
Organizations course of thousands and thousands of paperwork every day, from insurance coverage claims and invoices to authorized contracts and medical information. Whereas conventional optical character recognition (OCR) options extract textual content, they will’t perceive context, relationships, or that means embedded inside advanced paperwork. This limitation creates bottlenecks that require handbook intervention, growing processing time and prices whereas introducing potential errors.
Amazon Bedrock Knowledge Automation (BDA), supplies a unified API expertise for extracting significant insights from multimodal content material, together with paperwork, photographs, movies, and audio information. Not like conventional options that target textual content extraction, BDA understands doc context, validates extracted knowledge, and supplies confidence scores for accuracy. BDA processes paperwork by means of a pipeline that automates advanced duties together with doc classification, extraction, normalization, and validation. When a doc is submitted, BDA mechanically splits it alongside logical boundaries, classifies every part into applicable doc varieties, and matches them to the right processing blueprints. This clever routing removes the necessity for handbook doc sorting and orchestration of a number of AI fashions. The service helps a variety of file codecs, with assist for as much as 3,000 pages and 500 MB per API request, making it appropriate for processing numerous doc varieties at scale.
This publish outlines the event of a cheap and scalable clever doc processing pipeline on AWS, powered by Amazon Bedrock and its options. BDA is a managed service inside Amazon Bedrock that automates the extraction of insights from paperwork. We show how BDA extracts and analyzes doc content material, whereas Strands Agent hosted on Amazon Bedrock AgentCore Runtime coordinate specialised processing duties, and Amazon Bedrock Data Base allow contextual understanding throughout a number of paperwork. By combining these capabilities inside a unified structure, organizations can remodel their doc processing workflows with minimal improvement effort.
Resolution overview
Our clever doc processing pipeline combines generative AI with orchestrated workflows to mechanically extract, analyze visible plots, graphs, and charts, and derive insights from paperwork whereas sustaining context and relationships throughout a number of knowledge sources.The answer processes paperwork by means of 4 built-in layers:
- Enter processing layer: Doc add triggers processing orchestration and state machine coordination.
- Extraction and storage layer: Uncooked textual content and desk extraction, picture and visible component evaluation, and scalable knowledge integration.
- Intelligence layer: Data base ingestion with semantic search, multimodal basis mannequin (FM) evaluation, and huge language mannequin (LLM)-powered interpretation.
- Agentic coordination layer: Coordinator agent and specialised job brokers.
Structure elements
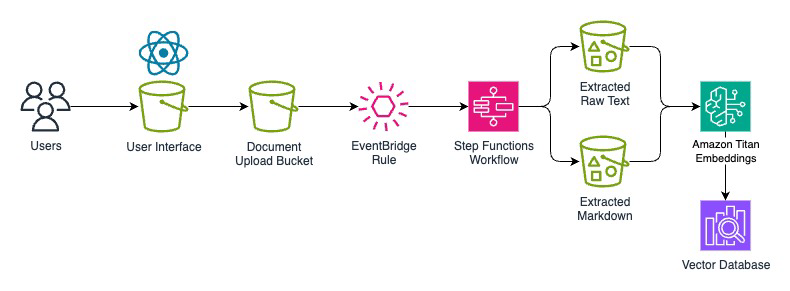
Enter processing layer
The enter processing layer kinds the inspiration of this answer. This layer manages the preliminary reception and routing of incoming paperwork. A Doc Add Triggers processing workflows when paperwork arrive in designated Amazon Easy Storage Service (Amzon S3) buckets, supporting numerous codecs together with PDFs, and scanned paperwork (in PDF).
