
Operating machine studying (ML) fashions in manufacturing requires extra than simply infrastructure resilience and scaling effectivity. You want practically steady visibility into efficiency and useful resource utilization. When latency will increase, invocations fail, or sources grow to be constrained, you want speedy perception to diagnose and resolve points earlier than they influence your clients.
Till now, Amazon SageMaker AI supplied Amazon CloudWatch metrics that supplied helpful high-level visibility, however these have been combination metrics throughout all cases and containers. Whereas useful for total well being monitoring, these aggregated metrics obscured particular person occasion and container particulars, making it troublesome to pinpoint bottlenecks, enhance useful resource utilization, or troubleshoot successfully.
SageMaker AI endpoints now assist enhanced metrics with configurable publishing frequency. This launch supplies the granular visibility wanted to observe, troubleshoot, and enhance your manufacturing endpoints. With SageMaker AI endpoint enhanced metrics, we are able to now drill down into container-level and instance-level metrics, which offer capabilities reminiscent of:
- View particular mannequin copy metrics. With a number of mannequin copies deployed throughout a SageMaker AI endpoint utilizing Inference Parts, it’s helpful to view metrics per mannequin copy reminiscent of concurrent requests, GPU utilization, and CPU utilization to assist diagnose points and supply visibility into manufacturing workload visitors patterns.
- View how a lot every mannequin prices. With a number of fashions sharing the identical infrastructure, calculating the true price per mannequin will be complicated. With enhanced metrics, we are able to now calculate and affiliate price per mannequin by monitoring GPU allocation on the inference element stage.
What’s new
Enhanced metrics introduce two classes of metrics with a number of ranges of granularity:
- EC2 Useful resource Utilization Metrics: Observe CPU, GPU, and reminiscence consumption on the occasion and container stage.
- Invocation Metrics: Monitor request patterns, errors, latency, and concurrency with exact dimensions.
Every class supplies totally different ranges of visibility relying in your endpoint configuration.
Occasion-level metrics: accessible for all endpoints
Each SageMaker AI endpoint now has entry to instance-level metrics, supplying you with visibility into what’s occurring on every Amazon Elastic Compute Cloud (Amazon EC2) occasion in your endpoint.
Useful resource utilization (CloudWatch namespace: /aws/sagemaker/Endpoints)
Observe CPU utilization, reminiscence consumption, and per-GPU utilization and reminiscence utilization for each host. When a problem happens, you’ll be able to instantly determine which particular occasion wants consideration. For accelerator-based cases, you will notice utilization metrics for every particular person accelerator.
Invocation metrics (CloudWatch namespace: AWS/SageMaker)
Observe request patterns, errors, and latency by drilling right down to the occasion stage. Monitor invocations, 4XX/5XX errors, mannequin latency, and overhead latency with exact dimensions that make it easier to pinpoint precisely which occasion skilled points. These metrics make it easier to diagnose uneven visitors distribution, determine error-prone cases, and correlate efficiency points with particular sources.
Container-level metrics: for inference parts
Should you’re utilizing Inference Parts to host a number of fashions on a single endpoint, you now have container-level visibility.
Useful resource utilization (CloudWatch namespace: /aws/sagemaker/InferenceComponents)
Monitor useful resource consumption per container. See CPU, reminiscence, GPU utilization, and GPU reminiscence utilization for every mannequin copy. This visibility helps you perceive which inference element mannequin copies are consuming sources, keep honest allocation in multi-tenant eventualities, and determine containers experiencing efficiency points. These detailed metrics embody dimensions for InferenceComponentName and ContainerId.
Invocation metrics (CloudWatch namespace: AWS/SageMaker)
Observe request patterns, errors, and latency on the container stage. Monitor invocations, 4XX/5XX errors, mannequin latency, and overhead latency with exact dimensions that make it easier to pinpoint precisely the place points occurred.
