us three weeks to ship a single information pipeline. In the present day, an analyst with zero Python expertise does it in a day. Right here’s how we acquired there.
I’m Kiril Kazlou, a knowledge engineer at Mindbox. Our crew frequently recalculates enterprise metrics for shoppers — which implies we’re always constructing information marts for billing and analytics, pulling from dozens of various sources.
For a very long time, we relied on PySpark for all our information processing. The issue? You possibly can’t actually work with PySpark with out Python expertise. Each new pipeline required a developer. And that meant ready — typically for weeks.
On this publish, I’ll stroll you thru how we constructed an inside information platform the place an analyst or product supervisor can spin up a frequently up to date pipeline by writing simply 4 YAML information.
Why PySpark Was Slowing Us Down
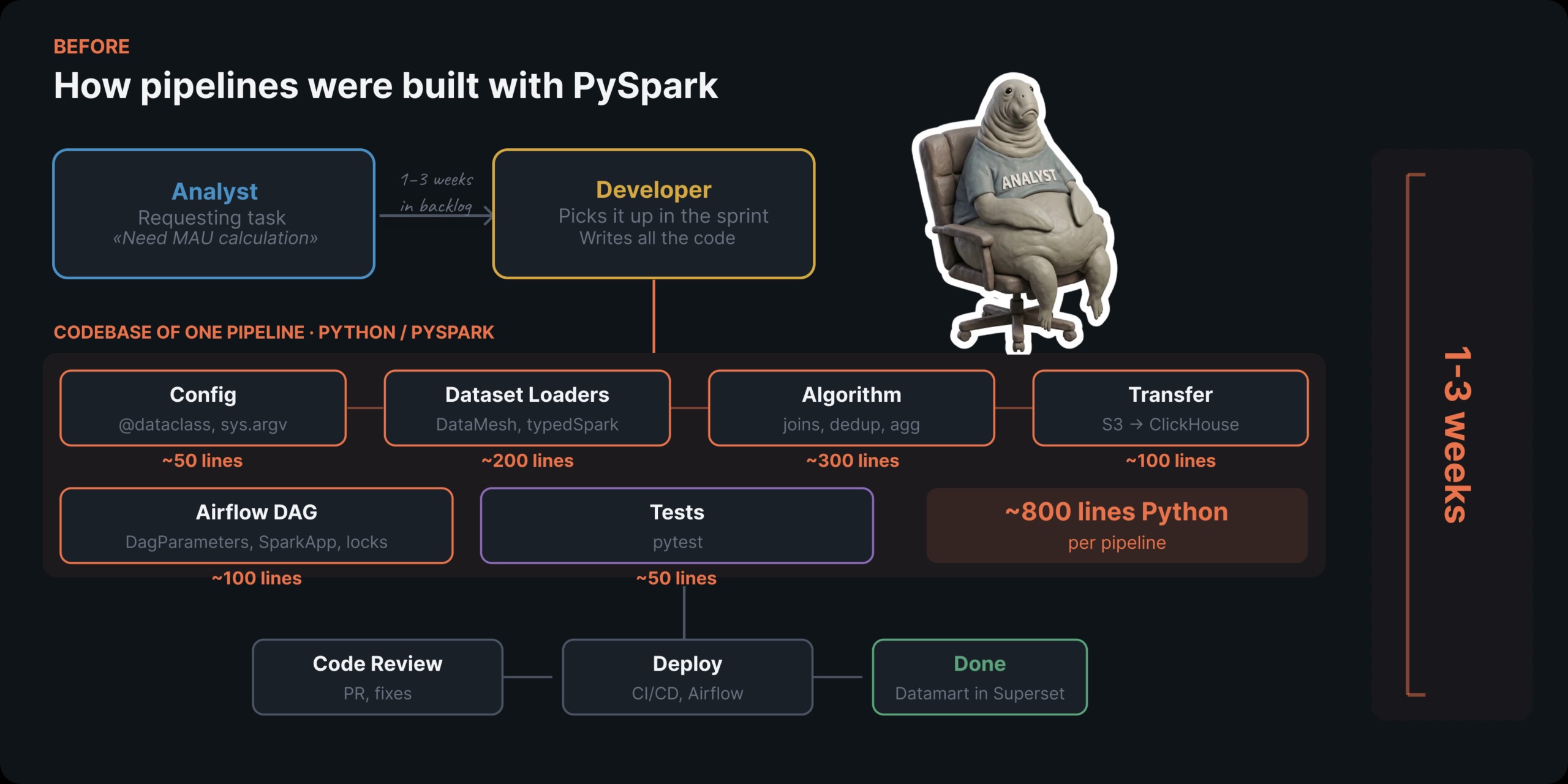
Let me illustrate the ache with a textbook instance — calculating MAU (Month-to-month Energetic Customers).
