
Constructing cohesive and unified buyer intelligence throughout your group begins with lowering the friction your gross sales representatives face when toggling between Salesforce, assist tickets, and Amazon Redshift. A gross sales consultant making ready for a buyer assembly may spend hours clicking by means of a number of completely different dashboards—product suggestions, engagement metrics, income analytics, and so on. – earlier than creating a whole image of the client’s scenario. At AWS, our gross sales group skilled this firsthand as we scaled globally. We would have liked a technique to unify siloed buyer information throughout metrics databases, doc repositories, and exterior trade sources – with out constructing advanced customized orchestration infrastructure.
We constructed the Buyer Agent & Information Engine (CAKE), a buyer centric chat agent utilizing Amazon Bedrock AgentCore to unravel this problem. CAKE coordinates specialised retriever instruments – querying information graphs in Amazon Neptune, metrics in Amazon DynamoDB, paperwork in Amazon OpenSearch Service, and exterior market information utilizing an online search API, together with safety enforcement utilizing Row Degree Safety software (RLS), delivering buyer insights by means of pure language queries in beneath 10 seconds (as noticed in agent load exams).
On this publish, we reveal methods to construct unified intelligence techniques utilizing Amazon Bedrock AgentCore by means of our real-world implementation of CAKE. You possibly can construct customized brokers that unlock the next options and advantages:
- Coordination of specialised instruments by means of dynamic intent evaluation and parallel execution
- Integration of purpose-built information shops (Neptune, DynamoDB, OpenSearch Service) with parallel orchestration
- Implementation of row-level safety and governance inside workflows
- Manufacturing engineering practices for reliability, together with template-based reporting to stick to enterprise semantic and magnificence
- Efficiency optimization by means of mannequin flexibility
These architectural patterns might help you speed up growth for various use instances, together with buyer intelligence techniques, enterprise AI assistants, or multi-agent techniques that coordinate throughout completely different information sources.
Why buyer intelligence techniques want unification
As gross sales organizations scale globally, they typically face three important challenges: fragmented information throughout specialised instruments (product suggestions, engagement dashboards, income analytics, and so on.) requiring hours to assemble complete buyer views, lack of enterprise semantics in conventional databases that may’t seize semantic relationships explaining why metrics matter, and guide consolidation processes that may’t scale with rising information volumes. You want a unified system that may mixture buyer information, perceive semantic relationships, and motive by means of buyer wants in enterprise context, making CAKE the important linchpin for enterprises all over the place.
Answer overview
CAKE is a customer-centric chat agent that transforms fragmented information into unified, actionable intelligence. By consolidating inner and exterior information sources/tables right into a single conversational endpoint, CAKE delivers customized buyer insights powered by context-rich information graphs—all in beneath 10 seconds. In contrast to conventional instruments that merely report numbers, the semantic basis of CAKE captures the which means and relationships between enterprise metrics, buyer behaviors, trade dynamics, and strategic contexts. This permits CAKE to elucidate not simply what is occurring with a buyer, however why it’s occurring and methods to act.
Amazon Bedrock AgentCore offers the runtime infrastructure that multi-agent AI techniques require as a managed service, together with inter-agent communication, parallel execution, dialog state monitoring, and power routing. This helps groups deal with defining agent behaviors and enterprise logic slightly than implementing distributed techniques infrastructure.
For CAKE, we constructed a customized agent on Amazon Bedrock AgentCore that coordinates 5 specialised instruments, every optimized for various information entry patterns:
- Neptune retriever software for graph relationship queries
- DynamoDB agent for fast metric lookups
- OpenSearch retriever software for semantic doc search
- Internet search software for exterior trade intelligence
- Row stage safety (RLS) software for safety enforcement
The next diagram reveals how Amazon Bedrock AgentCore helps the orchestration of those elements.
