
This publish was co-authored with Krišjānis Kočāns, Kaspars Magaznieks, Sergei Kiriasov from Solar Finance Group
When you course of identification paperwork at scale—mortgage functions, account openings, compliance checks—you’ve possible hit the identical wall: conventional optical character recognition (OCR) will get you partway there, however extraction errors nonetheless push a big share of functions into guide assessment queues. Add fraud detection to the combination, and the guide workload compounds.
Solar Finance, a Latvian fintech based in 2017, operates as a technology-first on-line lending market throughout 9 nations. The corporate processes a brand new mortgage request each 0.63 seconds and delivers greater than 4 million evaluations month-to-month. In considered one of their highest-volume industries, with 80,000 month-to-month functions for microloans, roughly 60% of functions required guide operator assessment. Solar Finance partnered with the AWS Generative AI Innovation Middle to rebuild the pipeline. Inside 35 enterprise days of handover, the answer was stay in manufacturing. The next timeline exhibits the complete undertaking journey from kickoff to manufacturing launch.
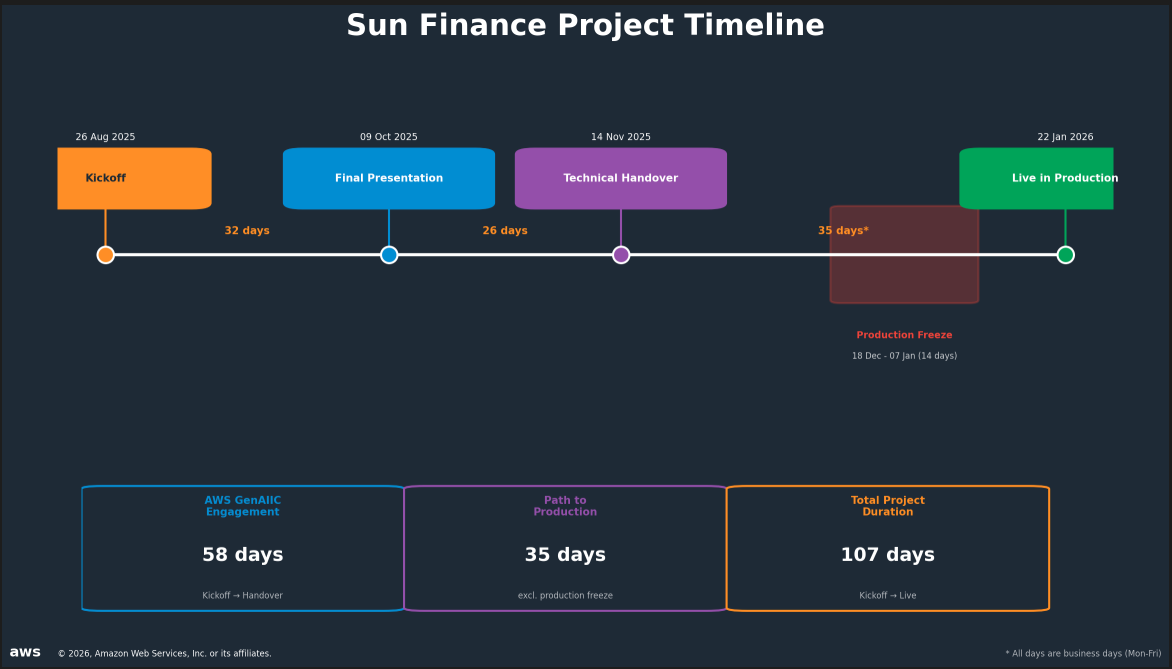
Solar Finance undertaking timeline from kickoff to manufacturing
The undertaking moved by means of 4 milestones over 107 enterprise days. The AWS Generative AI Innovation Middle engagement ran 32 days from kickoff (August 26, 2025) to remaining presentation (October 9, 2025), adopted by 26 days for technical handover (November 14, 2025). Solar Finance then took 35 enterprise days to maneuver the answer into manufacturing, together with a 14-day manufacturing freeze over the vacation interval (December 18 – January 7), and went stay on January 22, 2026.
On this publish, we present how Solar Finance used Amazon Bedrock, Amazon Textract, and Amazon Rekognition to construct an AI-powered identification verification (IDV) pipeline. The answer improved extraction accuracy from 79.7% to 90.8%, reduce per-document prices by 91%, and diminished processing time from as much as 20 hours to underneath 5 seconds. You’ll find out how combining specialised OCR with massive language mannequin (LLM) structuring outperformed utilizing both device alone. You’ll additionally discover ways to architect a serverless fraud detection system utilizing vector similarity search.
The Identification Verification Problem
Solar Finance had constructed its first IDV automation in 2019 utilizing Amazon Rekognition and Amazon Textract. As the corporate expanded into creating areas, the system’s limitations turned exhausting to disregard.
