
Constructing pure conversational experiences requires speech synthesis that retains tempo with real-time interactions. At present, we’re excited to announce the brand new Bidirectional Streaming API for Amazon Polly, enabling streamlined real-time text-to-speech (TTS) synthesis the place you can begin sending textual content and receiving audio concurrently.
This new API is constructed for conversational AI purposes that generate textual content or audio incrementally, like responses from giant language fashions (LLMs), the place customers should start synthesizing audio earlier than the total textual content is offered. Amazon Polly already helps streaming synthesized audio again to customers. The brand new API goes additional specializing in bidirectional communication over HTTP/2, permitting for enhanced velocity, decrease latency, and streamlined utilization.
The problem with conventional text-to-speech
Conventional text-to-speech APIs observe a request-response sample. This required you to gather the whole textual content earlier than making a synthesis request. Amazon Polly streams audio again incrementally after a request is made, however the bottleneck is on the enter facet—you possibly can’t start sending textual content till it’s totally accessible. In conversational purposes powered by LLMs, the place textual content is generated token by token, this implies ready for the whole response earlier than synthesis begins.
Think about a digital assistant powered by an LLM. The mannequin generates tokens incrementally over a number of seconds. With conventional TTS, customers should look ahead to:
- The LLM to complete producing the whole response
- The TTS service to synthesize the whole textual content
- The audio to obtain earlier than playback begins
The brand new Amazon Polly bidirectional streaming API is designed to handle these bottlenecks.
What’s new: Bidirectional Streaming
The StartSpeechSynthesisStream API introduces a basically completely different strategy:
- Ship textual content incrementally: Stream textual content to Amazon Polly because it turns into accessible—no want to attend for full sentences or paragraphs.
- Obtain audio instantly: Get synthesized audio bytes again in real-time as they’re generated.
- Management synthesis timing: Use flush configuration to set off quick synthesis of buffered textual content.
- True duplex communication: Ship and obtain concurrently over a single connection.
Key Parts
| Part | Occasion Course | Course | Function |
TextEvent |
Inbound | Shopper → Amazon Polly | Ship textual content to be synthesized |
CloseStreamEvent |
Inbound | Shopper → Amazon Polly | Sign finish of textual content enter |
AudioEvent |
Outbound | Amazon Polly → Shopper | Obtain synthesized audio chunks |
StreamClosedEvent |
Outbound | Amazon Polly → Shopper | Affirmation of stream completion |
Comparability to conventional strategies
Conventional file separation implementations
Beforehand, reaching low-latency TTS required application-level implementations:
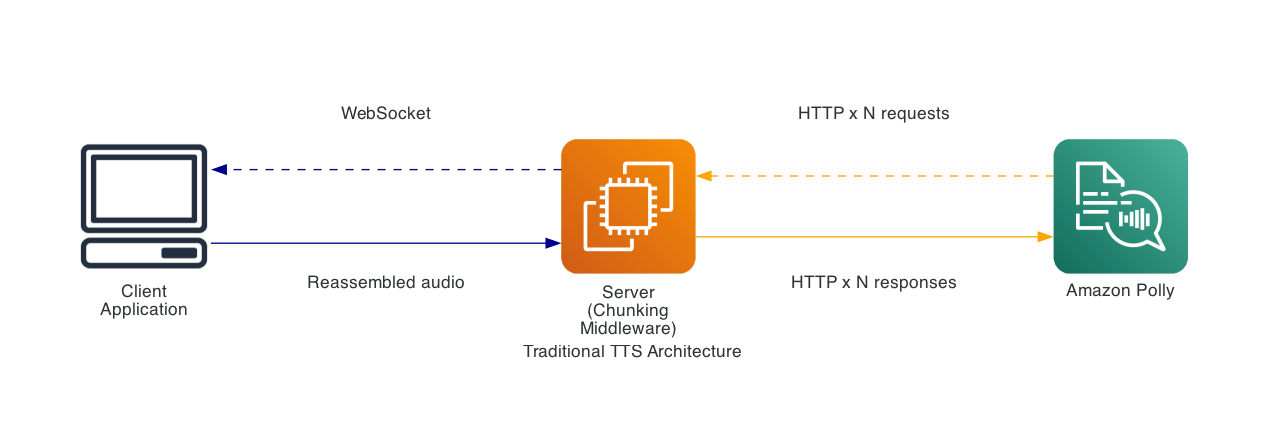
This strategy required:
- Server-side textual content separation logic
- A number of parallel Amazon Polly API calls
- Complicated audio reassembly
After: Native Bidirectional Streaming

Advantages:
- No separation logic required
- Single persistent connection
- Native streaming in each instructions
- Decreased infrastructure complexity
- Decrease latency
Efficiency benchmarks
To measure the real-world affect, we benchmarked each the standard SynthesizeSpeech API and the brand new bidirectional StartSpeechSynthesisStream API towards the identical enter: 7,045 characters of prose (970 phrases), utilizing the Matthew voice with the Generative engine, MP3 output at 24kHz in us-west-2.