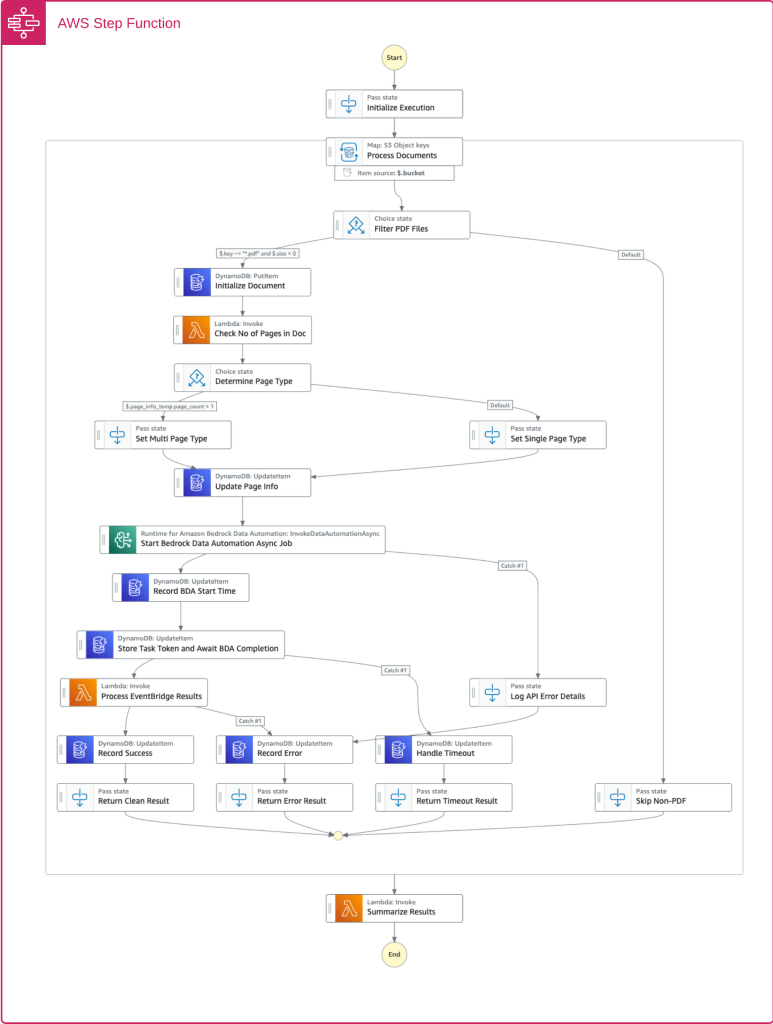
BDA serves because the core extraction engine within the enter processing layer, dealing with doc splitting, classification, and content material extraction by means of a unified API. AWS Step Capabilities orchestrates the workflow to maximise the capabilities of BDA within the Extraction and Storage Layer, offering operational visibility and management all through the method. Right here’s the detailed orchestration circulate:
- Doc Ingestion: Recordsdata arrive in S3 buckets in numerous codecs. Every format is processed by means of the unified API, eradicating the necessity for format-specific preprocessing.
- Metadata Recording: The workflow information doc metadata in Amazon DynamoDB for monitoring, audit trails, and reporting. This contains file kind, measurement, submission time, and processing standing.
- Web page Depend Evaluation: The workflow checks web page depend to enhance processing methods. BDA mechanically handles doc splitting and might course of paperwork as much as 3,000 pages. The web page depend examine in Step Capabilities helps with setting applicable timeout values for the asynchronous jobs and monitoring and alerting for unusually massive paperwork.
- BDA Processing Invocation: The workflow launches an asynchronous BDA job utilizing the InvokeDataAutomationAsync API. BDA then mechanically:
- Splits paperwork alongside logical boundaries (as much as 20 pages per break up).
- Classifies every part into doc varieties.
- Matches paperwork to applicable blueprints (if utilizing customized output). Blueprints are artifacts configured forward of time that outline the extraction logic and should be arrange earlier than BDA processing.
- Extracts all content material together with textual content, tables, kinds, and visible components.
- Asynchronous Processing with Process Tokens: The workflow shops a job token and waits for BDA job completion. This sample allows environment friendly useful resource utilization and permits processing of hundreds of paperwork concurrently.
- Error Dealing with and Routing: Complete error dealing with manages totally different eventualities together with profitable processing, validation errors, timeouts, and unsupported file varieties, making certain no doc is misplaced and all points are logged for overview.
This orchestration strategy supplies a extremely scalable serverless pipeline for automated doc evaluation with applicable branching logic and exception administration all through every processing stage.
Extraction and storage layer
This layer is central to this answer, the place BDA serves because the core engine for reworking uncooked content material into structured, actionable knowledge. We offer extra particulars within the following part.
