
Trendy enterprises face mounting challenges in extracting actionable insights from huge knowledge lakes and lakehouses spanning petabytes of structured and unstructured knowledge. Conventional analytics require specialised technical experience in SQL, knowledge modeling, and enterprise intelligence instruments, creating bottlenecks that gradual decision-making throughout retail, monetary providers, healthcare, Journey & Hospitality, manufacturing and lots of extra industries. This structure demonstrates how agentic AI assistant from Amazon Fast rework knowledge analytics right into a self-service functionality. It showcases enabling enterprise customers to question complicated structured datasets and blend with unstructured knowledge to search out the dear insights to enhance their enterprise outcomes by way of intuitive pure language interfaces.
To show the performance, we constructed a lakehouse utilizing the TPC-H datasets as our basis. This built-in structure leverages Amazon Easy Storage Service (Amazon S3) as a storage, Amazon SageMaker and AWS Glue for lakehouse, Amazon Athena for serverless SQL querying throughout a number of storage codecs (S3 Desk, Iceberg, and Parquet), and a number of options from Fast to construct dashboard and conversational AI brokers that present pure language entry to knowledge insights. By built-in data bases utilizing Amazon Fast areas, this answer democratizes lakehouse knowledge entry for enterprise customers whereas preserving enterprise-grade safety, governance frameworks, and the scalability required for contemporary data-driven decision-making throughout the group.
Resolution Overview
The next diagram reveals the general design and corresponding dataflow that we carried out as a part of this weblog put up.

Determine 1: Total design diagram Reference following steps for the detailed finish to finish knowledge movement and person interplay capabilities.
- Information Supply Ingestion: Structured Information TPC-H serves as the first knowledge supply, containing benchmark datasets saved in relational database format. AWS hosted the TPC-H knowledge within the publicly obtainable s3 bucket (s3://redshift-downloads/TPC-H/2.18/100GB)
- Information Load: Amazon Athena performs the primary question layer, executing serverless SQL queries towards the TPC-H structured knowledge to extract, put together knowledge for processing, load knowledge in S3, and create corresponding catalog in Glue.
- Multi-Format Storage Layer: As an example the flexibility of Information lake and Lakehouse we saved the info into three optimized storage codecs:
- Amazon S3 -CSV: Use exterior desk to create Athena desk based mostly on present CSV recordsdata.
- Amazon S3 (Apache Iceberg-parquet): ACID-compatible desk format enabling time-travel and schema evolution
- Amazon S3 Desk: Amazon S3 Tables ship the primary cloud object retailer with built-in Apache Iceberg assist and streamline storing tabular knowledge at scale.
- Metadata Cataloging: AWS Glue Catalog indexes all three storage codecs, making a unified metadata layer that permits seamless querying throughout totally different knowledge codecs.
- Lakehouse Question Layer: We used the Amazon Athena SQL queries throughout storage codecs (S3 Desk, Iceberg, and Parquet) utilizing the Glue Catalog metadata, offering a unified question interface.
- Enterprise Intelligence Pipeline: Structured TPC-H knowledge flows into Amazon Fast, which integrates with Fast Sight to create:
- Dataset – We utilized Amazon Athena connection from Amazon Fast to extract structured knowledge to load in Fast SPICE (Tremendous-fast, Parallel, In-memory Calculation Engine) dataset
- Subject – Organized knowledge domains for enterprise context
- Dashboard Utilizing Q – Interactive visualizations with pure language question capabilities to construct the dashboard and publish it
- AI Data Enhancement: Parallel to the structured knowledge movement, a Internet Crawler for TPC-H specs ingests unstructured knowledge (documentation, specs) and feeds it into Data Bases to offer contextual understanding.
- Conversational Agentic AI Layer: Data Bases energy Amazon Fast areas (collaborative environments), which in flip allow the Amazon Fast chat brokers with contextual consciousness and area data for pure language interactions.
- Finish Person Entry: Customers work together with the system by way of two major interfaces:
- Dashboard Utilizing Q – Visible analytics and self-service Enterprise Intelligence
- Chat Agent – Conversational AI for pure language knowledge exploration
Pre-requisite
Earlier than you get began, be sure to have the next conditions:
Information Preparation for lakehouse / knowledge Lake
On this part, we’ll mimic most of the knowledge lake options by working with exterior tables, which permit querying knowledge saved in Amazon S3 with out loading it right into a managed storage layer. We’ll discover Open Desk Format (OTF) tables utilizing Apache Iceberg to contemplate potential ACID transactions supported tables. Amazon managed S3 Tables will likely be leveraged to showcase how Amazon natively helps Iceberg-compatible desk administration instantly inside S3, simplifying lakehouse structure at scale. All through these workout routines, we’ll use the industry-standard TPC-H dataset, a benchmark workload representing a sensible enterprise knowledge mannequin with orders, prospects, and line objects to ensure our examples are each significant and reproducible.
We’ll leverage Amazon Athena for knowledge preparation. If that is your first time utilizing Amazon Athena, you’ll have to create an Amazon S3 bucket to retailer your question outcomes. Athena makes use of S3 as its output location earlier than you may run queries. Comply with the official AWS getting began information to finish this one-time setup: Getting Began with Amazon Athena. Alternately, you should utilize Managed question outcomes characteristic.
Tip: Select an S3 bucket within the identical AWS Area as your knowledge sources to keep away from cross-region knowledge switch prices and latency.
As soon as your S3 output location is configured, you’re able to proceed.
Create the Glue Database
Begin by making a Glue database that can function the metadata catalog for all of your tables utilizing Athena. Run the next SQL within the Athena question editor:
CREATE DATABASE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql COMMENT 'TPC-H database'; 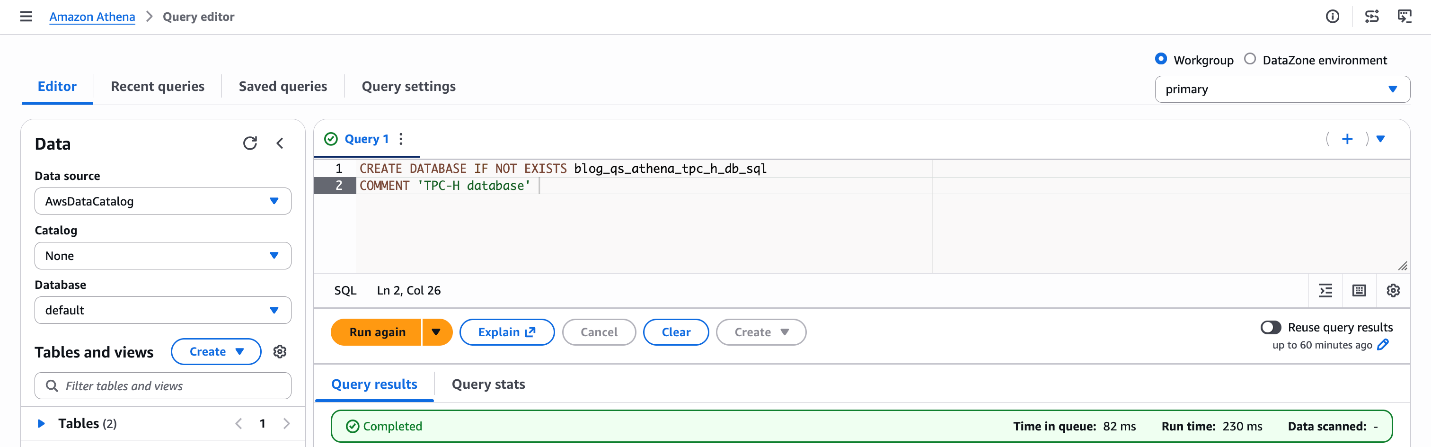
Determine 2: Database creation blog_qs_athena_tpc_h_db_sql
What this does: This registers a logical database within the AWS Glue Information Catalog, which Athena makes use of to arrange and uncover your tables. Tables created in subsequent steps will dwell beneath this database.
Create an Exterior Desk on S3
Subsequent, create an exterior desk pointing to the TPC-H “buyer” dataset saved in a public S3 bucket ('s3://redshift-downloads/TPC-H/2.18/100GB/buyer/'). Exterior tables in Athena don’t transfer or copy knowledge — they question it instantly from S3, making this a quick and cost-effective strategy to discover uncooked knowledge.
