is Nikolay Nikitin, PhD. I’m the Analysis Lead on the AI Institute of ITMO College and an open-source fanatic. I typically see lots of my colleagues failing to seek out the time and vitality to create open repositories for his or her analysis papers and to make sure they’re of correct high quality. On this article, I’ll focus on how we might help clear up this drawback utilizing OSA, an AI instrument developed by our crew that helps the repository turn into a greater model of itself. Should you’re sustaining or contributing to open supply, this submit will prevent effort and time: you’ll learn the way OSA can robotically enhance your repo by including a correct README, producing documentation, organising CI/CD scripts, and even summarizing the important thing strengths and weaknesses of the challenge.
There are numerous totally different documentation enchancment instruments. Nevertheless, they deal with totally different particular person elements of repository documentation. For instance, the Readme-AI instrument generates the README file, nevertheless it doesn’t account for extra context, which is necessary, for instance, for repositories of scientific articles. One other instrument, RepoAgent, generates full documentation for the repository code, however not README or CI/CD scripts. In distinction, OSA considers the repository holistically, aiming to make it simpler to know and able to run. The instrument was initially made for our colleagues in analysis, together with biologists and chemists, who typically lack expertise in software program engineering and trendy growth practices. The primary goal was to assist them make the repository extra readable and reproducible in a couple of clicks. However OSA can be utilized on any repository, not solely scientific ones.
Why is it wanted?
Scientific open supply faces challenges with the reuse of analysis outcomes. Even when code is shared with scientific papers, it’s not often obtainable or full. This code is often tough to learn; there isn’t a documentation for it, and generally even a fundamental README is lacking, because the developer supposed to write down it on the final second however didn’t have time. Libraries and frameworks typically lack fundamental CI/CD settings comparable to linters, automated checks, and different high quality checks. Subsequently, it’s unattainable to breed the algorithm described within the article. And this can be a massive drawback, as a result of if somebody publishes their analysis, they do it with a want to share it with the neighborhood
However this drawback isn’t restricted to science solely. Skilled builders additionally typically postpone writing readme and documentation for lengthy durations. And if a challenge has dozens of repositories, sustaining and utilizing them may be difficult.
Ideally, every repository ought to be simple to run and user-friendly. And infrequently the posted developments typically lack important components comparable to a transparent README file or correct docstrings, which may be compiled into full documentation utilizing customary instruments like mkdocs.
Primarily based on our expertise and evaluation of the issue, we tried to counsel an answer and implement it because the Open Supply Advisor instrument – OSA.
What’s the OSA instrument?
OSA is an open-source Python library that leverages LLM brokers to enhance open-source repositories and make them simpler to reuse.
The instrument is a package deal that runs through a command-line interface (CLI). It can be deployed regionally utilizing Docker. By specifying an API key in your most well-liked LLM, you’ll be able to work together with the instrument through the console. You may also strive OSA through the general public internet GUI. There may be brief introduction to foremost concepts of repository enchancment with OSA:
How does OSA work?
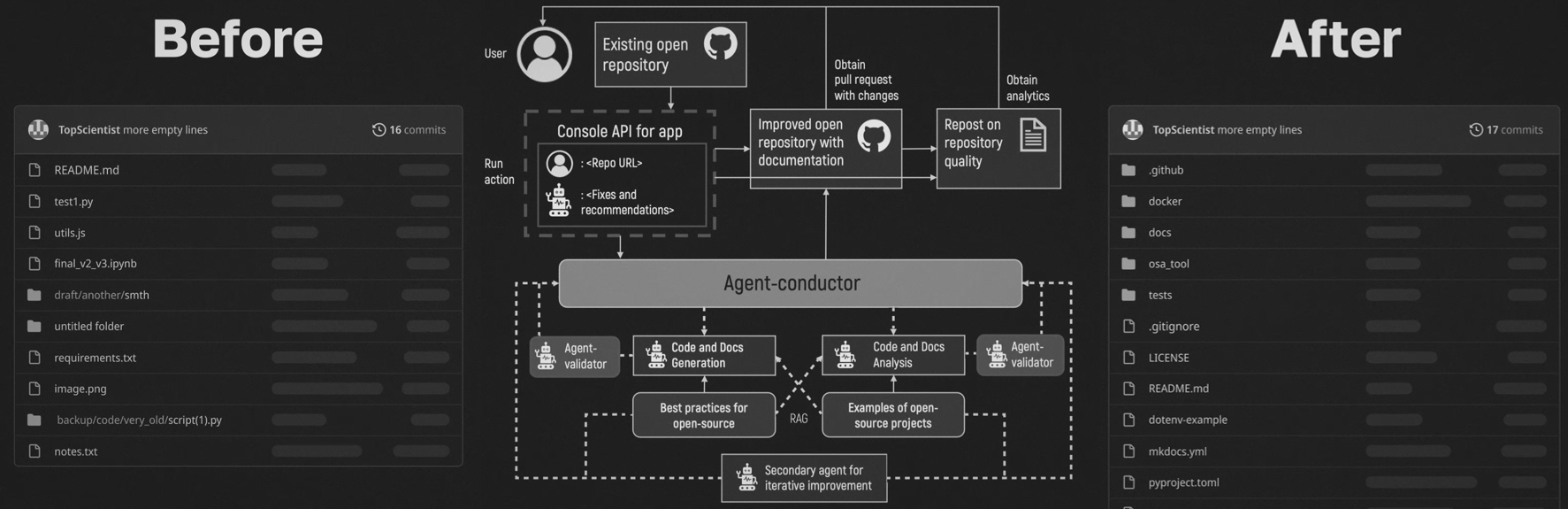
The Open Supply Advisor (OSA) is a multi-agent instrument that helps enhance the construction and value of scientific repositories in an automatic approach. It addresses widespread points in analysis initiatives by dealing with duties comparable to producing documentation (README information, code docstrings), creating important information (licenses and necessities), and suggesting sensible enhancements to the repository. Customers merely present a repository hyperlink and may both obtain an robotically generated Pull Request (PR) with all advisable adjustments or evaluate the strategies regionally earlier than making use of them.
OSA can be utilized in two methods: by cloning the repository and working it via a command-line interface (CLI), or through an online interface. It additionally provides three working modes: fundamental, automated, and superior, that are chosen at runtime to suit totally different wants. In fundamental mode, OSA applies a small set of ordinary enhancements with no further enter: it generates a report, README, neighborhood documentation, and an About part, and provides widespread folders like “checks” and “examples” in the event that they’re lacking. Superior mode offers customers full handbook management over each step. In automated mode, OSA makes use of an LLM to investigate the repository construction and the prevailing README, then proposes an inventory of enhancements for customers to approve or reject. An experimental multi-agent conversational mode can also be being developed, permitting customers to specify desired enhancements in free-form pure language through the CLI. OSA interprets this request and applies the corresponding adjustments. This mode is presently underneath energetic growth.
One other key energy of OSA is its flexibility with language fashions. It really works with widespread suppliers like OpenRouter and OpenAI, in addition to native fashions comparable to Ollama and self-hosted LLMs working through FastAPI.
OSA additionally helps a number of repository platforms, together with GitHub and GitLab (each GitLab.com and self-hosted situations). It may possibly regulate CI/CD configuration information, arrange documentation deployment workflows, and accurately configure paths for neighborhood documentation.
an experimental multi-agent system (MAS), presently underneath energetic growth, that serves as the idea for its automated and conversational modes. The system decomposes repository enchancment right into a sequence of reasoning and execution phases, every dealt with by a specialised agent. Brokers talk through a shared state and are coordinated via a directed state graph, enabling conditional transitions and iterative workflows.