Amazon Bedrock Knowledge Automation serves as the first processing engine, providing two versatile output choices:
- Commonplace output – Supplies generally required data based mostly on knowledge kind, together with doc summaries, extracted textual content in studying order, desk and determine captions, and generative insights. Commonplace output might be personalized by means of tasks to allow or disable particular extraction options like headers, footers, titles, and diagrams based mostly in your processing wants.
- Customized output with blueprints –The thought is to create one blueprint per doc kind, as you employ the identical set of directions to extract widespread data throughout paperwork of the identical kind. Nonetheless, throughout totally different doc varieties, you want totally different blueprints for various data. For instance, you wish to extract totally different data from a passport than from a financial institution assertion, so these two doc varieties require separate blueprints. All financial institution statements ought to be processed with just one blueprint for as a result of whatever the financial institution or format, the kind of data that you simply wish to extract from financial institution statements ought to be the identical. Blueprints permit exact management over extracted data by defining particular fields, knowledge codecs, and extraction directions. Initiatives can comprise as much as 40 doc blueprints, with BDA mechanically matching every doc to the suitable blueprint. This allows processing of numerous doc varieties like invoices, contracts, and kinds inside a single unified workflow.
As well as, BDA supplies:
- Unified API expertise for processing multimodal content material by means of a single interface
- Cross-Area inference functionality throughout a number of Areas for improved processing
- Constructed-in safeguards, together with visible grounding and confidence scores for accuracy
- Assist for customized blueprints to standardize output codecs for particular doc varieties
Visible evaluation processing makes use of the capabilities of BDA to extract insights from plots, diagrams, charts, and visible components that conventional optical character recognition (OCR) options can’t interpret. BDA supplies picture crops as a part of the output when doing determine captioning, and it additionally generates detailed textual descriptions and structured knowledge from these visible components which can be included within the downstream workflow. For instance, when BDA processes a chart, it produces:
- Generated captions describing the chart’s content material and objective
- Extracted knowledge factors and tendencies from graphs
- Structural relationships from diagrams and flowcharts
- Bounding field coordinates linking the visible component to its location within the doc
All doc codecs in downstream processing: Each supported doc format (PDF, PNG, JPG, TIFF, DOC, DOCX) is processed by means of the unified API. The extracted content material from BDA, together with visible component descriptions, can then be manually configured for indexing and vectorization in Amazon Bedrock Data Bases to allow semantic search throughout numerous doc varieties. Word that BDA additionally has a built-in integration with Data Bases the place it will probably function a parser throughout doc ingestion right into a information base, utilizing BDA normal output (no blueprints required). This downstream workflow receives structured JSON outputs from BDA containing all extracted data, enabling constant processing whatever the unique file format.
Knowledge extraction from paperwork contains:
- Textual content extraction in studying order with format preservation
- Desk construction recognition with cell relationships maintained
- Kind discipline detection and key-value pair extraction
- Visible component evaluation together with charts, graphs, and diagrams with generated captions
- Bounding field coordinates for exact location monitoring of extracted components
- Doc-level and page-level summaries with context preservation
Intelligence layer
This layer is the cognitive engine of this answer. Amazon Bedrock Data Bases should be configured to work with Amazon OpenSearch Serverless to rework uncooked content material into actionable insights by means of semantic search and Retrieval Augmented Technology (RAG) capabilities. The next part supplies extra particulars.
Amazon Bedrock Data Bases with Amazon OpenSearch Serverless allows semantic search and RAG workflows by:
- Indexing processed doc content material for clever querying
- Sustaining vector embeddings for similarity search throughout doc collections
- Supporting advanced queries that span a number of paperwork and knowledge sources
Amazon Bedrock FMs analyze visible content material together with chart and graph interpretation, doc format understanding, and cross-modal relationship detection between textual content and visible elements.
Agentic coordination layer
This layer organizes the intelligence of this answer. Strands Brokers on Amazon Bedrock AgentCore Runtime handle the general processing workflow by routing requests to the suitable specialised brokers based mostly on request kind and coordinating cross-agent communication for advanced doc evaluation.
