
A key growth in generative AI is AI-powered video era. Earlier than AI, creating dynamic video content material required in depth sources, technical experience, and important guide effort. At present, AI fashions can generate movies from easy inputs, however organizations nonetheless face challenges like unpredictable outcomes. This publish introduces Video Retrieval-Augmented Era (V-RAG), an strategy to assist enhance video content material creation. By combining retrieval augmented era with superior video AI fashions, V-RAG gives an environment friendly, and dependable answer for producing AI movies.
Video era
AI video era represents a transformative frontier in digital content material creation, enabling the automated manufacturing of dynamic visible narratives with out conventional filming or animation processes. By utilizing deep studying architectures, these methods can synthesize sensible or stylized video sequences. Not like typical video manufacturing that requires cameras, actors, and in depth post-production, AI era creates content material totally by means of computational processes analyzing patterns from large coaching datasets to render coherent visible tales. People and organizations can use this know-how to provide visible content material with minimal technical experience, decreasing the time, sources, and specialised abilities historically required. As these fashions proceed to evolve, they promise to essentially reshape how visible tales are conceived, produced, and shared throughout industries starting from leisure and advertising to training and communication.
Textual content-to-video era
Textual content-to-video era creates dynamic video content material from narrative or thematic textual content prompts. This know-how interprets textual descriptions and transforms them into coherent visible sequences that observe the required narrative. Whereas textual content prompts successfully information the general theme and storyline, they will typically fall quick in capturing extremely particular visible particulars with precision. Textual content-to-video serves as the muse of AI video creation, the place customers can generate content material primarily based on descriptive language alone.
Video era customization
Textual content prompting can solely get you to this point with video era. There’s inherently restricted management when relying solely on textual content descriptions, as fashions can ignore essential elements of your immediate or interpret them in another way than you meant. Sure visible ideas show tough to elucidate in phrases alone, moreover, you’re constrained by the mannequin’s token restrict that caps how detailed your directions may be. That is the place additional customization turns into invaluable. Customers can use strong customization instruments to specify quite a few parameters past what textual content can effectively talk, akin to type, temper, and complex visible aesthetics. These controls assist overcome the restrictions of textual content prompting by offering direct mechanisms to affect the output. With out such capabilities, creators are left hoping the mannequin accurately interprets their intentions reasonably than actively directing the artistic course of. Customization bridges the hole between obscure era and exact visible management, making AI video instruments really helpful for skilled purposes.
Mannequin fine-tuning
Advantageous-tuning adapts pre-trained video era fashions to particular domains, types, or use circumstances. This course of permits organizations to create specialised video turbines that excel at duties whether or not they’re producing product demonstrations with constant branding, producing medical academic content material, or creating movies in a particular creative type. Advantageous-tuning usually includes additional coaching of current fashions on fastidiously curated datasets representing the goal area, permitting the mannequin to study the distinctive visible patterns, actions, and stylistic parts required for specialised purposes. Nonetheless, fine-tuning video era fashions presents important challenges. The basic impediment begins with knowledge acquisition as a result of high-quality video knowledge that’s appropriate for coaching is each costly and tough to acquire. Organizations want numerous, well-labeled footage in a particular format masking particular use circumstances whereas assembly technical high quality requirements. The computational calls for are substantial, representing a significant barrier to entry. A single fine-tuning run can require a number of high-end GPUs working constantly, and retraining to include new capabilities multiplies these prices with every iteration. Even with excellent knowledge and limitless computational sources, success stays unsure because of the interconnected nature of video parts like coherence, bodily accuracy, lighting consistency, and object persistence. Enhancements in a single space typically led to sudden degradation in others, creating advanced optimization challenges immune to easy options.
Picture-to-video
Picture-to-video era enhances text-based approaches by providing extra visible management. By utilizing an enter picture as a reference, customers can guarantee particular particulars akin to the colour, type, and different attributes of objects are precisely represented within the generated video. For instance, if a person desires to characteristic a pink purse of their video, offering a picture of that precise purse ensures visible constancy that textual content descriptions alone won’t obtain. This method maintains consistency and improves immediate adherence by means of conditioning, whereas enabling dynamic motion and integration throughout the broader narrative context. Picture-to-video era doesn’t require any fine-tuning.
