A step-by-step information to constructing a Thai multilingual sub-word tokenizer primarily based on a BPE algorithm skilled on Thai and English datasets utilizing solely Python

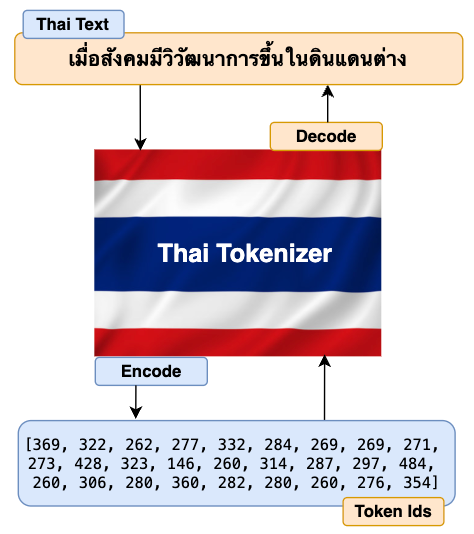
The first job of the Tokenizer is to translate the uncooked enter texts (Thai in our case however might be in any international language) into numbers and go them to the mannequin’s transformers. The mannequin’s transformer then generates output as numbers. Once more, Tokenizer interprets these numbers again to texts which is comprehensible to finish customers. The excessive stage diagram under describes the stream defined above.

Typically, many people are solely fascinated with studying how the mannequin’s transformer structure works underneath the hood. We regularly overlook studying some essential parts similar to tokenizers intimately. Understanding how tokenizer works underneath the hood and having good management of its functionalities offers us good leverage to enhance our mannequin’s accuracy and efficiency.
Much like Tokenizer, a number of the most essential parts of LLM implementation pipelines are Information preprocessing, Analysis, Guardrails/Safety, and Testing/Monitoring. I’d extremely suggest you research extra particulars on these matters. I spotted the significance of those parts solely after I used to be engaged on the precise implementation of my foundational multilingual mannequin ThaiLLM in manufacturing.
Why do you want a Thai tokenizer or every other international language tokenizer?
- Suppose you might be utilizing generic English-based tokenizers to pre-train a multilingual massive language mannequin similar to Thai, Hindi, Indonesian, Arabic, Chinese language, and many others. In that case, your mannequin would possibly not going give an appropriate output that makes good sense on your particular area or use circumstances. Therefore, constructing your individual tokenizer in your alternative of language actually helps make your mannequin’s output way more coherent and comprehensible.
- Constructing your individual tokenizer additionally offers you full management over how complete and inclusive vocabulary you need to construct. In the course of the consideration mechanism, due to complete vocabulary, the token can attend and be taught from extra tokens throughout the restricted context size of the sequence. Therefore it makes studying extra coherent which ultimately helps in higher mannequin inference.
The excellent news is that after you end constructing Thai Tokenizer, you may simply construct a tokenizer in every other language. All of the constructing steps are the identical besides that you just’ll have to coach on the dataset of your alternative of language.
Now that we’ve all the great motive to construct our personal tokenizer. Under are steps to constructing our tokenizer within the Thai language.
- Construct our personal BPE algorithm
- Prepare the tokenizer
- Tokenizer encode and decode perform
- Load and check the tokenizer
Step 1: Construct our personal BPE (Byte Pair Encoding) algorithm:
The BPE algorithm is utilized in many fashionable LLMs similar to Llama, GPT, and others to construct their tokenizer. We will select one in all these LLM tokenizers if our mannequin is predicated on the English language. Since we’re constructing the Thai Tokenizer, the most suitable choice is to create our personal BPE algorithm from scratch and use it to construct our tokenizer. Let’s first perceive how the BPE algorithm works with the assistance of the straightforward stream diagram under after which we’ll begin constructing it accordingly.

The examples within the stream diagram are proven in English to make it simpler to know.
Let’s write code to implement the BPE algorithm for our Thai Tokenizer.
# A easy observe instance to get familiarization with utf-8 encoding to transform strings to bytes.
textual content = "How are you คุณเป็นอย่างไร" # Textual content string in each English and Thai
text_bytes = textual content.encode("utf-8")
print(f"Textual content in byte: {text_bytes}")text_list = record(text_bytes) # Converts textual content bytes to a listing of integer
print(f"Textual content record in integer: {text_list}")
# As I do not need to reinvent the wheel, I shall be referencing a lot of the code block from Andrej Karpathy's GitHub (https://github.com/karpathy/minbpe?tab=readme-ov-file).