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.customer_csv
(
C_CUSTKEY INT,
C_NAME STRING,
C_ADDRESS STRING,
C_NATIONKEY INT,
C_PHONE STRING,
C_ACCTBAL DOUBLE,
C_MKTSEGMENT STRING,
C_COMMENT STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/buyer/'
TBLPROPERTIES ('classification' = 'csv'); Confirm the desk by previewing just a few rows:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.customer_csv LIMIT 10; 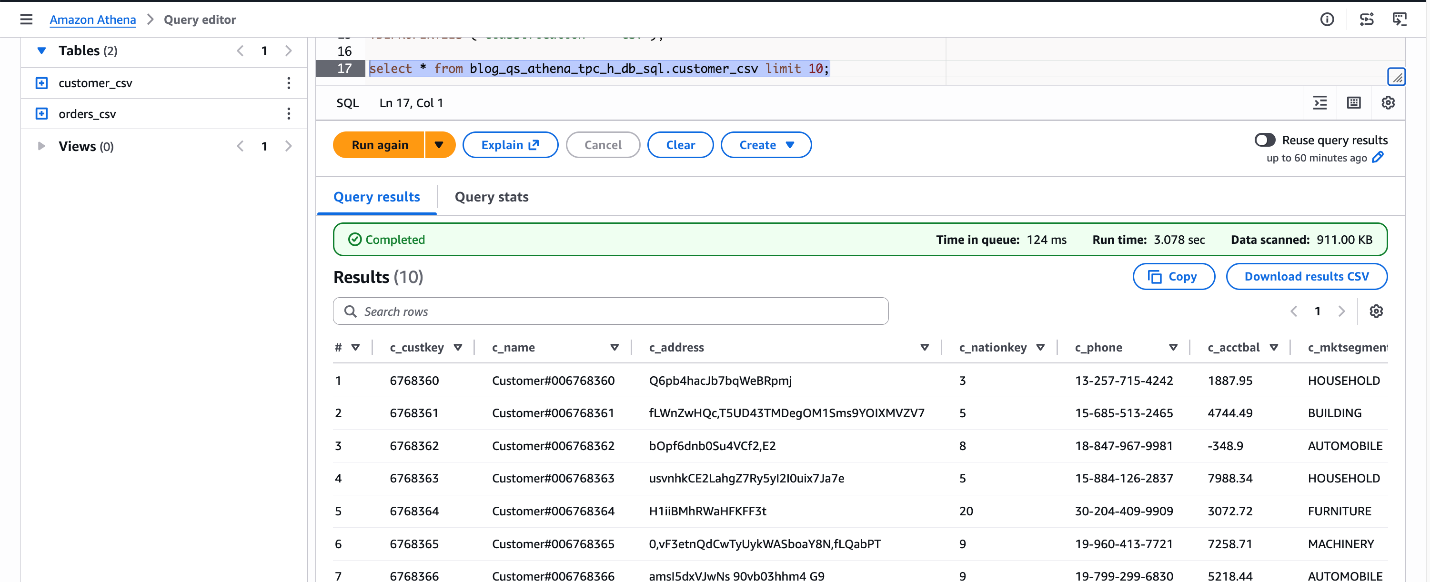
Determine 3: confirm blog_qs_athena_tpc_h_db_sql.customer_csv
Create an Apache Iceberg Desk
Subsequent, we’ll mimic the desk utilizing Apache Iceberg, which is an open desk format that brings ACID transactions, time journey, and partition evolution to your knowledge lake — making it superb for production-grade workloads. This can be a three-step course of.
Step1: Create the S3 Bucket – Earlier than writing SQL queries, arrange your storage layer. You may create an S3 bucket utilizing the AWS Administration Console or AWS CLI.
For this weblog, I’m utilizing the S3 bucket: amzn-s3-demo-bucket
Notice: Your bucket identify will likely be totally different, as S3 bucket names have to be globally distinctive throughout all AWS accounts.
Step2: Create an Exterior CSV Desk for Orders – First, register the uncooked orders knowledge as an exterior desk in its authentic format, in our case it’s CSV.
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.orders_csv
(
O_ORDERKEY BIGINT,
O_CUSTKEY BIGINT,
O_ORDERSTATUS STRING,
O_TOTALPRICE DOUBLE,
O_ORDERDATE STRING,
O_ORDERPRIORITY STRING,
O_CLERK STRING,
O_SHIPPRIORITY INT,
O_COMMENT STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('area.delim' = '|')
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/orders/'
TBLPROPERTIES ('classification' = 'csv');Let’s confirm the dataset.
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_csv LIMIT 10;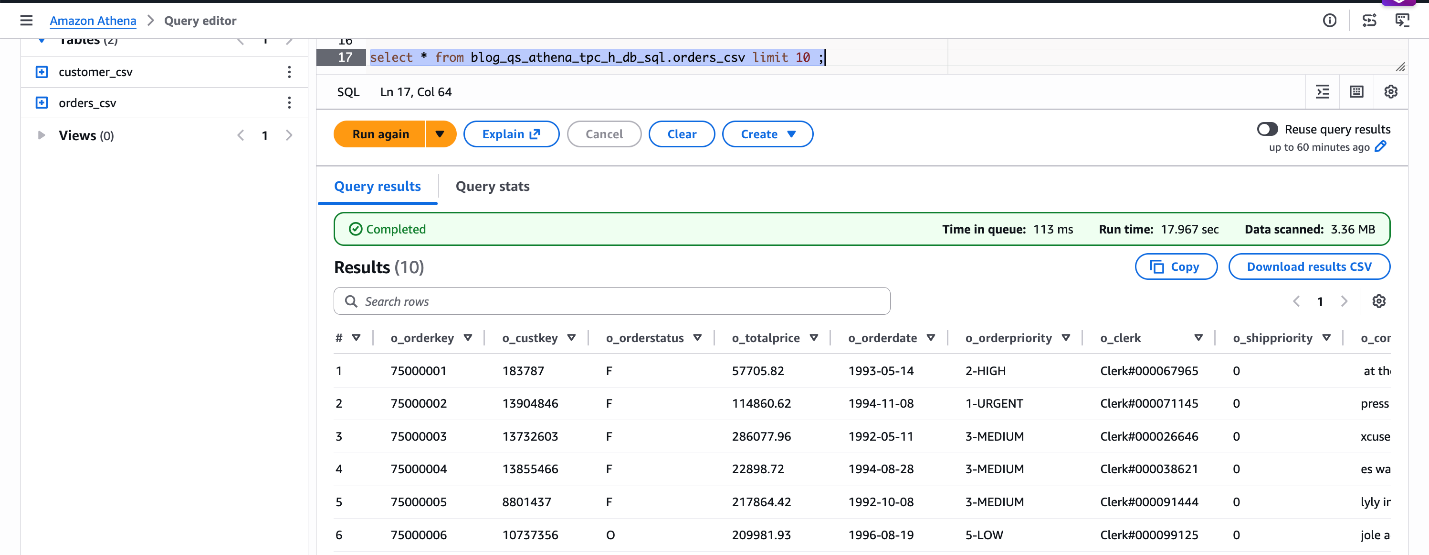
Determine 4: confirm blog_qs_athena_tpc_h_db_sql.orders_csv
Step3: Create the Iceberg Desk Utilizing CREATE TABLE AS SELECT (CTAS) – Use CREATE TABLE AS SELECT (CTAS) to create a self-managed Iceberg desk in Parquet format, partitioned by order date. We’ll load a pattern date vary O_ORDERDATE BETWEEN ‘1998-06-01’ AND ‘1998-12-31’.
CREATE TABLE blog_qs_athena_tpc_h_db_sql.orders_iceberg
WITH (
table_type="ICEBERG",
format="PARQUET",
is_external = false,
partitioning = ARRAY['o_orderdate'],
location = 's3://amzn-s3-demo-bucket/tpch_iceberg/orders/')
AS
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_csv
WHERE O_ORDERDATE BETWEEN '1998-06-01' AND '1998-12-31';Confirm the Iceberg desk knowledge:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_iceberg LIMIT 10; 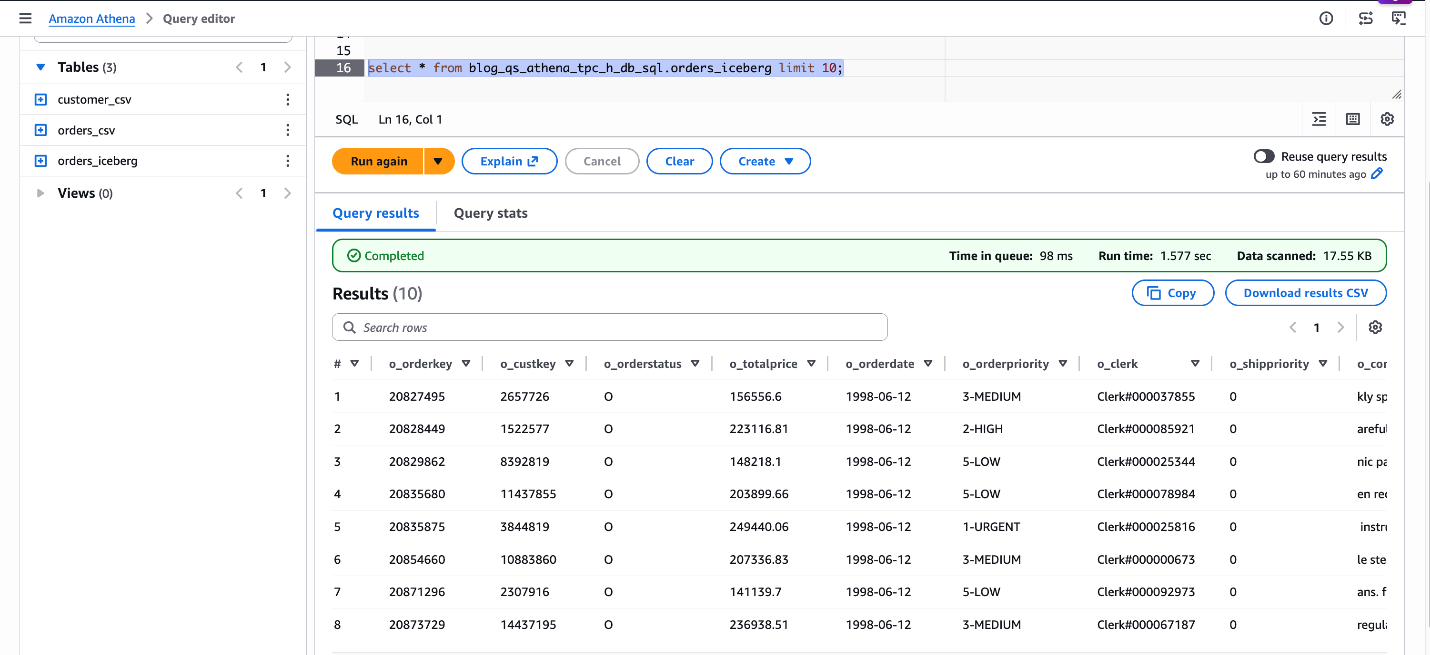
Determine 5: confirm blog_qs_athena_tpc_h_db_sql.orders_iceberg
Create an Amazon S3 Desk
Amazon S3 Tables are purpose-built, absolutely managed tables with built-in Apache Iceberg assist. It delivers high-performance question throughput with out the overhead of managing upkeep operations, equivalent to compaction, snapshot administration, and unreferenced file elimination. This can be a three-step course of.
Step1: Create the S3 Desk Bucket and Namespace – Navigate to S3 → Desk Buckets within the AWS Console to create the bucket blog-qs-athena-tpc-h-db-sql-s3-table-mar-3 and namespace. Alternatively, use the AWS CLI for scripted setup.