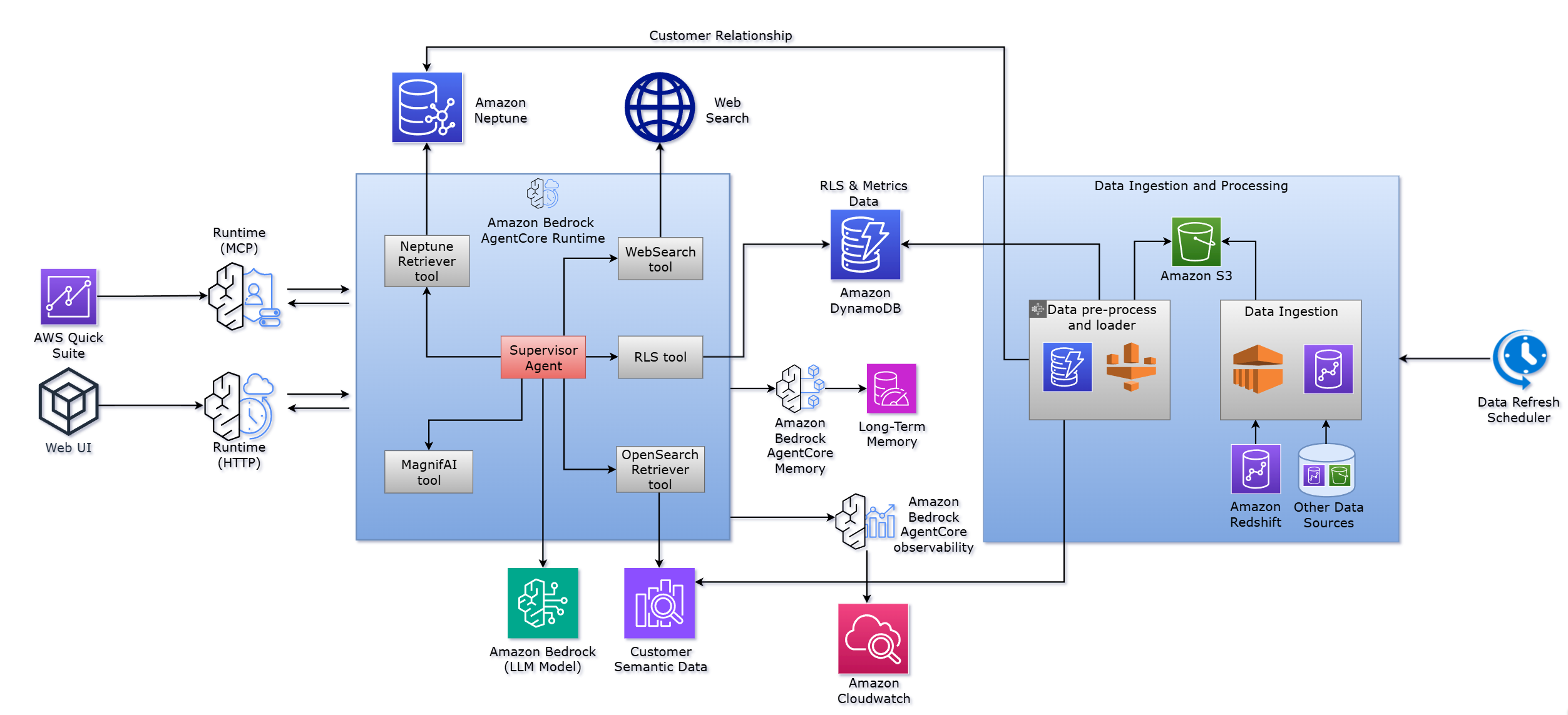
The answer flows by means of a number of key phases in response to a query (for instance, “What are the highest growth alternatives for this buyer?”):
- Analyzes intent and routes the question – The supervisor agent, operating on Amazon Bedrock AgentCore, analyzes the pure language question to find out its intent. The query requires buyer understanding, relationship information, utilization metrics, and strategic insights. The agent’s tool-calling logic, utilizing Amazon Bedrock AgentCore Runtime, identifies which specialised instruments to activate.
- Dispatches instruments in parallel – Quite than executing software calls sequentially, the orchestration layer dispatches a number of retriever instruments in parallel, utilizing the scalable execution surroundings of Amazon Bedrock AgentCore Runtime. The agent manages the execution lifecycle, dealing with timeouts, retries, and error situations mechanically.
- Synthesizes a number of outcomes – As specialised instruments return outcomes, Amazon Bedrock AgentCore streams these partial responses to the supervisor agent, which synthesizes them right into a coherent reply. The agent causes about how completely different information sources relate to one another, identifies patterns, and generates insights that span a number of information domains.
