern is scale: the goal vary can strongly form the visible impression. Tiny variations on the chart, barely seen to the attention, should correspond to errors of a number of thousand {dollars}. Worth prediction is a good instance right here, as a result of a deceptive visible impression of mannequin errors can translate immediately into cash.
When the variety of options grows, visualizing the mannequin immediately (characteristic vs. goal with a fitted line) shortly turns into messy. A cleaner various is an noticed vs. predicted scatter plot. It’s constructed like this: the x-axis reveals the precise values, and the y-axis reveals the expected values (Determine 10) [Moriasi, D. N., et al. Hydrologic and Water Quality Models: Performance Measures and Evaluation Criteria. 2015. pdf link]. I’ve additionally seen the axes swapped, with predicted values on the x-axis as an alternative. Both means, the plot serves the identical function – so be happy to decide on whichever conference you like.

This plot is learn as follows: the nearer the factors are to the diagonal line coming from the bottom-left nook, the higher. If the mannequin reproduced the observations completely, each level would sit precisely on that line with none deviation (dataset A seems fairly near this best case).
When datasets are massive, or the construction is uneven (for instance, when there are outliers), Q-Q plots could be useful. They present the identical predicted and noticed values on the identical axes, however after a particular transformation.
Q-Q plot Possibility 1, – order statistics. Predicted values are sorted in ascending order, and the identical is completed for the noticed values. The 2 sorted arrays are then plotted towards one another, identical to in Determine 10.
Q-Q plot Possibility 2, – two-sample Q-Q plot. Right here the plot makes use of quantiles fairly than uncooked sorted values. The info are grouped right into a finite variety of ranges (I often use round 100). This plot is helpful when the aim is to check the general sample, not particular person “prediction vs. commentary” pairs. It helps to see the form of the distributions, the place the median sits, and the way frequent very massive or very small values are.
Aspect department 2. Reminder about quantiles
In response to Wikipedia, a quantile is a price {that a} given random variable doesn’t exceed with a set likelihood.
Setting the likelihood wording apart for a second, a quantile could be considered a price that splits a dataset into elements. For instance, the 0.25 quantile is the quantity beneath which 25% of the pattern lies. And the 0.9 quantile is the worth beneath which 90% of the information lies.
For the pattern [ 1 , 3 , 5 , 7 , 9 ] the 0.5 quantile (the median) is 5. There are solely two values above 5 (7 and 9), and solely two beneath it (1 and three).
The 0.25 quantile is roughly 3, and the 0.75 quantile is roughly 7. See the reason within the determine beneath.

The 25th percentile can be known as the primary quartile, the 50th percentile is the median or second quartile, and the 75th percentile is the third quartile.

Within the second variant, regardless of how massive the dataset is, this plot all the time reveals 99 factors, so it scales effectively to massive samples. In Determine 11, the actual and predicted quantiles for dataset A lie near the diagonal line which signifies a very good mannequin. For dataset B, the fitting tail of the distributions (upper-right nook) begins to diverge, that means the mannequin performs worse on high-priced flats.
For dataset C:
- Beneath the 25th percentile, the expected quantiles lie above the noticed ones;
- Throughout the interquartile vary (from the 25th to the 75th percentile), the expected quantiles lie beneath the noticed ones;
- Above the 75th percentile, the expected tail once more lies above the noticed one.
One other extensively used diagnostic is the residual plot. The x-axis reveals the expected values, and the y-axis reveals the residuals. Residuals are the distinction between the noticed and predicted values. For those who desire, you possibly can outline the error with the other signal (predicted minus noticed) and plot that as an alternative. It doesn’t change the concept – solely the course of the values on the y-axis.

A residual plot is likely one of the most handy instruments for checking the important thing assumptions behind linear regression (Assumption 1 (linearity) was launched earlier):
- Assumption 2. Normality of residuals. The residuals (noticed minus predicted) ought to be roughly usually distributed. Intuitively, most residuals ought to be small and near zero, whereas massive residuals are uncommon. Residuals happen roughly equally usually within the constructive and unfavourable course.
- Assumption 3. Homoscedasticity (fixed variance). The mannequin ought to have errors of roughly the identical magnitude throughout the complete vary: low cost flats, mid-range ones, and costly ones.
- Assumption 4. Independence. Observations (and their residuals) ought to be impartial of one another – i.e., there ought to be no autocorrelation.
Determine 12 reveals that dataset B violates Assumption 3: because the variety of rooms will increase, the errors get bigger – the residuals fan out from left to proper, indicating rising variance. In different phrases, the error shouldn’t be fixed and is determined by the characteristic worth. This often means the mannequin is lacking some underlying sample, which makes its predictions much less dependable in that area.
For dataset C, the residuals don’t look regular: the mannequin typically systematically overestimates and typically systematically underestimates, so the residuals drift above and beneath zero in a structured means fairly than hovering round it randomly. On prime of that, the residual plot reveals seen patterns, which could be a signal that the errors are usually not impartial (to be honest, not all the time XD however both means it’s a sign that one thing is off with the mannequin).
A pleasant companion to Determine 12 is a set of residual distribution plots (Determine 13). These make the form of the residuals instantly seen: even with out formal statistical checks, you possibly can eyeball how symmetric the distribution is (a very good signal is symmetry round zero) and the way heavy its tails are. Ideally, the distribution ought to look bell-shaped, most residuals ought to be small, whereas massive errors ought to be uncommon.

Aspect department 3. A fast reminder about frequency distributions
In case your stats course has light from reminiscence otherwise you by no means took one this half is value a more in-depth look. This part introduces the most typical methods to visualise samples in mathematical statistics. After it, decoding the plots used later within the article ought to be simple.
Frequency distribution is an ordered illustration displaying what number of occasions the values of a random variable fall inside sure intervals.
To construct one:
- Break up the complete vary of values into okay bins (class intervals)
- Rely what number of observations fall into every bin – this is absolutely the frequency
- Divide absolutely the frequency by the pattern dimension n to get the relative frequency
Within the determine beneath, the identical steps are proven for the variable V:

The identical type of visualization could be constructed for variable U as effectively, however on this part the main target stays on V for simplicity. In a while, the histogram can be rotated sideways to make it simpler to check the uncooked information with the vertical format generally used for distribution plots.
From the algorithm description and from the determine above, one vital downside turns into clear: the variety of bins okay (and subsequently the bin width) has a serious influence on how the distribution seems.

There are empirical formulation that assist select an inexpensive variety of bins based mostly on the pattern dimension. Two frequent examples are Sturges’ rule and the Rice rule (see Further Determine 5 beneath) [Sturges. The Choice of a Class Interval. 1926. DOI: 10.1080/01621459.1926.10502161], [Lane, David M., et. al. Histograms. https://onlinestatbook.com/2/graphing_distributions/histograms.html].

An alternate is to visualise the distribution utilizing kernel density estimation (KDE). KDE is a smoothed model of a histogram: as an alternative of rectangular bars, it makes use of a steady curve constructed by summing many {smooth} “kernel” features, often, regular distributions (Further Determine 6).

I perceive that describing KDE as a sum of “tiny regular distributions” isn’t very intuitive. Right here’s a greater psychological image. Think about that every information level is stuffed with a lot of tiny grains of sand. For those who let the sand fall underneath gravity, it kinds a little bit pile immediately beneath that time. When a number of factors are shut to one another, their sand piles overlap and construct a bigger mound. Watch the animation beneath to see the way it works:

In a KDE plot, these “sand piles” are usually modeled as small regular (Gaussian) distributions positioned round every information level.
One other extensively used approach to summarize a distribution is a field plot. A field plot describes the distribution when it comes to quartiles. It reveals:
- The median (second quartile, Q2);
- The primary (Q1) and third (Q3) quartiles (the twenty fifth and seventy fifth percentiles), which kind the perimeters of the “field”;
- The whiskers, which mark the vary of the information excluding outliers;
- Particular person factors, which signify outliers.

To sum up, the following step is to visualise samples of various dimensions and shapes utilizing all of the strategies mentioned above. This can be completed by drawing samples from totally different theoretical distributions: two pattern sizes for every, 30 and 500 observations.

A frequency distribution is a key software for describing and understanding the conduct of a random variable based mostly on a pattern. Visible strategies like histograms, kernel density curves, and field plots complement one another and assist construct a transparent image of the distribution: its symmetry, the place the mass is concentrated, how unfold out it’s, and whether or not it comprises outliers.
Such perspective on the information can be helpful as a result of it has a pure probabilistic interpretation: the almost certainly values fall within the area the place the likelihood density is highest, i.e., the place the KDE curve reaches its peak.
As famous above, the residual distribution ought to look roughly regular. That’s why it is sensible to check two distributions: theoretical regular vs. the residuals we really observe. Two handy instruments for this are density plots and Q-Q plots with residual quantiles vs. regular quantiles. The parameters of the conventional distribution are estimated from the residual pattern. Since these plots work greatest with bigger samples, for illustration I’ll artificially improve every residual set to 500 values whereas preserving the important thing conduct of the residuals for every dataset (Determine 14).