Notice : You may ignore these steps if you have already got an S3 desk bucket and namespace obtainable.
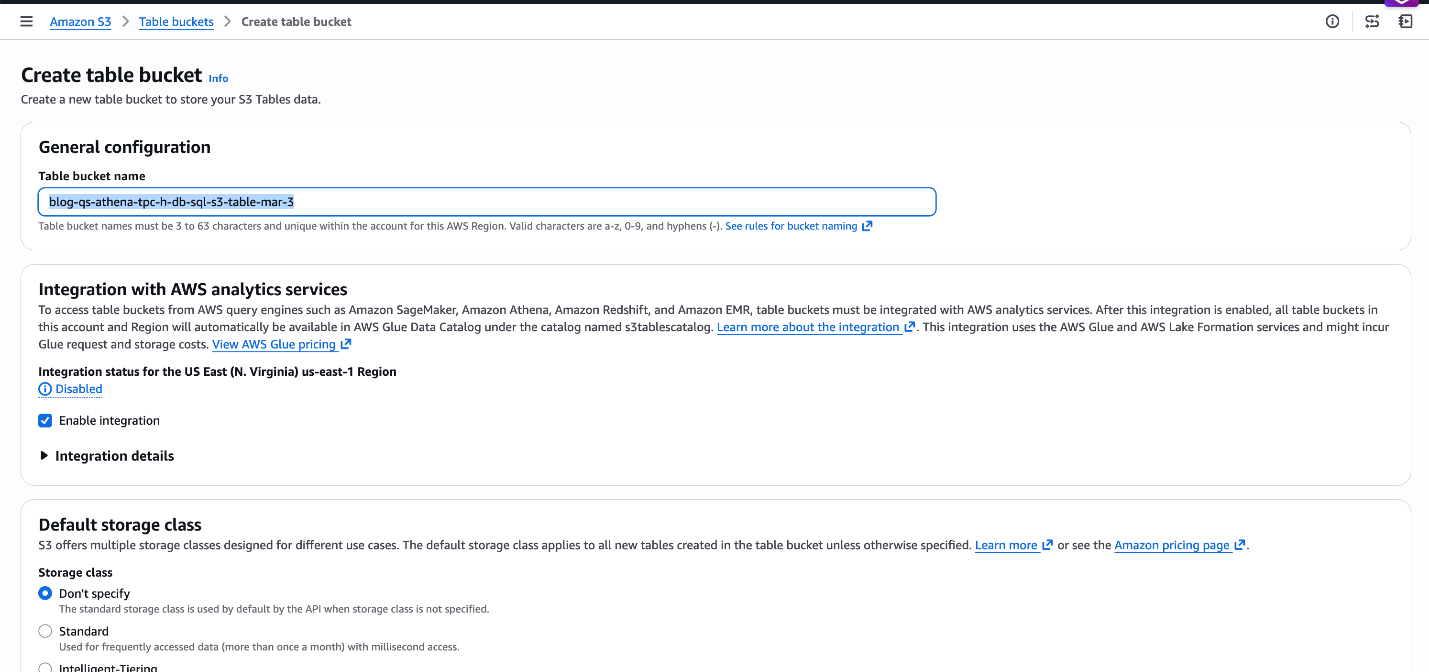
Determine 6: Create S3 Desk bucket blog-qs-athena-tpc-h-db-sql-s3-table-mar-3
Now let’s create a namespace blog_qs_athena_tpc_h_namespace related to above S3 desk bucket by clicking on the blog-qs-athena-tpc-h-db-sql-s3-table-mar-3.
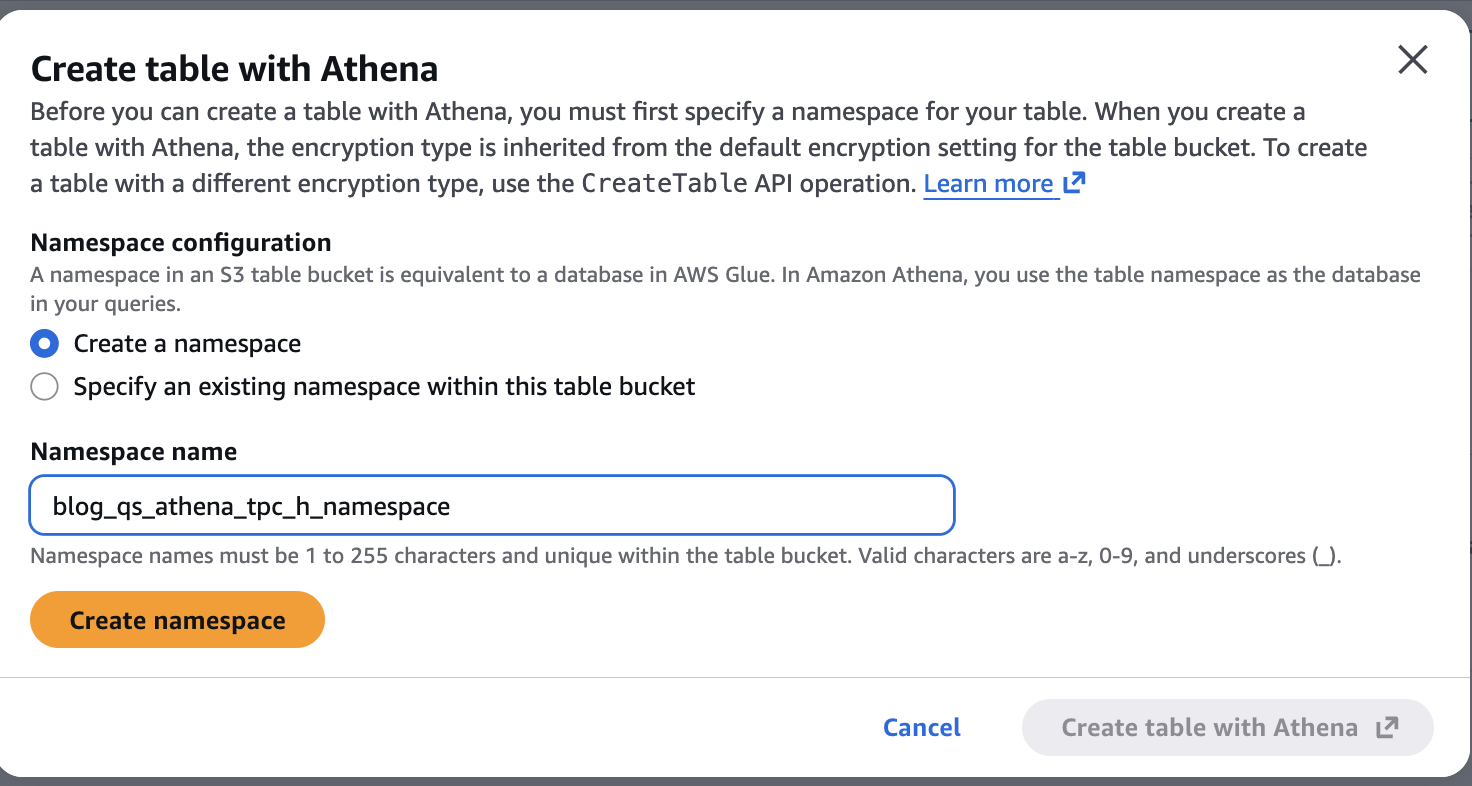
Determine 7: Create S3 desk Namespace blog_qs_athena_tpc_h_namespace
Step2: Create an Exterior CSV Desk for Line Objects – Use Athena to register the TPC-H line objects dataset as an exterior desk:
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.lineitem_csv
(
L_ORDERKEY BIGINT,
L_PARTKEY BIGINT,
L_SUPPKEY BIGINT,
L_LINENUMBER INT,
L_QUANTITY DECIMAL(15,2),
L_EXTENDEDPRICE DECIMAL(15,2),
L_DISCOUNT DECIMAL(15,2),
L_TAX DECIMAL(15,2),
L_RETURNFLAG STRING,
L_LINESTATUS STRING,
L_SHIPDATE STRING,
L_COMMITDATE STRING,
L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING,
L_SHIPMODE STRING,
L_COMMENT STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/lineitem/'
TBLPROPERTIES ('skip.header.line.depend' = '0');Preview the info:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.lineitem_csv LIMIT 10;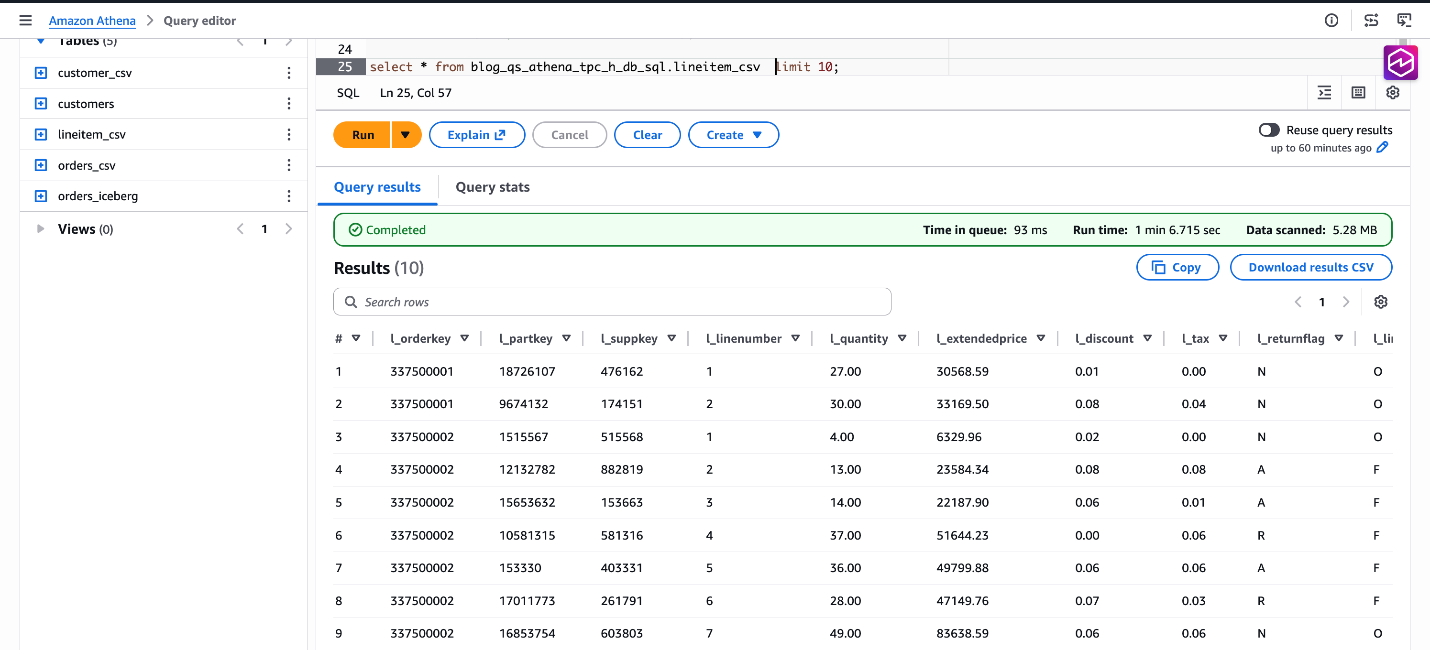
Determine 8: confirm knowledge blog_qs_athena_tpc_h_db_sql.lineitem_csv
Step3: Create the S3 Tables Desk Utilizing CTAS – Lastly, create a Parquet-formatted S3 Tables in your new catalog utilizing CTAS. We filter a pattern date vary to restrict the preliminary knowledge load based mostly on CAST(L_SHIPDATE AS DATE) BETWEEN DATE(‘1998-06-01’) AND DATE(‘1998-12-31’).