# Nonetheless, I will be modifying code blocks particular to constructing our Thai language tokenizer and in addition explaining the codes so as to perceive how every code block works and make it simple once you implement code on your use case later.# This module gives entry to the Unicode Character Database (UCD) which defines character properties for all Unicode characters.
import unicodedata
# This perform returns a dictionary with consecutive pairs of integers and their counts within the given record of integers.
def get_stats(ids, stats=None):
stats = {} if stats is None else stats
# zip perform permits to iterate consecutive objects from given two record
for pair in zip(ids, ids[1:]):
# If a pair already exists within the stats dictionary, add 1 to its worth else assign the worth as 0.
stats[pair] = stats.get(pair, 0) + 1
return stats
# As soon as we discover out the record of consecutive pairs of integers, we'll then exchange these pairs with new integer tokens.
def merge(ids, pair, idx):
newids = []
i = 0
# As we'll be merging a pair of ids, therefore the minimal id within the record ought to be 2 or extra.
whereas i < len(ids):
# If the present id and subsequent id(id+1) exist within the given pair, and the place of id just isn't the final, then exchange the two consecutive id with the given index worth.
if ids[i] == pair[0] and that i < len(ids) - 1 and ids[i+1] == pair[1]:
newids.append(idx)
i += 2 # If the pair is matched, the following iteration begins after 2 positions within the record.
else:
newids.append(ids[i])
i += 1 # Because the present id pair did not match, so begin iteration from the 1 place subsequent within the record.
# Returns the Merged Ids record
return newids
# This perform checks that utilizing 'unicodedata.class' which returns "C" as the primary letter if it's a management character and we'll have to interchange it readable character.
def replace_control_characters(s: str) -> str:
chars = []
for ch in s:
# If the character just isn't distorted (which means the primary letter does not begin with "C"), then append the character to chars record.
if unicodedata.class(ch)[0] != "C":
chars.append(ch)
# If the character is distorted (which means the primary letter has the letter "C"), then exchange it with readable bytes and append to chars record.
else:
chars.append(f"u{ord(ch):04x}")
return "".be a part of(chars)
# A few of the tokens similar to management characters like Escape Characters cannot be decoded into legitimate strings.
# Therefore these should be exchange with readable character similar to �
def render_token(t: bytes) -> str:
s = t.decode('utf-8', errors='exchange')
s = replace_control_characters(s)
return s
The 2 features get_stats and merge outlined above within the code block are the implementation of the BPE algorithm for our Thai Tokenizer. Now that the algorithm is prepared. Let’s write code to coach our tokenizer.
Step 2: Prepare the tokenizer:
Coaching tokenizer entails producing a vocabulary which is a database of distinctive tokens (phrase and sub-words) together with a singular index quantity assigned to every token. We’ll be utilizing the Thai Wiki dataset from the Hugging Face to coach our Thai Tokenizer. Similar to coaching an LLM requires an enormous information, you’ll additionally require quantity of knowledge to coach a tokenizer. You could possibly additionally use the identical dataset to coach the LLM in addition to tokenizer although not necessary. For a multilingual LLM, it’s advisable to make use of each the English and Thai datasets within the ratio of two:1 which is a regular strategy many practitioners comply with.
Let’s start writing the coaching code.
# Import Common Expression
import regex as re # Create a Thai Tokenizer class.
class ThaiTokenizer():
def __init__(self):
# The byte pair ought to be accomplished throughout the associated phrases or sentences that give a correct context. Pairing between unrelated phrases or sentences could give undesirable output.
# To stop this habits, we'll implement the LLama 3 common expression sample to make significant chunks of our textual content earlier than implementing the byte pair algorithm.
self.sample = r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^rnp{L}p{N}]?p{L}+|p{N}{1,3}| ?[^sp{L}p{N}]+[rn]*|s*[rn]+|s+(?!S)|s+"
self.compiled_pattern = re.compile(self.sample)
# Particular tokens are used to supply coherence within the sequence whereas coaching.
# Particular tokens are assigned a singular index quantity and saved in vocabulary.
self.special_tokens = >': 1103,
'<
# Initialize merges with empty dictionary
self.merges = {}
# Initialize the vocab dictionary by calling the perform _build_vocab which is outlined later on this class.
self.vocab = self._build_vocab()
# Tokenizer coaching perform
def prepare(self, textual content, vocab_size):
# Make certain the vocab dimension have to be a minimum of 256 because the utf-8 encoding for the vary 0-255 are identical because the Ascii character.