- Enforces safety boundaries – Earlier than information retrieval begins, the agent invokes the RLS software to deterministically implement consumer permissions. The customized agent then verifies that subsequent software calls respect these safety boundaries, mechanically filtering outcomes and serving to stop unauthorized information entry. This safety layer operates on the infrastructure stage, lowering the danger of implementation errors.
This structure operates on two parallel tracks: Amazon Bedrock AgentCore offers the runtime for the real-time serving layer that responds to consumer queries with minimal latency, and an offline information pipeline periodically refreshes the underlying information shops from the analytical information warehouse. Within the following sections, we talk about the agent framework design and core resolution elements, together with the information graph, information shops, and information pipeline.
Agent framework design
Our multi-agent system leverages the AWS Strands Brokers framework to ship structured reasoning capabilities whereas sustaining the enterprise controls required for regulatory compliance and predictable efficiency. The multi-agent system is constructed on the AWS Strands Brokers framework, which offers a model-driven basis for constructing brokers from many various fashions. The supervisor agent analyzes incoming inquiries to intelligently choose which specialised brokers and instruments to invoke and methods to decompose consumer queries. The framework exposes agent states and outputs to implement decentralized analysis at each agent and supervisor ranges. Constructing on model-driven strategy, we implement agentic reasoning by means of GraphRAG reasoning chains that assemble deterministic inference paths by traversing information relationships. Our brokers carry out autonomous reasoning inside their specialised domains, grounded round pre-defined ontologies whereas sustaining predictable, auditable habits patterns required for enterprise functions.
The supervisor agent employs a multi-phase choice protocol:
- Query evaluation – Parse and perceive consumer intent
- Supply choice – Clever routing determines which mixture of instruments are wanted
- Question decomposition – Unique questions are damaged down into specialised sub-questions optimized for every chosen software
- Parallel execution – Chosen instruments execute concurrently by means of serverless AWS Lambda motion teams
Instruments are uncovered by means of a hierarchical composition sample (accounting for information modality—structured vs. unstructured) the place high-level brokers and instruments coordinate a number of specialised sub-tools:
- Graph reasoning software – Manages entity traversal, relationship evaluation, and information extraction
- Buyer insights agent – Coordinates a number of fine-tuned fashions in parallel for producing buyer summaries from tables
- Semantic search software – Orchestrates unstructured textual content evaluation (resembling area notes)
- Internet analysis software – Coordinates internet/information retrieval
We prolong the core AWS Strands Brokers framework with enterprise-grade capabilities together with buyer entry validation, token optimization, multi-hop LLM choice for mannequin throttling resilience, and structured GraphRAG reasoning chains. These extensions ship the autonomous decision-making capabilities of recent agentic techniques whereas facilitating predictable efficiency and regulatory compliance alignment.
Constructing the information graph basis
CAKE’s information graph in Neptune represents buyer relationships, product utilization patterns, and trade dynamics in a structured format that empowers AI brokers to carry out environment friendly reasoning. In contrast to conventional databases that retailer data in isolation, CAKE’s information graph captures the semantic which means of enterprise entities and their relationships.
Graph building and entity modeling
We designed the information graph round AWS gross sales ontology—the core entities and relationships that gross sales groups talk about every day:
- Buyer entities – With properties extracted from information sources together with trade classifications, income metrics, cloud adoption part, and engagement scores
- Product entities – Representing AWS companies, with connections to make use of instances, trade functions, and buyer adoption patterns
- Answer entities – Linking merchandise to enterprise outcomes and strategic initiatives
- Alternative entities – Monitoring gross sales pipeline, deal levels, and related stakeholders
- Contact entities – Mapping relationship networks inside buyer organizations
Amazon Neptune excels at answering questions that require understanding connections—discovering how two entities are associated, figuring out paths between accounts, or discovering oblique relationships that span a number of hops. The offline information building course of runs scheduled queries towards Redshift clusters to organize information to be loaded within the graph.
Capturing relationship context
CAKE’s information graph captures how relationships join entities. When the graph connects a buyer to a product by means of an elevated utilization relationship, it additionally shops contextual attributes: the speed of improve, the enterprise driver (from account plans), and associated product adoption patterns. This contextual richness helps the LLM perceive enterprise context and supply explanations grounded in precise relationships slightly than statistical correlation alone.