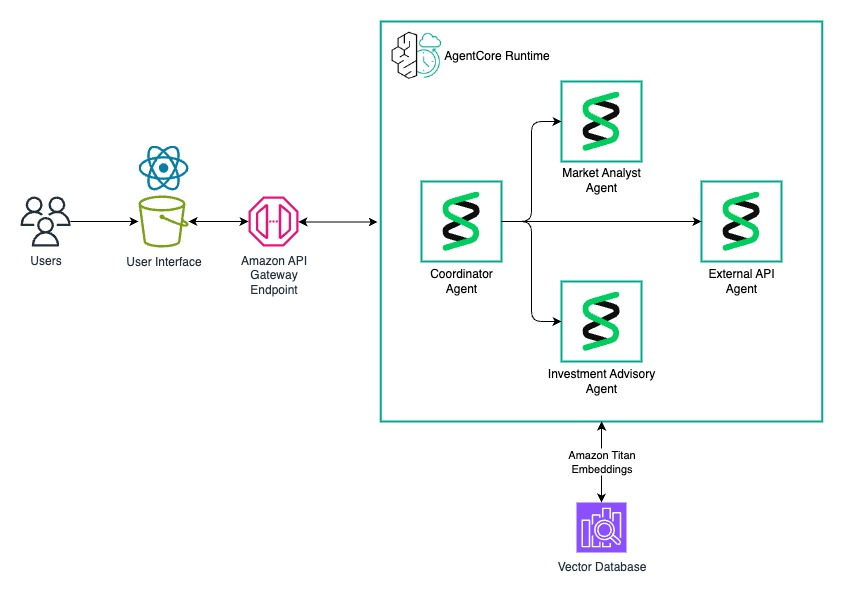
Specialised job brokers deal with particular doc processing capabilities:
- Market analyst brokers for monetary market studies and funding paperwork.
- Funding advisory brokers for portfolio evaluation and advisory documentation.
- Exterior API brokers for real-time, third-party knowledge integration by means of safe API connections to monetary knowledge suppliers, regulatory databases, and market intelligence platforms.
- Coordinator brokers carry out cross-reference validation by evaluating real-time market knowledge from the exterior API brokers in opposition to historic knowledge saved within the Amazon Bedrock information base.
Implementation structure
The processing pipeline employs an event-driven strategy to doc processing, integrating a number of specialised layers right into a cohesive workflow. It follows a logical development the place every step builds upon the earlier one. This begins with doc add, triggering Amazon S3 occasions that provoke state machines, and continuing by means of multi-modal processing that extracts that means from numerous content material varieties. The pipeline continues with agent coordination that directs processing based mostly on doc traits, adopted by information base indexing for clever retrieval. This methodical circulate culminates within the technology and integration of insights with enterprise methods, making a complete processing journey from uncooked paperwork to actionable intelligence.
Doc processing circulate
AWS Step Capabilities orchestrates the doc processing pipeline, dealing with doc classification, multi-modal extraction, knowledge validation, and information base integration.
Agentic interplay circulate
The user-facing layer supplies clever question processing by means of pure language interplay with the processed doc corpus, coordination agent supervision of specialised brokers, and the good distribution of queries to the suitable processing brokers.
Resolution walkthrough
Use case: Industrial actual property property evaluation
A industrial actual property funding agency receives over 200 property analysis studies month-to-month. These studies comprise:
- Property overview paperwork with location maps, zoning data, and property descriptions.
- Monetary evaluation spreadsheets embedded as photographs inside PDFs, displaying money circulate projections, cap charges, and ROI calculations.
- Market comparability charts displaying comparable property gross sales, rental charges, and market tendencies.
- Property pictures and ground plans with annotations and measurements.
- Authorized paperwork, together with title studies, environmental assessments, and zoning compliance.
- Historic efficiency graphs displaying occupancy charges, hire rolls, and upkeep prices over time.
The analyst accesses this answer, uploads the paperwork to it
Implementation
This implementation exhibits how our generative AI providers can remodel actual property funding evaluation by means of doc processing capabilities by doing the next:
Doc classification: The system mechanically identifies doc varieties, extracts property metadata (together with tackle and sq. footage), and routes totally different doc sections to the suitable processing brokers.
Multimodal content material extraction:
- Market analyst brokers course of embedded monetary charts to extract Internet Working Revenue projections and capitalization fee tendencies.
- Amazon Bedrock Knowledge Automation visible capabilities analyze property pictures to establish situation indicators and ground plan effectivity ratios.