Configuring enhanced metrics
Allow enhanced metrics by including one parameter when creating your endpoint configuration:
response = sagemaker_client.create_endpoint_config(
EndpointConfigName="my-config",
ProductionVariants=[{
'VariantName': 'AllTraffic',
'ModelName': 'my-model',
'InstanceType': 'ml.g6.12xlarge',
'InitialInstanceCount': 2
}],
MetricsConfig={
'EnableEnhancedMetrics': True,
'MetricsPublishFrequencyInSeconds': 10, # Default 60s
})Selecting your publishing frequency
After you’ve enabled enhanced metrics, configure the publishing frequency based mostly in your monitoring wants:
Commonplace decision (60 seconds): The default frequency supplies detailed visibility for many manufacturing workloads. That is enough for capability planning, troubleshooting, and optimization, whereas preserving prices manageable.
Excessive decision (10 or 30 seconds): For crucial functions needing close to real-time monitoring, allow 10-second publishing. That is useful for aggressive auto scaling, extremely variable visitors patterns, or deep troubleshooting.
Instance use instances
On this put up, we stroll by means of three widespread eventualities the place Enhanced Metrics delivers measurable enterprise worth, all of that are accessible on this pocket book :
- Actual-time GPU utilization monitoring throughout Inference Parts
When working a number of fashions on shared infrastructure utilizing Inference Parts, understanding GPU allocation and utilization is crucial for price optimization and efficiency tuning.With enhanced metrics, you’ll be able to question GPU allocation per inference element:
response = cloudwatch.get_metric_data(
MetricDataQueries=[ {
'Id': 'm1',
'Expression': 'SEARCH('{/aws/sagemaker/InferenceComponents,InferenceComponentName,GpuId} MetricName="GPUUtilizationNormalized" InferenceComponentName="IC-my-model"', 'SampleCount', 10)'
}, {
'Id': 'e1',
'Expression': 'SUM(m1)' # Returns GPU count
} ],
StartTime=start_time,
EndTime=end_time )This question makes use of the GpuId dimension to rely particular person GPUs allotted to every inference element. By monitoring the SampleCount statistic, you get a exact rely of GPUs in use for a selected Inference Element, which is crucial for:
- Validating useful resource allocation matches your configuration
- Detecting when inference parts scale up or down
- Calculating per-GPU prices for chargeback fashions
- Per-model price attribution in multi-model deployments
Probably the most requested capabilities is knowing the true price of every mannequin when a number of fashions share the identical endpoint infrastructure. Enhanced metrics make this doable by means of container-level GPU monitoring.Right here’s the way to calculate cumulative price per mannequin:
response = cloudwatch.get_metric_data(
MetricDataQueries=[ {
'Id': 'e1',
'Expression': 'SEARCH('{/aws/sagemaker/InferenceComponents,InferenceComponentName,GpuId} MetricName="GPUUtilizationNormalized" InferenceComponentName="IC-my-model"', 'SampleCount', 10)'
}, {
'Id': 'e2',
'Expression': 'SUM(e1)' # GPU count
}, {
'Id': 'e3',
'Expression': 'e2 * 5.752 / 4 / 360' # Cost per 10s based on ml.g6.12xlarge hourly cost
}, {
'Id': 'e4',
'Expression': 'RUNNING_SUM(e3)' # Cumulative cost
} ],
StartTime=start_time, EndTime=end_time ) This calculation:
- Counts GPUs allotted to the inference element (e2)
- Calculates price per 10-second interval based mostly on occasion hourly price (e3)
- Accumulates complete price over time utilizing
RUNNING_SUM(e4)
For instance, with an ml.g6.12xlarge occasion ($5.752/hour for 4 GPUs), in case your mannequin makes use of 4 GPUs, the price per 10 seconds is $0.016. The RUNNING_SUM supplies a repeatedly rising complete, excellent for dashboards and value monitoring.