As Determine 14 reveals, the residual distributions for datasets A* and B* are fairly effectively approximated by a traditional distribution. For B*, the tails drift a bit: massive errors happen barely extra usually than we wish. The bimodal case C* is way more placing: its residual distribution seems nothing like regular.
Heteroscedasticity in B* received’t present up in these plots, as a result of they have a look at residuals on their very own (one dimension) and ignore how the error modifications throughout the vary of predictions.
To sum up, a mannequin is never excellent, it has errors. Error evaluation with plots is a handy approach to diagnose the mannequin:
- For pair regression, it’s helpful to plot predicted and noticed values on the y-axis towards the characteristic on the x-axis. This makes the connection between the characteristic and the response straightforward to see;
- As an addition, plot noticed values (x-axis) vs. predicted values (y-axis). The nearer the factors are to the diagonal line coming from the bottom-left nook, the higher. This plot can be helpful as a result of it doesn’t rely on what number of options the mannequin has;
- If the aim is to check the complete distributions of predictions and observations, fairly than particular person pairs, a Q-Q plot is an effective selection;
- For very massive samples, cognitive load could be diminished by grouping values into quantiles on the Q-Q plot, so the plot can have, for instance, solely 100 scatter factors;
- A residual plot helps test whether or not the important thing linear regression assumptions maintain for the present mannequin (independence, normality of residuals, and homoscedasticity);
- For a neater comparability between the residual distribution and a theoretical regular distribution, use a Q-Q plot.
Metrics
Disclaimer relating to the designations X and Y
Within the visualizations on this part, some notation could look a bit uncommon in comparison with associated literature. For instance, predicted values are labeled , whereas the noticed response is labeled . That is intentional: although the dialogue is tied to mannequin analysis, I don’t need it to really feel like the identical concepts solely apply to the “prediction vs. commentary” pair. In follow, and could be any two arrays – the fitting selection is determined by the duty.
There’s additionally a sensible cause for selecting this pair: and are visually distinct. In plots and animations, they’re simpler to inform aside than pairs like and , or the extra acquainted and .
As compelling as visible diagnostics could be, mannequin high quality is greatest assessed along with metrics (numerical measures of efficiency). A superb metric is interesting as a result of it reduces cognitive load: as an alternative of inspecting one more set of plots, the analysis collapses to a single quantity (Determine 15).

Not like a residual plot, a metric can be a really handy format for automated evaluation, not simply straightforward to interpret, however straightforward to plug into code. That makes metrics helpful for numerical optimization, which we are going to get to a bit later.
This “Metrics” part additionally consists of statistical checks: they assist assess the importance of particular person coefficients and of the mannequin as an entire (we are going to cowl that later as effectively).
Here’s a non-exhaustive checklist:
- Coefficient of dedication R2 – [Kvalseth, Tarald O. Cautionary Note about R². 1985. https://www.tandfonline.com/doi/abs/10.1080/00031305.1985.10479448];
- Bias;
- Imply absolute error – MAE;
- Root imply sq. error – RMSE;
- Imply absolute share error – MAPE;
- Symmetric imply absolute share error – SMAPE;
- The F-test for checking whether or not the mannequin is critical as an entire;
- The t-test for checking the importance of the options and the goal;
- Durbin-Watson take a look at for analyzing residuals.
Determine 16 reveals metrics computed by evaluating the noticed house costs with the expected ones.

The metrics are grouped for readability. The primary group, proven in purple, consists of the correlation coefficient (between predicted and noticed values) and the coefficient of dedication, R². Each are dimensionless, and values nearer to 1 are higher. Be aware that correlation shouldn’t be restricted to predictions versus the goal. It will also be computed between a characteristic and the goal, or pairwise between options when there are a lot of of them.

The second group, proven in inexperienced, consists of metrics that measure error in the identical models because the response, which right here means $. For all three metrics, the interpretation is similar: the nearer the worth is to zero, the higher (Animation 2).

One attention-grabbing element: in Determine 16 the bias is zero in all circumstances. Actually, this implies the mannequin errors are usually not shifted in both course on common. A query for you: why is that this typically true for a linear regression mannequin fitted to any dataset (strive altering the enter values and enjoying with totally different datasets)?
Animation 2 and Determine 16 additionally present that because the hole between and grows, RMSE reacts extra strongly to massive errors than MAE. That occurs as a result of RMSE squares the errors.
The third group, proven in blue, consists of error metrics measured in percentages. Decrease values are higher. MAPE is delicate to errors when the true values are small, as a result of the components divides the prediction error by the noticed worth itself. When the precise worth is small, even a modest absolute error turns into a big share and might strongly have an effect on the ultimate rating (Determine 17).


Determine 17 reveals that the distinction measured within the unique models, absolutely the deviation between noticed and predicted values, stays the identical in each circumstances: it’s 0 for the primary pair, 8 for the second, and 47 for the third. For percentage-based metrics, the errors shrink for an apparent cause: the noticed values grow to be bigger.
The change is bigger for MAPE, as a result of it normalizes every error by the noticed worth itself. sMAPE, in distinction, normalizes by the typical magnitude of the noticed and predicted values. This distinction issues most when the observations are near zero, and it fades as values transfer away from zero, which is precisely what the determine reveals.
Aspect department 4. Options of MAPE and SMAPE calculations
The small print of metric calculations are vital to debate. Utilizing MAPE and SMAPE (and briefly MAE) as examples, this part reveals how otherwise metrics can behave throughout datasets. The primary takeaway is straightforward: earlier than beginning any machine studying mission, consider carefully about which metric, or metrics, it’s best to use to measure high quality. Not each metric is an effective match in your particular activity or information.
Here’s a small experiment. Utilizing the information from Determine 17, take the unique arrays, observations [1,2,3] and predictions [1,10,50]. Shift each arrays away from zero by including 10 to each worth, repeated for 10 iterations. At every step, compute three metrics: MAPE, SMAPE, and MAE. The outcomes are proven within the plot beneath:

As could be seen from the determine above, the bigger the values included within the dataset, the smaller the distinction between MAPE and SMAPE, and the smaller the errors measured in share phrases. The alignment of MAPE and SMAPE is defined by the calculation options that enable eliminating the impact of MAPE asymmetry, which is especially noticeable at small commentary values. MAE stays unchanged, as anticipated.
Now the explanation for the phrase “asymmetry” turns into clear. The best approach to present it’s with an instance. Suppose the mannequin predicts 110 when the true worth is 100. In that case, MAPE is 10%. Now swap them: the true worth is 110, however the prediction is 100. Absolutely the error continues to be 10, but MAPE turns into 9.1%. MAPE is uneven as a result of the identical absolute deviation is handled otherwise relying on whether or not the prediction is above the true worth or beneath it.
One other downside of MAPE is that it can’t be computed when some goal values are zero. A standard workaround is to switch zeros with a really small quantity throughout analysis, for instance 0.000001. Nonetheless, it’s clear that this could inflate MAPE.
Different metrics have their very own quirks as effectively. For instance, RMSE is extra delicate to massive errors than MAE. This part shouldn’t be meant to cowl each such element. The primary level is straightforward: select metrics thoughtfully. Use metrics really helpful in your area, and if there are not any clear requirements, begin with the most typical ones and experiment.
To summarize, the models of measurement for metrics and the ranges of potential values are compiled in Desk 2.
| Metric | Items | Vary | Which means |
| Pearson correlation coefficient (predictions vs goal) | Dimensionless | from -1 to 1 | The nearer to 1, the higher the mannequin |
| Coefficient of dedication R2 | Dimensionless | from −∞ to 1 | The nearer to 1, the higher the mannequin |
| Bias | The identical unit because the goal variable | from −∞ to ∞ | The nearer to 1, the higher the mannequin |
| Imply absolute error (MAE) | The identical unit because the goal variable | from 0 to ∞ | The nearer to zero, the higher the mannequin |
| Root imply sq. error (RMSE) | The identical unit because the goal variable | from 0 to ∞ | The nearer to zero, the higher the mannequin |
| Imply absolute share error (MAPE) | Share (%) | from 0 to ∞ | The nearer to zero, the higher the mannequin |
| Symmetric imply absolute share error (SMAPE) | Share (%) | from 0 to 200 | The nearer to zero, the higher the mannequin |
As talked about earlier, this isn’t an entire checklist of metrics. Some duties could require extra specialised ones. If wanted, fast reference data is all the time straightforward to get out of your favourite LLM.
Here’s a fast checkpoint. Mannequin analysis began with a desk of predicted and noticed values (Desk 1). Giant tables are laborious to examine, so the identical data was made simpler to digest with plots, shifting to visible analysis (Figures 9-14). The duty was then simplified additional: as an alternative of counting on professional judgment from plots, metrics have been computed (Figures 15-17 and Animations 1-3). There may be nonetheless a catch. Even after getting one or a number of numbers, it’s nonetheless as much as us to resolve whether or not the metric worth is “good” or not. In Determine 15, a 5% threshold was used for MAPE. That heuristic can’t be utilized to each linear regression activity. Information varies, enterprise targets are totally different, and many others. For one dataset, a very good mannequin would possibly imply an error beneath 7.5%. For an additional, the appropriate threshold is likely to be 11.2%.
F take a look at
That’s the reason we now flip to statistics and formal speculation testing. A statistical take a look at can, in precept, save us from having to resolve the place precisely to put the metric threshold, with one vital caveat, and provides us a binary reply: sure or no.
In case you have by no means come throughout statistical checks earlier than, it is sensible to begin with a simplified definition. A statistical take a look at is a approach to test whether or not what we observe is simply random variation or an actual sample. You possibly can consider it as a black field that takes in information and, utilizing a set of formulation, produces a solution: just a few intermediate values, equivalent to a take a look at statistic and a p-value, and a closing verdict (Determine 18) [Sureiman, Onchiri, et al. F-test of overall significance in regression analysis simplified. 2020. https://www.tandfonline.com/doi/full/10.1080/00031305.2016.1154108].

