
On this article, you’ll learn to consider AI brokers rigorously by inspecting their full execution course of fairly than solely their last outputs.
Subjects we are going to cowl embrace:
- Why agent analysis differs from conventional language mannequin analysis, and the place brokers fail throughout the reasoning and motion layers.
- Methods to grade brokers with deterministic code-based checks and model-based judges, matched to the kind of agent you might be constructing.
- Methods to account for non-determinism utilizing metrics like go@okay and go^okay, and tips on how to prolong analysis from growth into manufacturing monitoring.

The Roadmap to Mastering AI Agent Analysis
Let’s not waste any extra time.
Introduction
Many groups constructing AI brokers nonetheless consider them the identical means they consider massive language fashions: run just a few duties, examine the ultimate output, and assume every little thing is working. That strategy usually misses the failures that matter most. The mannequin could choose an inappropriate device or generate incorrect device arguments, whereas the agent system could deal with device failures poorly or comply with an inefficient sequence of actions. Evaluating solely the ultimate response usually makes it troublesome to establish the place these failures occurred.
Agent analysis addresses this hole. Somewhat than focusing solely on outcomes, it examines the complete execution course of — how an agent causes, makes selections, makes use of instruments, and adapts as a activity unfolds. This offers a extra correct image of reliability, effectivity, and general efficiency, serving to groups establish points earlier than they attain manufacturing.
The ideas lined on this article kind the inspiration of a scientific strategy to measuring and enhancing agent efficiency.
Step 1: Understanding Why Agent Analysis Is Vital
The intuition when an agent fails is to deal with it as a prompting downside: the system immediate must be clearer. Typically that’s true. Extra usually the failure is a measurement downside: the eval was not designed to catch what broke.
AI brokers function throughout layers, and people layers could fail independently:
- The reasoning layer — powered by the language mannequin — handles planning, activity decomposition, and gear choice.
- The motion layer — powered by device calls and exterior system responses — handles execution.
An agent can cause appropriately about what to do after which name the proper device with malformed arguments. Treating agent analysis as a single end-to-end accuracy test misses each failure surfaces.
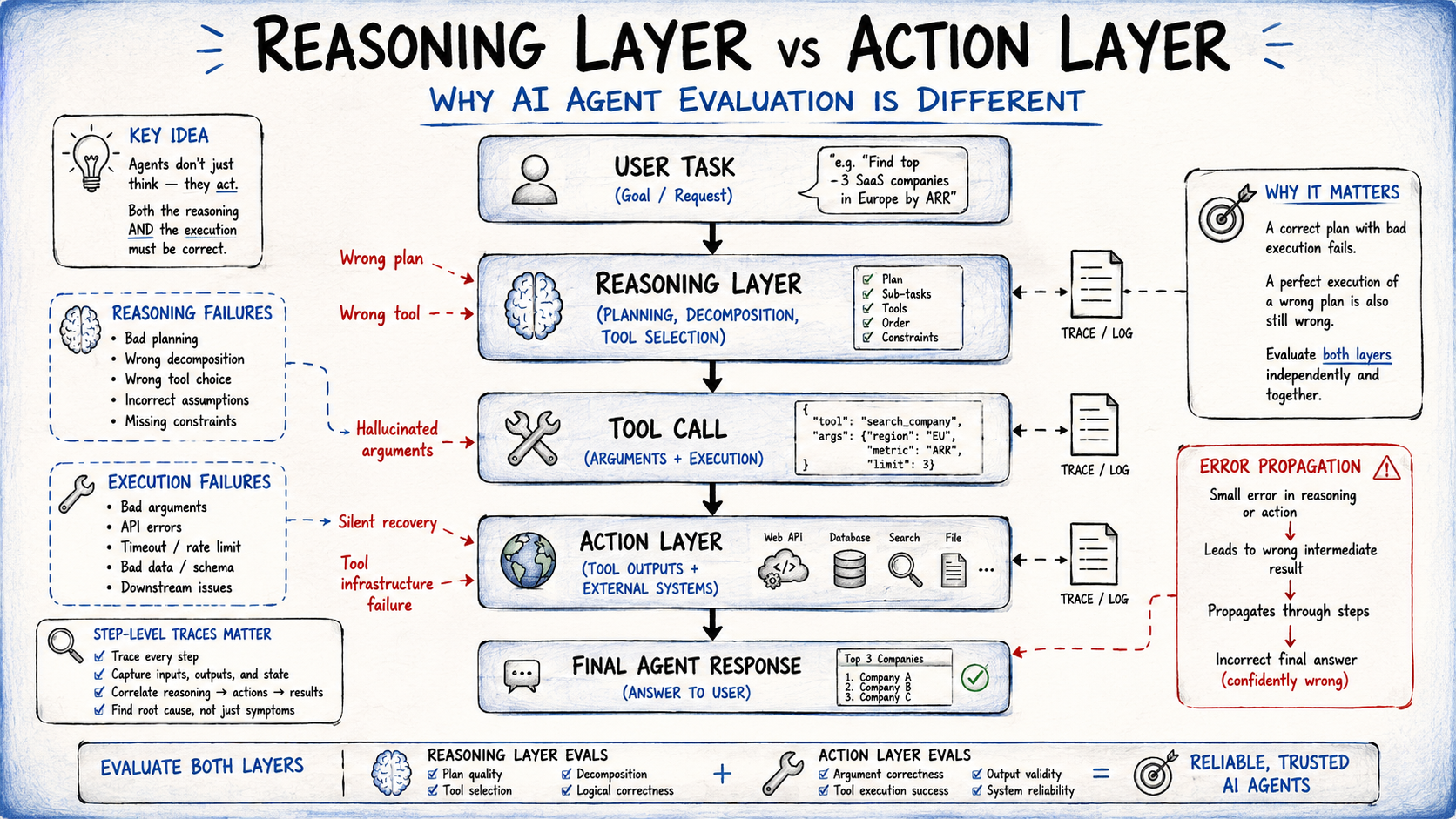
Reasoning vs Motion Layer
Helpful agent analysis runs at two scopes:
A activity completion charge of 80% tells you nothing about whether or not the 20% failure comes from unhealthy planning, incorrect device choice, incorrect arguments, or device infrastructure failures. Step-level traces — logs capturing every device name, its arguments, its end result, and the following mannequin determination — are what make that prognosis attainable. With out traces, debugging a manufacturing failure is guesswork.
Step 2: Defining What Agent Analysis Success Appears to be like Like
Analysis is barely pretty much as good as its success standards. A well-formed eval activity is one the place two area specialists, working independently, would attain the identical go/fail verdict.
Begin with unambiguous activity specs paired with reference options — known-correct outputs that go all graders. They show the duty is solvable and confirm that grading logic is appropriately configured.
You want the next outlined for evals earlier than any grading runs:
- The duty: what inputs the agent receives, what it’s anticipated to do, and what the setting appears like getting into
- The success standards: not simply the ultimate reply, however the intermediate outcomes that matter: Was the proper device referred to as? Was the state appropriately up to date? Was the response grounded within the retrieved context?
- The destructive circumstances: one-sided evals create one-sided optimization. Balanced datasets — protecting each when a habits ought to happen and when it shouldn’t — forestall brokers that over-trigger or under-trigger on a functionality
A set of well-specified duties drawn from actual utilization failures is a greater place to begin than ready for the right dataset. Evals get more durable to construct the longer you wait.
