
AI brokers can autonomously deal with complicated, multi-step duties, however their effectiveness relies on calling the appropriate instruments to retrieve info or take motion. When an agent picks the improper software, codecs parameters incorrectly, or breaks a workflow chain, process completion instances develop, error charges rise, help prices enhance, and consumer experiences degrade. As extra organizations transfer agentic functions from pilot to manufacturing, having brokers that choose the appropriate software for every request is crucial for dependable automation.
On this submit, you discover ways to use Supervised Effective-Tuning (SFT) and Direct Choice Optimization (DPO) collectively to enhance the tool-calling accuracy of a small language mannequin (SLM). The instance makes use of Amazon SageMaker AI coaching jobs, so you possibly can deal with coaching code as a substitute of managing your personal coaching infrastructure. You additionally discover ways to consider tool-calling accuracy and examine a base mannequin to a number of fine-tuned variants, so you can also make data-driven choices about mannequin high quality.
Effective-tuning methodologies
Supervised fine-tuning entails curating a high-quality dataset that aligns carefully with the mannequin’s meant perform, offering specific examples of how the mannequin ought to carry out sure duties or work together with particular instruments. This methodology is especially efficient for educating the mannequin to acknowledge the nuances of tool-specific language, instructions, and constraints.
Direct Choice Optimization refines these interactions by incorporating human suggestions or predefined aims instantly into the coaching loop. DPO aligns the mannequin’s output extra carefully with goal outcomes by emphasizing a choice for sure varieties of responses or behaviors over others. The coaching information in DPO accommodates a “like this, not like that” choice, which optimizes the identical objectives as reinforcement studying with out reward capabilities or reward fashions. This method reduces useful resource necessities and coaching time whereas sustaining high quality.
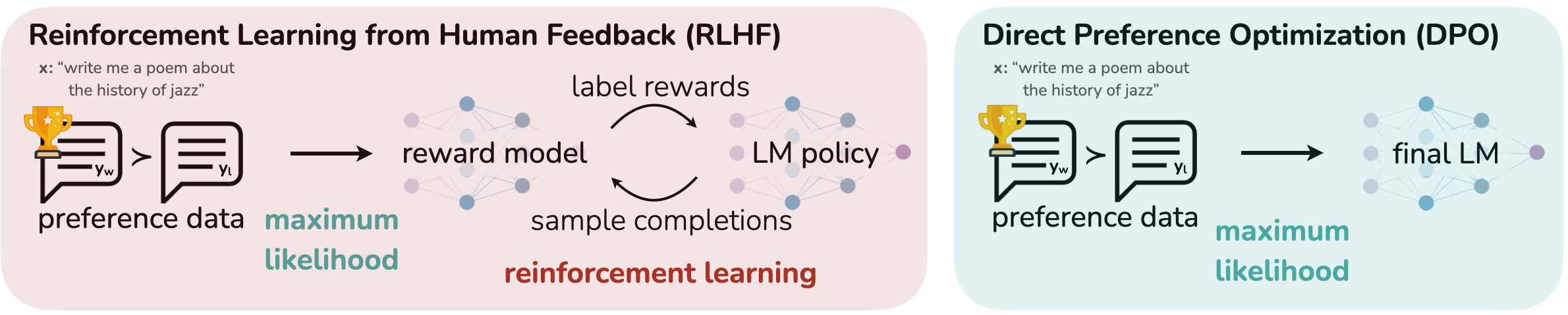
Supply: arXiv:2305.18290 [cs.LG]
For instance, the HuggingFace TRL library for DPO takes coaching samples within the following format:
This feedback-driven method permits for iterative enchancment of the mannequin’s tool-interaction capabilities primarily based on real-world utilization patterns within the coaching information.
Collectively, SFT and DPO kind a strong framework for fine-tuning language fashions to interface with a variety of digital instruments. Through the use of these strategies, you possibly can construct AI methods that perceive and generate human-like textual content and that carry out complicated duties by autonomously interacting with exterior functions, broadening the scope and utility of AI in each shopper and enterprise environments.
To grasp the prices related to Amazon SageMaker Studio notebooks and Amazon SageMaker AI coaching jobs, check with the SageMaker AI pricing web page.
Resolution overview
On this part, we stroll by means of the right way to fine-tune Qwen3 1.7B on Amazon SageMaker AI coaching jobs, a totally managed service that helps distributed multi-GPU and multi-node configurations. With SageMaker AI coaching jobs, you possibly can spin up high-performance clusters on demand, prepare billion-parameter fashions quicker, and mechanically shut down sources when the job finishes. Metrics from infrastructure and from contained in the coaching loop are despatched to MLflow on SageMaker AI for later evaluation.
Stipulations
To fine-tune function-calling fashions on SageMaker AI, you want the next stipulations:
Arrange your surroundings
Within the following sections, we run the code from a SageMaker Studio JupyterLab pocket book occasion. You may as well use your most well-liked IDE, resembling VS Code or PyCharm. Be sure that your native surroundings is configured to work with AWS, as listed within the stipulations.