As Determine 18 reveals, earlier than operating a take a look at, we have to select a threshold worth. Sure, that is the fitting second to return again to that caveat: right here too, we’ve got to cope with a threshold. However on this case it’s a lot simpler, as a result of there are extensively accepted commonplace values to select from. This threshold is known as the importance stage. A worth of 0.05 implies that we settle for a 5% likelihood of incorrectly rejecting the null speculation. On this case, the null speculation might be one thing like: the mannequin is not any higher than a naive prediction based mostly on the imply. We are able to differ this threshold. For instance, some scientific fields use 0.01 and even 0.001, which is extra strict, whereas others use 0.10, which is much less strict.
If the sensible that means of the importance stage shouldn’t be absolutely clear at this level, that’s utterly superb. There’s a extra detailed clarification on the finish of this part. For now, it is sufficient to repair one key level: the statistical checks mentioned beneath have a parameter, , which we as researchers or engineers select based mostly on the duty. In our case, it’s set to 0.05.
So, a statistical take a look at lets us take the information and some chosen parameters, then compute take a look at portions which can be used for comparability, for instance, whether or not the take a look at statistic is above or beneath a threshold. Primarily based on that comparability, we resolve whether or not the mannequin is statistically vital. I might not suggest reinventing the wheel right here. It’s higher to make use of statistical packages (it’s dependable) to compute these checks, which is one cause why I’m not giving the formulation on this part. As for what precisely to check, the 2 frequent choices are the F statistic towards the crucial F worth, or the p-value towards the importance stage. Personally, principally out of behavior, I lean towards the second possibility.
We are able to use the F take a look at to reply the query, “Is the mannequin vital?” Since statistics is a mathematical self-discipline, allow us to first describe the 2 potential interpretations of the fitted mannequin in a proper means. The statistical take a look at will assist us resolve which of those hypotheses is extra believable.
We are able to formulate the null speculation (H₀) as follows: all coefficients for the impartial variables, that’s, the options, are equal to zero. The mannequin doesn’t clarify the connection between the options and the goal variable any higher than merely utilizing the (goal) imply worth.
The choice speculation (H₁) is then: at the least one coefficient shouldn’t be equal to zero. In that case, the mannequin is critical as a result of it explains some a part of the variation within the goal variable.
Now allow us to run the checks on our three datasets, A, B, and C (Determine 19).

As we will see from Determine 19, in all three circumstances the p-value is beneath 0.05, which is our chosen significance stage. We use 0.05 as a result of it’s the usual default threshold, and within the case of house value prediction, selecting the improper speculation shouldn’t be as crucial as it will be, for instance, in a medical setting. So there isn’t any sturdy cause to make the edge extra strict right here. p-value is beneath 0.05 means we reject the null speculation, H₀, for fashions A, B, and C. After this test, we will say that every one three fashions are statistically vital total: at the least one characteristic contributes to explaining variation within the goal.
Nonetheless, the instance of dataset C reveals that affirmation that the mannequin is considerably higher than the typical value doesn’t essentially imply that the mannequin is definitely good. The F-statistic checks for minimal adequacy.
One limitation of this method to mannequin analysis is that it’s fairly slender in scope. The F take a look at is a parametric take a look at designed particularly for linear fashions, so in contrast to metrics equivalent to MAPE or MAE, it can’t be utilized to one thing like a random forest (one other machine studying algorithm). Even for linear fashions, this statistical take a look at additionally requires commonplace assumptions to be met (see Assumptions 2-4 above: independence of observations, normality of residuals, and homoscedasticity).
Nonetheless, if this matter pursuits you, there may be a lot extra to discover by yourself. For instance, you would look into the t take a look at for particular person options, the place the speculation is examined individually for every mannequin coefficient, or the Durbin-Watson take a look at. Or you possibly can select another statistical take a look at to review additional. Right here we solely lined the fundamental thought. P.S. It’s particularly value being attentive to how the take a look at statistics are calculated and to the mathematical instinct behind them.
Aspect department 5. In case you are not completely clear in regards to the significance stage , please learn this part
Each time I attempted to grasp what significance stage meant, I ran right into a brick wall. Extra complicated examples concerned calculations that I didn’t perceive. Less complicated sources conveyed the idea extra clearly – “right here’s an instance the place every part is intuitively comprehensible”:
- H₀ (null speculation): The affected person doesn’t have most cancers;
- Sort I error: The take a look at says “most cancers is current” when it’s not really;
- If the importance stage is about at 0.05, in 5% of circumstances the take a look at could mistakenly alarm a wholesome individual by informing them that they’ve most cancers;
- Due to this fact, in medication, a low (e.g., 0.01) is usually chosen to reduce false alarms.
However right here we’ve got information and mannequin coefficients – every part is fastened. We apply the F-test and get a p-value < 0.05. We are able to run this take a look at 100 occasions, and the end result would be the similar, as a result of the mannequin is similar and the coefficients are the identical. There we go – 100 occasions we get affirmation that the mannequin is critical. And what’s the 5 % threshold right here? The place does this “likelihood” come from?
Allow us to break this down collectively. Begin with the phrase, “The mannequin is critical on the 0.05 stage”. Regardless of the way it sounds, this phrase shouldn’t be actually in regards to the mannequin itself. It’s actually a press release about how convincing the noticed relationship is within the information we used. In different phrases, think about that we repeatedly accumulate information from the actual world, match a mannequin, then accumulate a brand new pattern and match one other one, and maintain doing this many occasions. In a few of these circumstances, we are going to nonetheless discover a statistically vital relationship even when, in actuality, no actual relationship exists between the variables. The importance stage helps us account for that.
To sum up, with a p-value threshold of 0.05, even when no actual relationship exists, the take a look at will nonetheless say “there’s a relationship” in about 5 out of 100 circumstances, merely due to random variation within the information.
To make the textual content a bit much less dense, let me illustrate this with an animation. We are going to generate 100 random factors, then repeatedly draw datasets of 30 observations from that pool and match a linear regression mannequin to every one. We are going to repeat this sampling course of 20 occasions. With a significance stage of 5%, this implies we enable for about 1 case out of 20 wherein the F take a look at says the mannequin is critical although, in actuality, there isn’t any relationship between the variables.

Certainly, in 1 out of 20 circumstances the place there was really no relationship between x and y, the take a look at nonetheless produced a p-value beneath 0.05. If we had chosen a stricter significance stage, for instance 0.01, we’d have averted a Sort I error, that’s, a case the place we reject H₀ (there isn’t any relationship between x and y) and settle for the choice speculation although H₀ is in actual fact true.
For comparability, we are going to now generate a inhabitants the place a transparent linear relationship is current and repeat the identical experiment: 20 samples and the identical 20 makes an attempt to suit a linear regression mannequin.

To wrap up this overview chapter on regression metrics and the F take a look at, listed here are the primary takeaways:
- Visible strategies are usually not the one approach to assess prediction error. We are able to additionally use metrics. Their major benefit is that they summarize mannequin high quality in a single quantity, which makes it simpler to evaluate whether or not the mannequin is nice sufficient or not.
- Metrics are additionally used throughout mannequin optimization, so it is very important perceive their properties. For instance:
- The metrics from the “inexperienced group” (RMSE, MAE, and bias) are handy as a result of they’re expressed within the unique models of the goal.
- The basis imply squared error (RMSE) reacts extra strongly to massive errors and outliers than the imply absolute error (MAE).
- The “blue group” (MAPE and SMAPE) is expressed in %, which frequently makes these metrics handy to debate in a enterprise context. On the similar time, when the goal values are near zero, these metrics can grow to be unstable and produce deceptive estimates.
- Statistical checks present an much more compact evaluation of mannequin high quality, giving a solution within the type of “sure or no”. Nonetheless, as we noticed above, such a take a look at solely checks primary adequacy, the place the primary various to the fitted regression mannequin is just predicting the imply. It doesn’t assist in extra complicated circumstances, equivalent to dataset C, the place the connection between the characteristic and the goal is captured by the mannequin effectively sufficient to rise above statistical noise, however not absolutely.
Later within the article, we are going to use totally different metrics all through the visualizations, so that you just get used to wanting past only one favourite from the checklist 🙂
Forecast uncertainty. Prediction interval
An attention-grabbing mixture of visible evaluation and formal metrics is the prediction interval. A prediction interval is a variety of values inside which a brand new commentary is predicted to fall with a given likelihood. It helps present the uncertainty of the prediction by combining statistical measures with the readability of a visible illustration (Determine 20).

