
an important AI use instances of an enterprise right this moment, doc comparability ranks alongside conversational chatbots. Organizations spend an enormous variety of person-hours evaluating contracts, insurance policies, technical specs, authorized petitions, analysis papers and plenty of extra to establish variations, dangers, revisions and semantic inconsistencies.
Nonetheless, doc comparability is way extra advanced than conventional textual content distinction. For one, these instruments are supposed to be efficient assistants to authorized and industrial professionals, scientists and others who anticipate the evaluation to be on the degree of depth and language as may be anticipated from a junior skilled within the area.
An excellent tougher downside is that that means in enterprise paperwork normally isn’t contained in remoted chunks. It’s embedded inside sections, hierarchies, clause groupings and relationships. And these sections could also be scattered throughout a number of pages of a doc spanning over a 100 pages. For instance, a credit score settlement might outline collateral limitations in a single part, exceptions to these a number of pages later, and describe enforcement rights beneath a totally totally different article. If one other settlement is being in contrast in opposition to this with the standards equivalent to “collateral construction, safety pursuits, and lien necessities,” the system should establish, retrieve, and synthesize all of those structurally scattered sections collectively earlier than any significant comparability can happen.
Proxy-Pointer structure, with its structure-aware, but low-cost retrieval pipeline that preserves doc hierarchy throughout retrieval and comparability, is ideally suited to this job. Utilizing a mixture of hierarchical breadcrumb embeddings and light-weight LLM re-ranker, it is ready to exactly extract semantically aligned areas throughout paperwork earlier than comparative reasoning begins.
On this article, I’m sharing the design and real-world outcomes of a flexible doc comparator able to analyzing each extremely advanced monetary Credit score Agreements and educational analysis papers. As you’ll discover within the structure described within the subsequent part, the core comparability engine is separated from the upstream doc processing and downstream report formatting and era, enabling the system to be simply tailored to any new doc area (equivalent to insurance coverage insurance policies, medical pointers, or tax codes). All that’s required is an upstream extraction pipeline to construction the enter for hierarchical tree era, and a downstream replace to the LLM’s analytical persona and report formatter—leaving the core multi-stage retrieval and comparability pipeline solely untouched.
Additionally, I’m including the complete code, to my current open-source Proxy-Pointer github repository, together with a 5 minute quickstart.
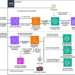
Doc Comparator Structure
Right here is an summary of the logical structure. The LLM used is gemini-3-flash together with gemini-embedding-001 (dimension: 1536) for vector embeddings.