This area introduced distinctive challenges with language and doc complexity. Processing paperwork in each English and a neighborhood language proved tough for conventional OCR programs. The native language textual content stays underrepresented in conventional OCR coaching datasets, inflicting frequent extraction errors. Solar Finance additionally wanted to deal with 7 completely different ID varieties, every with completely different layouts and codecs.
The guide workload was primarily pushed by OCR errors. Of the 60% of functions requiring guide assessment, roughly 80% of circumstances stemmed from mismatches between extracted data and customer-entered knowledge. Critically, 60% of those mismatches have been OCR errors, not buyer errors. The remaining 20% of guide interventions associated to fraud detection flags.
Fraud detection added one other layer of complexity. About 10% of every day requests have been precise fraudulent functions. Fraudsters used comparable photos with distinctive patterns to bypass primary controls whereas submitting a number of mortgage functions. Figuring out these patterns required time-intensive guide assessment throughout quite a few photos.
Value and pace constraints blocked enlargement. The per-document price and roughly 3 full-time equivalents (FTEs) devoted to guide verification on this area alone meant the unit economics blocked enlargement into industries with lower-value microloans. Processing occasions ranged from underneath 10 minutes for automated circumstances to twenty hours for guide critiques outdoors enterprise hours.
Resolution overview
The AWS Generative AI Innovation Middle ran a 6-week proof-of-concept (September–October 2025) centered on one high-volume {industry}. The crew constructed two AI-powered options: an ID extraction system and a fraud detection system. Each have been deployed as a completely serverless structure on AWS.The answer makes use of the next key providers:
- Amazon Bedrock – For AI structuring and visible evaluation utilizing Anthropic’s Claude Sonnet 4, and vector era utilizing Amazon Titan Multimodal Embeddings.
- Amazon Textract – For main OCR textual content extraction from identification paperwork.
- Amazon Rekognition – For fallback OCR, face detection, and face masking.
- Amazon S3 Vectors – For serverless vector similarity search towards identified fraud patterns.
- AWS Step Features – For orchestrating parallel fraud detection workflows.
- AWS Lambda – For serverless compute throughout each pipelines.
The next diagram illustrates the answer structure.