On the floor, this seems like a easy SQL job: COUNT(DISTINCT customerId) throughout a couple of tables over a time window. However due to all of the infrastructure overhead — PySpark, Airflow DAG setup, Spark useful resource allocation, testing — we needed to hand it off to builders. The end result? A full week simply to ship a MAU counter.
Each new metric took one to 3 weeks to ship. And each single time, the method regarded the identical:
- An analyst outlined the enterprise necessities, discovered an accessible developer, and handed over the context.
- The developer clarified particulars, wrote PySpark code, went by means of code overview, configured the DAG, and deployed.
What we truly needed was for analysts and product managers — the individuals who perceive the enterprise logic greatest and are fluent in SQL and YAML — to deal with this themselves. No Python. No PySpark.

What We Changed PySpark With: YAML and SQL Are All You Want
To take a declarative method, we cut up our information layer into three components and picked the fitting software for every:
- dlt (information load software) — ingests information from exterior APIs and databases into object storage. Configured solely by means of a YAML file. No code required.
- dbt (information construct software) on Trino — transforms information utilizing pure SQL. It hyperlinks fashions by way of
ref(), mechanically builds a dependency graph, and handles incremental updates. - Airflow + Cosmos — orchestrates the pipelines. The Airflow DAG is auto-generated from
dag.yamland the dbt undertaking.
We have been already utilizing Trino as a question engine for ad-hoc queries and had it plugged into Superset for BI. It had already confirmed itself: for queries with customary logic, it processed huge datasets quicker and with fewer assets than Spark. On high of that, Trino natively helps federated entry to a number of information shops from a single SQL question. For 90% of our pipelines, Trino was an ideal match.

How We Load Information: dlt.yaml
The primary YAML file describes the place and load information for downstream processing. Right here’s a real-world instance — loading billing information from an inside API:
product: sg-team
function: billing
schema: billing_tarification
dag:
dag_id: dlt_billing_tarification
schedule: "0 4 * * *"
description: "Every day refresh of tarification information"
tags:
- billing
alerts:
enabled: true
severity: warning
supply:
sort: rest_api
shopper:
base_url: "https://internal-api.instance.com"
auth:
sort: bearer
token: dlt-billing.token
assets:
- identify: tarification_data
endpoint:
path: /tarificationData
methodology: POST
json:
firstPeriod: "{{ previous_month_date }}"
lastPeriod: "{{ previous_month_date }}"
pricingPlanLine: CurrentPlan
write_disposition: change
processing_steps:
- map: dlt_custom.billing_tarification_data.map
- identify: charges_raw
columns:
staffUserName:
data_type: textual content
nullable: true
endpoint:
path: /data-feed/fees
methodology: POST
json:
firstPeriod: "{{ previous_month_date }}"
lastPeriod: "{{ previous_month_date }}"
write_disposition: change
- identify: discounts_raw
endpoint:
path: /data-feed/reductions
methodology: POST
json:
firstPeriod: "{{ previous_month_date }}"
lastPeriod: "{{ previous_month_date }}"
write_disposition: changeThis config defines 4 assets from a single API. For each, we specify the endpoint, request parameters, and a write technique — in our case, change means “overwrite each time.” You too can add processing steps, outline column varieties, and configure alerts.
Your entire config is 40 strains of YAML. With out dlt, every connector could be a Python script dealing with requests, pagination, retries, serialization to Delta Desk format, and uploads to storage.
How We Remodel Information With SQL: dbt_project.yaml and sources.yaml
The following step is configuring the dbt mannequin. With Trino, meaning SQL queries.