How we measured: Each assessments simulate an LLM producing tokens at ~30 ms per phrase. The standard API check buffers phrases till a sentence boundary is reached, then sends the whole sentence as a SynthesizeSpeech request and waits for the total audio response earlier than persevering with. These assessments mirror how conventional TTS integrations work, since you should have the whole sentence earlier than requesting synthesis. The bidirectional streaming API check sends every phrase to the stream because it arrives, permitting Amazon Polly to start synthesis earlier than the total textual content is offered. Each assessments use the identical textual content, voice, and output configuration.
| Metric | Conventional SynthesizeSpeech | Bidirectional Streaming | Enchancment |
| Whole processing time | 115,226 ms (~115s) | 70,071 ms (~70s) | 39% quicker |
| API calls | 27 | 1 | 27x fewer |
| Sentences despatched | 27 (sequential) | 27 (streamed as phrases arrive) | — |
| Whole audio bytes | 2,354,292 | 2,324,636 | — |
The important thing benefit is architectural: the bidirectional API permits sending enter textual content and receiving synthesized audio concurrently over a single connection. As an alternative of ready for every sentence to build up earlier than requesting synthesis, textual content is streamed to Amazon Polly word-by-word because the LLM produces it. For conversational AI, which means Amazon Polly receives and processes textual content incrementally all through era, relatively than receiving it all of sudden after the LLM finishes. The result’s much less time ready for synthesis after era completes—the general end-to-end latency from immediate to completely delivered audio is considerably diminished.
Technical implementation
Getting began
You should utilize the bidirectional streaming API with AWS SDK for Java-2x, JavaScript v3, .NET v4, C++, Go v2, Kotlin, PHP v3, Ruby v3, Rust, and Swift. Help for CLIs (AWS Command Line Interface (AWS CLI) v1 and v2, PowerShell v4 and v5), Python, .NET v3 usually are not at the moment supported. Right here’s an instance:
Sending textual content occasions
Textual content is distributed to Amazon Polly utilizing a reactive streams Writer. Every TextEvent incorporates textual content:
Dealing with audio occasions
Audio arrives by a response handler with a customer sample:
Full instance: streaming textual content from an LLM
Right here’s a sensible instance exhibiting find out how to combine bidirectional streaming with incremental textual content era:
Integration sample with LLM streaming
The next reveals find out how to combine patterns with LLM streaming:
Enterprise advantages
Improved consumer expertise
Latency immediately impacts consumer satisfaction. The quicker customers hear a response, the extra pure and interesting the interplay feels. The bidirectional streaming API permits:
- Decreased perceived wait time – Audio playback begins whereas the LLM remains to be producing, masking backend processing time.
- Increased engagement – Sooner, extra responsive interactions result in elevated consumer retention and satisfaction.
- Streamlined implementation – The setup and administration of the streaming answer is now a single API name with clear hooks and callbacks to take away the complexity.
Decreased operational prices
Streamlining your structure interprets on to value financial savings:
| Value issue | Conventional chunking | Bidirectional Streaming |
| Infrastructure | WebSocket servers, load balancers, chunking middleware | Direct client-to-Amazon Polly connection |
| Improvement | Customized chunking logic, audio reassembly, error dealing with | SDK handles complexity |
| Upkeep | A number of elements to watch and replace | Single integration level |
| API Calls | A number of calls per request (one per chunk) | Single streaming session |
Organizations can count on to cut back infrastructure prices by eradicating intermediate servers and reduce growth time through the use of native streaming functionality.
Use circumstances
The bidirectional streaming API is beneficial for:
- Conversational AI Assistants – Stream LLM responses on to speech
- Actual-time Translation – Synthesize translated textual content because it’s generated
- Interactive Voice Response (IVR) – Dynamic, responsive telephone programs
- Accessibility Instruments – Actual-time display readers and text-to-speech
- Gaming – Dynamic NPC dialogue and narration
- Reside Captioning – Audio output for dwell transcription programs
Conclusion
The brand new Bidirectional Streaming API for Amazon Polly represents a major development in real-time speech synthesis. By enabling true streaming in each instructions, it removes latency bottlenecks which have historically plagued conversational AI purposes.
Key takeaways:
- Decreased latency – Audio begins enjoying whereas textual content remains to be being generated
- Simplified structure – No want for file separation workarounds or complicated infrastructure
- Native LLM integration – Function-built for streaming textual content from language fashions
- Versatile management – Wonderful-grained management over synthesis timing with flush configuration
Whether or not you’re constructing a digital assistant, accessibility software, or any utility requiring responsive text-to-speech, the bidirectional streaming API offers the inspiration for really conversational experiences.
Subsequent steps
The bidirectional streaming API is now Typically Obtainable. To get began:
- Replace to the most recent AWS SDK for Java 2.x with bidirectional streaming help
- Evaluate the API documentation for detailed reference
- Strive the instance code on this publish to expertise the low-latency streaming
We’re excited to see what you construct with this new functionality. Share your suggestions and use circumstances with us!
Concerning the authors



{kind=link}