README era
OSA features a README era instrument that robotically creates clear and helpful README information in two codecs: a typical README and an article-style README. The instrument decides which format to make use of by itself, for instance, if the person supplies a path or URL to a scientific paper via the CLI, OSA switches to the article format. To begin, it scans the repository to seek out an important information, specializing in core logic and challenge descriptions, and takes under consideration the folder construction and any present README.
For the usual README, OSA analyzes the important thing challenge information, repository construction, metadata, and the primary sections of an present README if one is current. It then generates a “Core Options” part that serves as the inspiration for the remainder of the doc. Utilizing this info, OSA writes a transparent challenge overview and provides a “Getting Began” part when instance scripts or demo information can be found, serving to customers shortly perceive the way to use the challenge.
In article mode, the instrument creates a abstract of the related scientific paper and extracts related info from the primary code information. These items are mixed into an Overview that explains the challenge objectives, a Content material part that describes the primary elements and the way they work collectively, and an Algorithms part that explains how the carried out strategies match into the analysis. This strategy retains the documentation scientifically correct whereas making it simpler to learn and perceive.
Documentation era
The documentation era instrument produces concise, context-aware documentation for capabilities, strategies, lessons, and code modules. The documentation era course of is as follows:
(1) Reference parsing: Initially, a TreeSitter-driven parser fetches imported modules and resolves paths to them for every explicit supply code file, forming an import map that may additional be used to find out technique and performance requires the overseas modules utility. By implementing such an strategy, it’s comparatively simple to rectify interconnections between totally different components of the processed challenge and to tell apart between inner aliases. Together with the import maps, the parser additionally preserves normal info such because the processing file, an inventory of occurring lessons, and standalone capabilities. Every class accommodates its identify, attributes record, decorators, docstring, record of its strategies, and every technique has its particular particulars that are of the identical construction as standalone capabilities, that’s: technique identify, docstring, return kind, supply code and alias resolved overseas technique calls with a reputation of the imported module, class, technique, and path to it.
(2) Preliminary docstrings era for capabilities, strategies, and lessons: With a parser having a construction shaped, an preliminary docstrings era stage is ongoing. Solely docstrings that lack lessons, strategies, and capabilities are processed at this stage. Here’s a normal description of what the ‘what’ technique does. The context is usually the strategy’s supply code, since at this level, forming a normal description of the performance is essential. The onward immediate contains details about the strategy’s arguments and interior designers, and it trails with the supply code of the known as overseas strategies to offer further context for processing technique utility. A neat second right here is that class docstrings are generated solely in spite of everything their docstring-lacking strategies are generated; then class attributes, their strategies’ names, and docstrings are supplied to the mannequin.
(3) Era of “the primary thought” of the challenge utilizing descriptions of elements derived from the earlier stage.
(4) Docstrings replace utilizing generated “foremost thought”: Therefore, all docstrings for the challenge are presumably current, era of the primary thought of the challenge may be carried out. Basically, the immediate for the thought consists of docstrings for all lessons and capabilities, together with their significance rating primarily based on the speed of prevalence of every part within the import maps talked about earlier than, and their place within the challenge hierarchy decided by supply path. The mannequin response is returned in markdown format, summarizing the challenge’s elements. As soon as the primary thought is acquired, the second stage of docstring era begins, throughout which all the challenge’s supply code elements are processed. At this second, the important thing focus is on offering the mannequin with an authentic or generated docstring on the preliminary stage docstring with the primary thought to elaborate on ‘why’ this part is required for the challenge. The supply code for the strategies can also be being supplied, since an expanded challenge narrative might immediate the mannequin to appropriate some factors within the authentic docstring.
(5) Hierarchical modules description era ranging from the underside to the highest.
(6) Utilizing Mkdocs and GitHub pages for automated documentation pushing and streaming: Ultimate stage of the docstring pipeline, contemplating a recursive traversal throughout the challenge’s modules and submodules. Hierarchy is predicated on the supply path; at every leaf-processing degree, a beforehand parsed construction is used to create an outline of which submodule is used, in accordance with the primary thought. As processing strikes to greater ranges of the hierarchy, generated submodules’ summaries are additionally used to offer further context. The mannequin returns summaries in Markdown to make sure seamless integration with the mkdocs documentation era pipeline. The whole schema of the strategy is described within the picture under.