- Cross-document relationship evaluation validates projected money flows with historic efficiency knowledge.
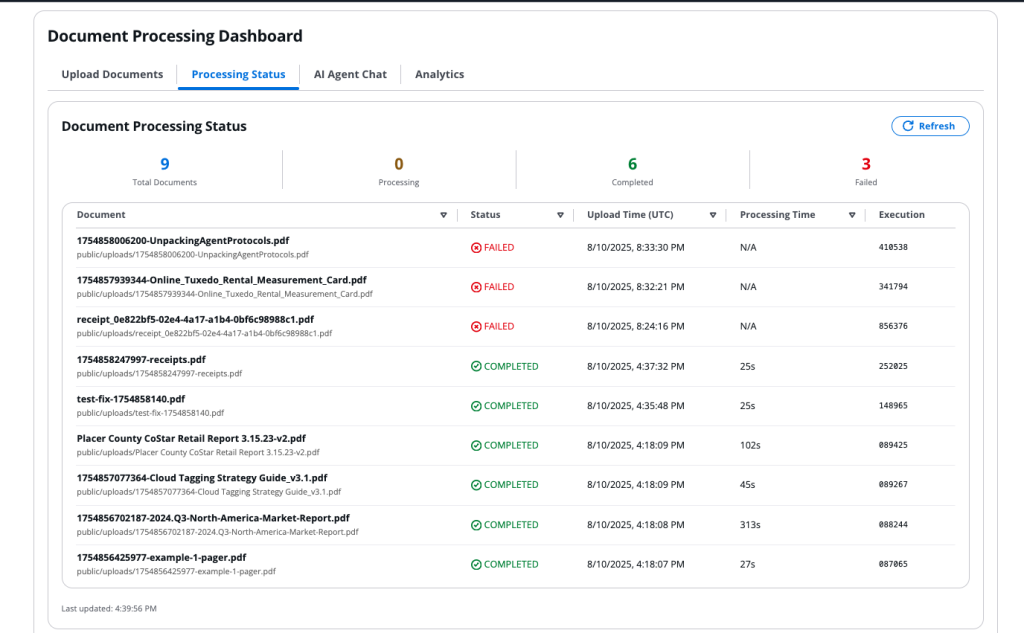
Pure language queries: Funding professionals course of data utilizing pure language queries, equivalent to “Present me properties with projected IRR above 12% and debt protection ratios over 1.25″ or “Examine NOI progress projections with precise market efficiency for related property.”
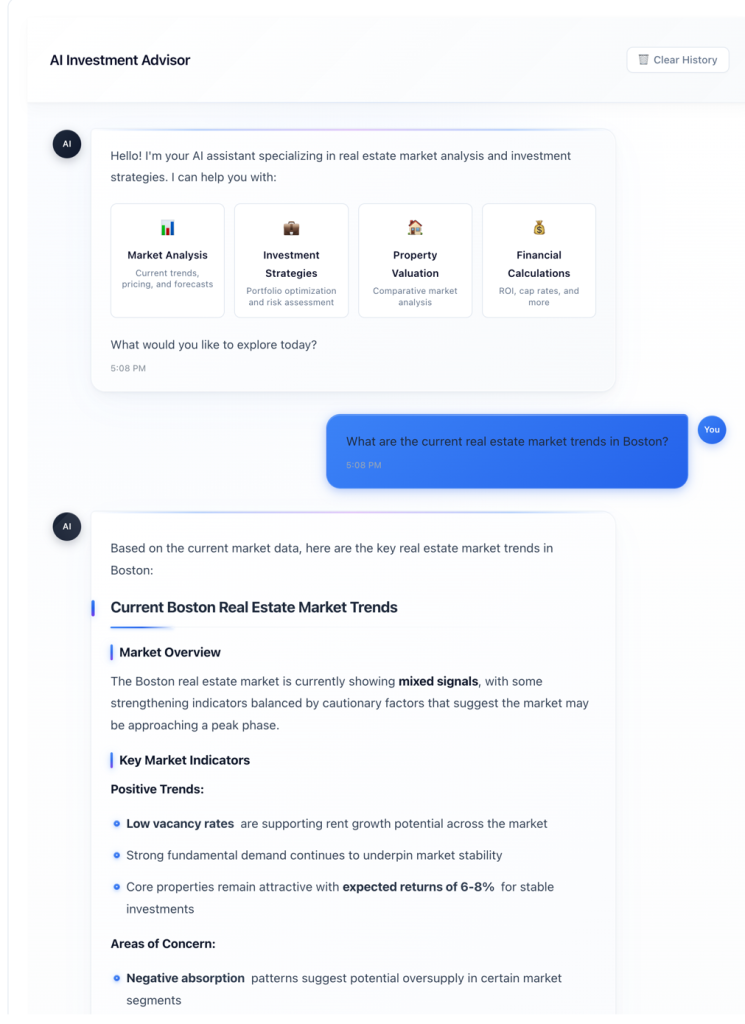
Outcomes
Processing time per property lowered from 3–4 hours to 15-20 minutes for preliminary screening. Automated extraction removes handbook transcription errors whereas cross-document validation identifies inconsistencies. The agency can course of considerably extra alternatives and establish enticing investments that may in any other case be neglected.
