displays the state of Claude Abilities, MCP, and subagents as of February 2026. AI strikes quick, so some particulars could also be outdated by the point you learn this. The ideas this put up focuses on, nevertheless, are timeless.
In the event you’ve been constructing with LLMs for some time, you’ve most likely lived by means of this loop time and again: you are taking your time crafting a terrific immediate that results in wonderful outcomes, after which a couple of days later you want the identical habits once more, so that you begin prompting from scratch once more. After some repetitions you possibly notice the inefficiencies, so that you’re going to retailer the immediate’s template someplace in an effort to retrieve it for later, however even then you want to discover your immediate, paste it in, and tweak it for this explicit dialog. It’s so tedious.
That is what I name the immediate engineering hamster wheel. And it’s a basically damaged workflow.
Claude Abilities are Anthropic’s reply to this “reusable immediate” downside, and extra. Past simply saving you from repetitive prompting, they introduce a basically completely different strategy to context administration, token economics, and the structure of AI-powered growth workflows.
On this put up, I’ll unpack what abilities and subagents truly are, how they differ from conventional MCP, and the place the talent / MCP / subagent combine is heading.
What are Abilities?
At their core, abilities are reusable instruction units that AI Brokers, like Claude, can mechanically entry after they’re related to a dialog. You write a talent.md file with some metadata and a physique of directions, drop it right into a .claude/abilities/ listing, and Claude takes it from there.
Their seems
In its easiest kind, a talent is a markdown file with a reputation, description, and physique of directions, like this:
---
title:
description:
---
Their strenghts
The primary power of abilities lies within the auto-invocation. When beginning a brand new dialog, the agent solely reads every talent’s title and outline, to avoid wasting on tokens. When it determines a talent is related, it hundreds the physique. If the physique references further recordsdata or folders, the agent reads these too, however solely when it decides they’re wanted. In essence, abilities are lazy-loaded context. The agent doesn’t devour the total instruction set upfront. It progressively discloses data to itself, pulling in solely what’s wanted for the present step.
This progressive disclosure operates throughout three ranges, every with its personal context finances:
- Metadata (loaded at startup): The talent’s title (max 64 characters) and outline (max 1,024 characters). This prices roughly ~100 tokens per talent, negligible overhead even with lots of of abilities registered.
- Talent physique (loaded on invocation): The total instruction set inside
talent.md, as much as ~5,000 tokens. This solely enters the context window when the agent determines the talent is related. - Referenced recordsdata (loaded on demand): Further markdown recordsdata, folders, or scripts throughout the talent listing. There’s virtually no restrict right here, and the agent reads these on demand, solely when the directions reference them and the present job requires it.

Perception: Abilities are reusable, lazy-loaded, and auto-invoked instruction units that use progressive disclosure throughout three ranges: metadata, physique, and referenced recordsdata. This minimizes the upfront value by stopping to dump all the things into the context window (taking a look at you, MCP 👀).
The issue in token economics
Value components
It’s no secret; an agent’s context window house isn’t free, and filling it has compounding prices. Each token in your context window prices you in 3 ways:
- Precise value: the plain one is that you simply’re paying per token. This may be immediately by means of API utilization, or not directly by means of utilization limits.
- Latency: you’re additionally paying together with your time, since extra enter tokens means slower responses. One thing that doesn’t scale nicely with the size of the context window (~consideration mechanism).
- High quality: lastly, there’s additionally a degradation in high quality because of lengthy context home windows. LLMs demonstrably carry out worse when their context is cluttered with irrelevant data.
The expensive overhead of MCPs
Let’s put this into perspective, by means of a fast back-of-the-envelope calculation. My go-to MCP picks for programming are:
- AWS for infrastructure deployment. Three servers (
aws-mcp,aws-official,aws-docs) mixed yield a price of round ~8,500 tokens (13 instruments). - Context7 for documentation. Metadata is round ~750 tokens (2 instruments).
- Figma for bringing design to frontend growth. Metadata is round ~500 tokens (2 instruments).
- GitHub for looking code in different repositories. Metadata is round ~2,000 tokens (26 instruments).
- Linear for mission administration. Metadata is round ~3,250 tokens (33 instruments).
- Serena for code search. Metadata is round ~4,500 tokens (26 instruments).
- Sentry for error monitoring. Metadata is round ~12,500 tokens (22 instruments).
That’s a complete of roughly ~32,000 tokens of instrument metadata, loaded into each single message, whether or not you’re interacting with the instrument or not.