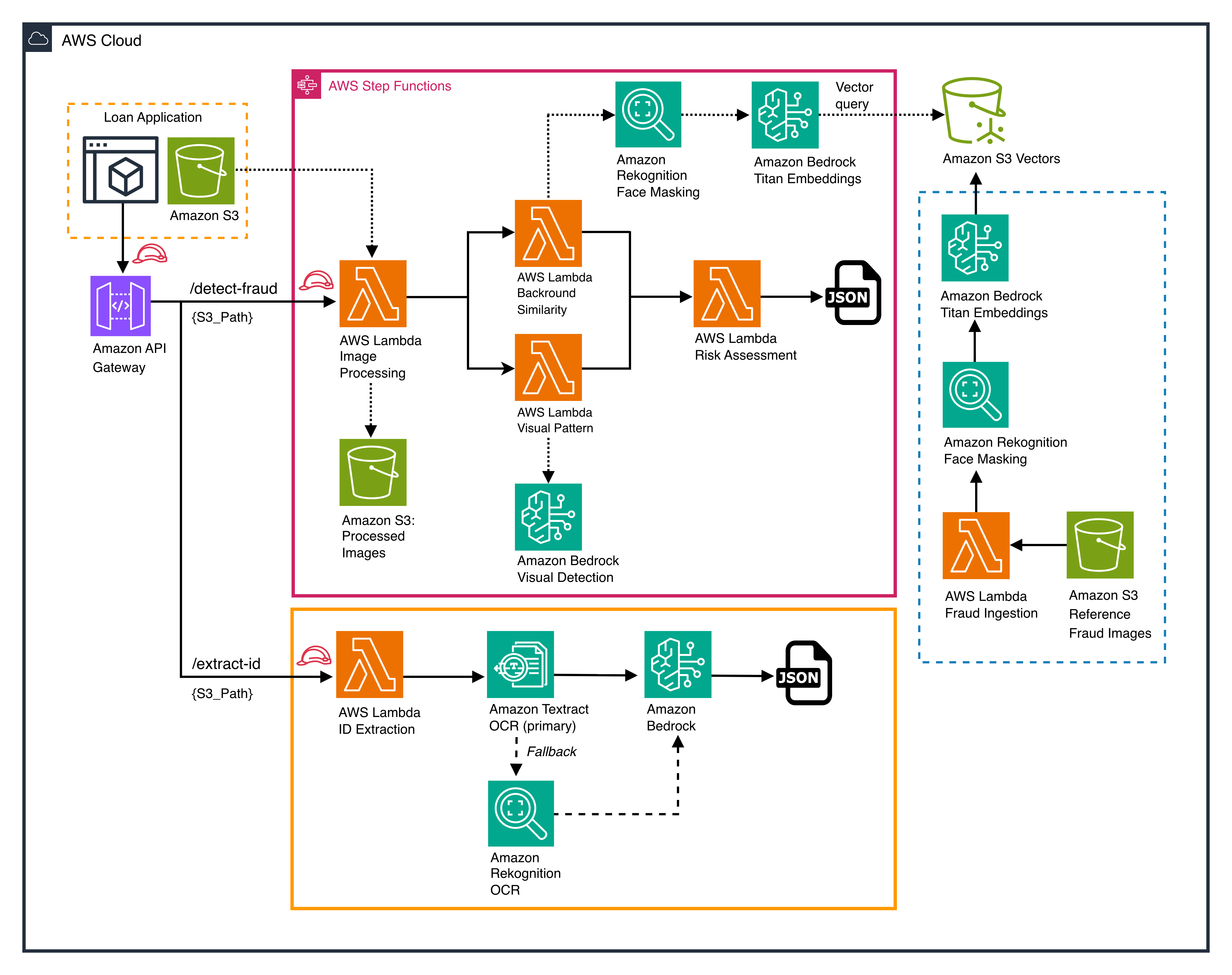
Solar Finance API structure displaying ID extraction and fraud detection routes
The structure exposes two API routes by means of Amazon API Gateway, with mortgage software knowledge saved in Amazon Easy Storage Service (Amazon S3):
- `/extract-id` route (ID extraction). An AWS Lambda operate receives the ID picture and sends it to Amazon Textract for main OCR. If Amazon Textract returns low-confidence outcomes, the system falls again to Amazon Rekognition for OCR. The extracted textual content is then handed to Amazon Bedrock (Claude Sonnet 4), which constructions it into standardized JSON fields.
- `/detect-fraud` route (fraud detection). An AWS Lambda operate triggers an AWS Step Features workflow that runs two checks in parallel:
- Background similarity — Amazon Rekognition masks the face from the selfie picture, then Amazon Bedrock Titan Multimodal Embeddings generates a vector illustration of the background. This vector is queried towards Amazon S3 Vectors to seek out matches with identified fraud patterns.
- Visible sample detection — Amazon Bedrock (Claude Sonnet 4) analyzes the picture for display screen picture artifacts and digital manipulation.
Each outcomes feed right into a Lambda-based threat evaluation operate that produces a mixed fraud rating as JSON.
- Fraud ingestion pipeline (proper aspect). Confirmed fraud photos are ingested from Amazon S3 by means of a Lambda operate. The photographs are processed by Amazon Rekognition for face masking, vectorized by Amazon Bedrock Titan Embeddings, and saved in Amazon S3 Vectors. This grows the reference database over time.
Stipulations
To implement an identical answer, you want the next:
Resolution walkthrough
This part walks by means of the 2 core pipelines: ID extraction and fraud detection.
ID extraction pipeline
The ID extraction system didn’t arrive at its remaining design on day one. The crew iterated by means of three distinct approaches over 4 weeks, and every failure pointed towards the following enchancment. The next diagram exhibits how the pipeline advanced from a single Claude Sonnet 4 through Amazon Bedrock strategy at 61.8% accuracy to the ultimate multi-tier design at 90.8%.
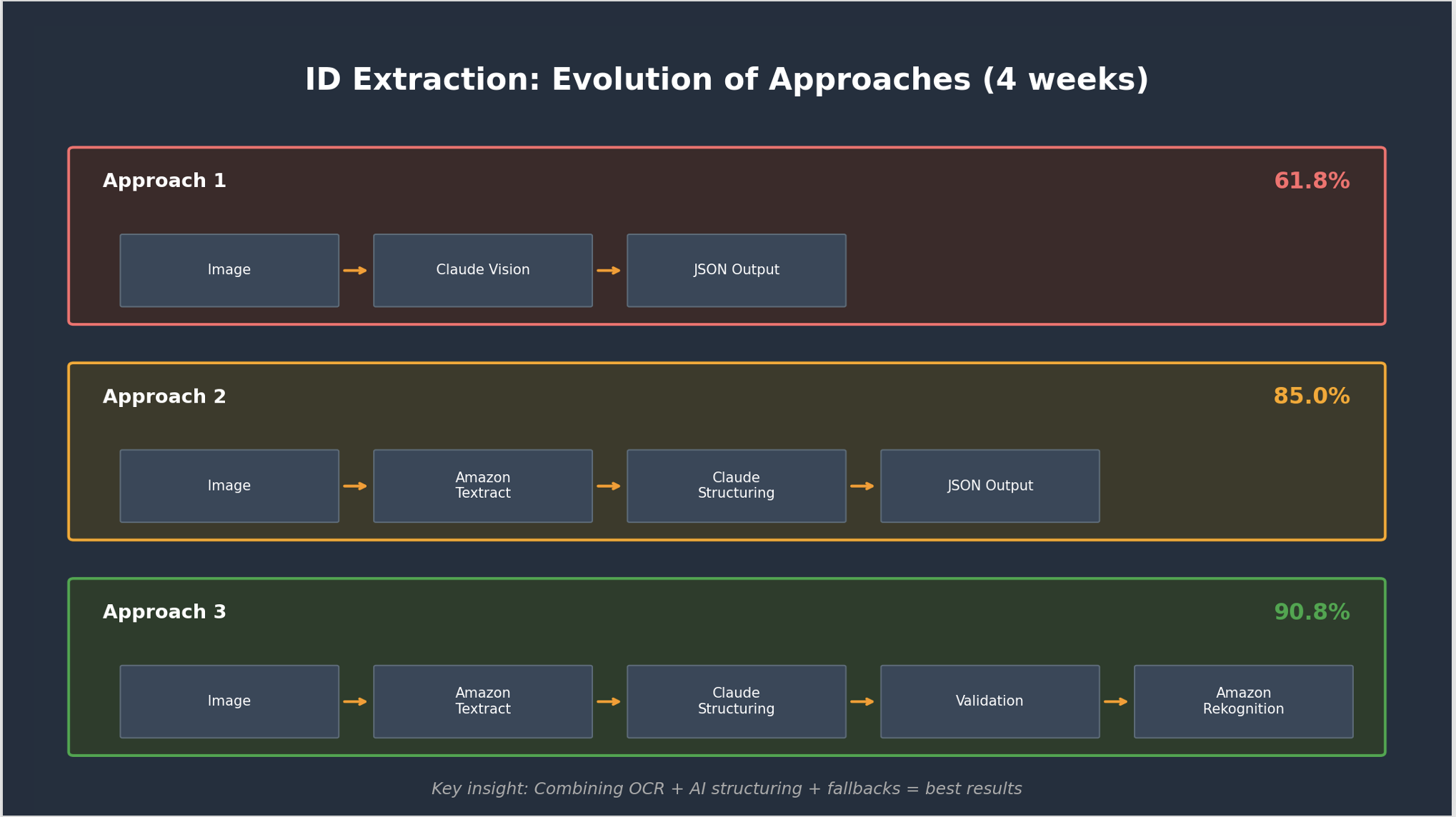
ID extraction: evolution of approaches displaying three iterations from 61.8% to 90.8% accuracy