Notice: Be certain to make use of s3tablescatalog to run the next queries as proven within the following screenshot.
CREATE TABLE lineitem_csv_s3_table
WITH ( format="PARQUET")
AS
SELECT * FROM AwsDataCatalog.blog_qs_athena_tpc_h_db_sql.lineitem_csv
WHERE CAST(L_SHIPDATE AS DATE) BETWEEN DATE('1998-06-01') AND DATE('1998-12-31');Confirm the end result:
SELECT * FROM lineitem_csv_s3_table LIMIT 10;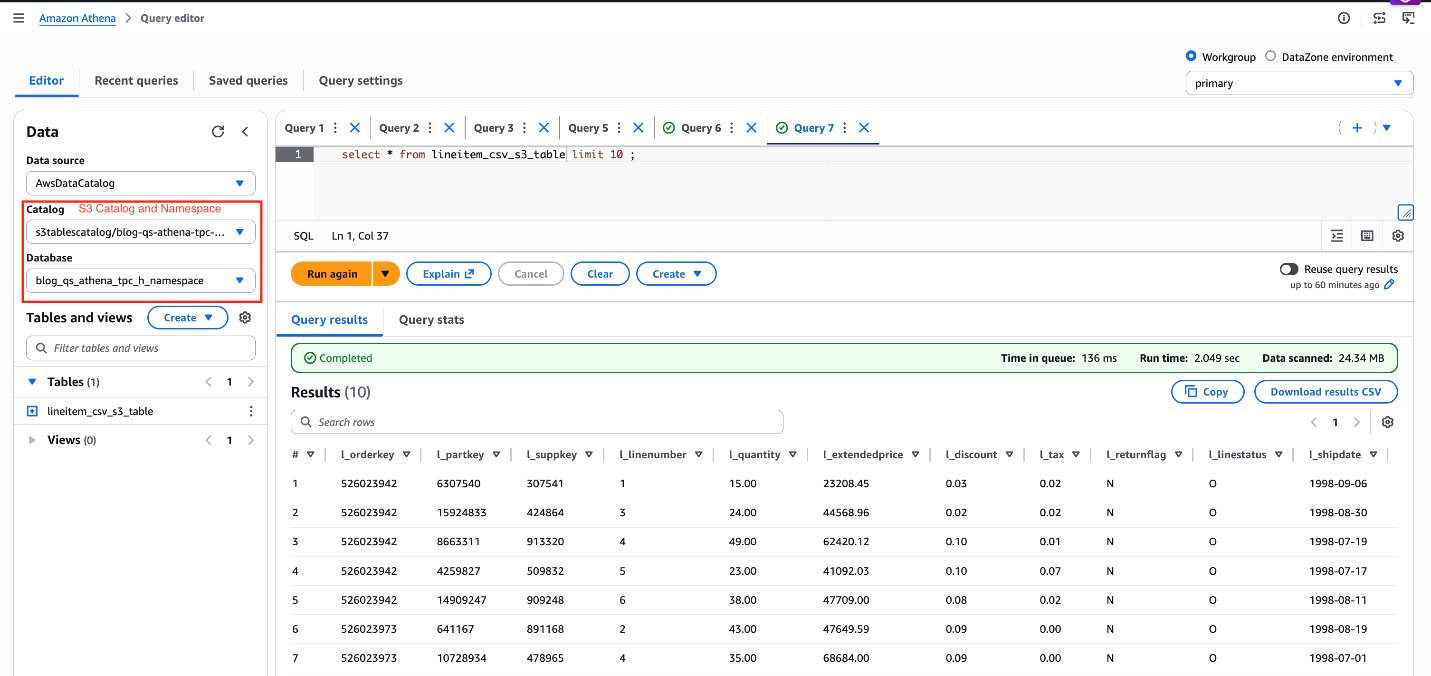
Determine 9: confirm knowledge lineitem_csv_s3_table
Dataset Preparation in Amazon Fast
Your Athena tables are registered and queryable. Now it’s time to convey that knowledge into Amazon Fast – connecting it, shaping it, and making it communicate the language of your corporation. This part walks by way of each step: connecting to the Athena knowledge supply, creating datasets and importing them into SPICE, becoming a member of the three SPICE datasets, configuring a Fast Subject for pure language Q&A, constructing and publishing a dashboard with Amazon Q, and establishing the Data Base that powers the agentic layer.
Information Supply Creation
Earlier than Amazon Fast can question your three tables in your knowledge lake, you create a single Athena knowledge supply connection. You may entry all three tables — the CSV exterior desk, the self-managed Iceberg Parquet desk, and the S3 Tables managed Iceberg desk — utilizing the identical connection as a result of all three are cataloged in AWS Glue Information Catalog and accessible by way of the identical Athena workgroup.
Steps:
- In Amazon Fast, navigate to Datasets → Information sources →Create knowledge supply.
- Choose Amazon Athena as the info supply kind.
- Enter a descriptive identify (for instance
tpch-lakehouse-athena). - Choose the Athena workgroup your crew makes use of for manufacturing queries. Utilizing a devoted workgroup enforces question price controls and separates Fast question site visitors from different workloads.
- Select Validate connection. Fast confirms it could attain Athena and the Glue Information Catalog.
- Choose Create knowledge supply.
Dataset Creation and SPICE Ingestion
With the Athena knowledge supply created, create one Fast dataset per desk. Import every dataset into SPICE — Fast’s Tremendous-fast, Parallel, In-memory Calculation Engine — to ship sub-second question efficiency in dashboards and agentic workflows, no matter how giant the underlying S3 knowledge grows.
Lake Formation Permissions
Earlier than creating datasets, be sure that the suitable knowledge entry permissions are in place:
- If Lake Formation will not be enabled: Permissions are managed on the Fast service position degree by way of commonplace IAM-based S3 entry management. Be certain the Fast service position (for instance,
aws-quicksight-service-role-v0) has the learn IAM permissions for the related S3 buckets and Athena assets. No extra Lake Formation configuration is required. - If Lake Formation is enabled: Lake Formation acts because the central authorization layer, overriding commonplace IAM-based S3 permissions. Grant permissions on to the Amazon Fast creator or IAM position:
- Open the AWS Lake Formation console.
- Select Permissions → Information permissions → Grant.
- Choose the SAML customers and teams.
- Enter Fast person ARN
- Select Named Information Catalog assets
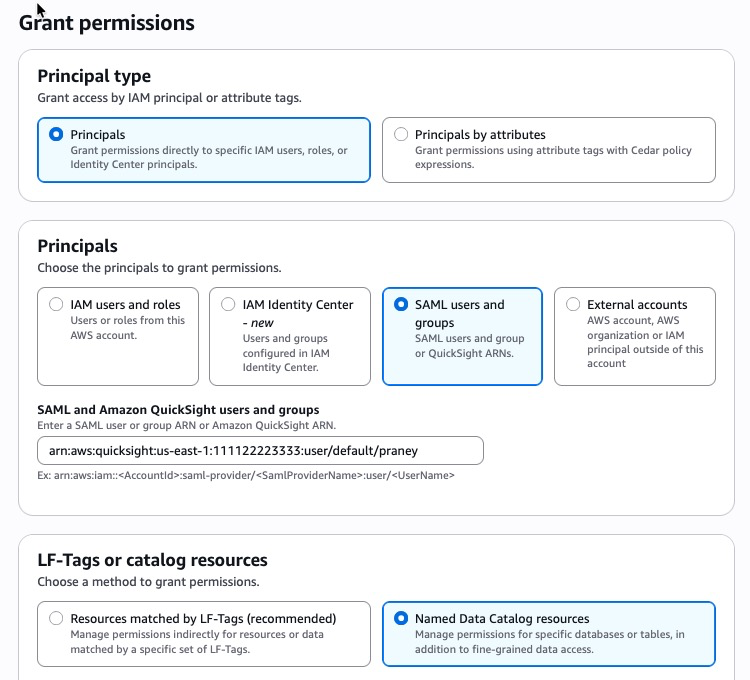
Determine 10: Lake Formation permissions
-
- Select the required databases, tables, and columns.