- Cluster-wide useful resource monitoring
Enhanced metrics allow complete cluster monitoring by aggregating metrics throughout all inference parts on an endpoint:
response = cloudwatch.get_metric_data(
MetricDataQueries=[ {
'Id': 'e1',
'Expression': 'SUM(SEARCH('{/aws/sagemaker/InferenceComponents,EndpointName,GpuId} MetricName="GPUUtilizationNormalized" EndpointName="my-endpoint"', 'SampleCount', 10))'
}, {
'Id': 'm2',
'MetricStat': {
'Metric': {
'Namespace': '/aws/sagemaker/Endpoints',
'MetricName': 'CPUUtilizationNormalized',
'Dimensions': [ {
'Name': 'EndpointName',
'Value': 'my-endpoint'
}, {
'Name': 'VariantName',
'Value': 'AllTraffic'
}
] },
'Interval': 10,
'Stat': 'SampleCount' # Returns occasion rely
}
}, {
'Id': 'e2',
'Expression': 'm2 * 4 - e1' # Free GPUs (assuming 4 GPUs per occasion)
} ],
StartTime=start_time, EndTime=end_time ) This question supplies:
- Complete GPUs in use throughout all inference parts (e1)
- Variety of cases within the endpoint (m2)
- Accessible GPUs for brand new deployments (e2)
This visibility is essential for capability planning and ensuring that you’ve enough sources for brand new mannequin deployments or scaling present ones.
Creating operational dashboards
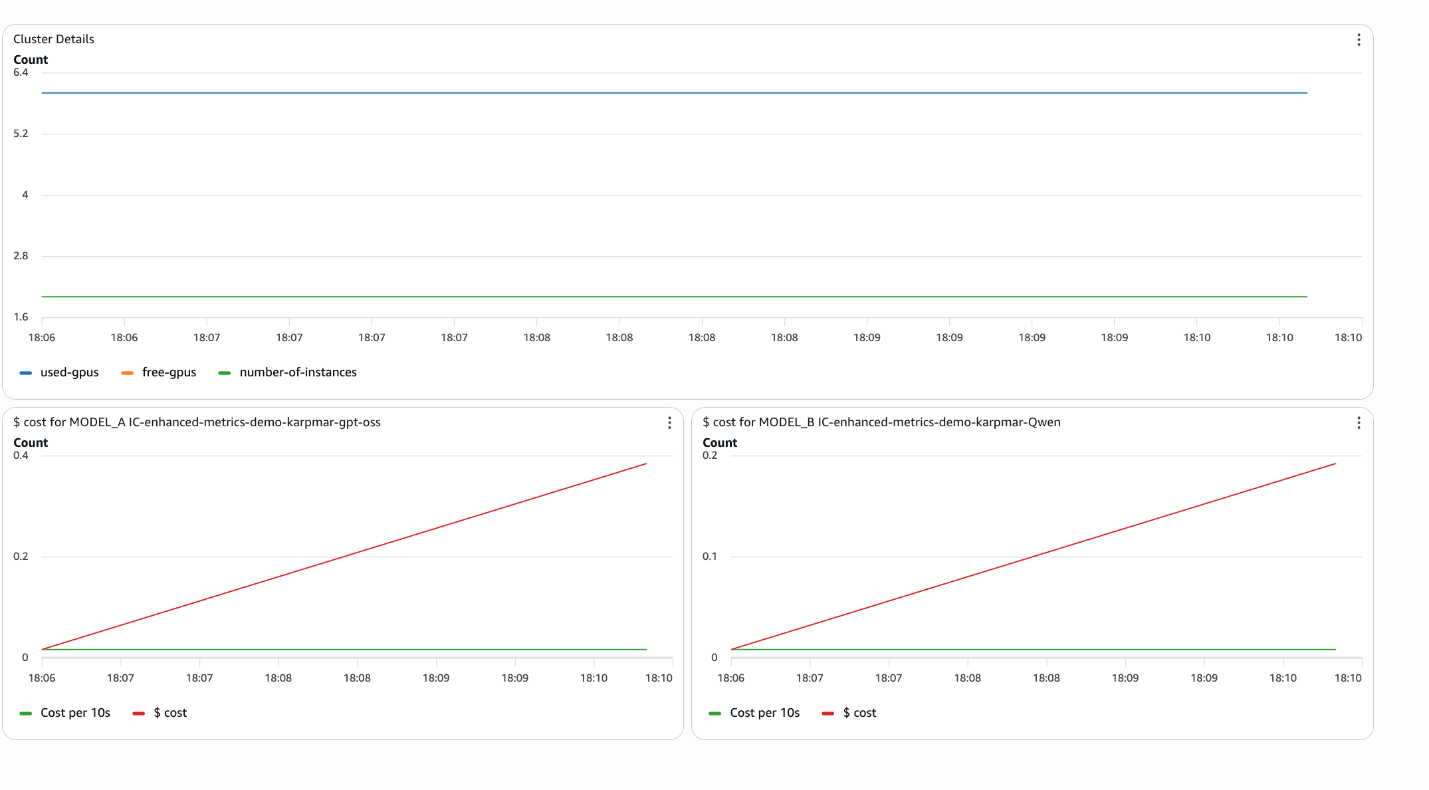
The accompanying pocket book demonstrates the way to create CloudWatch dashboards programmatically that mix these metrics:
from endpoint_metrics_helper import create_dashboard
create_dashboard(
dashboard_name="my-endpoint-monitoring",
endpoint_name="my-endpoint",
inference_components=[ {
'name': 'IC-model-a',
'label': 'MODEL_A'
}, {
'name': 'IC-model-b',
'label': 'MODEL_B'
} ],
cost_per_hour=5.752,
area='us-east-1' )This creates a dashboard with:
- Cluster-level useful resource utilization (cases, used/unused GPUs)
- Per-model price monitoring with cumulative totals
- Actual-time price per 10-second interval
The pocket book additionally contains interactive widgets for ad-hoc evaluation.
from endpoint_metrics_helper import create_metrics_widget, create_cost_widget
# Cluster metrics
create_metrics_widget('my-endpoint')
# Per-model price evaluation
create_cost_widget ('IC-model-a', cost_per_hour=5.752)These widgets present dropdown time vary choice (final 5/10/half-hour, 1 hour, or customized vary) and show:
- Variety of cases
- Complete/used/free GPUs