Scalability validation: This answer has been examined at scale, efficiently processing over 50,000 PDF paperwork concurrently by means of the BDA pipeline. The answer maintained excessive accuracy throughout numerous doc varieties together with contracts, monetary studies, and technical specs whereas processing at scale. The serverless structure with AWS Step Capabilities and asynchronous BDA processing enabled this huge parallel processing functionality with out efficiency degradation, demonstrating the answer’s readiness for enterprise-scale doc processing workloads.
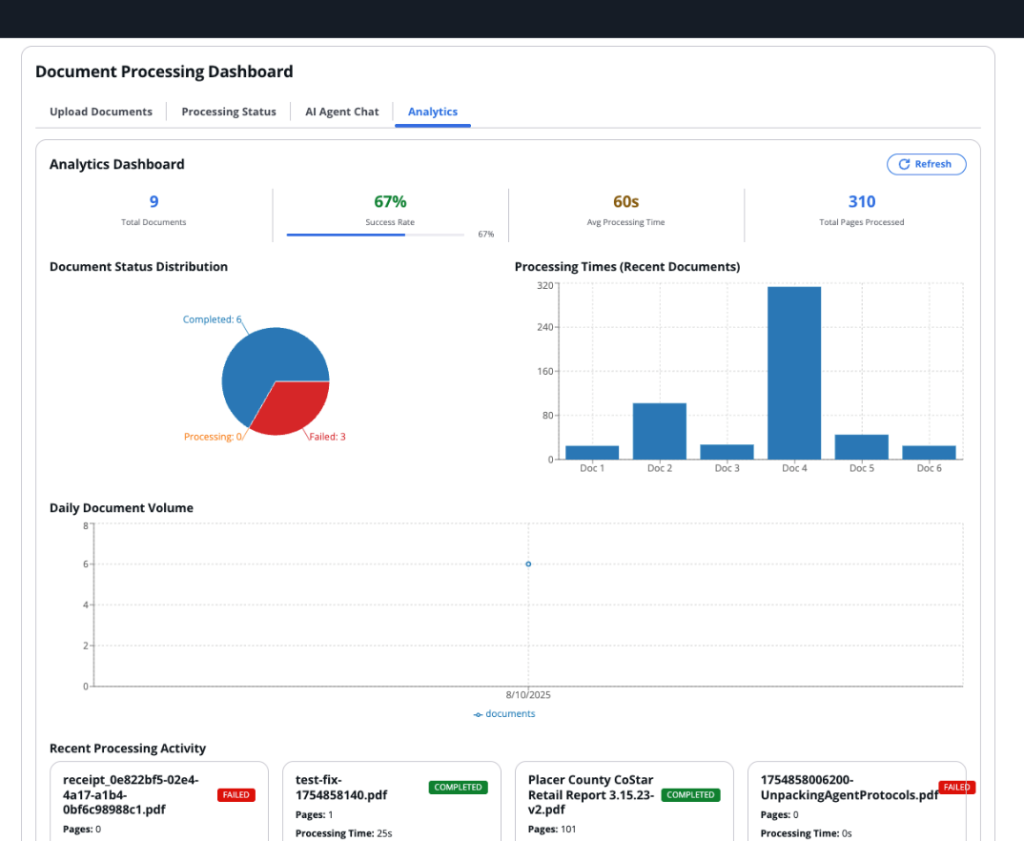
Deployment
The entire AWS Cloud Improvement Package (AWS CDK) implementation provisions all the structure with infrastructure as code (IaC) rules. The deployment creates 4 predominant stack elements aligned with our structure layers and contains environment-specific configurations for improvement, staging, and manufacturing environments.