- Grant SELECT at minimal; add DESCRIBE for dataset creation.
- Repeat for every person or position that requires entry.
For step-by-step directions, see Securely analyze your knowledge with AWS Lake Formation and Amazon Fast Sight, and Accessing Amazon S3 Tables by way of Amazon Fast with AWS Lake Formation Permissions.
For S3 Tables particularly, the Fast service position additionally requires an extra glue:GetCatalog inline coverage to entry the non-default s3tablescatalog catalog — see Visualizing S3 desk knowledge with Amazon Fast for the precise coverage assertion.
Dataset 1 — CSV Exterior Desk (customer_csv)
- From the Athena knowledge supply, select Create dataset.
- Choose the Glue database and select the desk (for instance
customer_csv). - Choose Edit/Preview knowledge to open the info preparation expertise.
- Confirm column knowledge sorts and make modifications as wanted. Notice: If you’re utilizing the brand new knowledge preparation expertise, click on the Preview tab to evaluate the info earlier than continuing.
- Set Question mode to SPICE.
- Title the dataset
TPC-H Buyer (CSV)and choose Save & publish.
Dataset 2 — Self-Managed Iceberg Parquet (orders_iceberg)
- From the identical Athena knowledge supply, select Create dataset.
- Choose the Glue database and select the desk (for instance
orders_iceberg). - Choose Edit/Preview knowledge to open the info preparation expertise.
- Confirm column knowledge sorts and make modifications as wanted. Notice: If you’re utilizing the brand new knowledge preparation expertise, click on the Preview tab to evaluate the info earlier than continuing.
- Set Question mode to SPICE.
- Title the dataset
TPC-H Orders (Iceberg)and choose Save & publish.
Dataset 3 — S3 Tables Managed Iceberg (lineitem_csv_s3_table)
S3 Tables are saved in a non-default AWS Glue catalog (s3tablescatalog), not in the usual AWSDataCatalog. Due to this, the Fast visible desk browser can’t show S3 Tables — they don’t seem within the “Select your desk” pane. You have to use Customized SQL to question S3 Tables knowledge and create a Fast dataset from it.
- From the identical Athena knowledge supply, select Create dataset.
- Choose Use customized SQL.
- Choose Edit/Preview knowledge to open the info preparation expertise.
- Enter an Athena SQL question referencing the S3 Tables catalog utilizing the
“s3tablescatalog/syntax:”.” ”.” ”
SELECT * FROM "s3tablescatalog/blog-qs-athena-tpc-h-db-sql-s3-table-mar-3"."blog_qs_athena_tpc_h_namespace"."lineitem_csv_s3_table"- Select Apply. Fast executes the question by way of Athena and previews the end result set.
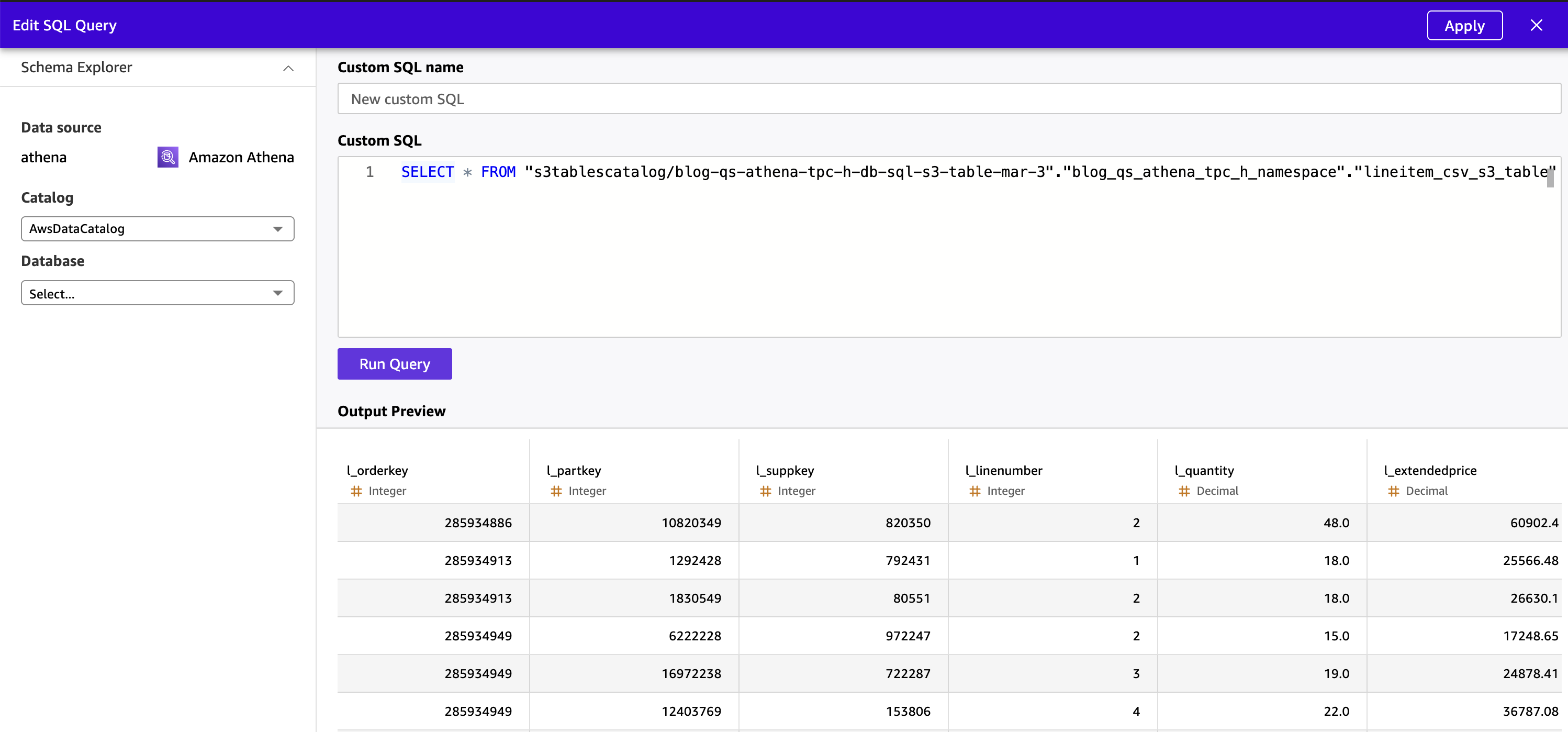
Determine 11: Preview S3 Desk knowledge from Fast
- Confirm column knowledge sorts and make modifications as wanted.
- Set Question mode to SPICE.
- Title the dataset
TPC-H Lineitem (S3 Tables)and choose Save & publish.
Notice: This tradition SQL requirement applies particularly to S3 Tables as a result of they reside in a toddler Glue catalog registered individually from the default AWSDataCatalog. The CSV and Iceberg tables in the usual catalog are seen within the desk browser and don’t require customized SQL.
Becoming a member of Datasets
The TPC-H schema is a star schema by design, and Amazon Fast’s visible knowledge preparation expertise helps becoming a member of datasets instantly within the UI. On this answer, we’ll pre-join all three tables in Athena utilizing Customized SQL and ingest the unified end result instantly into SPICE as a single flat dataset. This removes Fast’s secondary desk measurement constraint fully and delegates the be part of to Athena, which handles tables of various scale.
Notice on the cross-source JOIN restrict: In case your secondary tables (orders_iceberg + customer_csv) are sufficiently small to suit beneath 1 GB mixed, you may carry out the be part of inside Fast’s visible knowledge preparation expertise by opening the most important desk first (making it the first) and including the smaller tables as secondary joins. For giant TPC-H scale elements the place the lineitem desk dominates, the Athena pre-join method beneath is the advisable path.
Steps:
- From the Athena knowledge supply, select Create dataset.
- Choose Use customized SQL.
- Choose Edit/Preview knowledge to open the info preparation expertise.
- Enter the next Athena SQL question, which joins all three tables throughout the default Glue catalog (
blog_qs_athena_tpc_h_db_sql) and the S3 Tables non-default catalog (s3tablescatalog):
SELECT
c.c_custkey,
c.c_name,
c.c_mktsegment,
c.c_nationkey,
o.o_orderkey,
o.o_orderdate,
o.o_orderstatus,
o.o_totalprice,
o.o_orderpriority,
l.l_linenumber,
l.l_partkey,
l.l_suppkey,
l.l_quantity,
l.l_extendedprice,
l.l_discount,
l.l_shipmode,
l.l_returnflag
FROM "s3tablescatalog/blog-qs-athena-tpc-h-db-sql-s3-table-mar-3"."blog_qs_athena_tpc_h_namespace"."lineitem_csv_s3_table" l
INNER JOIN "blog_qs_athena_tpc_h_db_sql"."orders_iceberg" o
ON l.l_orderkey = o.o_orderkey
INNER JOIN "blog_qs_athena_tpc_h_db_sql"."customer_csv" c
ON o.o_custkey = c.c_custkey; The question joins the three tables utilizing the TPC-H overseas key relationships:
lineitem_csv_s3_table.l_orderkey = orders_iceberg.o_orderkey(Lineitem → Orders)orders_iceberg.o_custkey = customer_csv.c_custkey(Orders → Buyer)
Tip: Use express double quotes round each the database and desk names in Athena SQL — this helps stop parse errors brought on by hyphens or different particular characters in identifier names, significantly for S3 Tables catalog paths.
- Select Apply. Fast executes the question by way of Athena and previews the unified end result set.
- Confirm column knowledge sorts and make modifications as wanted. Conceal inner key columns (
c_custkey,o_custkey,o_orderkey,l_orderkey) that enterprise customers don’t have to see in dashboards or Q&A.