Strategy 1: Claude Sonnet 4 alone (61.8% accuracy). The crew’s first try despatched ID photos on to Anthropic’s Claude Sonnet 4 through Amazon Bedrock and requested it to extract fields as JSON. The outcomes have been disappointing: 61.8% general accuracy, with ID quantity extraction at solely 43%. The core subject was the mannequin’s built-in security protocols for dealing with personally identifiable data (PII). Claude is skilled to restrict processing of delicate PII discovered on identification paperwork like driver’s licenses, passports, and nationwide IDs. When introduced with actual ID photos, the mannequin triggered these privateness safeguards and refused to extract data from some information, which instantly impacted efficiency. Moreover, even when extraction succeeded, sure fields (like ID numbers) confirmed poor accuracy as a result of the mannequin prioritized security over exact character recognition on delicate paperwork.
The takeaway: whereas Claude excels at common doc evaluation and OCR duties, its built-in privateness protections make it unsuitable for direct extraction from identification paperwork containing PII.
Strategy 2: Amazon Textract + Claude structuring (85% accuracy). The breakthrough got here when the crew separated OCR from structuring. Amazon Textract dealt with uncooked textual content extraction from ID photos. Claude Sonnet 4 then structured the output into 7 standardized fields: doc kind, date of start, title, surname, center title, ID quantity, and expiry date. This single change produced an 11.6% accuracy bounce.
This strategy labored as a result of Amazon Textract, as a specialised OCR service, doesn’t have the identical PII refusal mechanisms as Claude, so it reliably extracted textual content from each ID picture with out triggering security protocols. As soon as the textual content was extracted, Claude might give attention to what it does greatest: clever structuring. Claude excelled at dealing with native language textual content with diacritical marks, inferring lacking data from context, and making use of document-specific extraction guidelines. These are duties that conventional OCR alone couldn’t deal with. By working with already-extracted textual content moderately than uncooked ID photos, Claude averted its security constraints.
The takeaway: separating considerations allowed every device to function inside its design parameters: Amazon Textract for dependable OCR and Claude for clever structuring.
Strategy 3: Multi-tier OCR + validation (90.8% accuracy). The ultimate iteration added Amazon Rekognition as a fallback for photos the place Amazon Textract struggled (sometimes low-quality scans, uncommon doc angles, or broken IDs) plus validation guidelines for ID quantity formatting, date standardization, and doc kind normalization.