Right here’s an instance of how we arrange the MAU calculation. That is what occasion preparation from a single supply appears to be like like:
-- int_mau_events_visits.sql (simplified)
{{ config(materialized='desk') }}
WITH interval AS (
-- Rolling window: final 5 months to present
SELECT
YEAR(CURRENT_DATE - INTERVAL '5' MONTH) AS start_year,
MONTH(CURRENT_DATE - INTERVAL '5' MONTH) AS start_month,
YEAR(CURRENT_DATE) AS end_year,
MONTH(CURRENT_DATE) AS end_month
),
occasions AS (
-- Pull go to occasions throughout the interval window
SELECT src._tenant, src.unmergedCustomerId,
'visits' AS src_type, src.endpoint
FROM {{ supply('closing', 'customerstracking_visits') }} src
CROSS JOIN interval p
WHERE src.unmergedCustomerId IS NOT NULL
AND /* ...timestamp filtering by yr/month bounds... */
),
events_with_customer AS (
-- Resolve merged buyer IDs
SELECT e._tenant,
COALESCE(mc.mergedCustomerId, e.unmergedCustomerId) AS customerId,
e.src_type, e.endpoint
FROM occasions e
LEFT JOIN {{ ref('int_merged_customers') }} mc
ON e._tenant = mc._tenant
AND e.unmergedCustomerId = mc.unmergedCustomerId
)
-- Preserve solely precise (non-deleted) clients
SELECT ewc._tenant, ewc.customerId, ewc.src_type, ewc.endpoint
FROM events_with_customer ewc
WHERE EXISTS (
SELECT 1 FROM {{ ref('int_actual_customers') }} ac
WHERE ewc._tenant = ac._tenant
AND ewc.customerId = ac.customerId
)All 10 occasion sources comply with the very same sample. The one variations are the supply desk and the filters. Then the fashions merge right into a single stream:
-- int_mau_events.sql (union of all sources)
SELECT * FROM {{ ref('int_mau_events_inapps_targetings') }}
UNION ALL
SELECT * FROM {{ ref('int_mau_events_inapps_clicks') }}
UNION ALL
SELECT * FROM {{ ref('int_mau_events_visits') }}
UNION ALL
SELECT * FROM {{ ref('int_mau_events_orders') }}
-- ...plus 6 extra sourcesAnd eventually, the info mart the place every part will get aggregated:
-- mau_period_datamart.sql
{{ config(
materialized='incremental',
incremental_strategy='merge',
unique_key=['_tenant', 'start_year', 'start_month', 'end_year', 'end_month']
) }}
int -%
WITH interval AS (
SELECT
YEAR(CURRENT_DATE - INTERVAL '{{ months_back }}' MONTH) AS start_year,
MONTH(CURRENT_DATE - INTERVAL '{{ months_back }}' MONTH) AS start_month,
YEAR(CURRENT_DATE) AS end_year,
MONTH(CURRENT_DATE) AS end_month
),
events_resolved AS (
SELECT * FROM {{ ref('int_mau_events') }}
),
metrics_by_tenant AS (
SELECT
er._tenant,
COUNT(DISTINCT CASE WHEN src_type = 'visits'
THEN customerId END) AS CustomersTracking_Visits,
COUNT(DISTINCT CASE WHEN src_type = 'orders'
THEN customerId END) AS ProcessingOrders_Orders,
COUNT(DISTINCT CASE WHEN src_type = 'mailings'
THEN customerId END) AS Mailings_MessageStatuses,
-- ...different metrics
COUNT(DISTINCT customerId) AS MAU
FROM events_resolved er
GROUP BY er._tenant
)
SELECT m.*, p.start_year, p.start_month, p.end_year, p.end_month
FROM metrics_by_tenant m
CROSS JOIN interval pFor the info mart configuration, we use incremental_strategy='merge'. dbt mechanically generates the merge question, substituting the unique_key for upsert. No must manually implement incremental loading.
To tie the fashions right into a single undertaking, we arrange dbt_project.yaml:
identify: mau_period
model: '1.0.0'
fashions:
mau_period:
+on_table_exists: change
+on_schema_change: append_new_columnsAnd sources.yaml, which describes the enter tables:
sources:
- identify: closing
database: data_platform
schema: closing
tables:
- identify: inapps_targetings_v2
- identify: inapps_clicks_v2
- identify: customerstracking_visits
- identify: processingorders_orders
- identify: cdp_mergedcustomers_v2
# ...The end result is similar enterprise logic we had in PySpark, however in pure SQL: sources.yaml replaces typedspark schemas, {{ ref() }} and {{ supply() }} change .get_table(), and computerized execution order by way of the dependency graph replaces guide Spark useful resource tuning.
How We Configure Airflow: dag.yaml
The fourth configuration file defines when and the way Airflow runs the pipeline:
product: sg-team
function: billing
schema: mau
schedule: "15 21 * * *" # every single day at 00:15 MSK
params:
- identify: start_date
description: "Begin date (YYYY-MM-DD). Go away empty for auto"
default: ""
- identify: end_date
description: "Finish date (YYYY-MM-DD). Go away empty for auto"
default: ""
- identify: months_back
description: "Months to look again (default: 5)"
default: 5
alerts:
enabled: true
severity: warningThen our Python script parses dag.yaml and dbt_project.yaml and makes use of the Cosmos library to generate a completely practical Airflow DAG. That is the solely piece of Python code in all the setup. It’s written as soon as and works for each dbt undertaking. Right here’s the important thing half:
def _build_dbt_project_dags(project_path: Path, environ: dict) -> record[DbtDag]:
config_dict = yaml.safe_load(dag_config_path.read_text())
config = DagConfig.model_validate(config_dict)
# YAML params → Airflow Params
params = {}
operator_vars = {}
for param in config.params:
params[param.name] = Param(
default=param.default if param.default just isn't None else "",
description=param.description,
)
operator_vars[param.name] = f"{{{{ params.{param.identify} }}}}"
# Cosmos creates the DAG from the dbt undertaking
with DbtDag(
dag_id=f"dbt_{project_path.identify}",
schedule=config.schedule,
params=params,
project_config=ProjectConfig(dbt_project_path=project_path),
profile_config=ProfileConfig(
profile_name="default",
target_name=project_name,
profile_mapping=TrinoLDAPProfileMapping(
conn_id="trino_default",
profile_args={
"database": profile_database,
"schema": profile_schema,
},
),
),
operator_args={"vars": operator_vars},
) as dag:
# Create schema earlier than operating fashions
create_schema = SQLExecuteQueryOperator(
task_id="create_schema",
conn_id="trino_default",
sql=f"CREATE SCHEMA IF NOT EXISTS {profile_database}.{profile_schema} ...",
)
# Connect to root duties
for unique_id, _ in dag.dbt_graph.filtered_nodes.gadgets():
job = dag.tasks_map[unique_id]
if not job.upstream_task_ids:
create_schema >> jobCosmos reads manifest.json from the dbt undertaking, parses the mannequin dependency graph, and creates a separate Airflow job for every mannequin. Job dependencies are constructed mechanically based mostly on ref() calls within the SQL.