Conditions
Earlier than implementing this answer, guarantee that you’ve:
- An AWS account with applicable permissions to create IAM roles, AWS Lambda capabilities, Step Capabilities, Amazon DynamoDB, Amazon Elastic Container Rregistry (Amazon ECR) and S3 buckets.
- Entry to Amazon Bedrock FMs enabled within the AWS Area the place you wish to deploy your answer.
- Amazon Bedrock Knowledge Automation enabled in an accessible Area. BDA is at present accessible in eight Areas – Europe (Frankfurt), Europe (London), Europe (Eire), Asia Pacific (Mumbai), Asia Pacific (Sydney), US West (Oregon), US East (N. Virginia), and AWS GovCloud (US-West) Areas.
- Primary familiarity with the AWS CDK and Python for infrastructure deployment.
- Understanding of doc processing workflows and enterprise necessities.
- Pattern paperwork for testing and validation.
The entire CDK implementation is offered in our public GitHub repository: Clever Doc Processing with Bedrock Brokers.
To deploy this answer, run the next command:
# Fast begin deployment
git clone https://github.com/aws-samples/sample-pdf-to-insights-idp-solution
cd sample-pdf-to-insights-idp-solution
./deploy.sh –profile default –surroundings UATPrice optimization methods
The next are considerate approaches to managing operational bills whereas sustaining the effectiveness of this answer’s processing.
Clever routing
Route paperwork to applicable processing ranges based mostly on complexity. Easy textual content paperwork use primary extraction, whereas advanced paperwork with tables and pictures make use of extra superior processing strategies.
Batch processing
Mix a number of paperwork right into a single Amazon Bedrock Knowledge Automation request the place applicable to enhance prices whereas respecting service limits.
Storage lifecycle administration
Implement Amazon S3 lifecyle insurance policies to mechanically transition processed paperwork to lower-cost storage tiers based mostly on entry patterns.
Safety and compliance
The structure incorporates enterprise-grade safety by means of AWS KMS keys for encryption of paperwork and processing outcomes, AWS PrivateLink connectivity for safe API entry inside VPC boundaries, and IAM roles with least-privilege entry rules throughout all elements.
Clear up
To keep away from ongoing fees, delete the sources created by this answer:
- Delete the AWS CDK stacks in reverse order of dependency
- Empty and delete S3 buckets containing processed paperwork
- Take away Amazon Bedrock brokers and information bases
- Delete Amazon CloudWatch Log teams and metrics
To delete all of the sources created, run this command:# Cleanup deployment./cleanup.sh –profile default –surroundings UAT
Conclusion
Organizations can use Amazon Bedrock Knowledge Automation, mixed with an agent-based coordination structure to automate doc processing from a conventional price heart right into a strategic enterprise asset. By mechanically extracting and analyzing visible plots, graphs, and charts, and deriving insights from paperwork whereas sustaining context and relationships throughout knowledge sources, organizations can unlock worth beforehand trapped in unstructured content material.The multilayered structure supplies a basis for scalable, cost-effective doc processing that adapts to various workloads whereas sustaining excessive accuracy. The visible evaluation capabilities present worthwhile insights embedded in charts, graphs, and pictures and are captured and made accessible for enterprise intelligence and decision-making.Begin with a targeted proof of idea that targets your most typical doc varieties and visible evaluation necessities. Then, develop the answer as you achieve expertise with the providers and perceive your particular accuracy and efficiency necessities.
To be taught extra about Amazon Bedrock Knowledge Automation, go to the Amazon Bedrock Knowledge Automation documentation. For hands-on expertise with clever doc processing, discover the IDP workshop on GitHub. The entire CDK implementation code for this structure is offered within the AWS Samples repository with deployment directions and configuration examples.
Concerning the authors


{kind=link}