Authors: Ahsaas Bajaj and Benjamin S Knight
? We ran 134,400 simulations grounded in actual manufacturing ML fashions to search out out. The reply relies on what you’re optimizing for, and on a single diagnostic you possibly can compute earlier than becoming a mannequin.
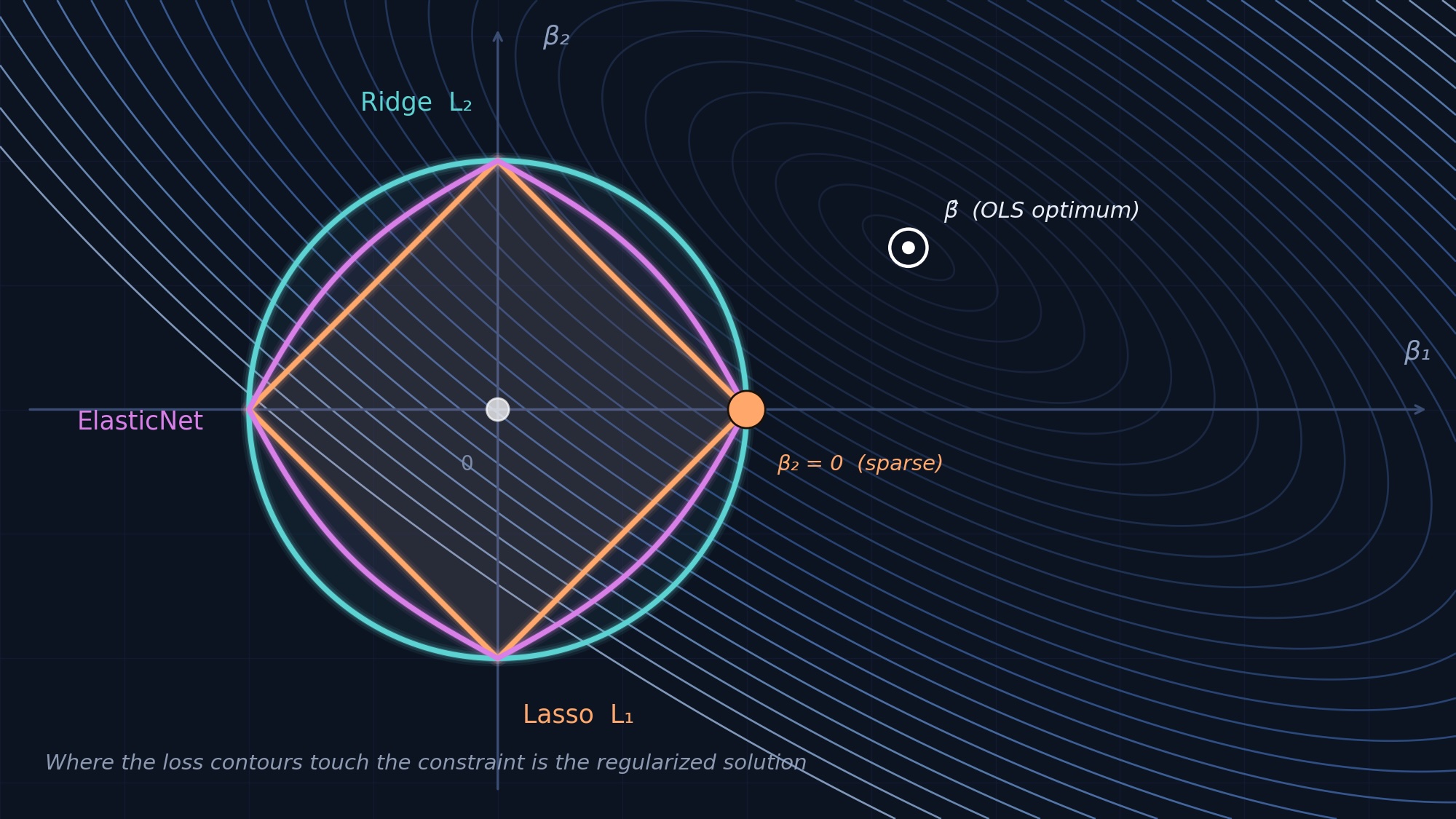
If you happen to’ve ever skilled a linear mannequin in scikit-learn, you’ve confronted this query: RidgeCV, LassoCV, or ElasticNetCV? Perhaps you defaulted to no matter a tutorial really useful. Perhaps a colleague had a robust opinion. Perhaps you tried all three and picked whichever gave the very best cross-validation rating.
We needed to interchange instinct with empirical decision-making.
We ran 134,400 simulations throughout 960 configurations of a 7-dimensional parameter area, various pattern measurement, options, multicollinearity, signal-to-noise ratio, coefficient sparsity, and two extra parameters. We benchmarked 4 regularization frameworks (Ridge, Lasso, ElasticNet, and Submit-Lasso OLS) throughout the three targets:
- Predictive accuracy (take a look at RMSE)
- Variable choice (F1 rating for recovering the true function set)
- Coefficient estimation (L2 error vs. true coefficients)
Our simulation ranges aren’t arbitrary. They’re grounded in eight real-world manufacturing ML fashions from Instacart, spanning demand forecasting, conversion prediction, and stock intelligence. The regimes we examined replicate situations that MLEs really encounter in follow.
This submit distills the sensible steerage from our research into a choice framework you should use in your subsequent challenge. If you happen to’re a Knowledge Scientist or MLE selecting a regularizer, that is for you.
The Headlines
Earlier than we get into the main points:
- For prediction, it barely issues. Ridge, Lasso, and ElasticNet differ by at most 0.3% in median RMSE. No hyperparameter achieves even a small impact measurement for RMSE variations amongst them. This solely holds with sufficient coaching knowledge (> 78 observations per function).
- For variable choice, it issues enormously, particularly below multicollinearity. Lasso’s recall collapses to 0.18 below excessive situation numbers with low sign, whereas ElasticNet maintains 0.93.
- At giant sample-to-feature ratios (n/p ≥ 78), the strategies grow to be interchangeable. Use Ridge; it’s the quickest.
- Submit-Lasso OLS ought to be prevented when optimizing for RMSE. It’s the one technique that persistently underperforms, and it does so on each goal we measured.
What We Examined and Why
Our simulation framework varies seven hyper-parameters concurrently:

We ran every of the 4 regularization frameworks towards 960 hyper-parameter configurations, every utilizing 35 random seeds for a complete of 134,400 simulations. For each simulation we logged the take a look at RMSE, F1 rating (precision and recall for recovering the true assist of β), and coefficient L2 error.
To measure what drives the variations between strategies, we used omega-squared (ω²) from one-way ANOVA, an impact measurement that tells us what quantity of variance in efficiency gaps is defined by every parameter. This goes past asking “which technique wins” to understanding why it wins, and below what situations.
Right here’s what this implies in follow: many of the parameters that drive technique variations are issues you possibly can observe earlier than becoming a mannequin. You realize n and p. You’ll be able to compute the situation quantity κ with numpy.linalg.cond(X). And the one essential latent parameter, SNR, has a free diagnostic proxy: the regularization energy α that LassoCV selects. Excessive α alerts low sign; low α alerts sturdy sign. We’ll come again to this.
Discovering 1: For Prediction, Simply Use Ridge
That is an important discovering for the most important variety of practitioners.
Ridge, Lasso, and ElasticNet are almost interchangeable for prediction. Throughout all 33,600 simulations per technique, the median take a look at RMSE differs by at most 0.3%. Our omega-squared evaluation confirms this: no single hyperparameter achieves even a small impact measurement (ω² ≥ 0.01) for RMSE variations amongst these three strategies. Each pairwise comparability is negligible (all < 0.02).
For practitioners who solely care about accuracy, the near-equivalence is itself the discovering. Regularizer alternative issues far lower than pattern measurement.