The primary query right here is how to decide on these threshold values, . Probably the most pure method, and the one that’s really utilized in follow, is to extract details about uncertainty from the circumstances the place the mannequin already made errors throughout coaching, particularly from the residuals. However to show a uncooked set of variations into precise threshold values, we have to go one stage deeper and have a look at linear regression as a probabilistic mannequin.
Recall how level prediction works. We plug the characteristic values into the mannequin, within the case of easy linear regression, only one characteristic, and compute the prediction. However a prediction is never precise. Normally, there’s a random error.
After we arrange a linear regression mannequin, we assume that small errors are extra doubtless than massive ones, and that errors in both course are equally doubtless. These two assumptions result in the probabilistic view of linear regression, the place the mannequin coefficients and the error distribution are handled as two elements of the identical complete (Determine 21) [Fisher, R. A. On the Mathematical Foundations of Theoretical Statistics. 1922. https://doi.org/10.1098/rsta.1922.0009].

As Determine 21 reveals, the variability of the mannequin errors could be estimated by calculating the usual deviation of the errors, denoted by . We may additionally speak in regards to the error variance right here, since it’s one other appropriate measure of variability. The usual deviation is just the sq. root of the variance. The bigger the usual deviation, the larger the uncertainty of the prediction (see Part 2 in Determine 21).
This leads us to the following step within the logic: the extra extensively the errors are unfold, the much less sure the mannequin is, and the broader the prediction interval turns into. General, the width of the prediction interval is determined by three major components:
- Noise within the information: the extra noise there may be, the larger the uncertainty;
- Pattern dimension: the extra information the mannequin has seen throughout coaching, the extra reliably its coefficients are estimated, and the narrower the interval turns into;
- Distance from the middle of the information: the farther the brand new characteristic worth is from the imply, the upper the uncertainty.
In simplified kind, the process for constructing a prediction interval seems like this:
- We match the mannequin (utilizing the components from the earlier part, Determine 6)
- We compute the error element, that’s, the residuals
- From the residuals, we estimate the standard dimension of the error
- Receive the purpose prediction
- Subsequent, we scale s utilizing a number of adjustment components: how a lot coaching information the mannequin was fitted on, how far the characteristic worth is from the middle of the information, and the chosen confidence stage. The arrogance stage controls how doubtless the interval is to include the worth of curiosity. We select it based mostly on the duty, in a lot the identical means we earlier selected the importance stage for statistical testing (frequent by default – 0.95).
As a easy instance, we are going to generate a dataset of 30 observations with a “excellent” linear relationship between the characteristic and the goal, match a mannequin, and compute the prediction interval. Then we are going to 1) add noise to the information, 2) improve the pattern dimension, and three) increase the arrogance stage from 90% to 95 and 99%, the place the prediction interval reaches its most width (see Animation 4).

And contemplate individually what the prediction interval seems like for datasets A, B, and C (Determine 22).

Determine 22 clearly reveals that although fashions A and B have the identical coefficients, their prediction intervals differ in width, with the interval for dataset B being a lot wider. In absolute phrases, the widest prediction interval, as anticipated, is produced by the mannequin fitted to dataset C.
Practice take a look at cut up and metrics
All the high quality assessments mentioned to date centered on how the mannequin behaves on the identical observations it was educated on. In follow, nevertheless, we need to know whether or not the mannequin may even carry out effectively on new information it has not seen earlier than.
That’s the reason, in machine studying, it is not uncommon greatest follow to separate the unique dataset into elements. The mannequin is fitted on one half, the coaching set, and its skill to generalize is evaluated on the opposite half, the take a look at pattern (Determine 23).

If we mix these mannequin diagnostic strategies into one massive visualization, that is what we get:

Determine 24 reveals that the metric values are worse on the take a look at information, which is precisely what we’d anticipate, for the reason that mannequin coefficients have been optimized on the coaching set. A couple of extra observations stand out:
- First, the bias metric has lastly grow to be informative: on the take a look at information it’s not zero, because it was on the coaching information, and now shifts in each instructions, upward for datasets A and B, and downward for dataset C.
- Second, dataset complexity clearly issues right here. Dataset A is the simplest case for a linear mannequin, dataset B is tougher, and dataset C is essentially the most tough. As we transfer from coaching to check information, the modifications within the metrics grow to be extra noticeable. The residuals additionally grow to be extra unfold out within the plots.
On this part, it is very important level out that the way in which we cut up the information into coaching and take a look at units can have an effect on what our mannequin seems like (Animation 5).

The selection of splitting technique is determined by the duty and on the character of the information. In some circumstances, the subsets shouldn’t be fashioned at random. Listed here are just a few conditions the place that is sensible:
- Geographic or spatial dependence. When the information have a spatial element, for instance temperature measurements, air air pollution ranges, or crop yields from totally different fields, close by observations are sometimes strongly correlated. In such circumstances, it is sensible to construct the take a look at set from geographically separated areas with the intention to keep away from overestimating mannequin efficiency.
- State of affairs-based testing. In some enterprise issues, it is very important consider upfront how the mannequin will behave in sure crucial or uncommon conditions, for instance at excessive or excessive characteristic values. Such circumstances could be deliberately included within the take a look at set, even when they’re absent or underrepresented within the coaching pattern.
Think about that there are solely 45 flats on this planet…
To make the remainder of the dialogue simpler to observe, allow us to introduce one vital simplification for this text. Think about that our hypothetical world, the one wherein we construct these fashions, could be very small and comprises solely 45 flats. In that case, all our earlier makes an attempt to suit fashions on datasets A, B, and C have been actually simply particular person steps towards recovering that unique relationship from all of the out there information.
From this perspective, A, B, and C are usually not actually separate datasets, although we will think about them as information collected in three totally different cities, A, B, and C. As a substitute, they’re elements of a bigger inhabitants, D. Allow us to assume that we will mix these samples and work with them as a single complete (Determine 25).

You will need to remember the fact that every part we do, splitting the information into coaching and take a look at units, preprocessing the information, calculating metrics, operating statistical checks, and every part else, serves one aim: to verify the ultimate mannequin describes the complete inhabitants effectively. The aim of statistics, and that is true for supervised machine studying as effectively, is to draw conclusions about the entire inhabitants utilizing solely a pattern.
In different phrases, if we in some way constructed a mannequin that predicted the costs of those 45 flats completely, we’d have a software that all the time provides the proper reply, as a result of on this hypothetical world there are not any different information on which the mannequin may fail. Once more, every part right here is determined by that “if.” Now let me return us to actuality and attempt to describe all the information with a single linear regression mannequin (Determine 26).

In the actual world, gathering information on each house is bodily unimaginable, as a result of it will take an excessive amount of time, cash, and energy, so we all the time work with solely a subset. The identical applies right here: we collected samples and tried to estimate the connection between the variables in a means that will carry us as shut as potential to the connection in inhabitants, total dataset D.
One essential observe: Later within the article, we are going to often benefit from the principles of our simplified world and peek at how the fitted mannequin behaves on the complete inhabitants. This can assist us perceive whether or not our modifications have been profitable, when the error metric goes down, or not, when the error metric goes up. On the similar time, please remember the fact that this isn’t one thing we will do in the actual world. In follow, it’s unimaginable to guage a mannequin on each single object!
Enhancing mannequin high quality
Within the earlier part, earlier than we mixed our information into one full inhabitants, we measured the mannequin’s prediction error and located the outcomes unsatisfying. In different phrases, we need to enhance the mannequin. Broadly talking, there are 3 ways to do this: change the information, change the mannequin, or change each. Extra particularly, the choices are:
- Increasing the pattern: rising the variety of observations within the dataset
- Decreasing the pattern: eradicating outliers and different undesirable rows from the information desk
- Making the mannequin extra complicated: including new options, both immediately noticed or newly engineered
- Making the mannequin less complicated: lowering the variety of options (typically this additionally improves the metrics)
- Tuning the mannequin: looking for the very best hyperparameters, that means parameters that aren’t realized throughout coaching
We are going to undergo these approaches one after the other, beginning with pattern enlargement. As an example the concept, we are going to run an experiment.
Increasing the pattern
Needless to say the values from the complete inhabitants are usually not immediately out there to us, and we will solely entry them in elements. On this experiment, we are going to randomly draw samples of 10 and 20 flats. For every pattern dimension, we are going to repeat the experiment 30 occasions. The metrics can be measured on 1) the coaching set, 2) the take a look at set, and three) the inhabitants, that’s, all 45 observations. This could assist us see whether or not bigger samples result in a extra dependable mannequin for the complete inhabitants (Animation 6).

Rising the pattern dimension is a good suggestion if solely as a result of mathematical statistics tends to work higher with bigger numbers. Because of this, the metrics grow to be extra secure, and the statistical checks grow to be extra dependable as effectively (Determine 27).