To place a greenback determine on this: Claude Opus 4.6 fees $5 per million enter tokens. These 32K tokens of idle MCP metadata add $0.16 to each message you ship. That sounds small, till you notice that even a easy 5-message dialog already provides $0.8 in pure overhead. And most builders don’t ship simply 5 messages; add some quick clarifications and context-gathering questions and also you rapidly attain 10s if not 100s of messages. Let’s say on common you ship 50 messages a day over a 20-day work month, that’s $8/day, ~$160/month* in pure overhead, only for instrument descriptions sitting in context. And that’s earlier than you account for the latency and high quality influence.
*A small asterisk: most fashions cost considerably much less for cached enter tokens (90% low cost). An asterisk to this asterisk is that a few of them cost further when enabling caching, they usually don’t all the time allow (API) caching by default (cough Claude cough).
The fee-effective strategy of abilities
The loading patttern of Abilities basically change all three value components. On the outset, the agent solely sees every talent’s title and a brief description, roughly ~100 tokens per talent. Like this, I may register 300 abilities and nonetheless devour fewer tokens than my MCP setup does. The total instruction physique (~5,000 tokens) solely hundreds when the agent decides it’s related, and referenced recordsdata will solely load when the present step wants them.
In observe, a typical dialog would possibly invoke one or two abilities whereas the remaining stay invisible to the context window. That’s the important thing distinction: MCP value scales with the variety of registered instruments (throughout all servers), whereas abilities’ value scales extra intently with precise utilization.

Perception: MCP is “keen” and hundreds all instrument metadata upfront no matter whether or not it’s used. Abilities are “lazy” and cargo context progressively and solely when related. The distinction issues for value, latency, and output high quality.
Wait, that’s deceptive? Abilities and MCP are two fully various things!
If the above reads like abilities are the brand new and higher MCPs, then permit me to appropriate that framing. The intent was to zoom in on their loading patterns and the influence they’ve on token consumption. Functionally, they’re fairly completely different.
MCP (Mannequin Context Protocol) is an open normal that provides any LLM the power to work together with exterior functions. Earlier than MCP, connecting M fashions to N instruments required M * N customized integrations. MCP collapses that to M + N: every mannequin implements the protocol as soon as, every instrument exposes it as soon as, they usually all interoperate. It’s a easy infrastructural change, however it’s genuinely highly effective (no marvel it took the world by storm).
Abilities, then again, are considerably “glorified prompts”, and I imply that in the absolute best manner. They provide an agent experience and route on find out how to strategy a job, what conventions to comply with, when to make use of which instrument, and find out how to construction its output. They’re reusable instruction units fetched on-demand when related, nothing extra, nothing much less.
Perception: MCP offers an agent capabilities (the “what”). Abilities give it experience (the “how”) and thus they’re complementary.
Right here’s an instance to make this concrete. Say you join GitHub’s MCP server to your agent. MCP offers the agent the power to create pull requests, listing points, and search repositories. Nevertheless it doesn’t inform the agent, for instance, how your group constructions PRs, that you simply all the time embrace a testing part, that you simply tag by change sort, that you simply reference the Linear ticket within the title. That’s what a talent does. The MCP gives the instruments, the talent gives the playbook.
So, when earlier I confirmed that abilities load context extra effectively than MCP, the true takeaway isn’t “use abilities as an alternative of MCP”, it’s that lazy-loading as a sample works. Therefore, it’s value asking: why can’t MCP instrument entry be lazy-loaded too? That’s the place subagents are available in.
Subagents: better of each worlds
Subagents are specialised youngster brokers with their very own remoted context window and instruments linked. Two properties make them highly effective:
- Remoted context: A subagent begins with a clear context window, pre-loaded with its personal system immediate and solely the instruments assigned to it. All the pieces it reads, processes, and generates stays in its personal context, the primary agent solely sees the ultimate end result.
- Remoted instruments: Every subagent could be geared up with its personal set of MCP servers and abilities. The primary agent doesn’t have to find out about (or pay for) instruments it by no means immediately makes use of.