Step 3: Grading the Agent Motion Layer with Code-Primarily based Checks
Deterministic graders — code that checks particular circumstances with out model-in-the-loop judgment — are the quickest, most cost-effective, and most reproducible possibility in any agent eval stack. For the motion layer, they need to at all times be the start line:
- Instrument name verification: whether or not the agent referred to as the proper device within the right sequence
- Argument validation: whether or not inputs have right sorts, required parameters, and legitimate values
- Final result verification: whether or not the setting ends within the anticipated state
- Transcript evaluation: variety of turns, tokens consumed, and latency
These are sometimes quick, goal, and simple to debug, however brittle. A grader checking for “confirmation_code”: “CONF-789” will miss an accurate response that codecs the identical knowledge in a different way.
Step 4: Grading Agent Reasoning and Output High quality with Mannequin-Primarily based Judges
Some agent analysis dimensions resist deterministic checking — output high quality, tone, faithfulness to retrieved context, acceptable empathy. For these, a language mannequin used as a decide or LLM-as-a-Choose is the proper device: versatile and able to dealing with open-ended output, however introducing non-determinism and calibration drift that code-based graders don’t have.
The next practices preserve model-based graders dependable:
Write structured rubrics. “Consider whether or not the response is useful” produces noise. A rubric specifying that the response should deal with the consumer’s query, floor claims in retrieved context, and keep away from out-of-scope recommendations produces a sign. Grade every dimension with a separate, remoted judgment.
Calibrate towards human judgment commonly. LLM-as-judge accuracy needs to be checked towards a pattern graded by area specialists. The place divergence exhibits up, the rubric is sort of at all times the issue. Give the grader an specific “Can’t decide” choice to keep away from compelled judgments on ambiguous circumstances.
Construct in partial credit score for multi-component duties. A help agent that appropriately identifies the issue and verifies the client however fails to course of the refund is meaningfully higher than one which fails on the 1st step. Binary go/fail hides the place the agent is definitely breaking down.
Step 5: Matching Agent Analysis Technique to Agent Sort
Grading methods apply broadly, however agent kind determines which graders carry probably the most weight and which failure modes to prioritize.