So why Ridge? Computational effectivity. Ridge has a closed-form resolution for every candidate α, making it dramatically quicker than the alternate options (examine Ridge’s median run time of 6 seconds to Lasso’s median runtime of 9 seconds and ElasticNet’s median runtime of 48 seconds).

ElasticNet’s overhead stems from its joint grid search over α and the L1 ratio ρ. The 167–219× imply overhead we measured is particular to our 8-value L1 ratio grid. A coarser 3-value grid would cut back this proportionally. Even worse, when the coefficient distribution is roughly uniform, Lasso can take over an hour to converge (see the right-side of the bimodal distribution). This overhead buys you a median RMSE enchancment of simply 0.04% over Ridge, a margin that’s negligible in follow.
Caveats
On the smallest pattern measurement we examined (n = 100), ElasticNet can beat Ridge by 5–15% in very particular situations: when SNR is excessive (~1.0). At low SNR, Ridge is definitely marginally higher. These are localized observations on the excessive of our simulation grid, not systematic traits.
Another word: LassoLars wasn’t a part of our analysis design, however the LARS algorithm computes the complete Lasso regularization path analytically in a single cross (O(np²)), doubtlessly matching Ridge’s closed-form velocity benefit. Nonetheless, LARS is understood to be numerically unstable below high-collinearity situations (κ > 10⁴) that characterize most manufacturing ML function units. That is exactly the regime the place our strongest findings apply.
Backside line for prediction: Default to RidgeCV. Pattern measurement issues excess of regularizer alternative. However prediction isn’t the one goal value optimizing. When variable choice or coefficient accuracy issues, particularly below multicollinearity, the story adjustments dramatically.
Discovering 2: For Variable Choice, ElasticNet Is the Protected Default
Right here technique alternative really issues. Variable choice, the duty of figuring out which options actually contribute to the result, is the target most delicate to the regularizer, and the place getting it fallacious carries the steepest value.
What Drives the Variations
From our ANOVA decomposition of pairwise F1 variations:

Pattern measurement dominates overwhelmingly. However when you’re within the small-n regime (n/p < 78), the situation quantity and SNR grow to be the first differentiators.
Excessive Multicollinearity (κ > ~10⁴): Do Not Use Lasso
This is likely one of the most strong findings in the complete research, and it’s straight related to manufacturing ML. Seven of eight fashions we surveyed function within the high-κ regime. In case your options are even reasonably correlated (which they nearly actually are in any engineered function set), this discovering applies to you.
At excessive κ with low SNR:
- Lasso recall: 0.18 (it misses 82% of true options)
- ElasticNet recall: 0.93 (it catches 93% of true options)
That’s a 5× recall benefit for ElasticNet. The mechanism is well-known. When options are extremely correlated, Lasso arbitrarily picks one from every correlated group and zeros the remainder. ElasticNet’s L2 penalty element, the “grouping impact” described by Zou and Hastie (2005), retains correlated options collectively.
Our simulations present this isn’t a nook case. The strongest F1 variations (ΔF1 of 0.50–0.75) focus squarely within the high-κ columns at n = 100 and n = 1,000. That is the widespread case in manufacturing.
Low Multicollinearity (κ < ~10²): Nonetheless Default to ElasticNet
You would possibly count on Lasso to lastly shine at low κ. It doesn’t, not less than not universally. Even at low κ, Lasso’s recall is extremely delicate to the signal-to-noise ratio (see beneath).