As soon as a subagent finishes its job, its whole context is discarded. The instrument metadata, the intermediate reasoning, the API responses: all gone. Solely the end result flows again to the primary agent. That is truly a terrific factor. Not solely can we keep away from bloating the primary agent’s context with pointless instrument metadata, we additionally stop pointless reasoning tokens from polluting the context. As an illustrative instance, think about a subagent that researches a library’s API. It would search throughout a number of documentation sources, learn by means of dozens of pages, and check out a number of queries earlier than discovering the fitting reply. You continue to pay for the subagent’s personal token utilization, however all of that intermediate work, the lifeless ends, the irrelevant pages, the search queries, will get discarded as soon as the subagent finishes. The important thing profit is that none of it compounds into the primary agent’s context, so each subsequent message in your dialog stays clear and low cost.
This implies you possibly can design your setup in order that MCP servers are solely accessible by means of particular subagents, by no means loaded on the primary agent in any respect. As an alternative of carrying ~32,000 tokens of instrument metadata in each message, the primary agent carries almost zero. When it must open a pull request, it spins up a GitHub subagent, creates the PR, and returns the hyperlink. Much like abilities being lazy-loaded context, subagents are lazy-loaded staff: the primary agent is aware of what specialists it might name on, and solely spins one up when a job calls for it.
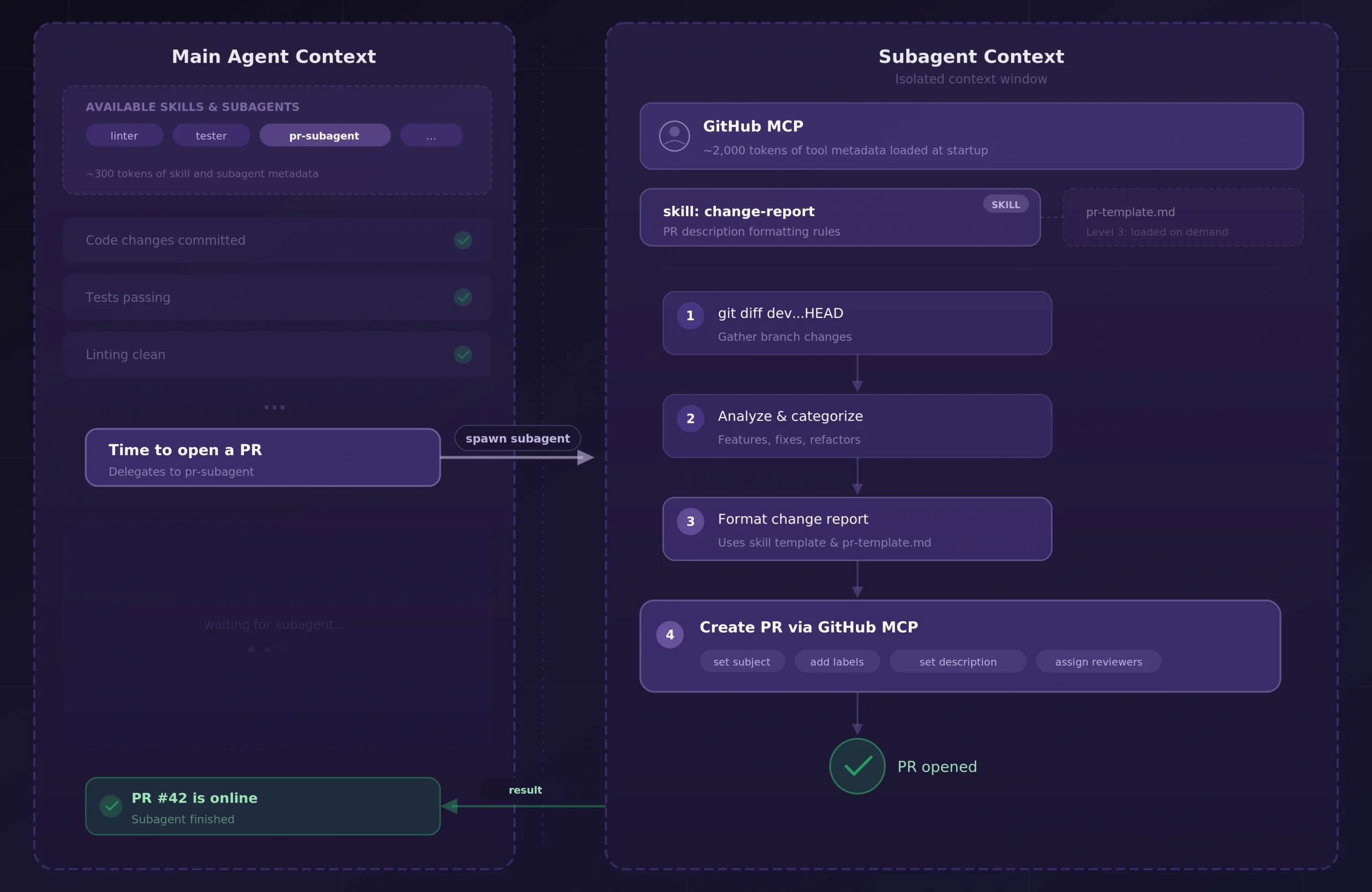
A sensible instance
Let’s make this tangible. One workflow I exploit each day is a “function department wrap-up” that automates most of a really tedious a part of my growth cycle: opening a pull request. Right here’s how abilities, MCP, and subagents play collectively.