- Cumulative price per mannequin
- Price per 10-second interval
Greatest practices
- Begin with a 60-second decision: This supplies enough granularity for many use instances whereas preserving CloudWatch prices manageable. Be aware that solely Utilization metrics generate CloudWatch prices. All different metric varieties are revealed at no further price to you.
- Use 10-second decision selectively: Allow high-resolution metrics just for crucial endpoints or throughout troubleshooting intervals.
- Use dimensions strategically: Use
InferenceComponentName,ContainerId, andGpuIddimensions to drill down from cluster-wide views to particular containers. - Create price allocation dashboards: Use
RUNNING_SUMexpressions to trace cumulative prices per mannequin for correct chargeback and budgeting. - Arrange alarms on unused GPU capability: Monitor the unused GPU metric to just remember to keep buffer capability for scaling or new deployments.
- Mix with invocation metrics: Correlate useful resource utilization with request patterns to grasp the connection between visitors and useful resource consumption.
Conclusion
Enhanced Metrics for Amazon SageMaker AI Endpoints transforms the way you monitor, enhance, and function manufacturing ML workloads. By offering container-level visibility with configurable publishing frequency, you acquire the operational intelligence wanted to:
- Precisely attribute prices to particular person fashions in multi-tenant deployments
- Monitor real-time GPU allocation and utilization throughout inference parts
- Observe cluster-wide useful resource availability for capability planning
- Troubleshoot efficiency points with exact, granular metrics
The mix of detailed metrics, versatile publishing frequency, and wealthy dimensions lets you construct refined monitoring options that scale together with your ML operations. Whether or not you’re working a single mannequin or managing dozens of inference parts throughout a number of endpoints, enhanced metrics present the visibility it is advisable to run AI effectively at scale.
Get began in the present day by enabling enhanced metrics in your SageMaker AI endpoints and discover the accompanying pocket book for full implementation examples and reusable helper capabilities.
Concerning the authors



{kind=link}