Coding brokers write, check, and debug code. Software program is basically deterministic: does the code run, do the assessments go, does the repair shut the difficulty with out breaking present performance? Benchmarks like SWE-bench Verified and Terminal-Bench comply with this go/fail strategy, supplemented by rubric-based high quality checks for safety, readability, and edge case dealing with.
Conversational brokers work together with customers throughout help, gross sales, and training workflows. The standard of the interplay is a part of what’s being evaluated — not solely whether or not the ticket was resolved, however whether or not the tone was acceptable and the decision clearly defined. This requires a second language mannequin simulating the consumer; τ-bench fashions precisely this, with graders assessing each activity completion and interplay high quality throughout turns.
Analysis brokers collect and synthesize data throughout sources. Groundedness checks confirm claims are supported by retrieved sources, protection checks outline what a great reply should embrace, and supply high quality checks affirm the agent consulted authoritative materials.
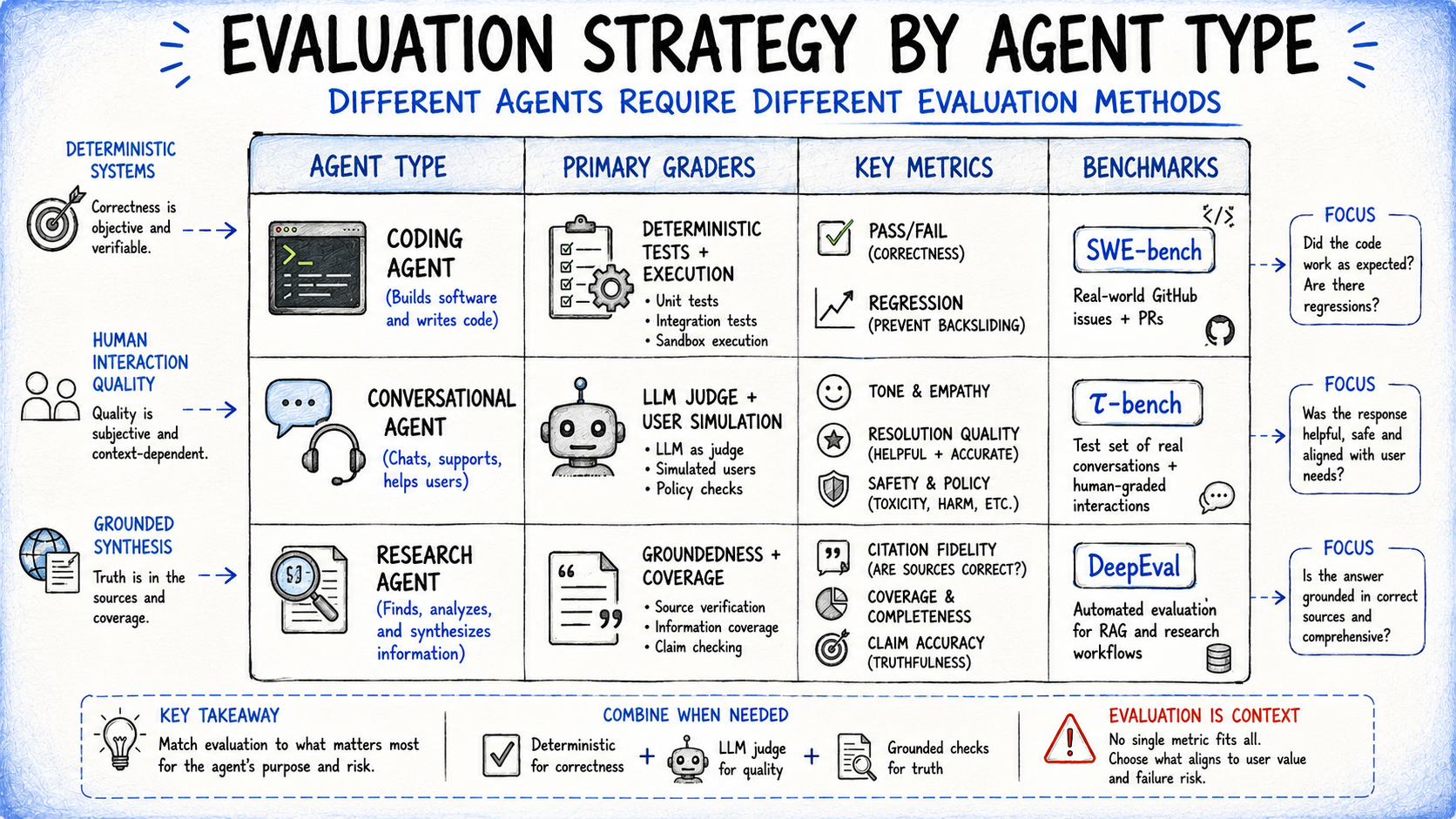
Matching Agent Analysis Technique to Agent Sort
Step 6: Accounting for Non-Determinism in Agent Analysis Outcomes
Agent habits varies between runs; the identical activity, similar inputs, similar agent can produce totally different device choices, reasoning paths, and outcomes. Single-trial analysis can due to this fact be deceptive, because it hides variability that straightforward accuracy metrics fail to seize.
This can be a direct consequence of non-determinism in agent programs. Stochastic mannequin outputs, device latency, partial failures, and adaptive decision-making all introduce variability throughout runs. Consequently, evaluating an agent requires reasoning over distributions of outcomes fairly than a single execution hint.
To account for this variability, metrics like go@okay and go^okay are generally used:
- go@okay: the chance that at the very least one in every of okay impartial trials succeeds, helpful when a number of makes an attempt are acceptable
- go^okay: the chance that each one okay trials succeed, essential when each interplay should be dependable
For instance, an agent with a 75 % single-trial success charge succeeds on all three makes an attempt solely about 42 % of the time, displaying how rapidly reliability degrades throughout repeated runs.