ElasticNet maintains recall ≥ 0.91 no matter SNR, even at low κ. Lasso is just aggressive when each SNR is excessive and the true mannequin is genuinely sparse. Because you usually don’t know SNR upfront, ElasticNet is the safer guess.
The Ridge Shock
We didn’t count on this: Ridge often achieves the highest F1 scores at small n, regardless of by no means performing specific variable choice. How? Ridge’s recall is all the time 1.0, as a result of it retains each function, and that good recall overwhelms the precision benefit of sparse strategies when these strategies’ recall collapses below low SNR.
However this isn’t real variable choice. Ridge offers you a nonzero coefficient for each function. If you happen to want an explicitly sparse mannequin, Ridge doesn’t assist. Combining Ridge with post-hoc permutation significance is a pure extension, however we didn’t consider it right here.
Variable Choice: Abstract

Backside line for variable choice: ElasticNetCV is the protected default. Lasso solely earns its place when κ is low, SNR is excessive, and you’ve got area cause to consider the true mannequin is sparse.
Discovering 3: For Coefficient Estimation, Department on κ
When the aim is recovering correct coefficient values, for interpretability or causal inference, the situation quantity κ turns into the important thing branching variable. Ideally we’d department on the distribution of the true 𝛽 coefficients, however we don’t get to watch it. In distinction, κ will be measured straight. At excessive κ ElasticNet dominates no matter sparsity. At low κ, the optimum technique relies on whether or not the true mannequin is sparse or dense. Pattern measurement adjustments the magnitude of variations however not their path.
Excessive κ (> ~10⁴): Use ElasticNet. It achieves 20–40% decrease L2 coefficient error than Lasso, and holds a constant edge over Ridge no matter sparsity degree.
Low κ (< ~10²): Department in your area data about sparsity.
- Sparse area (genomics, textual content classification, sensor arrays): Lasso or ElasticNet
- Dense area (engineered function units, demand forecasting, conversion fashions): Ridge

All regimes: Keep away from Submit-Lasso OLS. It exhibits increased coefficient L2 error than normal Lasso throughout the complete simulation grid. The unpenalized OLS refit amplifies first-stage choice errors. That is the situation the place you’d hope the two-stage process helps, and it doesn’t.

Backside line for coefficient estimation: ElasticNet at excessive κ, domain-dependent at low κ, by no means Submit-Lasso OLS.
A Practitioner’s Resolution Information
All the findings above distill into a choice framework that branches completely on portions you possibly can compute earlier than becoming a single mannequin: the sample-to-feature ratio n/p, the situation quantity κ (through numpy.linalg.cond(X)), and when finer discrimination is required, the regularization energy α elected by a fast LassoCV run as a proxy for the latent SNR.
The total flowchart is on the market in our paper (Determine 7). Right here, we stroll by the logic as a choice tree.
The under-determined regime
In case your function depend exceeds your pattern measurement, you’re within the under-determined regime. Lasso’s α often saturates on the higher boundary of the search grid right here, and its recall collapses. Default to Ridge or ElasticNet for all targets, and proceed with warning.
The big-sample regime
If n/p ≥ 78, you’re within the large-sample regime the place all strategies converge. Efficiency gaps vanish throughout prediction, variable choice, and coefficient estimation concurrently.
Use RidgeCV. It’s the quickest technique by a large margin, and there’s no accuracy penalty. If you happen to particularly want a sparse mannequin for interpretability, ElasticNetCV or LassoCV are completely wonderful at this ratio. The selection amongst them is immaterial.
The regime the place alternative issues
Beneath n/p = 78 is the place technique alternative issues most. The proper regularizer relies on what you’re optimizing for.
If prediction is your precedence: Use RidgeCV. The RMSE variations among the many core three strategies are too small to justify extra complexity or compute. One slim exception: at n ≈ 100 with excessive SNR (~1.0), ElasticNet presents a detectable 5–15% edge no matter κ; at n ≈ 100 with very low SNR, Ridge is marginally most popular. In both case, the margin is modest relative to the advance accessible from rising pattern measurement.
If variable choice is your precedence: Department on the situation quantity.
- κ > ~10⁴ (excessive multicollinearity): Use ElasticNetCV. That is among the many strongest suggestions within the research. One nuance: at moderate-to-high SNR (or n ≥ 1,000), ElasticNet is clearly most popular, with F1 benefits over Lasso reaching ΔF1 of +0.75. At very low SNR with n ≈ 100 (recognized by a saturated CV-elected α), Ridge achieves the very best F1, however solely by good recall (retaining all options), not real variable choice. If you happen to want an explicitly sparse mannequin even on this nook, ElasticNet stays the least-bad possibility and nonetheless vastly outperforms Lasso.
- κ < ~10² (well-conditioned): An essential warning first: don’t default to Lasso even at low κ. Lasso’s recall drops sharply at decrease SNR ranges no matter multicollinearity, whereas ElasticNet maintains recall ≥ 0.91 throughout all SNR ranges. ElasticNet is the protected default right here. To refine additional, run a fast LassoCV and examine the elected α. If α is excessive or saturated on the boundary, you’re in a low-SNR regime. Ridge supplies the very best F1 (although not by real sparsification). If α is reasonable, keep on with ElasticNet. If α is low and area experience suggests sparsity, Lasso turns into viable.
If coefficient estimation is your precedence: Department on the situation quantity.
- κ > ~10⁴: ElasticNetCV dominates no matter sparsity.
- κ < ~10²: Use area data. Sparse mannequin → Lasso. Dense mannequin → Ridge.
The α Diagnostic: A Free SNR Proxy
The one latent parameter that issues for fine-grained selections, signal-to-noise ratio, will be approximated at zero extra value. When scikit-learn’s LassoCV matches your knowledge, it studies the elected α. This worth is inversely associated to the underlying SNR: excessive α alerts weak sign, low α alerts sturdy sign.
Our simulations present direct empirical affirmation: the very best elected α values (approaching 10⁴–10⁵) focus completely in small-n, low-SNR configurations.