If boxplots are extra acquainted to you, check out Boxplot model of Determine 27.
Determine 27 in a type of Boxplot

Although we labored right here with very small samples, partly for visible comfort, Animation 6 and Determine 27 nonetheless allow us to draw just a few conclusions that additionally maintain for bigger datasets. Specifically:
- The typical RMSE on the inhabitants is decrease when the pattern dimension is 20 fairly than 10, particularly 4088 versus 4419. Which means a mannequin fitted on extra information has a decrease error on the inhabitants (all out there information).
- The metric estimates are extra secure for bigger samples. With 20 observations, the hole between RMSE on the coaching set, the take a look at set, and the inhabitants is smaller.
As we will see, utilizing bigger samples, 20 observations fairly than 10, led to raised metric values on the inhabitants. The identical precept applies in follow: after making modifications to the information or to the mannequin, all the time test the metrics. If the change improves the metric, maintain it. If it makes the metric worse, roll it again. Depend on an engineering mindset, not on luck. After all, in the actual world we can’t measure metrics on the complete inhabitants. However metrics on the coaching and take a look at units can nonetheless assist us select the fitting course.
Decreasing the pattern by filtering outliers
Since this part is about pruning the pattern, I’ll omit the train-test cut up so the visualizations keep simpler to learn. Another excuse is that linear fashions are extremely delicate to filtering when the pattern is small, and right here we’re intentionally utilizing small samples for readability. So on this part, every mannequin can be fitted on all observations within the pattern.
We tried to gather extra information for mannequin becoming. However now think about that we have been unfortunate: even with a pattern of 20 observations, we nonetheless did not acquire a mannequin that appears near the reference one (Determine 28).

In addition to a pattern that doesn’t replicate the underlying relationship effectively, different components could make the duty even tougher. Such distortions are fairly frequent in actual information for a lot of causes: measurement inaccuracies, technical errors throughout information storage or switch, and easy human errors. In our case, think about that a few of the actual property brokers we requested for information made errors when getting into data manually from paper data: they typed 3 as an alternative of 4, or added or eliminated zeros (Determine 29).

If we match a mannequin to this uncooked information, the end result can be removed from the reference mannequin, and as soon as once more we can be sad with the modeling high quality.
This time, we are going to attempt to remedy the issue by eradicating just a few observations which can be a lot much less much like the remaining, in different phrases, outliers. There are numerous strategies for this, however most of them depend on the identical primary thought: separating comparable observations from uncommon ones utilizing some threshold (Determine 30) [Mandic-Rajcevic, et al. Methods for the Identification of Outliers and Their Influence on Exposure Assessment in Agricultural Pesticide Applicators: A Proposed Approach and Validation Using Biological Monitoring. 2019. https://doi.org/10.3390/toxics7030037]:
- Interquartile vary (IQR), a nonparametric methodology
- Three-sigma rule, a parametric methodology, because it assumes a distribution, most frequently a traditional one
- Z-score, a parametric methodology
- Modified Z-score (based mostly on the median), a parametric methodology
Parametric strategies depend on an assumption in regards to the form of the information distribution, most frequently a traditional one. Nonparametric strategies don’t require such assumptions and work extra flexibly, primarily utilizing the ordering of values or quantiles. Because of this, parametric strategies could be more practical when their assumptions are appropriate, whereas nonparametric strategies are often extra strong when the distribution is unknown.

In a single-dimensional strategies (Determine 30), the options are usually not used. Just one variable is taken into account, particularly the goal y. That’s the reason, amongst different issues, these strategies clearly don’t take the development within the information into consideration. One other limitation is that they require a threshold to be chosen, whether or not it’s 1.5 within the interquartile vary rule, 3 within the three-sigma rule, or a cutoff worth for the Z-score.
One other vital observe is that three of the 4 outlier filtering strategies proven right here depend on an assumption in regards to the form of the goal distribution. If the information are usually distributed, or at the least have a single mode and are usually not strongly uneven, then the three-sigma rule, the Z-score methodology, and the modified Z-score methodology will often give affordable outcomes. But when the distribution has a much less typical form, factors flagged as outliers could not really be outliers. Since in Determine 30 the distribution is pretty near a traditional bell form, these commonplace strategies are applicable on this case.
Another attention-grabbing element is that the three-sigma rule is mostly a particular case of the Z-score methodology with a threshold of three.0. The one distinction is that it’s expressed within the unique y scale fairly than in standardized models, that’s, in Z-score area. You possibly can see this within the plot by evaluating the strains from the three-sigma methodology with the strains from the Z-score methodology at a threshold of two.0.
If we apply the entire filtering strategies described above to our information, we acquire the next fitted fashions (Determine 31).

Determine 31, we will see that the worst mannequin when it comes to RMSE on the inhabitants is the one fitted on the information with outliers nonetheless included. The most effective RMSE is achieved by the mannequin fitted on the information filtered utilizing the Z-score methodology with a threshold of 1.5.
Determine 31 makes it pretty straightforward to check how efficient the totally different outlier filtering strategies are. However that impression is deceptive, as a result of right here we’re checking the metrics towards the complete inhabitants D, which isn’t one thing we’ve got entry to in actual mannequin growth.
So what ought to we do as an alternative? Experiment. In some circumstances, the quickest and most sensible possibility is to scrub the take a look at set after which measure the metric on it. In others, outlier elimination could be handled as profitable if the hole between the coaching and take a look at errors turns into smaller. There isn’t any single method that works greatest in each case.
I recommend shifting on to strategies that use data from a number of variables. I’ll point out 4 of them, and we are going to have a look at the final two individually:

Every methodology proven in Determine 32 deserves a separate dialogue, since they’re already way more superior than the one-dimensional approaches. Right here, nevertheless, I’ll restrict myself to the visualizations and keep away from going too deep into the small print. We are going to deal with these strategies from a sensible perspective and have a look at how their use impacts the coefficients and metrics of a linear regression mannequin (Determine 33).

The strategies proven within the visualizations above are usually not restricted to linear regression. This sort of filtering will also be helpful for different regression algorithms, and never solely regression ones. That mentioned, essentially the most attention-grabbing strategies to review individually are those which can be particular to linear regression itself: leverage, Cook dinner’s distance, and Random Pattern Consensus (RANSAC).
Now allow us to have a look at leverage and Cook dinner’s distance. Leverage is a amount that reveals how uncommon an commentary is alongside the x-axis, in different phrases, how far is from the middle of the information. Whether it is far-off, the commentary has excessive leverage. A superb metaphor here’s a seesaw: the farther you sit from the middle, the extra affect you’ve on the movement. Cook dinner’s distance measures how a lot a degree can change the mannequin if we take away it. It is determined by each leverage and the residual.

Within the instance above, the calculations are carried out iteratively for readability. In follow, nevertheless, libraries equivalent to scikit-learn implement this otherwise, so Cook dinner’s distance could be computed with out really refitting the mannequin n occasions.
One vital observe: a big Cook dinner’s distance doesn’t all the time imply the information are unhealthy. It might level to an vital cluster as an alternative. Blindly eradicating such observations can harm the mannequin’s skill to generalize, so validation is all the time a good suggestion.
In case you are in search of a extra automated approach to filter out values, that exists too. One good instance is the RANSAC algorithm, which is a useful gizmo for automated outlier elimination (Animation 8). It really works in six steps:
- Randomly choose a subset of n observations.
- Match a mannequin to these n observations.
- Take away outliers, that’s, exclude observations for which the mannequin error exceeds a selected threshold.
- Non-compulsory step: match the mannequin once more on the remaining inliers and take away outliers yet one more time.
- Rely the variety of inliers, denoted by m.
- Repeat the primary 5 steps a number of occasions, the place we select the variety of iterations ourselves, after which choose the mannequin for which the variety of inliers m is the biggest.

The outcomes of making use of the RANSAC algorithm and the Cook dinner’s distance methodology are proven in Determine 34.

Primarily based on the outcomes proven in Determine 34, essentially the most promising mannequin on this comparability is the one fitted with RANSAC.
To sum up, we tried to gather extra information, after which filtered out what regarded uncommon. It’s value noting that outliers are usually not essentially “unhealthy” or “improper” values. They’re merely observations that differ from the remaining, and eradicating them from the coaching set shouldn’t be the identical as correcting information errors. Even so, excluding excessive observations could make the mannequin extra secure on the bigger share of extra typical information.
For readability, within the subsequent a part of the article we are going to proceed working with the unique unfiltered pattern. That means, we can see how the mannequin behaves on outliers underneath totally different transformations. Nonetheless, we now know what to do after we need to take away them.
Making the mannequin extra complicated: a number of linear regression
As a substitute, and likewise as a complement to the primary two approaches (of mannequin high quality enchancment), we will introduce new options to the mannequin.

Characteristic engineering. Producing new options
A superb place to begin reworking the characteristic area is with one of many easiest approaches to implement: producing new options from those we have already got. This makes it potential to keep away from modifications to the information assortment pipelines, which in flip makes the answer quicker and sometimes cheaper to implement (in distinction to gathering new options from scratch). One of the crucial frequent transformations is the polynomial one, the place options are multiplied by one another and raised to an influence. Since our present dataset has just one characteristic, this may look as follows (Determine 36).

Be aware that the ensuing equation is now a polynomial regression mannequin, which makes it potential to seize nonlinear relationships within the information. The upper the polynomial diploma, the extra levels of freedom the mannequin has (Determine 37).