Full the next steps to arrange your surroundings:
- On the SageMaker AI console, select Domains within the navigation pane, then open your area.
- Within the navigation pane below Purposes and IDEs, select Studio.
- On the Consumer profiles tab, find your consumer profile, then select Launch and Studio.
- In SageMaker Studio, launch an
ml.t3.mediumJupyterLab pocket book occasion with a minimum of 50 GB of storage. A big pocket book occasion isn’t required as a result of the fine-tuning job runs on a separate ephemeral coaching job occasion with NVIDIA accelerators. - To start fine-tuning, clone the GitHub repository:
git clone https://github.com/aws-samples/amazon-sagemaker-generativeai.git. - Navigate to the
6_use_cases/usecases/function-calling-sft-dpolisting. - Launch the
run_training_job.ipynbpocket book with a Python 3.12 or greater model kernel.
Dataset preparation
Selecting and creating the appropriate dataset is a crucial first step in fine-tuning basis fashions (FMs). This instance makes use of the When2Call dataset revealed by NVIDIA, a benchmark designed to judge tool-calling decision-making for FMs. It consists of when to generate a software name, when to ask follow-up questions, when to point that the query can’t be answered with the instruments supplied, and what to do if the query appears to require software use however a software name can’t be made.
The analysis code and artificial information era scripts used to generate the datasets are in NVIDIA’s GitHub repository.
The datasets comprise three totally different elements.
- Dataset for supervised fine-tuning (SFT), which accommodates 15,000 samples.
- Dataset for choice alignment, which makes use of Direct Choice Optimization (DPO) on this instance. This information accommodates 9,000 samples.
- The dataset for testing efficiency has two information: Multi-Alternative Query analysis (
mcq) and LLM-as-a-judge (llm_judge), which is a subset of the MCQ analysis set and might be downloaded as a singleDatasetDict.
For this use case, we have to do a little bit of preprocessing on the dataset to match the anticipated codecs for TRL’s SFTTrainer and DPOTrainer. To do this, we have to construct a system immediate that accommodates the listing of obtainable instruments and add the system immediate to the messages lists from the unique dataset.
Along with what we did for SFT, we have to put together the information for DPO. The DPOTrainer from TRL accepts a particular format that features columns labeled as chosen and rejected along with messages, so we have to create the messages column and rename chosen_response and rejected_response.
Now, save the SFT and DPO datasets in Amazon Easy Storage Service (Amazon S3) to make them out there for coaching.
Supervised fine-tuning (SFT) on the bottom mannequin
The next instance demonstrates the right way to fine-tune the Qwen3-1.7B mannequin. The repository accommodates the recipe within the scripts listing, the place you possibly can modify the bottom mannequin and coaching parameters for SFT. This instance makes use of a Spectrum-based fine-tuning recipe, however it’s also possible to use different PEFT strategies like LoRA or QLoRA.
The recipe accommodates the configuration for the mannequin and coaching parameters:
Create a coaching job with SageMaker AI ModelTrainer
Subsequent, we use a SageMaker AI coaching job to spin up a coaching cluster and run the mannequin fine-tuning. The SageMaker AI Python SDK ModelTrainer APIs run coaching jobs on totally managed infrastructure, dealing with surroundings setup, scaling, and artifact administration. Through the use of ModelTrainer, you possibly can specify coaching scripts, enter information, and compute sources with out manually provisioning servers.
First, configure the coaching surroundings:
To allow experiment monitoring in MLflow, provide the MLflow monitoring server ARN to the job.
The Compute part of the coaching setup determines the infrastructure necessities for coaching. Within the SourceCode part, we outline the native paths to code that might be imported into the coaching job.
The next is the listing construction for fine-tuning on SageMaker AI coaching jobs. We additionally present the necessities.txt file within the scripts listing, which ModelTrainer mechanically detects and installs the listed dependencies at runtime. For superior eventualities resembling disabling construct isolation, you possibly can present a bash script because the entry level to run shell instructions previous to beginning coaching.
Subsequent, specify the Amazon Elastic Container Registry (Amazon ECR) location for the coaching container, the place to retailer mannequin checkpoints, and what to call the SageMaker AI coaching job. These values are equipped to the ModelTrainer API to configure the job.
Lastly, configure the enter information parameters for the place the coaching information resides and begin the SFT coaching job with .prepare().
To fine-tune throughout a number of GPUs, we use Hugging Face Speed up and DeepSpeed ZeRO-3, which work collectively to coach fashions throughout a number of GPUs or nodes extra effectively. Hugging Face Speed up streamlines distributed coaching launches by mechanically dealing with machine placement, course of administration, and combined precision settings. DeepSpeed ZeRO-3 reduces reminiscence utilization by partitioning optimizer states, gradients, and parameters throughout GPUs, so billion-parameter fashions match and prepare quicker.
