
Organizations generate huge quantities of knowledge that’s proprietary to them, and it’s vital to get insights out of the information for higher enterprise outcomes. Generative AI and basis fashions (FMs) play an vital function in creating purposes utilizing a corporation’s information that enhance buyer experiences and worker productiveness.
The FMs are sometimes pretrained on a big corpus of knowledge that’s overtly out there on the web. They carry out nicely at pure language understanding duties comparable to summarization, textual content technology, and query answering on a broad number of matters. Nevertheless, they’ll typically hallucinate or produce inaccurate responses when answering questions that they haven’t been skilled on. To stop incorrect responses and enhance response accuracy, a method referred to as Retrieval Augmented Technology (RAG) is used to offer fashions with contextual information.
On this submit, we offer a step-by-step information for creating an enterprise prepared RAG utility comparable to a query answering bot. We use the Llama3-8B FM for textual content technology and the BGE Massive EN v1.5 textual content embedding mannequin for producing embeddings from Amazon SageMaker JumpStart. We additionally showcase how you should use FAISS as an embeddings retailer and packages comparable to LangChain for interfacing with the parts and run inferences inside a SageMaker Studio pocket book.
SageMaker JumpStart
SageMaker JumpStart is a strong function throughout the Amazon SageMaker ML platform that gives ML practitioners a complete hub of publicly out there and proprietary basis fashions.
Llama 3 overview
Llama 3 (developed by Meta) is available in two parameter sizes—8B and 70B with 8K context size—that may help a broad vary of use circumstances with enhancements in reasoning, code technology, and instruction following. Llama 3 makes use of a decoder-only transformer structure and new tokenizer that gives improved mannequin efficiency with 128K measurement. As well as, Meta improved post-training procedures that considerably diminished false refusal charges, improved alignment, and elevated variety in mannequin responses.
BGE Massive overview
The embedding mannequin BGE Massive stands for BAAI common embedding giant. It’s developed by BAAI and is designed to reinforce retrieval capabilities inside giant language fashions (LLMs). The mannequin helps three retrieval strategies:
- Dense retrieval (BGE-M3)
- Lexical retrieval (LLM Embedder)
- Multi-vector retrieval (BGE Embedding Reranker).
You should utilize the BGE embedding mannequin to retrieve related paperwork after which use the BGE reranker to acquire ultimate outcomes.
On Hugging Face, the Large Textual content Embedding Benchmark (MTEB) is supplied as a leaderboard for various textual content embedding duties. It presently supplies 129 benchmarking datasets throughout 8 completely different duties on 113 languages. The highest textual content embedding fashions from the MTEB leaderboard are made out there from SageMaker JumpStart, together with BGE Massive.
For extra particulars about this mannequin, see the official Hugging Face mode card web page.
RAG overview
Retrieval-Augmented Technology (RAG) is a method that allows the mixing of exterior data sources with FM. RAG includes three predominant steps: retrieval, augmentation, and technology.
First, related content material is retrieved from an exterior data base primarily based on the consumer’s question. Subsequent, this retrieved info is mixed or augmented with the consumer’s authentic enter, creating an augmented immediate. Lastly, the FM processes this augmented immediate, which incorporates each the question and the retrieved contextual info, and generates a response tailor-made to the precise context, incorporating the related data from the exterior supply.
Answer overview
You’ll assemble a RAG QnA system on a SageMaker pocket book utilizing the Llama3-8B mannequin and BGE Massive embedding mannequin. The next diagram illustrates the step-by-step structure of this answer, which is described within the following sections.
