
Scaling reinforcement studying from tabular strategies to massive areas

Reinforcement studying is a website in machine studying that introduces the idea of an agent studying optimum methods in complicated environments. The agent learns from its actions, which end in rewards, based mostly on the surroundings’s state. Reinforcement studying is a difficult subject and differs considerably from different areas of machine studying.
What’s exceptional about reinforcement studying is that the identical algorithms can be utilized to allow the agent adapt to fully completely different, unknown, and complicated circumstances.
Be aware. To completely perceive the ideas included on this article, it’s extremely advisable to be aware of ideas mentioned in earlier articles.
Reinforcement Studying
Up till now, we have now solely been discussing tabular reinforcement studying strategies. On this context, the phrase “tabular” signifies that each one doable actions and states might be listed. Due to this fact, the worth perform V or Q is represented within the type of a desk, whereas the final word purpose of our algorithms was to search out that worth perform and use it to derive an optimum coverage.
Nevertheless, there are two main issues concerning tabular strategies that we have to deal with. We’ll first have a look at them after which introduce a novel strategy to beat these obstacles.
This text is predicated on Chapter 9 of the e book “Reinforcement Studying” written by Richard S. Sutton and Andrew G. Barto. I extremely respect the efforts of the authors who contributed to the publication of this e book.
1. Computation
The primary side that needs to be clear is that tabular strategies are solely relevant to issues with a small variety of states and actions. Allow us to recall a blackjack instance the place we utilized the Monte Carlo methodology partially 3. Regardless of the very fact that there have been solely 200 states and a couple of actions, we bought good approximations solely after executing a number of million episodes!
Think about what colossal computations we would wish to carry out if we had a extra complicated downside. For instance, if we have been coping with RGB photographs of dimension 128 × 128, then the full variety of states can be 3 ⋅ 256 ⋅ 256 ⋅ 128 ⋅ 128 ≈ 274 billion. Even with fashionable technological developments, it will be completely unattainable to carry out the mandatory computations to search out the worth perform!

In actuality, most environments in reinforcement studying issues have an enormous variety of states and doable actions that may be taken. Consequently, worth perform estimation with tabular strategies is now not relevant.
2. Generalization
Even when we think about that there aren’t any issues concerning computations, we’re nonetheless more likely to encounter states which might be by no means visited by the agent. How can normal tabular strategies consider v- or q-values for such states?

This text will suggest a novel strategy based mostly on supervised studying that can effectively approximate worth features regardless the variety of states and actions.
The concept of value-function approximation lies in utilizing a parameterized vector w that may approximate a worth perform. Due to this fact, to any extent further, we’ll write the worth perform v̂ as a perform of two arguments: state s and vector w:

Our goal is to search out v̂ and w. The perform v̂ can take numerous varieties however the most typical strategy is to make use of a supervised studying algorithm. Because it seems, v̂ is usually a linear regression, resolution tree, or perhaps a neural community. On the identical time, any state s might be represented as a set of options describing this state. These options function an enter for the algorithm v̂.
Why are supervised studying algorithms used for v̂?
It’s recognized that supervised studying algorithms are excellent at generalization. In different phrases, if a subset (X₁, y₁) of a given dataset D for coaching, then the mannequin is anticipated to additionally carry out effectively for unseen examples X₂.
On the identical time, we highlighted above the generalization downside for reinforcement studying algorithms. On this state of affairs, if we apply a supervised studying algorithm, then we should always now not fear about generalization: even when a mannequin has not seen a state, it will nonetheless attempt to generate an excellent approximate worth for it utilizing accessible options of the state.
Instance
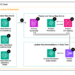
Allow us to return to the maze and present an instance of how the worth perform can look. We’ll characterize the present state of the agent by a vector consisting of two elements:
- x₁(s) is the gap between the agent and the terminal state;
- x₂(s) is the variety of traps positioned across the agent.
For v, we will use the scalar product of s and w. Assuming that the agent is presently positioned at cell B1, the worth perform v̂ will take the shape proven within the picture under:

Difficulties
With the offered thought of supervised studying, there are two principal difficulties we have now to handle:
1. Discovered state values are now not decoupled. In all earlier algorithms we mentioned, an replace of a single state didn’t have an effect on every other states. Nevertheless, now state values rely on vector w. If the vector w is up to date in the course of the studying course of, then it can change the values of all different states. Due to this fact, if w is adjusted to enhance the estimate of the present state, then it’s possible that estimations of different states will change into worse.

2. Supervised studying algorithms require targets for coaching that aren’t accessible. We wish a supervised algorithm to study the mapping between states and true worth features. The issue is that we do not need any true state values. On this case, it isn’t even clear methods to calculate a loss perform.
State distribution
We can not fully do away with the primary downside, however what we will do is to specify how a lot every state is vital to us. This may be executed by making a state distribution that maps each state to its significance weight.
This data can then be taken into consideration within the loss perform.
More often than not, μ(s) is chosen proportionally to how typically state s is visited by the agent.
Loss perform
Assuming that v̂(s, w) is differentiable, we’re free to decide on any loss perform we like. All through this text, we can be wanting on the instance of the MSE (imply squared error). Other than that, to account for the state distribution μ(s), each error time period is scaled by its corresponding weight:

Within the proven components, we have no idea the true state values v(s). Nonetheless, we will overcome this difficulty within the subsequent part.
Goal
After having outlined the loss perform, our final purpose turns into to search out the very best vector w that can decrease the target VE(w). Ideally, we want to converge to the worldwide optimum, however in actuality, essentially the most complicated algorithms can assure convergence solely to an area optimum. In different phrases, they will discover the very best vector w* solely in some neighbourhood of w.