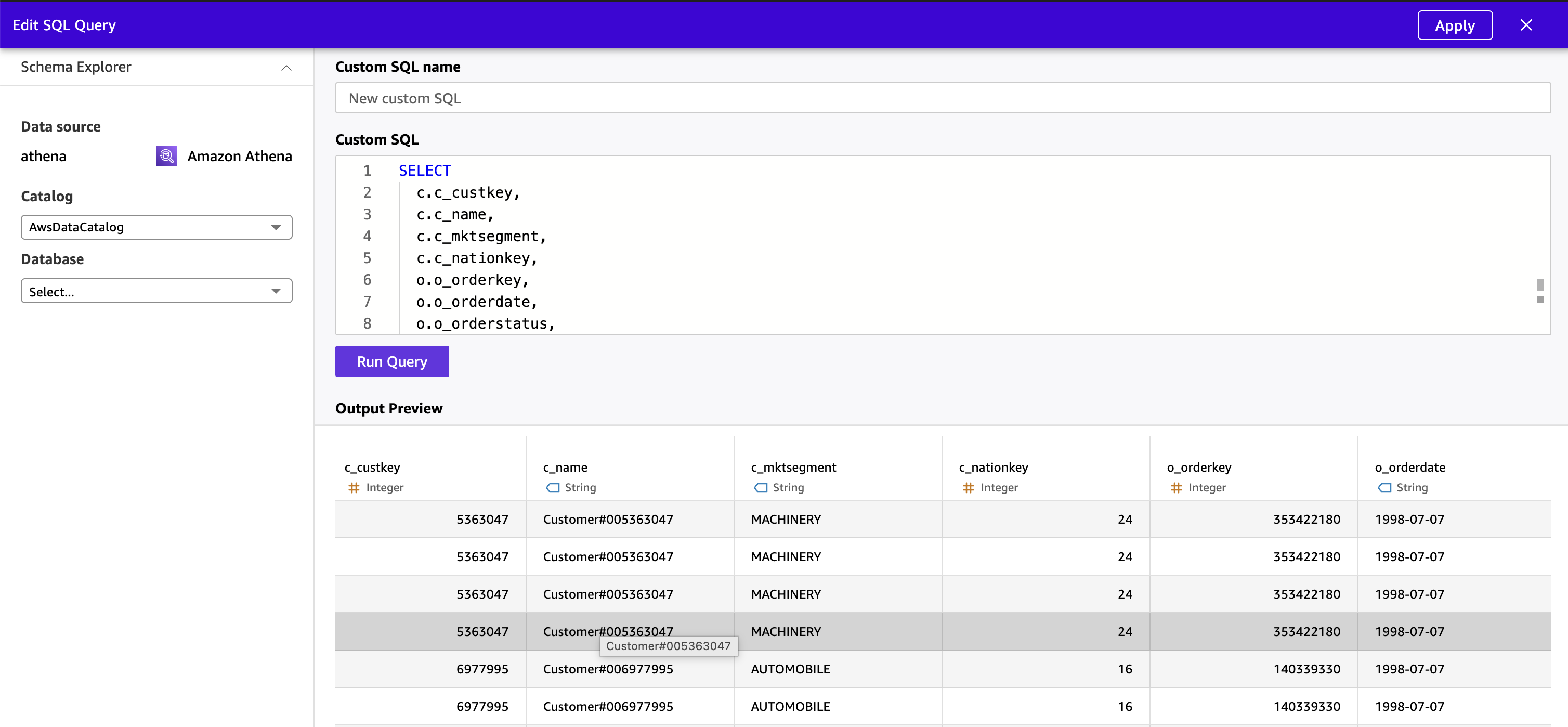 Determine 12 : Preview denormalized knowledge from Fast
Determine 12 : Preview denormalized knowledge from Fast
- Set Question mode to SPICE.
- Title the dataset
TPC-H Unified (Joined)and choose Save & publish and look ahead to the SPICE dataset standing change to “Prepared” (anticipated time 2-3 minutes)
The joined dataset is now a single, denormalized SPICE dataset combining buyer, order, and line merchandise knowledge throughout all three desk codecs — CSV exterior, self-managed Iceberg Parquet, and S3 Tables managed Iceberg — prepared for each dashboard authoring and pure language Q&A.
Fast Subject Configuration
A Fast Subject is the semantic layer that interprets column names into enterprise ideas. When a person asks “What was complete income final quarter by buyer phase?”, the Subject maps income to l_extendedprice, “final quarter” to a date filter on o_orderdate, and buyer phase to c_mktsegment. And not using a well-configured Subject, pure language queries return generic or incorrect outcomes. With one, they return exact, cited solutions in seconds.
Steps:
- In Amazon Fast, navigate to Matters → Create matter.
- Enter a reputation
TPC-H Analyticsand a plain-language description: “Buyer, order, and line merchandise knowledge from the TPC-H benchmark dataset, protecting income, pricing, reductions, order standing, and buyer market segments.” - Choose the
TPC-H Unified(Joined) dataset as the info supply. - Fast analyzes the dataset and auto-generates area configurations (anticipated time to finish 8-10 min). Assessment every area on the Information tab:
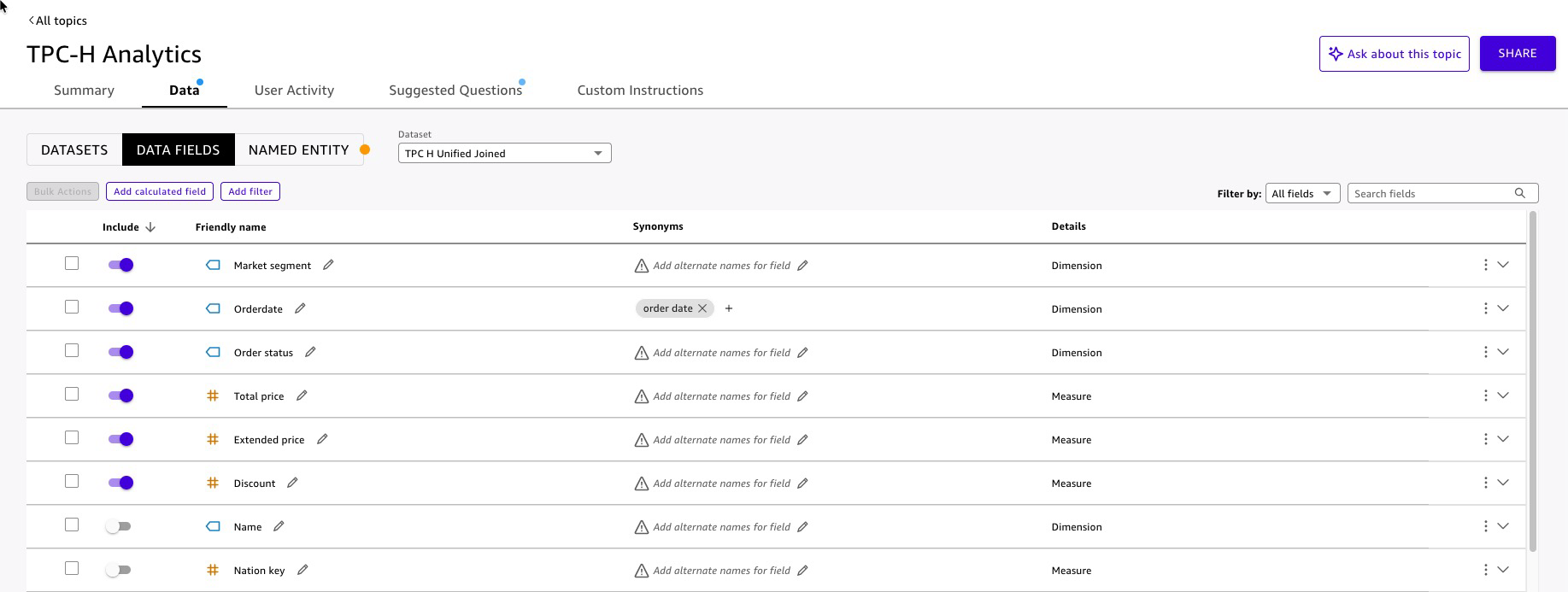 Determine 13: Fast Subject enhancement
Determine 13: Fast Subject enhancement
- Add named entities for widespread enterprise groupings.
- Add prompt questions to information first-time customers:
- “What’s complete income by order standing this 12 months?”
- “Which buyer segments positioned essentially the most orders final quarter?”
- “Present me the highest 10 orders by complete worth final month.”
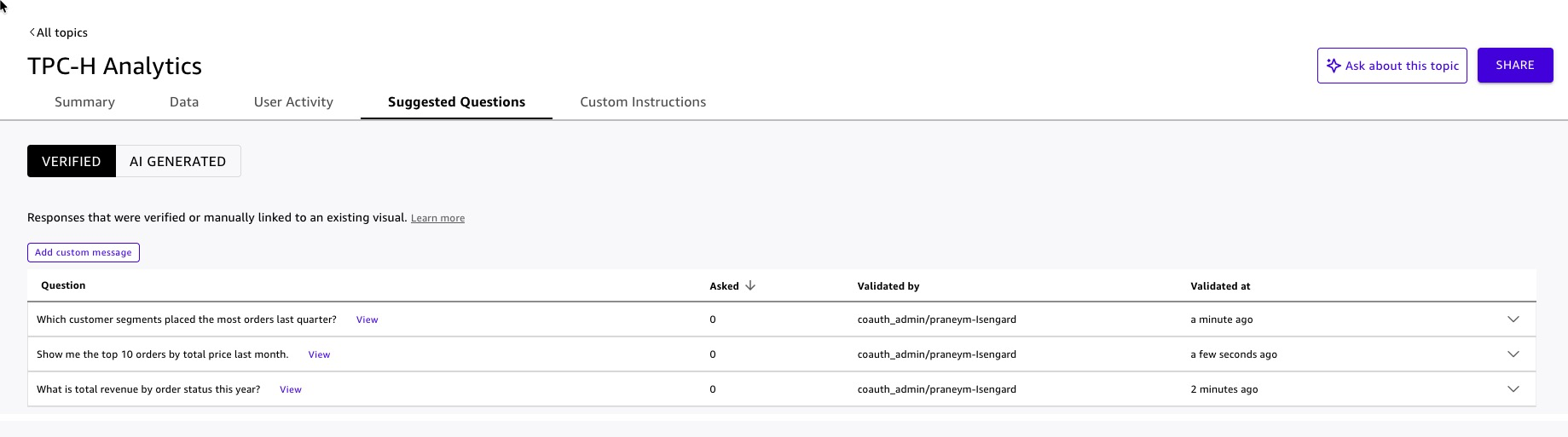 Determine 14: Fast Subject prompt questions
Determine 14: Fast Subject prompt questions
Dashboard Construct and Publish with Amazon Q
Amazon Q in Fast lets authors construct dashboards utilizing pure language — describe the visible you need, and Q generates it. This accelerates dashboard growth from days to minutes and retains the give attention to enterprise storytelling moderately than chart configuration.