You possibly can run your SFTTrainer script with Hugging Face Speed up utilizing a command like the next:
With the SFT mannequin artifact prepared, now you can use that as a base mannequin for DPO coaching. The DPO coaching recipe seems to be much like the SFT one with just a few small modifications.
beta– This can be a DPO-specific hyperparameter, sometimes certain between 0–2, that controls how aggressively the mannequin adopts new preferences. A price nearer to 0 is extra aggressive and a worth nearer to 2 is extra conservative. A typical start line is 0.1 to 0.5, which may drive important modifications in habits. Nonetheless, this may result in excessive variance and even degradation. The optimum worth is extremely depending on the dataset.learning_rate– DPO advantages from decrease studying charges (for instance, 5e-7) with awarmup_ratioto stop overfitting. This worth contrasts with the SFTlearning_ratefrom the earlier run of 5e-5. Though this instance makes use of a continuinglr_scheduler_type, cosine annealing is one other widespread choice.batch_size– Giant batch sizes are inclined to carry out higher. The batch measurement on this instance is deliberately small to scale back useful resource necessities.
Optionally, you possibly can present a mix of loss values to carry out Combined Choice Optimization, which permits for the mixture and weighting of a number of loss sorts. On this instance, there’s SFT coaching information and DPO coaching information which are run individually. In case you solely have DPO coaching information, you need to use MPO with the sft loss kind to make use of the accepted column within the DPO information for SFT. If potential, offering separate, distinctive datasets leads to a bigger corpus of information and higher outcomes.
If loss_weights is omitted, all loss sorts can have equal weights (1.0 by default).
Direct Choice Optimization (DPO) coaching on the SFT-trained mannequin
Within the DPO instance, we present how one can cross configuration information into the coaching container as hyperparameters or as surroundings variables. The previous is picked up within the coaching script with TRLParser and the latter with Python os.environ references.
The DPO coaching configuration is outlined as follows:
Then kick off the coaching job for DPO:
Outcomes
We ran the experiment for 3 totally different fashions, utilizing the NVIDIA-provided script for analysis, with the next outcomes. Among the many base fashions, Qwen3-0.6B was the strongest performer out of the field regardless of being the smallest, beating Qwen3-1.7B by roughly 6 p.c and Llama-3.2-3B-instruct by roughly 1 p.c.
After a cycle of fine-tuning, the rankings change. The Qwen3-1.7B mannequin positive factors roughly 19 p.c in accuracy and outperforms the others by roughly 4–7 p.c. The spherical of choice optimization was additionally efficient, including one other roughly 10.5 p.c accuracy and ending the experiment within the lead by roughly 8–9 p.c over the opposite fashions.
This exhibits the effectiveness of a multi-step method to mannequin customization. Qwen3-1.7B gained 30 p.c in total accuracy and carried out 9 p.c higher than the Llama-3.2-3B mannequin, which has nearly twice the parameter depend. Reaching comparable or higher efficiency with a smaller mannequin can scale back price and enhance throughput when it’s time to host the mannequin.
| Mannequin | Tuning Approach | Acc-Norm |
| Llama 3.2 3B Instruct | Base | 46.50% |
| Llama 3.2 3B Instruct | Spectrum SFT | 53.41% |
| Llama 3.2 3B Instruct | Spectrum SFT + DPO | 62.67% |
| Qwen3-0.6B | Base | 47.64% |
| Qwen3-0.6B | Spectrum SFT | 56.10% |
| Qwen3-0.6B | Spectrum SFT + DPO | 62.02% |
| Qwen3-1.7B | Base | 41.57% |
| Qwen3-1.7B | Spectrum SFT | 60.43% |
| Qwen3-1.7B | Spectrum SFT + DPO | 71.06% |
Clear up
To keep away from incurring prices for sources you now not want, full the next clean-up steps:
- Delete any SageMaker AI coaching jobs you launched. Coaching jobs that full efficiently don’t proceed to incur prices, however you possibly can clear up information from the SageMaker AI console or with the AWS CLI.
- Take away the datasets you uploaded to Amazon S3:
- Cease or delete the SageMaker Studio JupyterLab pocket book occasion to keep away from idle prices.
- Delete any mannequin checkpoints saved in Amazon S3 that you simply now not want.
Conclusion
On this submit, we confirmed the right way to enhance an agent’s tool-calling accuracy by combining supervised fine-tuning (SFT) with Direct Choice Optimization (DPO) on Amazon SageMaker AI. SFT makes use of labeled datasets to refine mannequin parameters, so the mannequin develops a foundational understanding by studying from expert-annotated examples. DPO then aligns the mannequin’s outputs with human preferences or particular efficiency standards by means of direct suggestions, with out the necessity to outline reward capabilities.
By integrating these two methodologies, you get a better-performing mannequin that advantages from the structured, knowledge-driven method of SFT and the adaptability and user-centered refinement of DPO. The result’s a mannequin that’s extra correct, extra related, and higher aligned with how customers need it to behave.
For extra examples on fine-tuning basis fashions, go to the SageMaker AI generative AI samples GitHub repository. For extra details about coaching fashions in SageMaker AI, see the SageMaker AI documentation.
Concerning the authors


{kind=link}