There are numerous totally different transformations that may be utilized to the unique information. Nonetheless, as soon as we use them, the mannequin is not really linear, which is already seen within the form of the fitted curves in Determine 37. For that cause, I can’t go into them intimately on this article. If this sparked your curiosity, you possibly can learn extra about different characteristic transformations that may be utilized to the unique information. A superb reference right here is Trevor Hastie, Robert Tibshirani, Jerome Friedman – The Parts of Statistical Studying):
- Purposeful transformations
- Logarithms:
- Reciprocals:
- Roots:
- Exponentials:
- Trigonometric features: particularly when a characteristic has periodic conduct
- Sigmoid:
- Binarization and discretization
- Binning: cut up a characteristic X into intervals, for instance,
- Quantile binning: cut up the information into teams with equal numbers of observations
- Threshold features (whats up, neural networks)
- Splines
- Wavelet and Fourier transforms
- and plenty of others
Gathering new options
If producing new options doesn’t enhance the metric, we will transfer to a “heavier” method: accumulate extra information, however this time not new observations, as we did earlier, however new traits, that’s, new columns.
Suppose we’ve got an opportunity to gather a number of extra candidate options. Within the case of house costs, the next would make sense to think about:
- Condominium space, in sq. meters
- Distance to the closest metro station, in meters
- Metropolis
- Whether or not the house has air-con
The up to date dataset would then look as follows:

A observe on visualization
Trying again at Determine 1, and at many of the figures earlier within the article, it’s straightforward to see {that a} two-dimensional plot is not sufficient to seize all of the options. So it’s time to swap to new visualizations and have a look at the information from a unique angle (Determine 39 and Animation 9).

It’s best to evaluate the determine intimately (Determine 40).


Animation 9 highlights two noticeable patterns within the dataset:
- The nearer an house is to the metro, the upper its value tends to be. Flats close to metro stations additionally are likely to have a smaller space (Statement 2 in Determine 40)
- Air-con is a characteristic that clearly separates the goal, that’s, house value: flats with air-con are usually costlier (Statement 6 in Determine 40).
Because the figures and animation present, a very good visualization can reveal vital patterns within the dataset lengthy earlier than we begin becoming a mannequin or taking a look at residual plots.
Aspect department 6. Pondering again to Determine 5, why did the worth lower in spite of everything?
Allow us to return to one of many first figures (Determine 5 and Determine 7) within the article, the one used to clarify the concept of describing information with a straight line. It confirmed an instance with three observations the place the worth went down although the variety of rooms elevated. However every part turns into clear as soon as we visualize the information with a further characteristic:

The explanation for the worth drop turns into a lot clearer right here: although the flats have been getting bigger, they have been additionally a lot farther from the metro station. Don’t let the simplicity of this instance idiot you. It illustrates an vital thought that’s straightforward to lose sight of when working with really massive and complicated information: we can’t see relationships between variables past the information we really analyze. That’s the reason conclusions ought to all the time be drawn with care. A brand new sample could seem as quickly because the dataset features yet one more dimension.
Because the variety of options grows, it turns into tougher to construct pairwise visualizations like those proven in Figures 39 and 40. In case your dataset comprises many numerical options, a standard selection is to make use of correlation matrices (Determine 41). I’m positive you’ll come throughout them usually should you proceed exploring information science / information evaluation area.

The identical precept applies right here because it did when evaluating mannequin high quality: it’s cognitively simpler for an engineer to interpret numbers, one for every pair, than to examine a big set of subplots. Determine 41 reveals that value is positively correlated with the options variety of rooms and space, and negatively correlated with distance to the metro. This is sensible: usually, the nearer an house is to the metro or the bigger it’s, the costlier it tends to be.
It’s also value noting why the correlation coefficient is so usually visualized. It’s all the time helpful to test whether or not the dataset comprises predictors which can be strongly correlated with one another, a phenomenon referred to as multicollinearity. That’s precisely what we see for the pair variety of rooms and space, the place the correlation coefficient is the same as one. In circumstances like this, it usually is sensible to take away one of many options, as a result of it provides little helpful data to the mannequin whereas nonetheless consuming sources, for instance throughout information preparation and mannequin optimization. Multicollinearity may result in different disagreeable penalties, however we are going to speak about it a bit later.
On the significance of preprocessing (categorical) options
As Determine 39 reveals, the desk now comprises not solely clear numerical values such because the variety of rooms, but in addition much less tidy distances to the metro, and even not simple values equivalent to metropolis names or textual content solutions to questions like whether or not the house has a sure characteristic (e.g. air-con).
And whereas distance to the metro shouldn’t be an issue, it’s simply one other numerical characteristic like those we used within the mannequin earlier, metropolis names can’t be fed into the mannequin immediately. Simply strive assigning a coefficient to an expression like this: house value = X * New York. You might joke that some “flats” actually may cost a little, say, two New York, however that won’t offer you a helpful mannequin. That’s the reason categorical options require particular strategies to transform them into numerical kind
Beginning with the less complicated characteristic, air-con, because it takes solely two values, sure or no. Options like this are often encoded, that’s, transformed from textual content into numbers, utilizing two values, for instance (Determine 42):

Discover that Determine 42 doesn’t present two separate fashions, every fitted to its personal subset, however a single mannequin. Right here, the slope coefficient stays fastened, whereas the vertical shift of the fitted line differs relying on whether or not the binary characteristic is 0 or 1. This occurs as a result of when the characteristic is the same as 0, the corresponding time period within the mannequin turns into zero. This works effectively when the connection between the options and the goal is linear and follows the identical course for all observations. However a binary characteristic won’t assist a lot when the connection is extra complicated and modifications course throughout the information (Determine 43).

As Determine 43 reveals, within the worst case a mannequin with a binary characteristic collapses to the identical conduct as a mannequin with only one numerical characteristic. To deal with this “downside,” we will borrow an thought from the earlier part (characteristic era) and generate a brand new interplay characteristic, or we will match two separate fashions for various elements of the dataset (Determine 44).

Now that we’ve got handled the binary characteristic, it is sensible to maneuver on to the extra complicated case the place a column comprises greater than two distinctive values. There are numerous methods to encode categorical values, and a few of them are proven in Determine 45. I can’t undergo all of them right here, although, as a result of in my very own expertise one-hot encoding has been sufficient for sensible functions. Simply remember the fact that there are totally different encoding strategies.

Estimating characteristic significance
Now that we all know how you can make the mannequin extra complicated by including new options, it is sensible to speak about how you can mix the impartial variables extra thoughtfully. After all, when the characteristic area grows, whether or not via characteristic era or via gathering new information, sensible limits shortly seem, equivalent to “frequent sense” and mannequin “coaching time”. However we will additionally depend on more practical heuristics to resolve which options are literally value conserving within the mannequin. Beginning with the only one and take a more in-depth have a look at the coefficients of a a number of linear regression mannequin (Determine 46).

As Determine 46 reveals, a small downside seems right here: variations in characteristic scale have an effect on the estimated coefficients. Variations in scale additionally result in different disagreeable results, which grow to be particularly noticeable when numerical strategies are used to seek out the optimum coefficients. That’s the reason it’s commonplace follow to carry options to a standard scale via normalization.
Normalization and standardization (commonplace scaling) of options
Normalization is a knowledge transformation that brings the values within the arrays to the identical vary (Determine 47).

As soon as the options are delivered to the identical scale, the scale of the coefficients in a linear regression mannequin turns into a handy indicator of how strongly the mannequin depends on every variable when making predictions.
The precise formulation used for normalization and standardization are proven in Determine 48.

From this level on, we are going to assume that every one numerical options have been standardized. For the sake of clearer visualizations, we are going to apply the identical transformation to the goal as effectively, although that isn’t obligatory. When wanted, we will all the time convert the goal again to its unique scale.
Mannequin coefficient and error panorama when the options are standardized
As soon as the unique options have been standardized, that means the coefficients , , and so forth are actually on a comparable scale, which makes them simpler to differ, it turns into a very good second to look extra carefully at how their values have an effect on mannequin error. To measure error, we are going to use MAE and MAPE for easy linear regression, and RMSE for a number of linear regression.

As Animation 10 reveals, there’s a explicit mixture of coefficients at which the mannequin error reaches its minimal. On the similar time, modifications within the intercept and the slope have an effect on the error to the same diploma, the contour strains of the error floor on the left are nearly round.
For comparability, it’s helpful to take a look at how totally different metric landscapes could be. Within the case of imply absolute share error, the image modifications noticeably. As a result of MAPE is delicate to errors at small goal values, right here, “low cost flats”, the minimal stretches into an elongated valley. Because of this, many coefficient mixtures produce comparable MAPE values so long as the mannequin suits the area of small y effectively, even when it makes noticeable errors for costly flats (Animation 11).