Steps:
- In Amazon Fast, navigate to Analyses → Create evaluation.
- Choose the
TPC-H Unified (Joined)dataset. - Open the Amazon Q panel .
- Use pure language prompts to construct every visible and Add to Evaluation:
- “Present a KPI card for complete income.”
- “Add a bar chart displaying prolonged income by order standing.”
- “Create a scatter plot of low cost price versus prolonged income by buyer phase.”
- For every generated visible, evaluate the sector mappings and modify titles, axis labels, and colour encoding to match your group’s type information.
- Add a filter management on
o_orderdateso dashboard viewers can scope the info to a time vary of their selection with out requesting a brand new report. - Click on Handle Q&A to decide on radio button and choose
TPC-H Analyticsmatter for enabling Dashboard Q&A. This embeds a pure language question bar instantly within the printed dashboard, permitting viewers to ask follow-up questions with out leaving the dashboard. Fast routinely extracts semantic info from the dashboard visuals to energy the Q&A expertise. - Choose Publish, identify it
TPC-H Lakehouse Analytics. - Optionally, Fast permits to share dashboard.
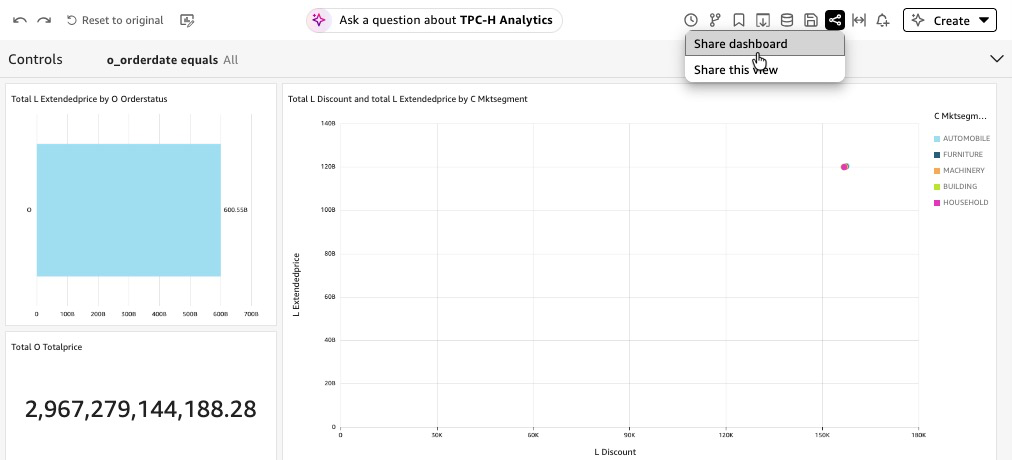
Determine 15: Share Dashboard
Agentic AI Integration with Amazon Fast
Your SPICE datasets are loaded, your Subject is printed, and your dashboard is dwell. Every of those is effective by itself. Collectively, unified inside a Fast Area, surfaced by way of a customized Chat Agent and listed Data Base, they grow to be one thing qualitatively totally different: an agentic AI system that solutions questions, retrieves context, and drives motion — all from a single conversational interface.
Data Base Configuration
The Data Base offers the Chat Agent entry to unstructured context that structured knowledge alone can’t reply — knowledge dictionaries, schema documentation, enterprise guidelines, and area reference materials. For this answer, the Data Base is constructed from TPC-H unstructured knowledge: the official TPC-H specification doc describing how your group maps TPC-H fields to enterprise ideas.
Steps:
- In Amazon Fast, navigate to Integrations → Data bases → Webcrawler.
- Add TPC-H specification (PDF) doc content material URL : https://www.tpc.org/tpc_documents_current_versions/pdf/tpc-h_v2.17.1.pdf.
- Title the data base
TPC-H Reference Data Base. - Choose Create.
Fast indexes the doc and makes it searchable by the Chat Agent at question time. The agent retrieves related passages — not whole doc — so responses keep grounded and concise.
Greatest observe: Preserve every doc targeted on a single matter. A 5-page knowledge dictionary is extra helpful to the agent than a 200-page mixed specification, as a result of the agent retrieves by relevance — smaller, targeted paperwork produce extra exact retrievals.
Area Creation
A Fast Area is the organizational layer that abstracts your knowledge property — Matters, Data Bases, dashboards, and datasets — right into a single, ruled context boundary. The Chat Agent you construct within the subsequent step doesn’t question Matters and Data Bases instantly. It queries the Area. This design offers you one place to handle what the agent is aware of, who can entry it, and what it’s allowed to floor.
Steps:
- In Amazon Fast, navigate to Areas → Create area.
- Title the area
TPC-H Lakehouse Analytics Area. - Add assets to the area:
Add the Subject:
- Choose Add data → Matters.
- Select
TPC-H Analytics(the Subject configured within the Fast Subject Configuration part). - The agent can now reply structured knowledge questions — income, orders, buyer segments — by querying the Subject by way of the Area.
Add the Data Base:
- Choose Add data → Data bases.
- Select
TPC-H Reference Data Base(the Data Base configured within the Data Base Configuration part). - The agent can now retrieve unstructured context from the TPC-H specification doc — together with the enterprise intent of all 22 benchmark queries, question definitions, and the conceptual knowledge mannequin. When a person asks “What’s TPC-H Question 3 designed to measure?” or “What does the TPC-H specification say about order precedence?”, the agent retrieves the related passage from the specification and cites it within the response.
Add the Dashboard:
- Choose Add data → Dashboards.
- Select
TPC-H Lakehouse Analytics(the dashboard configured within the Dashboard Construct and Publish with Amazon Q part) - The agent can reference dashboard visuals and direct customers to particular views when answering questions.
The Area now encapsulates every part the Chat Agent wants: structured knowledge by way of the Subject, unstructured context by way of the Data Base, and visible references by way of the Dashboard. The agent queries the Area; the Area enforces the boundaries. Fast enforces the identical safety guidelines from the underlying data contained in the Area — customers within the Area see solely the info their position permits, no matter how they ask the query.
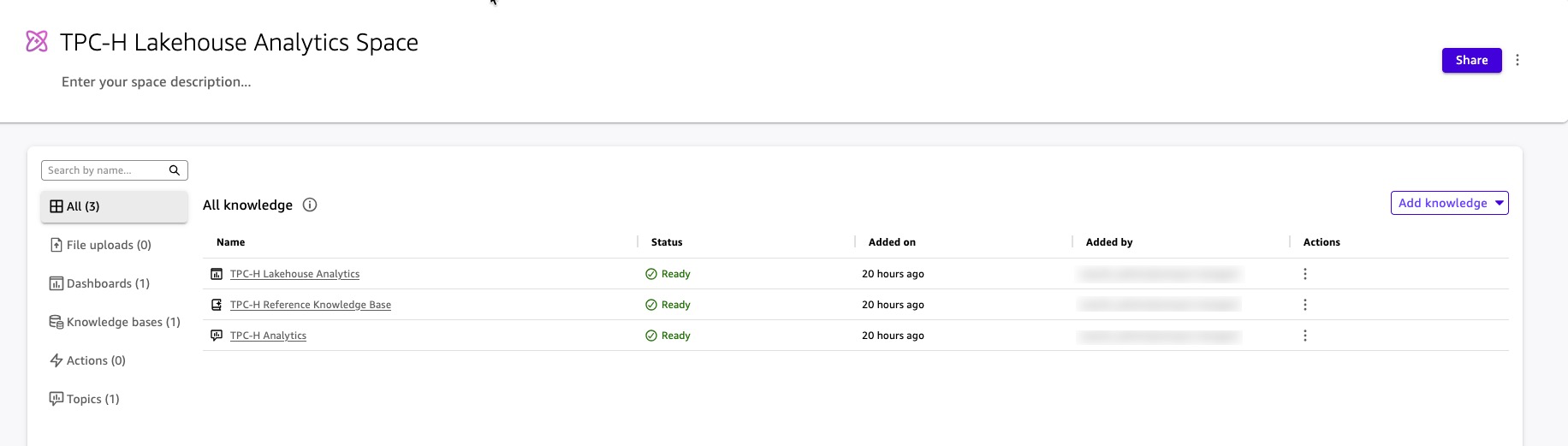 Determine 16: Artifacts in Area
Determine 16: Artifacts in Area
Customized Chat Agent Creation
The Chat Agent is the interface your corporation customers work together with. It isn’t a generic assistant — it’s a purpose-built, ruled AI teammate scoped to TPC-H Lakehouse Analytics Area. Customers ask questions in plain English. The agent causes over the Area, retrieves the best mixture of structured knowledge and unstructured context, and returns grounded, cited solutions.
Steps:
- In Amazon Fast, navigate to Chat brokers → Create chat agent.
- Write the persona directions in plain language:
“You’re the TPC-H Analytics Agent for [Your Organization]. You assist enterprise analysts and knowledge engineers reply questions on order income, provider efficiency, line merchandise pricing, and stock availability utilizing the TPC-H lakehouse dataset. At all times floor your solutions in knowledge from the TPC-H Lakehouse Analytics Area. When a person asks a query that requires a chart or desk, retrieve the reply from the Subject and current it clearly. When a person asks about schema definitions, question logic, or knowledge dictionary phrases, retrieve the reply from the Data Base. Don’t speculate. When you can’t discover a grounded reply, say so and counsel a follow-up query.”