After the primary agent and I end the coding work, I ask it to wrap up the function department. The primary agent doesn’t deal with this itself; it delegates your entire PR workflow to a devoted subagent. This subagent is provided with the GitHub MCP server and a change-report talent that defines how my group constructions PRs. Its talent.md seems roughly like this:
---
title: change-report
description: Use when producing a change report for a PR.
Defines the group's PR construction, categorization guidelines, and formatting
conventions.
---
1. Make sure that there are not any staging adjustments left, in any other case report again to
the primary agent
2. Run `git diff dev...HEAD --stat` and `git log dev..HEAD --oneline`
to assemble all adjustments on this function department.
3. Analyze the diff and categorize essentially the most essential adjustments by their sort
(new options, refactors, bug fixes, or config adjustments).
4. Generate a structured change report following the template
in `pr-template.md`.
5. Open the PR through GitHub MCP, populating the title and physique from
the generated report.
6. Reply with the PR hyperlink.The pr-template.md file in the identical listing defines my group’s PR construction: sections for abstract, adjustments breakdown, and testing notes. That is stage 3 of progressive disclosure: the subagent solely reads it when step 4 tells it to.
Right here’s what makes this setup work. The talent gives the experience on how my group reviews on adjustments, the GitHub MCP gives the potential to truly create the PR, and the subagent gives the context boundary to carry out all of this work. The primary agent, then again, solely calls the subagent, waits for it to finish, and will get both a affirmation again or a message of what went mistaken.

Perception: abilities, MCPs, and subagents work in concord. The talent gives experience and instruction, MCP gives the potential, the subagent gives the context boundary (retaining the primary agent’s context clear).
The larger image
Within the early days of LLMs, the race was about higher fashions: fewer hallucinations, sharper reasoning, extra inventive output. That race hasn’t stopped fully, however the middle of gravity has definitely shifted. MCP and Claude Code have been genuinely revolutionary. Upgrading Claude Sonnet from 3.5 to three.7 truthfully was not. The incremental mannequin enhancements we’re getting immediately matter far lower than the infrastructure we construct round them. Abilities, subagents, and multi-agent orchestration are all a part of this shift: from “how can we make the mannequin smarter” to “how can we get essentially the most worth out of what’s already right here”.
Perception: the worth in AI growth has shifted from higher fashions to raised infrastructure. Abilities, subagents, and multi-agent orchestration aren’t simply developer expertise enhancements; they’re the structure that makes agentic AI economically and operationally viable at scale.
The place we’re immediately
Abilities clear up the immediate engineering hamster wheel by turning your greatest prompts into reusable, auto-invoked instruction units. Subagents clear up the context bloat downside by isolating instrument entry and intermediate reasoning into devoted staff. Collectively, they make it doable to codify your experience as soon as and have it mechanically utilized throughout each future interplay. That is what engineering groups following the state-of-the-practice already do with documentation, type guides, and runbooks. Abilities and subagents simply make these artifacts machine-readable.
The subagent sample can also be unlocking multi-agent parallelism. As an alternative of 1 agent working by means of duties sequentially, you possibly can spin up a number of subagents concurrently, have them work independently, and accumulate their outcomes. Anthropic’s personal multi-agent analysis system already does this: Claude Opus 4.6 orchestrates whereas Claude Sonnet 4.6 subagents execute in parallel. This naturally results in heterogeneous mannequin routing, the place an costly frontier mannequin orchestrates and plans, whereas smaller, cheaper fashions deal with execution. The orchestrator causes, the employees execute. This may dramatically cut back prices whereas sustaining output high quality.