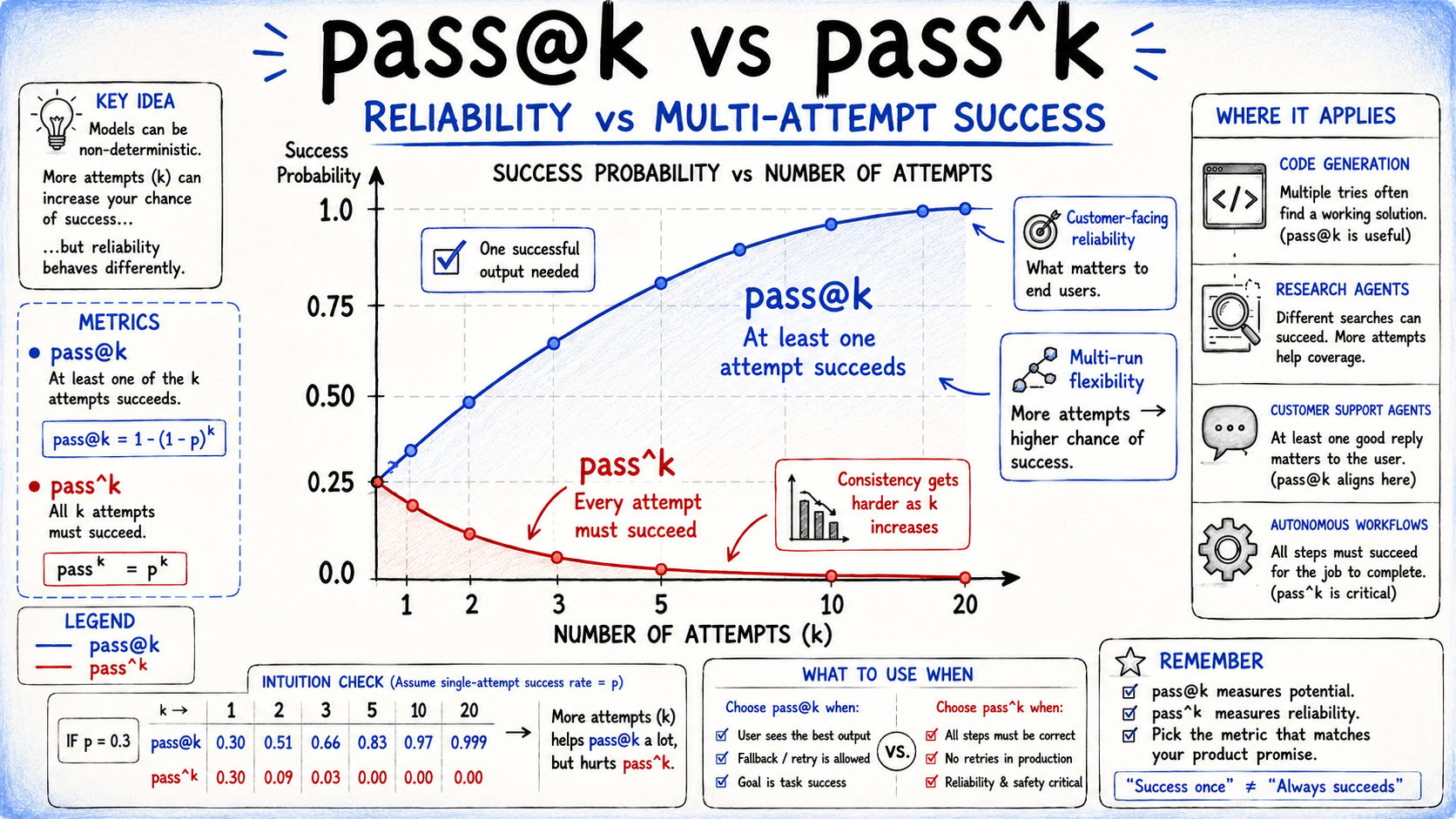
go@okay and go^okay
The selection between these metrics is in the end a product determination fairly than a purely technical one. If just one right end result is required, go@1 or go@okay is helpful. If each interplay should succeed constantly, go^okay is the extra significant measure.