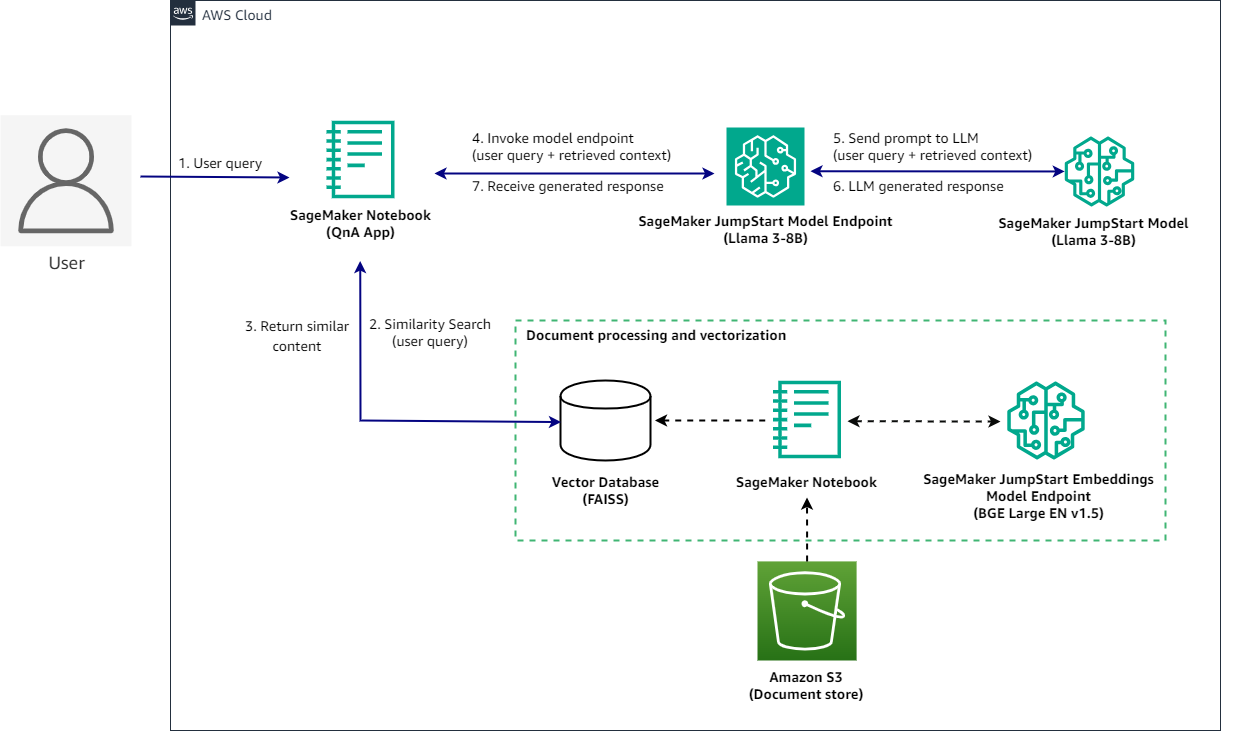
Implementing this answer takes three excessive stage steps: Deploying fashions, information processing and vectorization, and working inferences.
To exhibit this answer, a pattern pocket book is accessible within the GitHub repo.
The pocket book is powered by an ml.t3.medium occasion to exhibit deploying the mannequin as an API endpoint utilizing an SDK by way of SageMaker JumpStart. You should utilize these mannequin endpoints to discover, experiment, and optimize for evaluating superior RAG utility methods utilizing LangChain. We additionally illustrate the mixing of the FAISS embeddings retailer into the RAG workflow, highlighting its function in storing and retrieving embeddings to reinforce the applying’s efficiency.
We may even talk about how you should use LangChain to create efficient and extra environment friendly RAG purposes. LangChain is a Python library designed to construct purposes with LLMs. It supplies a modular and versatile framework for combining LLMs with different parts, comparable to data bases, retrieval programs, and different AI instruments, to create highly effective and customizable purposes.
After every thing is ready up, when a consumer interacts with the QnA utility, the move is as follows:
- The consumer sends a question utilizing the QnA utility.
- The appliance sends the consumer question to the vector database to search out comparable paperwork.
- The paperwork returned as a context are captured by the QnA utility.
- The QnA utility submits a request to the SageMaker JumpStart mannequin endpoint with the consumer question and context returned from the vector database.
- The endpoint sends the request to the SageMaker JumpStart mannequin.
- The LLM processes the request and generates an acceptable response.
- The response is captured by the QnA utility and exhibited to the consumer.
Conditions
To implement this answer, you want the next:
- An AWS account with privileges to create AWS Id and Entry Administration (IAM) roles and insurance policies. For extra info, see Overview of entry administration: Permissions and insurance policies.
- Primary familiarity with SageMaker and AWS companies that help LLMs.
- The Jupyter Notebooks wants ml.t3.medium.
- You want entry to accelerated situations (GPUs) for internet hosting the LLMs. This answer wants entry to a minimal of the next occasion sizes:
- ml.g5.12xlarge for endpoint use when deploying the BGE Massive En v1.5 textual content embedding mannequin
- ml.g5.2xlarge for endpoint use when deploying the Llama-3-8B mannequin endpoint
To extend your quota, seek advice from Requesting a quota improve.
Immediate template for Llama3
Whereas each Llama 2 and Llama 3 are highly effective language fashions which can be optimized for dialogue-based duties, their prompting codecs differ considerably in how they deal with multi-turn conversations, specify roles, and mark message boundaries, reflecting distinct design decisions and trade-offs.