The multi-tier structure works as follows. Amazon Textract handles main OCR. Amazon Rekognition gives backup extraction when Amazon Textract confidence is low. Claude constructions the mixed output, and validation guidelines catch formatting errors that slip by means of. ID numbers get padded to the proper size based mostly on doc kind, and dates are standardized to YYYY-MM-DD format. These validation guidelines proved crucial. They caught edge circumstances the place OCR extracted right characters however in inconsistent codecs.
The next chart exhibits the weekly accuracy development throughout 585 take a look at photos. The crew didn’t beat the baseline till Week 4, after they added Amazon Textract. Every iteration revealed new failure modes that knowledgeable the following architectural enchancment.
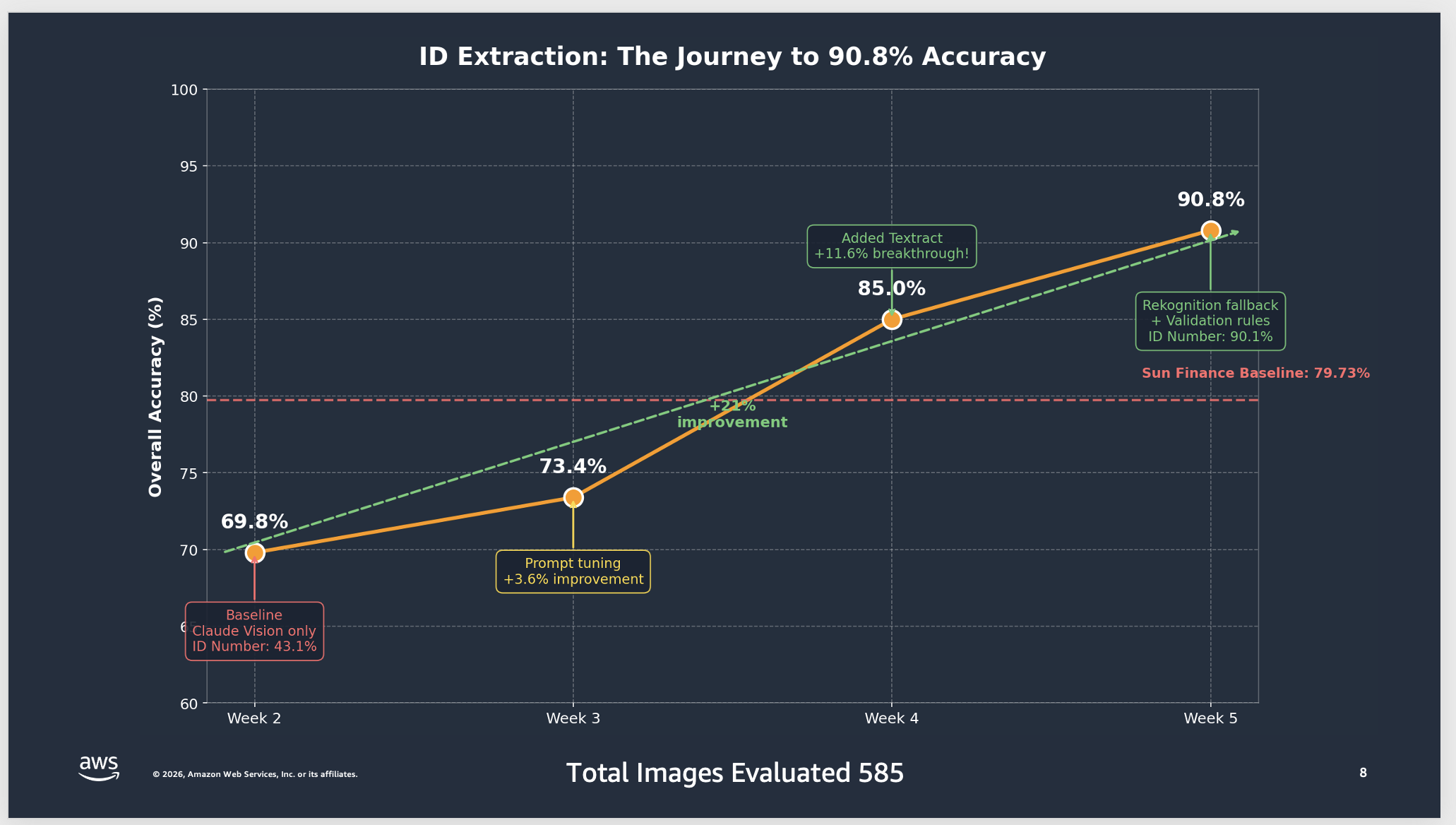
ID extraction: the journey to 90.8% accuracy displaying weekly progress
The takeaway: combining specialised OCR instruments (Amazon Textract + Amazon Rekognition) with LLM structuring (Claude) and validation guidelines beats utilizing a single device alone for doc extraction.
Fraud detection pipeline
The fraud detection system makes use of AWS Step Features to run two detection strategies in parallel, then combines their scores right into a remaining threat evaluation.