CI/CD and construction group
OSA provides an automatic CI/CD setup that works throughout totally different repository internet hosting platforms. It generates configurable workflows that make it simpler to run checks, test code high quality, and deploy initiatives. The instrument helps widespread utilities comparable to Black for code formatting, unit_test for working checks, PEP8 and autopep8 for fashion checks, fix_pep8 for automated fashion fixes, pypi_publish for publishing packages, and slash_command_dispatch for dealing with instructions. Relying on the platform, these workflows are positioned within the acceptable places, for instance, .github/workflows/ for GitHub or a .gitlab-ci.yml file within the repository root for GitLab.
Customers can customise the generated workflows utilizing choices like –use-poetry to allow Poetry for dependency administration, –branches to outline which branches set off the workflows (by default, foremost and grasp), and code protection settings through --codecov-token and --include-codecov.
To make sure dependable testing, OSA additionally reorganizes the repository construction. It identifies take a look at and instance information and strikes them into standardized checks and examples directories, permitting CI workflows to run checks persistently with out further configuration.
Workflow information are created from templates that mix project-specific info with user-defined settings. This strategy retains workflows constant throughout initiatives whereas nonetheless permitting flexibility when wanted.
OSA additionally automates documentation deployment utilizing MkDocs. For GitHub repositories, it generates a YAML workflow within the .github/workflows listing and requires enabling learn/write permissions and choosing the gh-pages department for deployment within the repository settings. For GitLab, OSA creates or updates the .gitlab-ci.yml file to incorporate construct and deployment jobs utilizing Docker pictures, scripts, and artifact retention guidelines. Documentation is then robotically revealed when adjustments are merged into the primary department.
The best way to use OSA
To start utilizing OSA, select your repository with draft code that’s incomplete or underdocumented. Optionally, embrace a associated scientific paper or one other doc describing the library or algorithm carried out within the chosen repo. The paper is uploaded as a separate file and used to generate the README. You may also specify the LLM supplier (e.g., OpenAI) and the mannequin identify (comparable to GPT-4o).
OSA generates suggestions for enhancing the repository, together with:
- A README file generated from code evaluation, utilizing customary templates and examples
- Docstrings for lessons and strategies which can be presently lacking, to allow automated documentation era with MkDocs
- Fundamental CI/CD scripts, together with linters and automatic checks
- A report with actionable suggestions for enhancing the repository
- Contribution pointers and information (Code of Conduct, pull request and subject templates, and so forth.)
You may simply set up OSA by working:
pip set up osa_toolAfter organising the atmosphere, you must select an LLM supplier (comparable to OpenAI or an area mannequin). Subsequent, you must add GIT_TOKEN (GitHub token with customary repo permissions) and OPENAI_API_KEY (for those who use OpenAI-compatible API) as atmosphere variables, or you’ll be able to retailer them within the .env file as nicely. Lastly, you’ll be able to launch OSA immediately from the command line. OSA is designed to work with an present open-source repository by offering its URL. The fundamental launch command contains the repository handle and elective parameters such because the operation mode, API endpoint, and mannequin identify:
osa_tool -r {repository} [--mode {mode}] [--api {api}] [--base-url {base_url}] [--model {model_name}]OSA helps three working modes:
- auto (default) – analyzes the repository and creates a personalized enchancment plan utilizing the specialised LLM agent.
- fundamental – applies a predefined set of enhancements: generates a challenge report, README, neighborhood pointers, an “About” part, and creates customary directories for checks and examples (if they’re lacking).
- superior – permits handbook choice and configuration of actions earlier than execution.
Further CLI choices can be found right here. You may customise OSA by passing these choices as arguments to the CLI, or by choosing desired options within the interactive command-line mode.