assert vocab_size >= 256
# Complete variety of merges into the vocabulary.
num_merges = vocab_size - 256
# Step one is to ensure to separate the textual content up into textual content chunks utilizing the sample outlined above.
text_chunks = re.findall(self.compiled_pattern, textual content)
# Every text_chunks shall be utf-8 encoded to bytes after which transformed into an integer record.
ids = [list(ch.encode("utf-8")) for ch in text_chunks]
# Iteratively merge the commonest pairs to create new tokens
merges = {} # (int, int) -> int
vocab = {idx: bytes([idx]) for idx in vary(256)} # idx -> bytes
# Till the entire num_merges is reached, discover the widespread pair of consecutive id within the ids record and begin merging them to create a brand new token
for i in vary(num_merges):
# Rely the variety of occasions each consecutive pair seems
stats = {}
for chunk_ids in ids:
# Passing in stats will replace it in place, including up counts
get_stats(chunk_ids, stats)
# Discover the pair with the very best depend
pair = max(stats, key=stats.get)
# Mint a brand new token: assign it the following accessible id
idx = 256 + i
# Substitute all occurrences of pair in ids with idx
ids = [merge(chunk_ids, pair, idx) for chunk_ids in ids]
# Save the merge
merges[pair] = idx
vocab[idx] = vocab[pair[0]] + vocab[pair[1]]
# Save class variables for use later throughout tokenizer encode and decode
self.merges = merges
self.vocab = vocab
# Perform to return a vocab dictionary combines with merges and particular tokens
def _build_vocab(self):
# The utf-8 encoding for the vary 0-255 are identical because the Ascii character.
vocab = {idx: bytes([idx]) for idx in vary(256)}
# Iterate by means of merge dictionary and add into vocab dictionary
for (p0, p1), idx in self.merges.objects():
vocab[idx] = vocab[p0] + vocab[p1]
# Iterate by means of particular token dictionary and add into vocab dictionary
for particular, idx in self.special_tokens.objects():
vocab[idx] = particular.encode("utf-8")
return vocab
# After coaching is full, use the save perform to avoid wasting the mannequin file and vocab file.
# Mannequin file shall be used to load the tokenizer mannequin for additional use in llm
# Vocab file is only for the aim of human verification
def save(self, file_prefix):
# Writing to mannequin file
model_file = file_prefix + ".mannequin" # mannequin file identify
# Mannequin write begins
with open(model_file, 'w') as f:
f.write("thai tokenizer v1.0n") # write the tokenizer model
f.write(f"{self.sample}n") # write the sample utilized in tokenizer
f.write(f"{len(self.special_tokens)}n") # write the size of particular tokens
# Write every particular token within the particular format like under
for tokens, idx in self.special_tokens.objects():
f.write(f"{tokens} {idx}n")
# Write solely the keys half from the merges dict
for idx1, idx2 in self.merges:
f.write(f"{idx1} {idx2}n")
# Writing to the vocab file
vocab_file = file_prefix + ".vocab" # vocab file identify
# Change the place of keys and values of merge dict and retailer into inverted_merges
inverted_merges = {idx: pair for pair, idx in self.merges.objects()}
# Vocab write begins
with open(vocab_file, "w", encoding="utf-8") as f:
for idx, token in self.vocab.objects():
# render_token perform processes tokens and prevents distorted bytes by changing them with readable character
s = render_token(token)
# If the index of vocab is current in merge dict, then discover its baby index, convert their corresponding bytes in vocab dict and write the characters
if idx in inverted_merges:
idx0, idx1 = inverted_merges[idx]
s0 = render_token(self.vocab[idx0])
s1 = render_token(self.vocab[idx1])
f.write(f"[{s0}][{s1}] -> [{s}] {idx}n")
# If index of vocab just isn't current in merge dict, simply write it is index and the corresponding string
else:
f.write(f"[{s}] {idx}n")
# Perform to load tokenizer mannequin.
# This perform is invoked solely after the coaching is full and the tokenizer mannequin file is saved.
def load(self, model_file):
merges = {} # Initialize merge and special_tokens with empty dict
special_tokens = {} # Initialize special_tokens with empty dict
idx = 256 # Because the vary (0, 255) is already reserved in vocab. So the following index solely begins from 256 and onwards.