Llama 3 prompting format: Llama 3 employs a structured format designed for multi-turn conversations involving completely different roles (system, consumer, and assistant). It makes use of devoted tokens to explicitly mark roles, message boundaries, and the top of the immediate:
- Placeholder tokens:
{{user_message}}and{{assistant_message}} - Function marking:
<|start_header_id|>{function}<|end_header_id|> - Message boundaries:
<|eot_id|>indicators finish of a message inside a flip. - Immediate Finish Marker:
<|start_header_id|>assistant<|end_header_id|>indicators begin of assistant’s response.
Llama 2 prompting format: Llama 2 makes use of a extra compact illustration with completely different tokens for dealing with conversations:
- Person message enclosure:
[INST][/INST] - Begin and finish of sequence:
- System message enclosure:
<>< > - Message separation:
Key variations:
- Function specification: Llama 3 makes use of a extra express method with devoted tokens, whereas Llama 2 depends on enclosing tags.
- Message boundary marking: Llama 3 makes use of
<|eot_id|>, Llama 2 makes use of - Immediate finish marker: Llama 3 makes use of
<|start_header_id|>assistant<|end_header_id|>, Llama 2 makes use of[/INST] and.
The selection will depend on the use case and integration necessities. Llama 3’s format is extra structured and role-aware and is best fitted to conversational AI purposes with complicated multi-turn conversations. Llama 2’s format, whereas extra compact, could be much less express in dealing with roles and message boundaries.
Implement the answer
To implement the answer, you’ll use the next steps:
- Arrange a SageMaker Studio pocket book
- Deploy fashions on Amazon SageMaker JumpStart
- Arrange Llama3-8b and BGE Massive En v1.5 fashions with LangChain
- Put together information and generate embeddings
- Load paperwork of various form and generate embeddings to create a vector retailer
- Retrieve paperwork to the query utilizing the next approaches from LangChain
- Common Retrieval Chain
- Guardian Doc Retriever Chain
- Put together a immediate that goes as enter to the LLM and presents a solution in a human pleasant method
Arrange a SageMaker Studio pocket book
To comply with the code on this submit:
- Open SageMaker Studio and clone the next GitHub repository.
- Open the pocket book RAG-recipes/llama3-rag-langchain-smjs.ipynb and select the PyTorch 2.0.0 Python 3.10 GPU Optimized picture, Python 3 kernel, and
ml.t3.mediumbecause the occasion kind. - If that is your first time utilizing SageMaker Studio notebooks, see Create or Open an Amazon SageMaker Studio Pocket book.
To arrange the event setting, you want to set up the required Python libraries, as demonstrated within the following code. The instance pocket book supplied consists of these instructions:
After the libraries are written in requirement.txt, set up all of the libraries:
Deploy pretrained fashions
After you’ve imported the required libraries, you’ll be able to deploy the Llama 3 8B Instruct LLM mannequin on SageMaker JumpStart utilizing the SageMaker SDK:
- Import the
JumpStartModelclass from the SageMaker JumpStart library - Specify the mannequin ID for the HuggingFace
Llama 3 8b InstructLLM mannequin, and deploy the mannequin. - Specify the mannequin ID for the HuggingFace BGE Massive EN embedding mannequin and deploy the mannequin.
Arrange fashions with LangChain
For this step, you’ll use the next code to arrange fashions.
- Substitute the endpoint names within the beneath code snippet with the endpoint names which can be deployed in your setting. You may get the endpoint names from predictors created within the earlier part or view the endpoints created by going to SageMaker Studio, left navigation deployments → endpoints and exchange the values for
llm_endpoint_nameandembedding_endpoint_name. - Remodel enter and output information to course of API requires
Llama 3 8B Instructon Amazon SageMaker. - Instantiate the LLM with SageMaker and LangChain
- Remodel enter and output information to course of API requires
BGE Massive Enon SageMaker - Instantiate the embedding mannequin with SageMaker and LangChain
Put together information and generate embeddings
On this instance, you’ll use a number of years of Amazon’s Annual Experiences (SEC filings) for traders as a textual content corpus to carry out QnA on.
- Begin by utilizing the next code to obtain the PDF paperwork from the supplied URLs and create an inventory of metadata for every downloaded doc.
In the event you take a look at the Amazon 10-Ks, the primary 4 pages are all of the very comparable and may skew the responses if they’re stored within the embeddings. This may trigger repetition, take longer to generate embeddings, and may skew your outcomes.
- Within the subsequent step, you’ll take the downloaded information, trim the 10-Ok (first 4 pages) and overwrite them as processed information.