As soon as launched, OSA performs an preliminary evaluation of the repository and shows key info: normal challenge particulars, the present atmosphere configuration, and tables with deliberate and inactive actions. The person is then prompted to both settle for the prompt plan, cancel the operation, or enter an interactive enhancing mode.
In interactive mode, the plan may be modified: actions toggled on or off, parameters (strings and lists) adjusted, and extra choices configured. The system guides the person via every motion’s description, potential values, and present settings. This course of continues till the person confirms the ultimate plan.
This CLI-based workflow ensures flexibility, from totally automated processing to express handbook management, making it appropriate for each fast preliminary assessments and detailed challenge refinements.
OSA additionally contains an experimental conversational interplay mode that enables customers to specify desired repository enhancements utilizing free-form pure language through the CLI. If the request is ambiguous or insufficiently associated to repository processing, the system iteratively requests clarifications and permits the connected supplementary file to be up to date. As soon as a sound instruction is obtained, OSA analyzes the repository, selects the suitable inner modules, and executes the corresponding actions. This mode is presently underneath energetic growth.
When OSA finishes, it creates a pull request (PR) within the repository. The PR contains all proposed adjustments, such because the README, docstrings, documentation web page, CI/CD scripts, сontribution pointers, report, and extra. The person can simply evaluate the PR, make adjustments if wanted, and merge it into the challenge’s foremost department.
Let’s take a look at an instance. GAN-MFS is a repository that gives a PyTorch implementation of Wasserstein GAN with Gradient Penalty (WGAN-GP). Right here is an instance of a command to launch OSA on this repo:
osa_tool -r github.com/Roman223/GAN_MFS --mode auto --api openai --base-url https://api.openai.com/v1 --model gpt-4.1-miniOSA made a number of contributions to the repository, together with a README file generated from the paper’s content material.