There’s an essential caveat right here. The place parallelism works nicely for learn duties, it will get a lot tougher for write duties that contact shared state. Say, for instance, you’re spinning up a backend and a frontend subagent in parallel. The backend agent refactors an API endpoint, whereas the frontend agent, working from a snapshot taken earlier than that change, generates code that calls the outdated endpoint. Neither agent is mistaken in isolation, however collectively they produce an inconsistent end result. This can be a basic concurrency downside, coming from the AI workflows of the near-future, which so far stays an open downside.
The place it’s heading
I anticipate talent composition to develop into extra refined. Right now, abilities are comparatively flat: a markdown file with elective references. However the structure naturally helps layered abilities that reference different abilities, creating one thing like an inheritance hierarchy of experience. Suppose a base “code overview” talent prolonged by language-specific variants, additional prolonged by team-specific conventions.
Most multi-agent programs immediately are strictly hierarchical: a principal agent delegates to a subagent, the subagent finishes, and management returns. There’s presently not a lot peer-to-peer collaboration between subagents but. Anthropic’s just lately launched “agent groups” function for Opus 4.6 is an early step in the direction of this, permitting a number of brokers to coordinate immediately relatively than routing all the things by means of an orchestrator. On the protocol aspect, Google’s A2A (Agent-to-Agent Protocol) may standardize this sample throughout suppliers; the place MCP handles agent-to-tool communication, A2A would deal with agent-to-agent communication. That mentioned, A2A’s adoption has been gradual in comparison with MCP’s explosive progress. One to observe, not one to wager on but.
Brokers will develop into the brand new features
There’s a broader abstraction rising right here that’s value stepping again to understand. Andrej Karpathy’s well-known tweet “The most well liked new programming language is English” captured one thing actual about how we work together with LLMs. However abilities and subagents take this abstraction one stage additional: brokers have gotten the brand new features.
A subagent is a self-contained unit of labor: it takes an enter (a job description), has its personal inside state (context window), makes use of particular instruments (MCP servers), follows particular directions (abilities), and returns an output. It may be known as from a number of locations, it’s reusable, and it’s composable. That’s a perform. The primary agent turns into the execution thread: orchestrating, branching, delegating, and synthesizing outcomes from specialised staff.
Other than the analogy, it might have the identical sensible implications that features had for software program engineering. Isolation limits the blast radius when an agent fails, relatively than corrupting your entire system, and failures could be caught by means of try-except mechanisms. Specialization means every agent could be optimized for its particular job. Composability means you possibly can construct more and more advanced workflows from easy, testable elements. And observability follows naturally; since every agent is a discrete unit with clear inputs and outputs, tracing “why did the system do X” turns into inspecting a name stack relatively than observing a 200K-token context dump.

Conclusion
Abilities appear like easy “reusable prompts” on the floor, however they really signify a considerate reply to a few of the hardest issues in AI tooling: context administration, token effectivity, and the hole between uncooked functionality and area experience.
In the event you haven’t experimented with abilities but, begin small. Decide your most-repeated prompting sample, extract it right into a talent.md, and see the way it adjustments your workflow. As soon as that clicks, take the subsequent step: establish which MCP instruments don’t have to dwell in your principal agent, or which subprocesses require a whole lot of reasoning that’s used after you discover the reply, and scope them to devoted subagents as an alternative. You’ll be shocked how a lot cleaner your setup turns into when every agent solely carries what it truly wants.
Key insights from this put up
- Abilities are reusable, lazy-loaded, and auto-invoked instruction units that use progressive disclosure throughout three ranges: metadata, physique, and referenced recordsdata. This minimizes the upfront value by stopping to dump all the things into the context window (taking a look at you, MCP 👀).
- MCP is “keen” and hundreds all instrument metadata upfront no matter whether or not it’s used. Abilities are “lazy” and cargo context progressively and solely when related. The distinction issues for value, latency, and output high quality.
- MCP offers an agent capabilities (the “what”). Abilities give it experience (the “how”) and thus they’re complementary.
- Abilities, MCPs, and subagents work in concord. The talent gives experience and instruction, MCP gives the potential, the subagent gives the context boundary (retaining the primary agent’s context clear).
- The worth in AI growth has shifted from higher fashions to raised infrastructure. Abilities, subagents, and multi-agent orchestration aren’t simply developer expertise enhancements; they’re the structure that makes agentic AI economically and operationally viable at scale.
Ultimate perception: The immediate engineering hamster wheel is elective. It’s time to step off.
Discovered this convenient? Comply with me on LinkedIn, TDS, or Medium to see my subsequent explorations!
All pictures proven on this article have been created on my own, the writer.



{kind=link}