Regardless of this truth, in lots of sensible instances, convergence to an area optimum is usually sufficient.
Stochastic-gradient strategies are among the many hottest strategies to carry out perform approximation in reinforcement studying.
Allow us to assume that on iteration t, we run the algorithm by way of a single state instance. If we denote by wₜ a weight vector at step t, then utilizing the MSE loss perform outlined above, we will derive the replace rule:

We all know methods to replace the load vector w however what can we use as a goal within the components above? To start with, we’ll change the notation slightly bit. Since we can not receive precise true values, as an alternative of v(S), we’re going to use one other letter U, which is able to point out that true state values are approximated.

The methods the state values might be approximated are mentioned within the following sections.
Gradient Monte Carlo
Monte Carlo is the only methodology that can be utilized to approximate true values. What makes it nice is that the state values computed by Monte Carlo are unbiased! In different phrases, if we run the Monte Carlo algorithm for a given surroundings an infinite variety of instances, then the averaged computed state values will converge to the true state values:

Why will we care about unbiased estimations? In accordance with idea, if goal values are unbiased, then SGD is assured to converge to an area optimum (underneath acceptable studying charge circumstances).
On this method, we will derive the Gradient Monte Carlo algorithm, which makes use of anticipated returns Gₜ as values for Uₜ:

As soon as the entire episode is generated, all anticipated returns are computed for each state included within the episode. The respective anticipated returns are used in the course of the weight vector w replace. For the subsequent episode, new anticipated returns can be calculated and used for the replace.
As within the unique Monte Carlo methodology, to carry out an replace, we have now to attend till the top of the episode, and that may be an issue in some conditions. To beat this drawback, we have now to discover different strategies.
Bootstrapping
At first sight, bootstrapping looks as if a pure various to gradient Monte Carlo. On this model, each goal is calculated utilizing the transition reward R and the goal worth of the subsequent state (or n steps later within the normal case):

Nevertheless, there are nonetheless a number of difficulties that have to be addressed:
- Bootstrapped values are biased. Firstly of an episode, state values v̂ and weights w are randomly initialized. So it’s an apparent incontrovertible fact that on common, the anticipated worth of Uₜ won’t approximate true state values. As a consequence, we lose the assure of converging to an area optimum.
- Goal values rely on the load vector. This side isn’t typical in supervised studying algorithms and may create problems when performing SGD updates. Consequently, we now not have the chance to calculate gradient values that may result in the loss perform minimization, in response to the classical SGD idea.
The excellent news is that each of those issues might be overcome with semi-gradient strategies.
Semi-gradient strategies
Regardless of dropping vital convergence ensures, it seems that utilizing bootstrapping underneath sure constraints on the worth perform (mentioned within the subsequent part) can nonetheless result in good outcomes.

As we have now already seen in half 5, in comparison with Monte Carlo strategies, bootstrapping gives sooner studying, enabling it to be on-line and is often most well-liked in observe. Logically, these benefits additionally maintain for gradient strategies.
Allow us to have a look at a selected case the place the worth perform is a scalar product of the load vector w and the function vector x(s):

That is the only type the worth perform can take. Moreover, the gradient of the scalar product is simply the function vector itself:

Consequently, the replace rule for this case is very simple:

The selection of the linear perform is especially engaging as a result of, from the mathematical viewpoint, worth approximation issues change into a lot simpler to investigate.
As a substitute of the SGD algorithm, it is usually doable to make use of the methodology of least squares.
Linear perform in gradient Monte Carlo
The selection of the linear perform makes the optimization downside convex. Due to this fact, there is just one optimum.

On this case, concerning gradient Monte Carlo (if its studying charge α is adjusted appropriately), an vital conclusion might be made:
Because the gradient Monte Carlo methodology is assured to converge to an area optimum, it’s routinely assured that the discovered native optimum can be world when utilizing the linear worth approximation perform.
Linear perform in semi-gradient strategies
In accordance with idea, underneath the linear worth perform, gradient one-step TD algorithms additionally converge. The one subtlety is that the convergence level (which known as the TD fastened level) is often positioned close to the worldwide optimum. Regardless of this, the approximation high quality with the TD fastened level if typically sufficient in most duties.
On this article, we have now understood the scalability limitations of normal tabular algorithms. This led us to the exploration of value-function approximation strategies. They permit us to view the issue from a barely completely different angle, which elegantly transforms the reinforcement studying downside right into a supervised machine studying job.
The earlier information of Monte Carlo and bootstrapping strategies helped us elaborate their respective gradient variations. Whereas gradient Monte Carlo comes with stronger theoretical ensures, bootstrapping (particularly the one-step TD algorithm) remains to be a most well-liked methodology on account of its sooner convergence.
All photographs except in any other case famous are by the writer.


{kind=link}