Visible sample detection. Claude Sonnet 4 through Amazon Bedrock analyzes submitted selfie photos for indicators of fraud: display screen pictures (seen bezels, scan traces, moiré patterns), display screen glare and reflections, and digital manipulation artifacts. Photographs scoring 85% confidence or greater are flagged. The system ignores regular traits like blur, compression artifacts, and commonplace cropping to cut back false positives. Display picture detection works effectively, with 95%+ confidence on identified patterns.
Background similarity evaluation. This part catches fraud rings, that are teams of fraudsters submitting selfies from the identical location. The pipeline works in three steps. First, Amazon Rekognition masks faces to give attention to the background. Then, Amazon Titan Multimodal Embeddings generates a 1024-dimensional vector of the background. Lastly, Amazon S3 Vectors searches for matches towards identified fraud patterns.
The crew examined each text-based and visible embeddings for similarity search. Textual content embeddings (having Claude describe the background, then evaluating descriptions) achieved 91% accuracy however solely 27.8% precision and 21.7% recall. Visible embeddings carried out much better: 96% accuracy, 80% precision, and 52% recall.
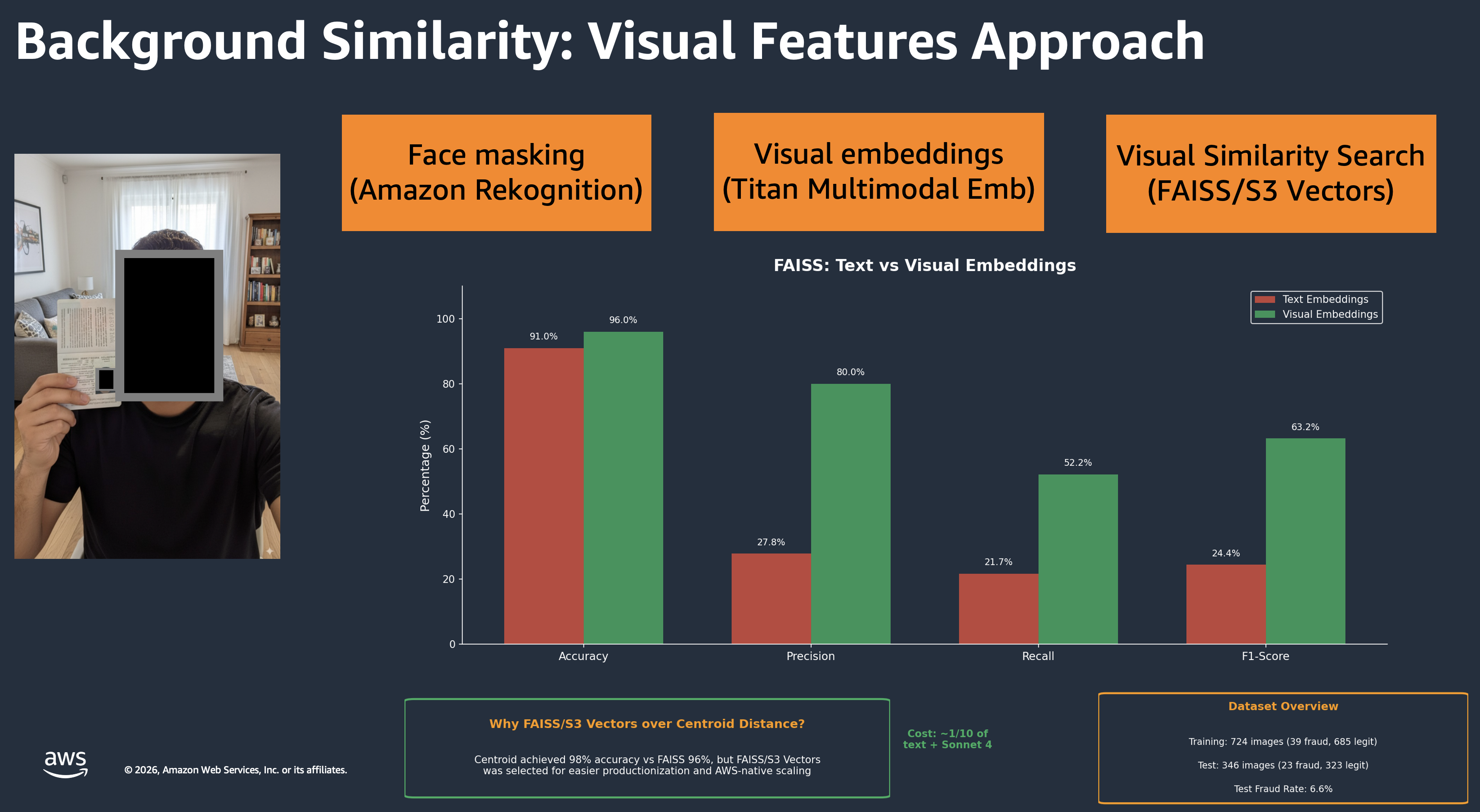
Background similarity: visible options strategy displaying the pipeline and textual content vs visible embedding comparability
Danger evaluation. The scoring algorithm weighs visible sample detection (50%) and background similarity (50%) equally. Scores of 75+ point out high-confidence fraud, 38–74 point out medium confidence, and beneath 38 is assessed as respectable. The parallel execution structure processes photos in 3–5 seconds, down from 6–8 seconds when run sequentially.