Subsequent, we improve the variety of options within the mannequin, so as an alternative of discovering the optimum mixture of two coefficients, we now want to seek out the very best mixture of three (Animations 12 and 13):


The animations above present that the options are strongly linearly associated. For instance, in Animation 12, the vs projection, the aircraft on the left within the lower-left panel, reveals a transparent linear sample. This tells us two issues. First, there’s a sturdy unfavourable correlation between the options variety of rooms and distance to the metro. Second, although the coefficients “transfer alongside the valley” of low RMSE values, the mannequin predictions stay secure, and the error hardly modifications. This additionally means that the options carry comparable data. The identical sample seems in Animation 13, however there the linear relationship between the options is even stronger, and constructive fairly than unfavourable.
I hope this brief part with visualizations gave you an opportunity to catch your breath, as a result of the following half can be tougher to observe: from right here on, linear algebra turns into unavoidable. Nonetheless, I promise it’s going to embody simply as many visualizations and intuitive examples.
Extending the analytical resolution to the multivariate case
Earlier within the article, after we explored the error floor, we may visually see the place the mannequin error reached its minimal. The mannequin itself has no such visible cue, so it finds the optimum, the very best mixture of coefficients , , , and so forth, utilizing a components. For easy linear regression, the place there is just one characteristic, we already launched that equation (Determine 6). However now we’ve got a number of options, and as soon as they’ve been preprocessed, it’s pure to ask how you can discover the optimum coefficients for a number of linear regression, in different phrases, how you can prolong the answer to higher-dimensional information.
A fast disclaimer: this part can be very colourful, and that’s intentional, as a result of every coloration carries that means. So I’ve two requests. First, please pay shut consideration to the colours. Second, when you’ve got issue distinguishing colours or shades, please ship me your options on how these visualizations might be improved, together with in a personal message should you desire. I’ll do my greatest to maintain enhancing the visuals over time.
Earlier, after we launched the analytical resolution, we wrote the calculations in scalar kind. However it’s way more environment friendly to change to vector notation. To make that step simpler, we are going to visualize the unique information not in characteristic area, however in commentary area (Determine 49).

Although this manner of wanting on the information could seem counterintuitive at first, there isn’t any magic behind it. The info are precisely the identical, solely the shape has modified. Shifting on, at school, at the least in my case, vectors have been launched as directed line segments. These “directed line segments” could be multiplied by a quantity and added collectively. In vector area, the aim of linear regression is to discover a transformation of the vector x such that the ensuing prediction vector, often written as , is as shut as potential to the goal vector y. To see how this works, we will begin by making an attempt the only transformations, starting with multiplication by a quantity (Determine 50).

Ranging from the top-left nook of Determine 50, the mannequin doesn’t remodel the characteristic vector x in any respect, as a result of the coefficient is the same as 1. Because of this, the expected values are precisely the identical because the characteristic values, and the vector x absolutely corresponds to the forecast vector
If the coefficient is bigger than 1, multiplying the vector x by this coefficient will increase the size of the prediction vector proportionally. The characteristic vector will also be compressed, when is between 0 and 1, or flipped in the wrong way, when is lower than 0.

Determine 50 provides a transparent visible clarification of what it means to multiply a vector by a scalar. However in Determine 51, two extra vector operations seem. It is sensible to briefly evaluate them individually earlier than shifting on (Determine 52).

After this temporary reminder, we will proceed. As Determine 51 reveals, for 2 observations we have been capable of categorical the goal vector as a mix of characteristic vectors and coefficients. However now it’s time to make the duty tougher (Animation 14).

Because the variety of observations grows, the dimensionality grows with it, and the plot features extra axes. That shortly turns into laborious for us (people) to image, so I can’t go additional into greater dimensions right here, there isn’t any actual want. The primary concepts we’re discussing nonetheless work there as effectively. Specifically, the duty stays the identical: we have to discover a mixture of the vectors (the all-ones vector) and , the characteristic vector from the dataset, such that the ensuing prediction vector is as shut as potential to the goal vector . The one issues we will differ listed here are the coefficients multiplying v, particularly , and , particularly . So now we will strive totally different mixtures and see what the answer seems like each in characteristic area and in vector area (Animation 15).

The realm of the graph that comprises all potential options could be outlined, which supplies us a aircraft. Within the animation above, that aircraft is proven as a parallelogram to make it simpler to see. We are going to name this aircraft the prediction subspace and denote it as . As proven in Animation 15, the goal vector y doesn’t lie within the resolution subspace. Which means regardless of which resolution, or prediction vector, we discover, it’s going to all the time differ barely from the goal one. Our aim is to discover a prediction vector that lies as shut as potential to y whereas nonetheless belonging to the subspace .
Within the visualization above, we constructed this subspace by combining the vectors and with totally different coefficients. The identical expression will also be written in a extra compact kind, utilizing matrix multiplication. To do that, we introduce yet one more vector, this time constructed from the coefficients and . We are going to denote it by . A vector could be remodeled by multiplying it by a matrix, which might rotate it, stretch or compress it, and likewise map it into one other subspace. If we take the matrix constructed from the column vectors and , and multiply it by the vector made up of the coefficient values, we acquire a mapping of into the subspace (Determine 53).

Be aware that, consistent with our assumptions, the goal vector doesn’t lie within the prediction subspace. Whereas a straight line can all the time be drawn precisely via two factors, with three or extra factors the prospect will increase that no excellent mannequin with zero error exists. That’s the reason the goal vector doesn’t lie on the hyperplane even for the optimum mannequin (see the black vector for mannequin C in Determine 54).

A better have a look at the determine reveals an vital distinction between the prediction vectors of fashions A, B, and C: the vector for mannequin C seems just like the shadow of the goal vector on the aircraft. Which means fixing a linear regression downside could be interpreted as projecting the vector y onto the subspace . The most effective prediction amongst all potential ones is the vector that ends on the level on the aircraft closest to the goal. From primary geometry, the closest level on a aircraft is the purpose the place a perpendicular from the goal meets the aircraft. This perpendicular section can be a vector, known as the residual vector , as a result of it’s obtained by subtracting the predictions from the goal (recall the residual components from the chapter on visible mannequin analysis).
So, we all know the goal vector and the characteristic vector . Our aim is to discover a coefficient vector such that the ensuing prediction vector is as shut as potential to . We have no idea the residual vector , however we do know that it’s orthogonal to the area . This, in flip, implies that is orthogonal to each course within the aircraft, and subsequently, particularly, perpendicular to each column of , that’s, to the vectors and .

The analytical methodology we’ve got simply gone via is known as the least squares methodology, or Extraordinary Least Squares (OLS). It has this identify as a result of we selected the coefficients to reduce the sum of squared residuals of the mannequin (Determine 6). In vector area, the scale of the residuals is the squared Euclidean distance from the goal level to the subspace (Determine 55). In different phrases, least squares means the smallest squared distance.
Now allow us to recall the aim of this part: we labored via the formulation and visualizations above to increase the analytical resolution to the multivariate case. And now it’s time to test how the components works when there are usually not one however two options! Take into account a dataset with three observations, to which we add yet one more characteristic (Animation 16).

There are three vital findings to remove from Animation 16:
- First, the mannequin aircraft passes precisely via all three information factors. Which means the second characteristic added the lacking data that the one characteristic mannequin lacked. In Determine 50, for instance, not one of the strains handed via all of the factors.
- Second, on the fitting, the variety of vectors has not modified, as a result of the dataset nonetheless comprises three observations.
- Third, the subspace is not only a “aircraft” on the graph, it now fills all the area. For visualization functions, the values are bounded by a 3 dimensional form, a parallelepiped. Since this subspace absolutely comprises the goal vector y, the projection of the goal turns into trivial. Within the animation, the goal vector and the prediction vector coincide. The residual is zero.
When the analytical resolution runs into difficulties
Now think about we’re unfortunate, and the brand new characteristic x2 doesn’t add any new data. Suppose this new characteristic could be expressed as a linear mixture of the opposite two, the shift time period and have x1. In that case, the polygon collapses again right into a aircraft, as proven in Animation 17.

And although we beforehand had no bother discovering a projection onto such a subspace, the prediction vector is now constructed not from two vectors, the shift time period and x1, however from three, the shift time period, x1 and x2. As a result of there are actually extra levels of freedom, there may be a couple of resolution. On the left aspect of the graph, that is proven by two separate mannequin surfaces that describe the information equally effectively from the perspective of the least squares methodology. On the fitting, the characteristic vectors for every mannequin are proven, and in each circumstances they add as much as the identical prediction vector.
With this type of enter information, the issue seems when making an attempt to compute the inverse matrix (Determine 56).