These thresholds are approximate heuristics derived from our simulation grid, they’ll differ with function scaling and dataset traits. Deal with them as pointers, not sharp cutoffs.
In All Unsure Circumstances
Whenever you’re uncertain about SNR, uncertain about sparsity, or working within the intermediate-κ vary we didn’t straight take a look at: ElasticNet is the default that gained’t burn you, and Submit-Lasso OLS ought to be prevented.
The Meta-Discovering: Pattern Dimension Trumps All the pieces
One takeaway issues greater than any method-level steerage: rising your sample-to-feature ratio does extra for each goal than any regularizer alternative.
Pattern measurement is the dominant driver of efficiency variations throughout all three metrics (ω² = 0.308 for F1, a giant impact). The n × SNR interplay is the strongest two-way interplay throughout all comparisons (F = 569, p < 0.001). Sign-to-noise issues most exactly when samples are scarce. And at n/p ≥ 78, technique alternative turns into irrelevant fully.
If you happen to’re spending days tuning your regularizer when you might be rising your coaching set, you’re optimizing the fallacious factor.
Fast Reference

Placing It Into Follow
The simulation framework is a reusable harness. We capped pattern sizes at 100k observations for compute causes, however the grid nonetheless spans the n/p inflection level the place regularizer efficiency shifts. We’re extending it now to newer regularizers (Adaptive Lasso, SCAD, MCP) and intermediate κ ranges.
To use this framework to your subsequent challenge, compute three portions earlier than you match something: the sample-to-feature ratio (n/p), the situation quantity (κ), and in case you’re within the small-n regime, a fast LassoCV α as your SNR proxy. Route by the choice information above based mostly in your main goal.
If n/p ≥ 78, use Ridge and spend your tuning price range elsewhere. If n/p < 78 and κ is excessive, use ElasticNet and don’t second-guess it. The one situation the place the selection requires actual thought is low κ with small n, and even there, ElasticNet is rarely a foul reply.
The total paper, together with all appendix figures, ANOVA tables, and the consolidated choice flowchart, is on the market on ArXiv.
Ahsaas Bajaj is a Machine Studying Tech Lead at Instacart. Benjamin S Knight is a Employees Knowledge Scientist at Instacart.
All pictures had been created by the authors.



{kind=link}