Step 7: Separating Agent Functionality Evals from Regression Suites
Functionality evals are designed to reply a forward-looking query: what can this agent do this it couldn’t do earlier than? Due to that, they need to start with comparatively low go charges and deal with duties which can be nonetheless difficult for the system. When a functionality eval reaches very excessive scores — say 90 % — it’s usually now not measuring functionality, however merely confirming reliability on already solved issues.
Regression evals serve a unique goal. They ask whether or not the agent can nonetheless carry out every little thing it beforehand might. These assessments ought to run near 100% and act as a safeguard towards efficiency regressions. Any significant drop in rating is a sign that one thing has damaged and needs to be investigated earlier than launch.
Over time, functionality evals naturally grow to be simpler for the agent. As go charges rise and efficiency stabilizes, these duties may be promoted into the regression suite. Nonetheless, as soon as a set totally saturates, it turns into much less delicate to actual enhancements — that means significant progress could seem as noise fairly than sign. Because of this, new and more difficult evals needs to be launched earlier than the prevailing suite saturates, not after.
Step 8: Extending Agent Analysis into Manufacturing Monitoring
Growth evals seize what you anticipate to fail; manufacturing reveals what really does. Actual customers introduce inputs, edge circumstances, and contexts that not often seem in artificial check suites, making manufacturing monitoring a obligatory extension of analysis.
A whole analysis system combines a number of complementary alerts:
| Technique | What it Captures |
|---|---|
| Automated evals | Run on each commit, protecting identified failure modes at scale earlier than customers are impacted. Can create false confidence when real-world utilization diverges from the check distribution. |
| Manufacturing monitoring | Tracks latency, error charges, device failures, and token utilization. Surfaces points artificial assessments miss, however usually solely after they happen. |
| Consumer suggestions | Highlights circumstances the place the agent appears right by metrics however fails the consumer’s intent. Sparse and self-selected, however usually extremely informative. |
| Handbook transcript evaluate | Supplies qualitative perception into reasoning, device use, and determination paths, and helps validate whether or not automated graders are measuring the proper behaviors. |
Collectively, these layers kind a extra full view of agent efficiency in apply. Step-level traces — capturing reasoning, device calls, arguments, outcomes, and selections at every level within the loop — are the infrastructure that makes all of this work. Instruments like LangSmith, Arize Phoenix, Braintrust, and Langfuse present tracing and eval frameworks;Harbor and DeepEval deal with the harness layer.
Abstract of Key Agent Analysis Steps
Right here’s a fast overview of the steps we’ve mentioned:
| Step | Why it Issues |
|---|---|
| Agent analysis as a definite downside | Brokers fail throughout reasoning and motion layers. Finish-to-end accuracy can disguise each forms of failures. |
| Defining success earlier than measuring it | Clear specs and reference outputs scale back noise and make analysis metrics extra significant. |
| Code-based graders for the motion layer | Deterministic checks rapidly establish device utilization, argument, and execution errors. |
| Mannequin-based judges for reasoning and output high quality | LLM-based grading captures nuanced qualities equivalent to correctness, faithfulness, and tone. |
| Analysis technique by agent kind | Totally different brokers fail in several methods, requiring analysis strategies tailor-made to every use case. |
| go@okay and go^okay for non-determinism | Single-run outcomes may be deceptive. Metrics ought to replicate whether or not one or all makes an attempt should succeed. |
| Functionality vs regression evals | Functionality evaluations measure progress, whereas regression evaluations shield present efficiency. |
| Extending analysis into manufacturing | Monitoring, consumer suggestions, and transcript evaluations reveal real-world failures that offline evaluations could miss. |
As a subsequent step, learn Anthropic’s Demystifying evals for AI brokers information, particularly the part Going from zero to at least one: a roadmap to nice evals for brokers.


{kind=link}