OSA additionally added a License file to the pull request, in addition to some fundamental CI/CD scripts.

OSA added docstrings to all lessons and strategies the place documentation was lacking. It additionally generated a structured, web-based documentation web site utilizing these docstrings.

The generated report contains an audit of the repository’s key elements: README, license, documentation, utilization examples, checks, and a challenge abstract. It additionally analyzes key sections of the repository, comparable to construction, README, and documentation. Primarily based on this evaluation, the system identifies key areas for enchancment and supplies focused advice.

Lastly, OSA interacts with the goal repository through GitHub. The OSA bot creates a fork of the repository and opens a pull request that features all proposed adjustments. The developer solely must evaluate the strategies and regulate something that appears incorrect. In my view, that is a lot simpler than writing the identical README from scratch. After evaluate, the repository maintainer efficiently merged the pull request. All adjustments proposed by OSA can be found right here.

Though the variety of adjustments launched by the OSA is critical, it’s tough to evaluate the general enchancment in repository high quality. To do that, we determined to look at the repository from a safety perspective. The scorecard instrument permits us to guage the repository utilizing the aggregated metric. Scorecard was created to assist open supply maintainers enhance their safety greatest practices and to assist open supply shoppers choose whether or not their dependencies are secure. The combination rating takes under consideration many repository parameters, together with the presence of binary artifacts, CI/CD checks, the variety of contributors, and a license. The aggregated rating of the unique repository was 2.2/10. After the processing by OSA, it rose to three.7/10. This occurred because of the addition of a license and CI/CD scripts. This rating should appear too low, however the repository being processed isn’t supposed for integration into massive initiatives. It’s a small instrument for producing artificial information primarily based on a scientific article, so its safety necessities are decrease.
What’s Subsequent for OSA?
We plan to combine a RAG system into OSA, primarily based on greatest practices in open-source growth. OSA will examine the goal repository with reference examples to establish lacking elements. For instance, if the repository already has a high-quality README, it gained’t be regenerated. Initially, we used OSA for Python repositories, however we plan to help further programming languages sooner or later.
If in case you have an open repository that requires enchancment, give OSA a strive! We might additionally respect concepts for brand new options you can depart as points and PRs.
Should you want to use OSA in your works, it may be cited as:
Nikitin N. et al. An LLM-Powered Software for Enhancing Scientific Open-Supply Repositories // Championing Open-source DEvelopment in ML Workshop@ ICML25.



{kind=link}