V-RAG: an efficient strategy in video era customization
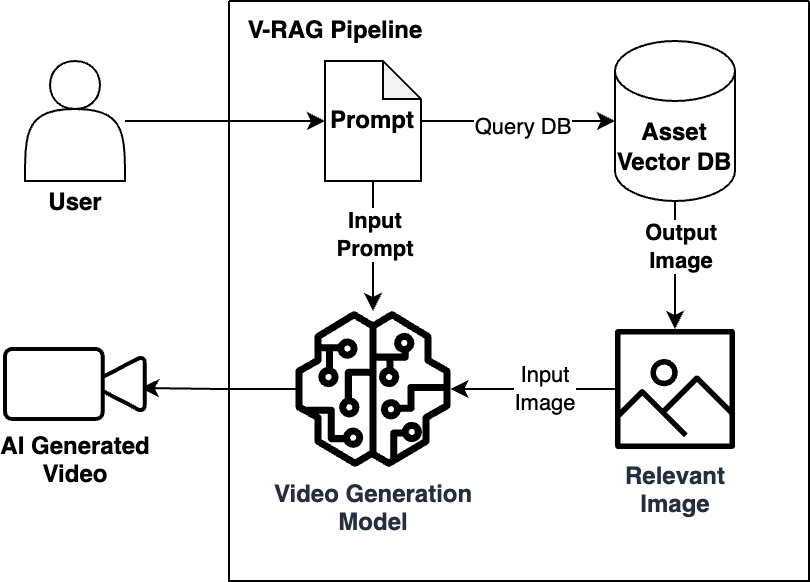
Video Retrieval-Augmented Era (V-RAG) builds upon image-to-video know-how to broaden video customization capabilities. Whereas conventional image-to-video converts a single reference picture into movement, V-RAG expands this functionality by retrieving and incorporating a related picture from a database to feed right into a video era. This strategy gives a number of capabilities with out requiring any mannequin coaching or retraining. Organizations can ingest their picture collections right into a vector database, question it, and feed its output to an current video era mannequin and begin producing tailor-made content material instantly.
V-RAG’s effectivity comes from requiring solely static pictures, that are typically extra available than video coaching knowledge. These pictures may be added to the vector database on the fly, making them immediately out there for the following era process with out computational delays. Each video generated by means of this course of maintains clear traceability to its supply pictures, creating an auditable path that enhances verification and debugging capabilities. The system grounds video outputs in particular reference imagery, which is designed to assist cut back hallucination dangers and handle computational prices. Organizations can preserve separate visible data bases for various departments or use circumstances, streamlining compliance as all supply supplies may be completely vetted earlier than coming into the system.
Logical Diagram of V-RAG
The evolving nature of V-RAG
V-RAG represents not a hard and fast know-how, however an evolving framework that can constantly broaden as AI capabilities advance. Whereas present implementations primarily make the most of picture databases, the basic retrieval augmentation strategy is modality-agnostic. As multimodal AI fashions mature, V-RAG methods will naturally incorporate audio samples, video snippets, and 3D fashions as reference factors throughout era. Future iterations will seemingly assist synthesizing full audio-visual experiences, producing movies with completely synchronized speech, sensible environmental sounds, and customized musical scores primarily based on retrieved audio patterns. This flexibility positions V-RAG as a foundational paradigm reasonably than a particular implementation, permitting it to adapt alongside broader AI developments whereas sustaining its core advantages of traceability, effectivity, and lowered hallucination. The last word imaginative and prescient extends past even audiovisual content material to doubtlessly incorporating interactive parts, making a complete multimodal era system that may produce partaking outputs whereas sustaining grounding in dependable reference materials.
Key advantages of V-RAG
Producing movies utilizing pictures retrieved by means of V-RAG gives important advantages like elevated accuracy, relevance, and contextual understanding. This strategy grounds generated content material in a particular data base to assist information video creation. This reduces hallucination and ensures that the video aligns with data from the picture supply, making it significantly helpful for academic, documentary, or explainer video codecs. Key advantages of utilizing V-RAG from pictures embrace:
- Factual accuracy – Making certain the generated video content material is grounded in actual data, decreasing the probability of inaccurate or deceptive visuals.
- Contextual relevance – Retrieving pictures which might be extremely related to the given matter or question, resulting in a extra cohesive and centered video narrative.
- Dynamic content material era – Permitting for versatile video creation by dynamically choosing and assembling pictures primarily based on person enter or altering necessities.
- Decreased growth time – Utilizing a pre-existing data base to chop down on the time wanted to assemble and curate visible property for video creation.
- Personalised content material – Tailoring movies to particular person person wants, producing content material designed to be related and interesting.
- Scalability – Designed to scale by ingesting extra pictures into the vector database.
Actual-world purposes of V-RAG
Actual-world purposes of V-RAG are huge and assorted. In training, V-RAG can mechanically create tutorial movies by pulling related pictures from a topic data base. For personalised content material, V-RAG can tailor video content material to particular person customers by retrieving pictures primarily based on their particular pursuits. For advertising, V-RAG can create focused video advertisements by pulling pictures that align with particular demographics or product options.
Conclusion
As AI know-how continues to evolve, V-RAG’s versatile framework positions it to include new modalities and capabilities, from superior audio integration to interactive parts. The AWS implementation demonstrates how organizations can already start utilizing this know-how by means of current cloud providers, making AI video era accessible to a broader vary of customers. Wanting forward, V-RAG’s influence on video content material creation will seemingly prolong far past its present purposes in training, and advertising. Because the know-how matures, it has the potential to make video manufacturing accessible whereas supporting high quality, accuracy, and customization. This strategy gives a promising path for AI-powered video era, enabling organizations to create compelling visible content material.
References
Acknowledgement
Particular because of Vishwa Gupta, Shuai Cao and Seif for his or her contribution.
Concerning the authors



{kind=link}