Serverless structure
The whole answer runs on AWS Lambda, AWS Step Features, and Amazon API Gateway. This design lets the crew modify particular person Lambda features, take a look at modifications instantly, and deploy updates with out downtime. This was crucial throughout a 6-week engagement the place the strategy modified weekly.
Authentication makes use of Amazon Cognito with AWS SigV4 request signing. AWS WAF protects towards widespread net safety points. Knowledge is encrypted at relaxation with AWS Key Administration Service (AWS KMS) and in transit through TLS 1.2+. The infrastructure is outlined in Terraform and handed safety audits with 25 findings analyzed: 14 false positives, 9 justified exceptions, and a couple of deferred for manufacturing.
Outcomes
The proof-of-concept delivered measurable enhancements throughout accuracy, pace, fraud detection, and price.
ID extraction efficiency
The system was evaluated towards 585 ID photos:
| Metric | Baseline | New answer | Enchancment |
| Identify | 84.93% | 87.72% | +2.79% |
| Date of start | 81.25% | 90.80% | +9.55% |
| Doc kind | 78.43% | 96.40% | +17.97% |
| ID quantity | 74.32% | 89.40% | +15.08% |
| Total accuracy | 79.73% | 90.80% | +11.07% |
ID quantity extraction, beforehand the weakest area at 74.32%, improved by over 15 proportion factors. Doc kind classification reached 96.4%. Common processing time: 4.42 seconds per doc.
Fraud detection efficiency
The mixed end-to-end fraud detection pipeline (visible sample detection plus background similarity) achieved 81% accuracy with 59% recall and 83% specificity.

Fraud detection outcomes: 81% accuracy, 59% recall, 83% specificity
The 59% recall means the system catches about 6 in 10 fraud circumstances. The conservative thresholds replicate a enterprise actuality: false positives create buyer friction, whereas missed fraud could be caught by means of different controls. Because the fraud sample database grows with confirmed circumstances, recall improves.
Value and pace
The brand new answer diminished prices and processing time throughout each pipelines.
| Element | Value discount |
| ID extraction (Amazon Textract + Amazon Rekognition + Claude) | 91% discount vs. earlier answer |
| Fraud detection (Claude Sonnet 4 + Amazon Titan Embeddings + Amazon S3 Vectors) | 3–5 seconds per picture |
The ID extraction price represents a 91% discount from the earlier answer. This makes it economically viable to serve industries with lower-value microloans. The fraud detection pipeline completes in 3–5 seconds per picture.
Operational influence
Past accuracy and price, the answer modified how Solar Finance operates day-to-day:
- Guide intervention projected to drop from 60% to 30% of functions, chopping the assessment workload in half.
- Staffing projected to lower from roughly 3 FTEs to roughly 1 FTE for this {industry}.
- Area enlargement now economically viable for low-value mortgage economies.
- Adaptability—including a brand new doc kind or language requires immediate engineering and validation, not retraining specialised fashions.
Scalability and enlargement
The answer’s structure was designed for speedy enlargement. Solar Finance operates throughout 9 nations, and the serverless design allows industry-specific deployments with out infrastructure duplication. Including a brand new financial system requires configuration updates and redeployment. The crew updates Claude Sonnet 4 prompts through Amazon Bedrock and defines document-specific validation guidelines, then assessments towards a validation dataset. These configuration modifications require redeploying the Lambda features by means of the continual integration and steady supply (CI/CD) pipeline utilizing Terraform. The fraud detection system makes use of two complementary strategies. Visible sample detection through Claude Sonnet 4 identifies display screen pictures and digital manipulation. These methods are largely common throughout industries. Background similarity evaluation utilizing Amazon S3 Vectors catches fraud rings by evaluating backgrounds towards identified patterns, with confirmed fraud circumstances added to enhance detection over time.
The modular structure allows steady enhancement. The AWS Step Features orchestration permits including new fraud detection strategies as parallel Lambda features with out disrupting current checks. These could possibly be capabilities like EXIF metadata evaluation, gadget fingerprinting, and geolocation validation. Every would combine as further parallel checks with out requiring architectural modifications.