Architectural Tiers
Upstream Extraction Layer
Converts any incoming uncooked doc construction right into a standardized, machine-readable hierarchy.
Applications Concerned
-
extract_pdf_to_md.py: Handles upstream ingestion, changing PDFs into clear, hierarchically formatted Markdown. build_doc_index.py: Parses Markdown headers, filters administrative noise, and builds the hierarchical JSON construction map (_structure.json).
Core Comparability Engine
Coordinates semantic search over hierarchical doc nodes.
Applications Concerned
criteria_validator.py: Dynamically detects thedoc_type(e.g., Tutorial vs. Authorized) and performs an preliminary feasibility examine on the person’s comparability standards, to establish if the standards is related for the recognized doc sort.section_selector.py: Implements Stage 1 Proxy-Pointer retrieval. It identifies and extracts probably the most related sections of Doc 1 based mostly on person standards utilizing FAISS semantic search and an LLM re-ranker.cross_retriever.py: Implements Stage 2 Proxy-Pointer retrieval. It performs a focused semantic search inside Doc 2’s vector area utilizing the context of the chosen Doc 1 sections (pairing the Doc 1 part content material with the person’s standards because the question). The Proxy-Pointer pipeline is extraordinarily correct in figuring out the proper semantically analogous sections for comparability.section_comparator.py: Coordinates pairwise evaluations of matching sections, passing them to the LLM to investigate alignments and discrepancies.
Downstream Presentation Layer
Tailors the analytical output to the audience and codecs the ultimate visualization.
Applications Concerned
build_comparison_prompt(incriteria_validator.py): The immediate assigns the suitable persona (e.g., Skilled Tutorial Researcher or Senior Authorized Counsel) based mostly on the detecteddoc_type.report_builder.py: Renders the ultimate comparability report side-by-side utilizing skilled CSS colours and extremely readable structure formatting. The report will also be downloaded as a markdown file.
Dataset Used
For the prototype, publicly out there Credit score Agreements, Emerson (136 pages) and Texas Roadhouse (190 pages) are used. These have been intentionally chosen as they’ve totally different buildings and belong to totally different industries. Emerson is a utility supplier, and its settlement reads like a sovereign company treasury doc based mostly on credit score company scores, whereas Texas Roadhouse’s settlement is very custom-made, constructed particularly round restaurant leases, multi-entity subsidiary buildings, and dynamic leverage ratios.
As well as, I added the function to match analysis papers for which I chosen VectorFusion and VectorPainter, which have been utilized in my article on Multimodal Solutions RAG. They’re each papers within the extremely specialised subject of text-to-vector graphics era. Whereas each share an equivalent technical basis—utilizing differentiable rendering (equivalent to DiffVG) to optimize Scalable Vector Graphics (SVG) paths through diffusion fashions—they differ considerably of their methodological execution. This slim, shared-domain relationship is a troublesome take a look at case for our comparability engine, of its skill to bypass surface-level similarities and as a substitute consider delicate architectural variations, which we will see within the subsequent part.
Comparability of Credit score Agreements
I ran a number of totally different queries with a various set of standards; the detailed stories are totally included within the repository, and a snapshot is shared under. The Streamlit UI accepts two paperwork (both in .pdf or .md format) as enter, with the comparability carried out strictly from the attitude of Doc 1. For instance, if Doc 1 is Emerson and Doc 2 is Texas Roadhouse, the ultimate comparability is framed round Emerson.
There are three steps to the method. First, it selects all sections from the Emerson settlement which can be related to the person’s standards. For every chosen part, it finds as much as three comparative sections in Texas Roadhouse, after which performs a side-by-side evaluation. Together with the detailed evaluation, the system gives a practical Function, a Discrepancy Ranking, and a Threat Path (or Methodological Tradeoff for educational papers)
Within the following 4 instances, Doc 1 is Emerson, Doc 2 is Texas Roadhouse.
Standards 1: collateral construction, safety pursuits, ensures, and lien necessities


Standards 2: occasions of default, lender cures, acceleration rights, and remedy intervals


Standards 3: monetary covenants, leverage ratio necessities, and borrower compliance obligations


Standards 4a: representations and warranties, materials antagonistic impact clauses, and disclosure obligations


For edge case testing, right here is the above “warranties” standards with the paperwork switched. Within the following, Doc 1 is Texas Roadhouse and Doc 2 is Emerson.
Standards 4b: representations and warranties, materials antagonistic impact clauses, and disclosure obligations


Evaluation of Credit score Settlement comparability
What the above outcomes present is that Proxy-Pointer is not only matching clauses by key phrases or incomplete chunks, it’s taking a look at them from the persona of a authorized analyst, somebody who understands how credit score works, throughout these extremely various industries. One being an investment-grade utility, and the opposite a midsize restaurant chain. As an illustration, it identifies the financial and authorized penalties hidden beneath superficially related language — like structural subordination threat inside a damaging pledge, enterprise-value preservation inside disposition covenants or litigation publicity inside disclosure representations.
One other remark is that the evaluation remained directionally constant when the paperwork have been flipped. It didn’t anchor itself to Emerson as Doc 1, however as a substitute re-evaluated the agreements from the Texas Roadhouse perspective. It accurately recognized which settlement positioned extra restrictions on the borrower, which gave lenders larger management throughout defaults, which was extra weak to property being moved out of attain, and which required the corporate to reveal extra info. None of those are explicitly written in both agreements. They develop into evident to a authorized analyst when a number of clauses, exceptions, thresholds, and definitions are learn collectively. The end result feels much less like a easy clause comparability and extra like understanding how threat and management are shared between the borrower and the lender.
Analysis Paper Comparability
For the VectorFusion and VectorPainter papers, I in contrast utilizing the next standards: Evaluate how every paper approaches type management and primitive initialization in vector graphics synthesis. Particularly, analyze how VectorFusion makes use of path reinitialization and raster pattern initialization versus how VectorPainter extracts and rearranges vectorized strokes from a reference picture utilizing stroke imitation studying and style-preserving losses
Right here is one comparability:


The evaluation reveals a deep domain-intensive comparability, a instrument {that a} researcher can use to match each papers with out studying them of their entirety. Proxy-Pointer strikes past surface-level structure matching and identifies the deeper design philosophy behind each papers. As well as, it accurately acknowledges that VectorFusion treats SVG era as a dynamic optimization downside with steady path reinitialization, whereas VectorPainter approaches it as a style-guided synthesis downside targeted on creative consistency and discovered stroke historical past. What was additionally fairly fascinating was that it might join concepts unfold throughout utterly totally different sections of the papers and stability the underlying limitations. This demonstrates a fine-grained evaluation of two methods in the identical slim area however that work in a different way.
Open-Supply Repository
Proxy-Pointer is totally open-source (MIT License) and may be accessed at Proxy-Pointer Github repository. The Doc Comparator is being added to the repo along with the present Textual content-Solely and Multimodal Answering bots.
A 5-minute quickstart will allow you to check rapidly with out there knowledge.
DocComparator/
├── src/
│ ├── comparability/
│ │ ├── cross_retriever.py # Stage 2 PP Retrieval (Doc 2)
│ │ ├── section_comparator.py # Pairwise LLM analysis engine
│ │ └── section_selector.py # Stage 1 PP Retrieval (Doc 1)
│ ├── extraction/
│ │ └── extract_pdf_to_md.py # LlamaParse PDF ingestion & formatting
│ ├── indexing/
│ │ └── build_doc_index.py # Skeleton tree & FAISS vector builder
│ ├── report/
│ │ └── report_builder.py # Markdown report era logic
│ ├── validation/
│ │ └── criteria_validator.py # Persona injection & standards feasibility
│ └── config.py # Core configurations and mannequin definitions
├── knowledge/ # Unified Information Hub
│ └── uploads/ # Uncooked PDFs and take a look at paperwork
├── outcomes/ # Artifact stories for the take a look at instances tried
└── app.py # Streamlit Comparator UIConclusion
Doc comparability utilizing a Chunk-Embed-Match method will not be possible to present good outcomes. In a posh enterprise doc equivalent to Contract Phrases and Circumstances, semantic that means is encapsulated into sections and subsections containing dense textual content. Every of those sections could possibly be pages in size and a part of a really lengthy doc. For efficient comparability and evaluation – sections, definitions, exceptions, and structural relationships should be extracted collectively to make sense when learn collectively.
Proxy-Pointer with its correct two-step retrieval pipeline is good for this job. Because the outcomes above present, even with a funds LLM equivalent to gemini-flash, one can examine agreements or analysis papers such that it might protect the underlying intent and trade-offs hidden throughout structurally disparate sections.
The three-tier structure of the Doc Comparator can scale to different domains with no change to the comparability engine itself. This allows structure-aware retrieval to generalize higher than a custom-built instrument that works just for a particular sort of doc. Organizations can adapt this to their particular industries and use instances, with minimal incremental engineering effort.
Clone the repo. Attempt your personal paperwork. Let me know your ideas.
Join with me and share your feedback at www.linkedin.com/in/partha-sarkar-lets-talk-AI
All analysis papers used on this article can be found at VectorFusion and VectorPainter with CC-BY license. The credit score agreements are publicly out there at SEC.gov. Code and benchmark outcomes are open-source beneath the MIT License. Photographs used on this article are generated utilizing Google Gemini.


{kind=link}