- After downloading, you’ll be able to load the paperwork with the assistance of DirectoryLoader from PyPDF out there beneath LangChain and splitting them into smaller chunks. Word: The retrieved doc or textual content needs to be giant sufficient to include sufficient info to reply a query; however sufficiently small to suit into the LLM immediate. Additionally, the embedding mannequin has a restrict on the size of enter tokens of 512 tokens, which interprets to roughly 2,000 characters. For this use-case, you’re creating chunks of roughly 1,000 characters with an overlap of 100 characters utilizing RecursiveCharacterTextSplitter.
- Earlier than you proceed, take a look at a few of the statistics concerning the doc preprocessing you simply carried out:
- You began with 4 PDF paperwork, which have been cut up into roughly 500 smaller chunks. Now you’ll be able to see how a pattern embedding would appear to be for a kind of chunks.
This may be performed utilizing FAISS implementation inside LangChain which takes enter from the embedding mannequin and the paperwork to create all the vector retailer. Utilizing the Index Wrapper, you’ll be able to summary away a lot of the heavy lifting comparable to creating the immediate, getting embeddings of the question, sampling the related paperwork, and calling the LLM. VectorStoreIndexWrapper.
Reply questions utilizing a LangChain vector retailer wrapper
You utilize the wrapper supplied by LangChain, which wraps across the vector retailer and takes enter from the LLM. This wrapper performs the next steps behind the scenes:
- Inputs the query
- Creates query embedding
- Fetches related paperwork
- Stuffs the paperwork and the query right into a immediate
- Invokes the mannequin with the immediate and generate the reply in a human readable method.
Word: On this instance we’re utilizing Llama 3 8B Instruct because the LLM beneath Amazon SageMaker, this specific mannequin performs finest if the inputs are supplied beneath
<|begin_of_text|><|start_header_id|>system<|end_header_id|>, {{system_message}}, <|eot_id|><|start_header_id|>consumer<|end_header_id|>,{{user_message}}, and the mannequin is requested to generate an output after<|eot_id|><|start_header_id|>assistant<|end_header_id|>.
The next is an instance of the right way to management the immediate in order that the LLM stays grounded and doesn’t reply outdoors the context.
You possibly can ask one other query.
Retrieval QA chain
We’ve proven you a primary methodology to get context-aware solutions. Now, let’s take a look at a extra customizable choice with RetrievalQA. You possibly can customise how fetched paperwork are added to the immediate utilizing the chain_type parameter, management the variety of related paperwork retrieved by altering the okay parameter, and get supply paperwork utilized by the LLM by enabling return_source_documents.RetrievalQA additionally permits offering customized immediate templates particular to the mannequin.
You possibly can then ask a query:
Guardian doc retriever chain
Let’s discover a extra superior RAG choice with ParentDocumentRetriever. It balances storing small chunks for correct embeddings and bigger chunks to protect context. First, a parent_splitter divides paperwork into bigger mum or dad chunks. Then, a child_splitter creates smaller baby chunks. Little one chunks are listed in a vector retailer utilizing embeddings for environment friendly retrieval. To retrieve related information, ParentDocumentRetriever fetches baby chunks from the vector retailer, appears up their mum or dad IDs, and returns corresponding bigger mum or dad chunks, saved in an InMemoryStore. This method balances correct embeddings with contextual info for significant retrieval.
- Typically, the complete paperwork can so giant that you just don’t need to retrieve them as is. In that case, you’ll be able to first cut up the uncooked paperwork into bigger chunks, after which cut up it into smaller chunks. You then index the smaller chunks, however on retrieval you retrieve the bigger chunks (however nonetheless not the complete paperwork).
- Now, initialize the chain utilizing the
ParentDocumentRetriever. Cross the immediate in utilizing thechain_type_kwargsargument. - Begin asking questions:
Clear up
To keep away from incurring pointless prices, while you’re performed, delete the SageMaker endpoints and OpenSearch Service area, both utilizing the next code snippets or the SageMaker JumpStart UI.
To make use of the SageMaker console, full the next steps:
- On the SageMaker console, beneath Inference within the navigation pane, select Endpoints.
- Seek for the embedding and textual content technology endpoints.
- On the endpoint particulars web page, select Delete.
- Select Delete once more to verify.
Conclusion
On this submit, we confirmed you a strong RAG answer utilizing SageMaker JumpStart to deploy the Llama 3 8B Instruct mannequin and the BGE Massive En v1.5 embedding mannequin.