Classes realized
5 sensible takeaways from the engagement:
OCR + LLM beats LLM alone. Claude Sonnet 4 through Amazon Bedrock by itself achieved 61.8% accuracy for ID extraction, which was beneath the present baseline. Including Amazon Textract for uncooked textual content extraction and utilizing Claude just for structuring jumped accuracy to 85%. The LLM is sweet at understanding context and normalizing messy knowledge. It’s not as dependable at exact character-by-character recognition from photos.
Multi-tier OCR delivers resilience. The cascading strategy makes use of Amazon Textract as main and Amazon Rekognition as a fallback. No single OCR service dealt with each edge case, however the mixture added minimal price whereas serving to keep away from full failures on difficult photos.
Fraud detection wants a number of strategies. Visible sample detection catches display screen pictures at 95%+ confidence. Background similarity catches fraud rings by means of location patterns. However background similarity solely achieves 55% recall on seen patterns and drops to 16.7% on novel patterns. Neither methodology alone is ample, and the system improves as extra confirmed fraud circumstances are added to the database.
Begin easy, add complexity when metrics demand it. The crew achieved a 91% price discount through the use of Amazon Textract as main OCR as an alternative of Claude for every part. They referred to as AnalyzeID solely when particular fields have been lacking and cached embeddings for fraud detection. Reserve costly fashions for duties the place they’re truly wanted.
Serverless allows speedy iteration. The parallel execution in AWS Step Features reduce fraud detection latency by 40% with minimal code modifications. The flexibility to switch and deploy particular person Lambda features with out downtime was crucial throughout a 6-week engagement the place the strategy advanced weekly.
Subsequent steps
Solar Finance plans to construct on the proof-of-concept in a number of instructions.
- Develop visible detection. The present system solely checks for display screen pictures. It misses cartoons, illustrations, and AI-generated photos. Increasing the detection immediate is the lowest-effort, highest-impact enchancment.
- Extra coaching knowledge. Steady assortment of confirmed fraud circumstances and various background patterns will instantly enhance background similarity recall past the present 55% on seen patterns.
- Further fraud indicators. Integrating EXIF metadata evaluation, gadget fingerprinting, and geolocation validation would add detection paths that don’t depend upon visible evaluation. That is notably helpful for novel fraud patterns.
- Multi-language enlargement. Increasing to Solar Finance’s different economies in nations throughout Southeast Asia, Africa, Latin America, and Europe requires language-specific immediate engineering and validation guidelines. Claude’s multilingual capabilities present a place to begin, and the crew is constructing a configuration framework to allow enlargement with out code modifications.
Clear up
When you implement an identical proof-of-concept, delete the next assets once you’re executed to keep away from ongoing costs:
- AWS Lambda features created for the ID extraction and fraud detection pipelines.
- AWS Step Features state machines.
- Amazon S3 buckets and Amazon S3 Vectors vector indexes used for fraud sample storage.
- Amazon API Gateway REST APIs.
- Amazon Cognito consumer swimming pools.
- AWS WAF net entry management lists (ACLs).
- Any Amazon Bedrock provisioned throughput (if configured).
You may delete these assets by means of the AWS Administration Console or by operating `terraform destroy` should you deployed the infrastructure utilizing Terraform.
Conclusion
On this publish, we confirmed how Solar Finance mixed Amazon Textract, Amazon Rekognition, and Amazon Bedrock to construct an AI-powered identification verification pipeline. The answer improved extraction accuracy from 79.7% to 90.8%, reduce per-document prices by 91%, and diminished processing time from as much as 20 hours to underneath 5 seconds. The core architectural sample, utilizing specialised OCR for textual content extraction and an LLM for clever structuring, applies to doc processing workflows the place conventional OCR falls brief. The serverless fraud detection system demonstrates how one can mix visible evaluation with vector similarity search to catch fraud patterns at scale.
For purchasers making use of for a microloan, that’s the distinction between ready a day and getting a solution whereas they’re nonetheless on their cellphone.
“Thanks to the AWS Generative AI Innovation Middle crew for an impressive partnership and really distinctive outcomes. What initially felt like an bold — virtually unrealistic — goal has been remodeled right into a safe, production-ready answer delivering measurable beneficial properties in accuracy, pace, and price effectivity. Particularly, the AI-powered fraud detection functionality — combining visible sample recognition and background similarity evaluation — represents a serious step ahead in defending our portfolio whereas sustaining a seamless buyer expertise. The influence on our operations and threat administration framework is instant and vital, and we deeply recognize the experience, dedication, and execution excellence that made this potential.”
— Agris Vaselāns, Group CRO, Solar Finance
To find out how generative AI can enhance your doc processing and fraud detection workflows, go to the Amazon Bedrock product web page or join with the AWS Generative AI Innovation Middle. For extra on OCR and doc processing, check with the Amazon Textract Developer Information.
We’d love to listen to about your expertise with doc processing and fraud detection. Share your ideas within the feedback part.
In regards to the authors



{kind=link}