- Enter a reputation:
TPC-H Analytics Agent. - Connect the Area: Fast can establish and fasten
TPC-H Lakehouse Analytics Area. Optionally, you add the area with the next steps.- Beneath Data sources, choose Hyperlink areas.
- Select
TPC-H Lakehouse Analytics Area. - The agent now has entry to the Subject, Data Base, and Dashboard by way of the Area — no direct dataset connections are wanted.
- Configure customization choices:
- Welcome message: Add a customized greeting that seems when customers first open the chat agent (e.g., “Hiya! I’m your TPC-H Analytics Agent. Ask me about order income, buyer segments, or line merchandise pricing.”)
- Steered prompts: Add 3-5 starter inquiries to information customers on what the agent can reply (e.g., “What was complete income final quarter?”, “Present me high prospects by order quantity”, “Clarify the Transport Precedence Question”)
- These customization choices assist customers perceive the agent’s capabilities instantly and scale back the training curve for first-time interactions.
- Preview and take a look at the agent utilizing the built-in preview panel on the best facet of the configuration web page earlier than publishing. Check with questions that span each knowledge sources:
- “What was complete income for fulfilled orders final quarter?” — retrieves from the Subject and Dashboard (structured knowledge).
- “What does the l_shipmode area symbolize?” — retrieves from the Data Base (TPC-H specification).
- “Present me the highest 5 buyer segments by order quantity.” — retrieves from the Subject and returns a ranked end result.
- “What enterprise query does the Transport Precedence Question reply?” — retrieves from Part 2.4.3 of the TPC-H specification within the Data Base.
- Choose Launch chat agent to avoid wasting and publish the modifications.
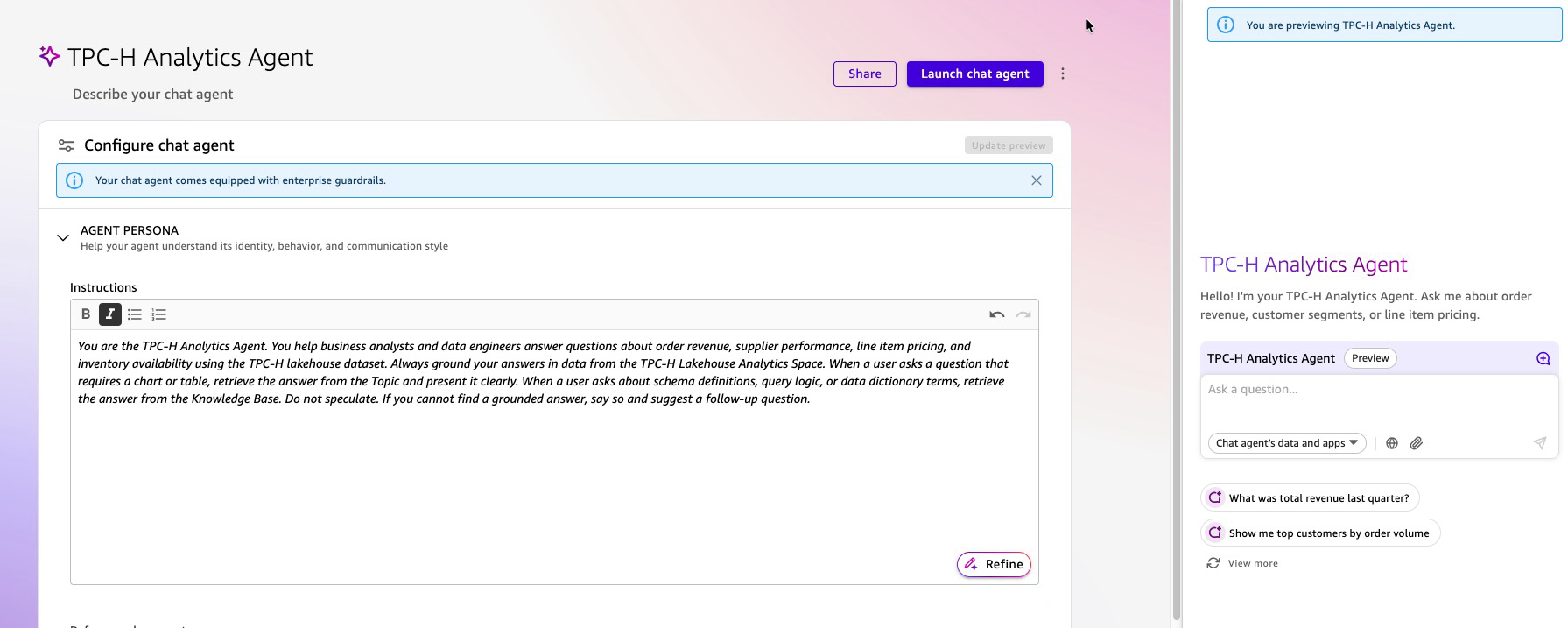 Determine 17: Work together with Agent
Determine 17: Work together with Agent
What Your Customers Expertise
A enterprise analyst opens the TPC-H Analytics Agent and kinds:
“Which buyer phase drove essentially the most income final month, and what does ‘market phase’ imply within the TPC-H schema?”
The agent:
- Queries the
TPC-H AnalyticsSubject by way of the Area for income byc_mktsegmentfiltered to final month — returning a ranked end result from SPICE. - Concurrently retrieves the definition of
c_mktsegmentfrom the TPC-H knowledge dictionary within the Data Base. - Returns a single, unified reply: the ranked income end result with a quotation to the SPICE dataset, adopted by the schema definition with a quotation to the specification doc.
No SQL. No dashboard navigation. No ticket to the info crew. The reply arrives in a single response, grounded in two sources, with each declare traceable to its origin.
Cleanup
Run following steps to take away the artifacts created by this weblog put up
Lakehouse / Information Lake Artifacts
Run following steps utilizing Athena console
Drop Tables
DROP TABLE blog_qs_athena_tpc_h_db_sql.customer_csv;
DROP TABLE blog_qs_athena_tpc_h_db_sql.orders_csv;
DROP TABLE blog_qs_athena_tpc_h_db_sql.orders_iceberg;
DROP TABLE blog_qs_athena_tpc_h_db_sql.lineitem_csv;
DROP TABLE lineitem_csv_s3_table; --(use S3 catalog configuration) Drop Databases
DROP DATABASE blog_qs_athena_tpc_h_db_sql; Drop S3 Desk bucket
- To delete
lineitem_csv_s3_tabledesk, use the AWS CLI, AWS SDKs, or Amazon S3 REST API. Study extra - To delete namespace
blog_qs_athena_tpc_h_namespace, use the AWS CLI, AWS SDKs, or Amazon S3 REST API. Study extra - To delete
blog-qs-athena-tpc-h-db-sql-s3-table-mar-3desk bucket, use the AWS CLI, AWS SDKs, or Amazon S3 REST API. Study extra
Drop S3 bucket
Use S3 console to take away S3 bucket amzn-s3-demo-bucket.
Fast Artifacts
Delete the Customized Chat Agent
- In Amazon Fast, navigate to Brokers.
- Choose
TPC-H Analytics Agentand select Delete. - Verify the deletion.
Delete the Area
- Navigate to Areas.
- Choose
TPC-H Lakehouse Analytics Areaand select Delete. - Verify the deletion. This removes the Area however doesn’t delete the underlying Matters, Data Bases, or Dashboards — these have to be deleted individually.
Delete the Dashboard
- Navigate to Dashboards.
- Choose
TPC-H Lakehouse Analyticsand select Delete. - Verify the deletion.
Delete the Subject
- Navigate to Matters.
- Choose
TPC-H Analyticsand select Delete. - Verify the deletion.
Delete the Data Base
- Navigate to Integrations → Data bases.
- Choose
TPC-H Reference Data Baseand select Delete data base. - Verify the deletion. This removes the Data Base and the listed paperwork.
Delete the Datasets
- Navigate to Datasets.
- Choose every of the next datasets and select Delete:
TPC-H Unified (Joined)TPC-H Buyer (CSV)TPC-H Orders (Iceberg)TPC-H Lineitem (S3 Tables)
- Verify every deletion. This removes the SPICE knowledge and frees the related SPICE capability.
Delete the Information Supply
- Navigate to Datasets → Information sources.
- Choose
tpch-lakehouse-athenaand select Delete. - Verify the deletion.
Conclusion
This structure demonstrates how Amazon Fast’s agentic AI transforms enterprise knowledge analytics from a technical bottleneck into an accessible self-service functionality. By integrating Amazon S3, AWS Glue Information Catalog, Amazon Athena, and Amazon Lake Formation with Amazon Fast’s conversational AI brokers and dashboards, enterprise customers can now question complicated lakehouse knowledge by way of pure language interfaces with out requiring SQL or BI experience. The answer seamlessly combines structured TPC-H datasets throughout a number of storage codecs (S3 Desk, Iceberg, Parquet) with unstructured knowledge from data bases, enabling richer contextual insights. This democratization of knowledge entry accelerates decision-making throughout industries whereas sustaining enterprise-grade safety, governance, and scalability for contemporary data-driven organizations.
Subsequent steps
Reference Getting began tutorial for extra use instances utilizing B2B, income, gross sales, advertising and marketing, and HR datasets. To dive deeper in Lake Formation permission with Fast reference AWS documentation “Utilizing AWS Lake Formation with Fast“ and weblog put up – “Securely analyze your knowledge with AWS Lake Formation and Amazon Fast Sight”. Be part of Amazon Fast Neighborhood to search out solutions to your questions, studying assets, and occasions in your space.
For added learn reference following hyperlinks –
Modernize Enterprise Intelligence Workloads Utilizing Amazon Fast
Greatest practices for Amazon Fast Sight SPICE and direct question mode
Accessing Amazon S3 Tables by way of Amazon Fast with AWS Lake Formation Permissions AWS safety in Fast.
In regards to the authors



{kind=link}