We confirmed you the right way to create a sturdy vector retailer by processing paperwork of assorted codecs and producing embeddings. This vector retailer facilitates retrieving related paperwork primarily based on consumer queries utilizing LangChain’s retrieval algorithms. We demonstrated the flexibility to arrange customized prompts tailor-made for the Llama 3 mannequin, guaranteeing context-aware responses, and introduced these context-specific solutions in a human-friendly method.
This answer highlights the facility of SageMaker JumpStart in deploying cutting-edge fashions and the flexibility of LangChain in creating efficient RAG purposes. By seamlessly integrating these parts, we enabled high-quality, context-specific response technology, enhancing the Llama 3 mannequin’s efficiency throughout pure language processing duties. To discover this answer and embark in your context-aware language technology journey, go to the pocket book within the GitHub repository.
To get began now, try SageMaker JumpStart in SageMaker Studio.
Concerning the Authors
 Supriya Puragundla is a Senior Options Architect at AWS. She has over 15 years of IT expertise in software program improvement, design and structure. She helps key enterprise buyer accounts on their information, generative AI and AI/ML journeys. She is captivated with data-driven AI and the world of depth in ML and generative AI.
Supriya Puragundla is a Senior Options Architect at AWS. She has over 15 years of IT expertise in software program improvement, design and structure. She helps key enterprise buyer accounts on their information, generative AI and AI/ML journeys. She is captivated with data-driven AI and the world of depth in ML and generative AI.
 Dr. Farooq Sabir is a Senior Synthetic Intelligence and Machine Studying Specialist Options Architect at AWS. He holds PhD and MS levels in Electrical Engineering from the College of Texas at Austin and an MS in Pc Science from Georgia Institute of Know-how. He has over 15 years of labor expertise and likewise likes to show and mentor school college students. At AWS, he helps prospects formulate and clear up their enterprise issues in information science, machine studying, laptop imaginative and prescient, synthetic intelligence, numerical optimization, and associated domains. Based mostly in Dallas, Texas, he and his household like to journey and go on lengthy highway journeys.
Dr. Farooq Sabir is a Senior Synthetic Intelligence and Machine Studying Specialist Options Architect at AWS. He holds PhD and MS levels in Electrical Engineering from the College of Texas at Austin and an MS in Pc Science from Georgia Institute of Know-how. He has over 15 years of labor expertise and likewise likes to show and mentor school college students. At AWS, he helps prospects formulate and clear up their enterprise issues in information science, machine studying, laptop imaginative and prescient, synthetic intelligence, numerical optimization, and associated domains. Based mostly in Dallas, Texas, he and his household like to journey and go on lengthy highway journeys.
 Marco Punio is a Sr. Specialist Options Architect centered on generative AI technique, utilized AI options, and conducting analysis to assist prospects hyperscale on AWS. Marco is predicated in Seattle, WA, and enjoys writing, studying, exercising, and constructing purposes in his free time.
Marco Punio is a Sr. Specialist Options Architect centered on generative AI technique, utilized AI options, and conducting analysis to assist prospects hyperscale on AWS. Marco is predicated in Seattle, WA, and enjoys writing, studying, exercising, and constructing purposes in his free time.
 Niithiyn Vijeaswaran is a Options Architect at AWS. His space of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s diploma in Pc Science and Bioinformatics. Niithiyn works intently with the Generative AI GTM group to allow AWS prospects on a number of fronts and speed up their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys gathering sneakers.
Niithiyn Vijeaswaran is a Options Architect at AWS. His space of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s diploma in Pc Science and Bioinformatics. Niithiyn works intently with the Generative AI GTM group to allow AWS prospects on a number of fronts and speed up their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys gathering sneakers.
 Yousuf Athar is a Options Architect at AWS specializing in generative AI and AI/ML. With a Bachelor’s diploma in Info Know-how and a focus in Cloud Computing, he helps prospects combine superior generative AI capabilities into their programs, driving innovation and aggressive edge. Outdoors of labor, Yousuf likes to journey, watch sports activities, and play soccer.
Yousuf Athar is a Options Architect at AWS specializing in generative AI and AI/ML. With a Bachelor’s diploma in Info Know-how and a focus in Cloud Computing, he helps prospects combine superior generative AI capabilities into their programs, driving innovation and aggressive edge. Outdoors of labor, Yousuf likes to journey, watch sports activities, and play soccer.
 Gaurav Parekh is an AWS Options Architect specializing in Generative AI, Analytics and Networking applied sciences.
Gaurav Parekh is an AWS Options Architect specializing in Generative AI, Analytics and Networking applied sciences.



{kind=link}