How Analysts Construct Pipelines With out Builders
Now when an analyst wants a brand new recurring pipeline, they’ll put it collectively in a couple of steps:
Step 1. Create a folder within the repo: dbt-projects/my_new_pipeline/.
Step 2. If exterior information ingestion is required, write a YAML config for dlt.
Step 3. Write SQL fashions within the fashions/ folder and describe the sources in sources.yaml.
Step 4. Create dbt_project.yaml and dag.yaml.
Step 5. Push to Git, undergo overview, merge.
CI/CD builds the dbt undertaking and ships artifacts to S3. Airflow reads the DAG information from there, Cosmos parses the dbt undertaking and generates the duty graph. On schedule, dbt runs the fashions on Trino within the appropriate order. The top result’s an up to date information mart within the warehouse, accessible by means of Superset.
What Modified After the Migration

For analysts to construct pipelines on their very own, they should perceive ref() and supply() ideas, the distinction between desk and incremental materialization, and the fundamentals of Git. We ran a couple of inside workshops and put collectively step-by-step guides for every job sort.
Why the New Stack Doesn’t Absolutely Change PySpark
For about 10% of our pipelines, PySpark continues to be the one possibility — when a change merely doesn’t match into SQL. dbt helps Jinja macros, however that’s no substitute for full-blown Python. And it will be dishonest to skip over the constraints of the brand new instruments.
dlt + Delta: experimental upsert assist. We use the Delta format in our storage layer. dlt’s Delta connector is marked as experimental, so the merge technique didn’t work out of the field. We needed to discover workarounds — in some circumstances we used change as a substitute of merge (sacrificing incrementality), and in others we wrote customized processing_steps.
Trino’s restricted fault tolerance. Trino does have a fault tolerance mechanism, however it works by writing intermediate outcomes to S3. At our terabyte-scale information volumes, that is impractical — the sheer variety of S3 operations makes it prohibitively costly. With out fault tolerance enabled, if a Trino employee goes down, all the question fails. Spark, against this, restarts simply the failed job. We addressed this with DAG-level retries and by decomposing heavy fashions into chains of intermediate ones.
UDFs and customized logic. In Spark, you’ll be able to write customized logic in Python proper contained in the pipeline — tremendous handy. With the brand new structure, that is a lot more durable. dbt on high of Trino doesn’t assist: Jinja solely generates SQL, and dbt’s Python fashions solely work with Snowflake, Databricks, and BigQuery. You possibly can write UDFs in Trino, however solely in Java — with all of the overhead that entails: a separate repo, a construct pipeline, deploying JARs throughout all staff. So when a change doesn’t match into SQL, you both find yourself with an unmaintainable SQL monster or a standalone script that breaks the lineage.
What’s Subsequent: Assessments, Mannequin Templates, and Coaching
Higher testing. We had stable pipeline testing in PySpark, however the brand new structure continues to be catching up. Current dbt variations launched unit testing — now you can validate SQL mannequin logic towards mock information with out spinning up the total pipeline. We wish to add dbt assessments each on the mannequin stage and as a separate monitoring layer.
Reusable templates for frequent patterns. Lots of our dbt fashions look alike. A single config might describe a dozen fashions with the identical sample — solely the supply desk and filters differ. We plan to extract the shared logic into dbt macros.
Increasing the platform’s consumer base. We wish extra engineers and analysts to work with information independently. We’re planning common inside coaching classes, documentation, and onboarding guides so new customers can stand up to hurry shortly and begin constructing their very own fashions.
In case your crew is caught in the identical “analysts anticipate builders” loop, I’d love to listen to the way you’re fixing it. Join with me on LinkedIn and let’s evaluate notes.
All photos on this article are by the creator until in any other case famous.



{kind=link}