# Learn mannequin file
with open(model_file, 'r', encoding="utf-8") as f:
model = f.readline().strip() # Learn the tokenizer model as outlined throughout mannequin file writing
self.sample = f.readline().strip() # Learn the sample utilized in tokenizer
num_special = int(f.readline().strip()) # Learn the size of particular tokens
# Learn all of the particular tokens and retailer in special_tokens dict outlined earlier
for _ in vary(num_special):
particular, special_idx = f.readline().strip().cut up()
special_tokens[special] = int(special_idx)
# Learn all of the merge indexes from the file. Make it a key pair and retailer it in merge dictionary outlined earlier.
# The worth of this key pair can be idx(256) as outlined above and carry on improve by 1.
for line in f:
idx1, idx2 = map(int, line.cut up())
merges[(idx1, idx2)] = idx
idx += 1
self.merges = merges
self.special_tokens = special_tokens
# Create a remaining vocabulary dictionary by combining merge, special_token and vocab (0-255). _build_vocab perform helps to do exactly that.
self.vocab = self._build_vocab()
Step 3: Tokenizer encode and decode perform:
- Tokenizer Encode: The tokenizer encoding perform seems into vocabulary and interprets the given enter texts or prompts into the record of integer IDs. These IDs are then fed into the transformer blocks.
- Tokenizer Decode: The tokenizer decoding perform seems into vocabulary and interprets the record of IDs generated from the transformer’s classifier block into output texts.
Let’s check out the diagram under to have additional readability.

Let’s write code to implement the tokenizer’s encode and decode perform.
# Tokenizer encode perform takes textual content as a string and returns integer ids record
def encode(self, textual content): # Outline a sample to determine particular token current within the textual content
special_pattern = "(" + "|".be a part of(re.escape(ok) for ok in self.special_tokens) + ")"
# Break up particular token (if current) from the remainder of the textual content
special_chunks = re.cut up(special_pattern, textual content)
# Initialize empty ids record
ids = []
# Loop by means of every of elements within the particular chunks record.
for half in special_chunks:
# If the a part of the textual content is the particular token, get the idx of the half from the particular token dictionary and append it to the ids record.
if half in self.special_tokens:
ids.append(self.special_tokens[part])
# If the a part of textual content just isn't a particular token
else:
# Break up the textual content into a number of chunks utilizing the sample we have outlined earlier.
text_chunks = re.findall(self.compiled_pattern, textual content)
# All textual content chunks are encoded individually, then the outcomes are joined
for chunk in text_chunks:
chunk_bytes = chunk.encode("utf-8") # Encode textual content to bytes
chunk_ids = record(chunk_bytes) # Convert bytes to record of integer
whereas len(chunk_ids) >= 2: # chunks ids record have to be a minimum of 2 id to type a byte-pair
# Rely the variety of occasions each consecutive pair seems
stats = get_stats(chunk_ids)
# Some idx pair may be created with one other idx within the merge dictionary. Therefore we'll discover the pair with the bottom merge index to make sure we cowl all byte pairs within the merge dict.
pair = min(stats, key=lambda p: self.merges.get(p, float("inf")))
# Break the loop and return if the pair just isn't current within the merges dictionary
if pair not in self.merges:
break
# Discover the idx of the pair current within the merges dictionary
idx = self.merges[pair]
# Substitute the occurrences of pair in ids record with this idx and proceed
chunk_ids = merge(chunk_ids, pair, idx)
ids.lengthen(chunk_ids)
return ids
# Tokenizer decode perform takes a listing of integer ids and return strings
def decode(self, ids):
# Initialize empty byte record
part_bytes = []
# Change the place of keys and values of special_tokens dict and retailer into inverse_special_tokens
inverse_special_tokens = {v: ok for ok, v in self.special_tokens.objects()}
# Loop by means of idx within the ids record
for idx in ids:
# If the idx is present in vocab dict, get the bytes of idx and append them into part_bytes record
if idx in self.vocab:
part_bytes.append(self.vocab[idx])
# If the idx is present in inverse_special_tokens dict, get the token string of the corresponding idx, convert it to bytes utilizing utf-8 encode after which append it into part_bytes record
elif idx in inverse_special_tokens:
part_bytes.append(inverse_special_tokens[idx].encode("utf-8"))
# If the idx just isn't present in each vocab and particular token dict, throw an invalid error
else:
increase ValueError(f"invalid token id: {idx}")
# Be a part of all the person bytes from the part_byte record
text_bytes = b"".be a part of(part_bytes)
# Convert the bytes to textual content string utilizing utf-8 decode perform. Make certain to make use of "errors=exchange" to interchange distorted characters with readable characters similar to �.