As Determine 56 reveals, the matrix is singular, which suggests the inverse matrix components can’t be utilized and there’s no distinctive resolution. It’s value noting that even when there isn’t any precise linear dependence, the issue nonetheless stays if the options are extremely correlated with each other, for instance, ground space and variety of rooms. In that case, the matrix turns into ill-conditioned, and the answer turns into numerically unstable. Different points may additionally come up, for instance with one-hot encoded options, however even that is already sufficient to begin occupied with various resolution strategies.
Along with the problems mentioned above, an analytical resolution to linear regression can be not relevant within the following circumstances:
- A non-quadratic or non-smooth loss operate is used, equivalent to L1 loss or quantile loss. In that case, the duty not reduces to the least squares methodology.
- The dataset could be very massive, or the computing system has restricted reminiscence, so even when a components exists, calculating it immediately shouldn’t be sensible.
Anticipating how the reader could really feel after getting via this part, it’s value pausing for a second and conserving one major thought in thoughts: typically the “components” both doesn’t work or shouldn’t be value utilizing, and in these circumstances we flip to numerical strategies.
Numerical strategies
To deal with the issue with the analytical resolution components described above, numerical strategies are used. Earlier than shifting on to particular implementations, nevertheless, it’s helpful to state the duty clearly: we have to discover a mixture of coefficients for the options in a linear regression mannequin that makes the error as small as potential. We are going to measure the error utilizing metrics.
Exhaustive search
The best method is to strive all coefficient mixtures utilizing some fastened step dimension. On this case, exhaustive search means checking each pair of coefficients from a predefined discrete grid of values and choosing the pair with the smallest error. The MSE metric is often used to measure that error, which is similar as RMSE however with out the sq. root.
Maybe due to my love for geography, one analogy has all the time come to thoughts: optimization because the seek for the placement with the bottom elevation (Animation 18). Think about a panorama within the “actual world” on the left. Throughout the search, we will pattern particular person areas and construct a map within the middle, with the intention to remedy a sensible downside, in our case, to seek out the coordinates of the purpose the place the error operate reaches its minimal.
For simplicity, Animations 18 and 19 present the method of discovering coefficients for easy linear regression. Nonetheless, the numerical optimization strategies mentioned right here additionally prolong to multivariate circumstances, the place the mannequin consists of many options. The primary thought stays the identical, however such issues grow to be extraordinarily tough to visualise due to their excessive dimensionality.

Random search
The exhaustive search method has one main downside: it relies upon closely on the grid step dimension. The grid covers the area uniformly, and though some areas are clearly unpromising, computations are nonetheless carried out for poor coefficient mixtures. Due to this fact, it is likely to be useful to discover panorama randomly with out a pre-defined grid (Animation 19).

One downside of each random search and grid based mostly search is their computational price, particularly when the dataset is massive and the variety of options is excessive. In that case, every iteration requires computational effort, so it is sensible to search for an method that minimizes the variety of iterations.
Utilizing details about the course
As a substitute of blindly making an attempt random coefficient mixtures, the method could be improved by utilizing details about the form of the error operate panorama and taking a step in essentially the most promising course based mostly on the present worth. That is particularly related for the MSE error operate in linear regression, as a result of the error operate is convex, which suggests it has just one world optimum.
To make the concept simpler to see, we are going to simplify the issue and take a slice alongside only one parameter, a one dimensional array, and use it for example. As we transfer alongside this array, we will use the truth that the error worth has already been computed on the earlier step. By taking MSE on this instance and evaluating the present worth with the earlier one, we will decide which course is sensible for the following step, as proven in Determine 57.

We transfer alongside the slice from left to proper, and if the error begins to extend, we flip and transfer in the wrong way.
It is sensible to visualise this method in movement. Begin from a random preliminary guess, a randomly chosen level on the graph, and transfer to the fitting, thereby rising the intercept coefficient. If the error begins to develop, the following step is taken in the wrong way. Throughout the search, we may even depend what number of occasions the metric is evaluated (Animation 20).

You will need to observe explicitly that in Animation 20 the step is all the time equal to 1 interval, one grid step, and no derivatives are used but, anticipating the gradient descent algorithm. We merely examine metric values in pairs.
The method described above has one main downside: it relies upon closely on the grid dimension. For instance, if the grid is okay, many steps can be wanted to achieve the optimum. However, if the grid is simply too coarse, the optimum can be missed (Animation 21).

So, we wish the grid to be as dense as potential with the intention to descend to the minimal with excessive accuracy. On the similar time, we wish it to be as sparse as potential with the intention to scale back the variety of iterations wanted to achieve the optimum. Utilizing the spinoff solves each of those issues.
Gradient descent
Because the grid step turns into smaller in pairwise comparisons, we arrive on the restrict based mostly definition of the spinoff (Determine 58).

Now it’s time to surf throughout the error panorama. See the animation beneath, which reveals the gradient and the anti-gradient vectors (Animation 22). As we will see, the step dimension can now be chosen freely, as a result of we’re not constrained by an everyday grid [Goh, Gabriel. Why Momentum Really Works. 2017. https://distill.pub/2017/momentum/].

In multivariate areas, for instance when optimizing the intercept and slope coefficients on the similar time, the gradient consists of partial derivatives (Determine 59).

It’s now time to see gradient descent in motion (Animation 23).

See how gradient descent converges at totally different studying charges


(hyperlink to the code for producing the animation – animation by writer)
A helpful characteristic of numerical strategies is that the error operate could be outlined in several methods and, because of this, totally different properties of the mannequin could be optimized (Determine 60).

When Tukey’s loss operate is used, the optimization course of seems as follows (Animation 24).

Nonetheless, in contrast to the squared loss, Tukey’s loss operate shouldn’t be all the time convex, which suggests it could have native minima and saddle factors the place the optimization could get caught (Animation 25).

Now we transfer on to multivariate regression. If we have a look at the convergence historical past of the answer towards the optimum coefficients, we will see how the coefficients for the “vital” options step by step improve, whereas the error step by step decreases as effectively (Determine 61).

Regularization
Recall the impact proven in Animation 5, the place totally different coaching samples led to totally different estimated coefficients, although we have been making an attempt to get better the identical underlying relationship between the characteristic and the goal. The mannequin turned out to be unstable, that means it was delicate to the prepare take a look at cut up.
There may be one other downside as effectively: typically a mannequin performs effectively on the coaching set however poorly on new information.
So, on this part, we are going to have a look at coefficient estimation from two views:
- How regularization helps when totally different prepare take a look at splits result in totally different coefficient estimates
- How regularization helps the mannequin carry out effectively to new information
Needless to say our information shouldn’t be nice: there may be multicollinearity, that means correlation between options, which results in numerically unstable coefficients (Determine 62).

A method to enhance numerical stability is to impose constraints on the coefficients, that’s, to make use of regularization (Determine 63).

Regularization permits finer management over the coaching course of: the characteristic coefficients tackle extra affordable values. This additionally helps handle potential overfitting, when the mannequin performs a lot worse on new information than on the coaching set (Determine 64).

At a sure level (Determine 64), the metric on the take a look at set begins to rise and diverge from the metric on the coaching set, ranging from iteration 10 of gradient descent with L2 regularization. That is one other signal of overfitting. Nonetheless, for linear fashions, such conduct throughout gradient descent iterations is comparatively uncommon, in contrast to in lots of different machine studying algorithms.
Now we will have a look at how the plots change for various coefficient values in Determine 65.

Determine 65 reveals that with regularization, the coefficients grow to be extra even and not differ a lot, even when totally different coaching samples are used to suit the mannequin.
Overfitting
The energy of regularization could be diversified (Animation 26).

Animation 26 reveals the next:
- Row 1: The characteristic coefficients, the metrics on the coaching and take a look at units, and a plot evaluating predictions with precise values for the mannequin with out regularization.
- Row 2: How Lasso regression behaves at totally different ranges of regularization. The error on the take a look at set decreases at first, however then the mannequin step by step collapses to predicting the imply as a result of the regularization turns into too sturdy, and the characteristic coefficients shrink to zero.
- Row 3: Because the regularization turns into stronger, Ridge regression reveals higher and higher error values on the take a look at set, although the error on the coaching set step by step will increase.
The primary takeaway from Animation 26 is that this: with weak regularization, the mannequin performs very effectively on the coaching set, however its high quality drops noticeably on the take a look at set. That is an instance of overfitting (Determine 66).

Right here is a man-made however extremely illustrative instance based mostly on generated options for polynomial regression (Animation 27).

Hyperparameters tuning
Above, we touched on a vital query: how you can decide which worth of the hyperparameter alpha is appropriate for our dataset (since we will differ regularization energy). One possibility is to separate the information into coaching and take a look at units, prepare n fashions on the coaching set, then consider the metric on the take a look at set for every mannequin. We then select the one with the smallest take a look at error (Determine 67).

Nonetheless, the method above creates a danger of tuning the mannequin to a selected take a look at set, which is why cross-validation is usually utilized in machine studying (Determine 68).

As Determine 68 reveals, in cross-validation the metric is evaluated utilizing all the dataset, which makes comparisons extra dependable. This can be a quite common method in machine studying, and never just for linear regression fashions. If this matter pursuits you, the scikit-learn documentation on cross-validation is an effective place to proceed: https://scikit-learn.org/secure/modules/cross_validation.html.
Linear regression is an entire world
In machine studying, it’s linked with metrics, cross-validation, hyperparameter tuning, coefficient optimization with gradient descent, strategies for filtering values and choosing options, and preprocessing.
In statistics and likelihood concept, it entails parameter estimation, residual distributions, prediction intervals, and statistical testing.
In linear algebra, it brings in vectors, matrix operations, projections onto characteristic subspaces, and way more.

Conclusion
Thanks to everybody who made it this far.
We didn’t simply get acquainted with a machine studying algorithm, but in addition with the toolkit wanted to tune it fastidiously and diagnose its conduct. I hope this text will play its half in your journey into the world of machine studying and statistics. From right here on, you sail by yourself 🙂
For those who loved the visualizations and examples, and want to use them in your individual lectures or talks, please do. All supplies and the supply code used to generate them can be found within the GitHub repository – https://github.com/Dreamlone/linear-regression
Sincerely yours, Mikhail Sarafanov


{kind=link}