textual content = text_bytes.decode("utf-8", errors="exchange")
return textual content
Step 4: Load and check the tokenizer:
Lastly, right here comes the perfect a part of this text. On this part, we’ll carry out two fascinating duties.
- First, prepare our tokenizer with the Thai Wiki Dataset from the Hugging Face. We now have chosen a small dataset dimension (2.2 MB) to make coaching quicker. Nonetheless, for real-world implementation, you need to select a a lot bigger dataset for higher outcomes. After the coaching is full, we’ll save the mannequin.
- Second, we’ll load the saved tokenizer mannequin and carry out testing the tokenizer’s encode and decode perform.
Let’s dive in.
# Prepare the tokenizerimport time # To caculate the length of coaching completion
# Load coaching uncooked textual content information (thai_wiki dataset) from huggingface. thai_wiki_small.textual content: https://github.com/tamangmilan/thai_tokenizer
texts = open("/content material/thai_wiki_small.txt", "r", encoding="utf-8").learn()
texts = texts.strip()
# Outline vocab dimension
vocab_size = 512
# Initialize a tokenizer mannequin class
tokenizer = ThaiTokenizer()
# Begin prepare a tokenizer
start_time = time.time()
tokenizer.prepare(texts, vocab_size)
end_time = time.time()
# Save tokenizer: you may change path and filename.
tokenizer.save("./fashions/thaitokenizer")
print(f"Complete time to finish tokenizer coaching: {end_time-start_time:.2f} seconds")
# Output: Complete time to finish tokenizer coaching: 186.11 seconds (3m 6s) [Note: Training duration will be longer if vocab_size is bigger and lesser for smaller vocab_size]
# Check the tokenizer# Initialize a tokenizer mannequin class
tokenizer = ThaiTokenizer()
# Load tokenizer mannequin. This mannequin was saved throughout coaching.
tokenizer.load("./fashions/thaitokenizer.mannequin")
# Invoke and confirm the tokenizer encode and decode perform for English Language
eng_texts = "When society developed in numerous lands"
print(f"English Textual content: {eng_texts}")
encoded_ids = tokenizer.encode(eng_texts)
print(f"Encoded Ids: {encoded_ids}")
decoded_texts = tokenizer.decode(encoded_ids)
print(f"Decoded Texts: {decoded_texts}n")
# Invoke and confirm the tokenizer encode and decode perform for Thai Language
thai_texts = "เมื่อสังคมมีวิวัฒนาการขึ้นในดินแดนต่าง"
print(f"Thai Textual content: {thai_texts}")
thai_encoded_ids = tokenizer.encode(thai_texts)
print(f"Encoded Ids: {thai_encoded_ids}")
thai_decoded_texts = tokenizer.decode(thai_encoded_ids)
print(f"Decoded Texts: {thai_decoded_texts}")

Excellent. Our Thai Tokenizer can now efficiently and precisely encode and decode texts in each Thai and English languages.
Have you ever seen that the encoded IDs for English texts are longer than Thai encoded IDs? It is because we’ve solely skilled our tokenizer with the Thai dataset. Therefore the tokenizer is simply capable of construct a complete vocabulary for the Thai language. Since we didn’t prepare with an English dataset, the tokenizer has to encode proper from the character stage which leads to longer encoded IDs. As I’ve talked about earlier than, for multilingual LLM, you need to prepare each the English and Thai datasets with a ratio of two:1. This gives you balanced and high quality outcomes.
And that’s it! We now have now efficiently created our personal Thai Tokenizer from scratch solely utilizing Python. And, I believe that was fairly cool. With this, you may simply construct a tokenizer for any international language. This gives you plenty of leverage whereas implementing your Multilingual LLM.
Thanks rather a lot for studying!
Hyperlink to Google Colab pocket book
References
[1] Andrej Karpathy, Git Hub: Karpthy/minbpe


{kind=link}