Function-built information shops
Quite than storing information in a single database, CAKE makes use of specialised information shops, every designed for the way it will get queried. Our customized agent, operating on Amazon Bedrock AgentCore, manages the coordination throughout these shops—sending queries to the appropriate database, operating them on the similar time, and mixing outcomes—so each customers and builders work with what looks like a single information supply:
- Neptune for graph relationships – Neptune shops the net of connections between prospects, accounts, stakeholders, and organizational entities. Neptune excels at multi-hop traversal queries that require costly joins in relational databases—discovering relationship paths between disconnected accounts, or discovering prospects in an trade who’ve adopted particular AWS companies. When Amazon Bedrock AgentCore identifies a question requiring relationship reasoning, it mechanically routes to the Neptune retriever software.
- DynamoDB for fast metrics – DynamoDB operates as a key-value retailer for precomputed aggregations. Quite than computing buyer well being scores or engagement metrics on-demand, the offline pipeline pre-computes these values and shops them listed by buyer ID. DynamoDB then delivers sub-10ms lookups, enabling immediate report era. Instrument chaining in Amazon Bedrock AgentCore permits it to retrieve metrics from DynamoDB, move them to the magnifAI agent (our customized table-to-text agent) for formatting, and return polished studies—all with out customized integration code.
- OpenSearch Service for semantic doc search – OpenSearch Service shops unstructured content material like account plans and area notes. Utilizing embedding fashions, OpenSearch Service converts textual content into vector representations that assist semantic matching. When Amazon Bedrock AgentCore receives a question about “digital transformation,” for instance, it acknowledges the necessity for semantic search and mechanically routes to the OpenSearch Service retriever software, which finds related passages even when paperwork use completely different terminology.
- S3 for doc storage – Amazon Easy Storage Service (Amazon S3) offers the muse for OpenSearch Service. Account plans are saved as Parquet recordsdata in Amazon S3 earlier than being listed as a result of the supply warehouse (Amazon Redshift) has truncation limits that will lower off massive paperwork. This multi-step course of—Amazon S3 storage, embedding era, OpenSearch Service indexing—preserves full content material whereas sustaining the low latency required for real-time queries.
Constructing on Amazon Bedrock AgentCore makes these multi-database queries really feel like a single, unified information supply. When a question requires buyer relationships from Neptune, metrics from DynamoDB, and doc context from OpenSearch Service, our agent mechanically dispatches requests to all three in parallel, manages their execution, and synthesizes their outcomes right into a single coherent response.
Knowledge pipeline and steady refresh
The CAKE offline information pipeline operates as a batch course of that runs on a scheduled cadence to maintain the serving layer synchronized with the newest enterprise information. The pipeline structure separates information building from information serving, so the real-time question layer can preserve low latency whereas the batch pipeline handles computationally intensive aggregations and graph building.
The Knowledge Processing Orchestration layer coordinates transformations throughout a number of goal databases. For every database, the pipeline performs the next steps:
- Extracts related information from Amazon Redshift utilizing optimized queries
- Applies enterprise logic transformations particular to every information retailer’s necessities
- Hundreds processed information into the goal database with acceptable indexes and partitioning
For Neptune, this entails extracting entity information, developing graph nodes and edges with property attributes, and loading the graph construction with semantic relationship sorts. For DynamoDB, the pipeline computes aggregations and metrics, buildings information as key-value pairs optimized for buyer ID lookups, and applies atomic updates to take care of consistency. For OpenSearch Service, the pipeline follows a specialised path: massive paperwork are first exported from Amazon Redshift to Amazon S3 as Parquet recordsdata, then processed by means of embedding fashions to generate vector representations, that are lastly loaded into the OpenSearch Service index with acceptable metadata for filtering and retrieval.
Engineering for manufacturing: Reliability and accuracy
When transitioning CAKE from prototype to manufacturing, we carried out a number of important engineering practices to facilitate reliability, accuracy, and belief in AI-generated insights.
Mannequin flexibility
The Amazon Bedrock AgentCore structure decouples the orchestration layer from the underlying LLM, permitting versatile mannequin choice. We carried out mannequin hopping to offer computerized fallback to various fashions when throttling happens. This resilience occurs transparently inside AgentCore’s Runtime—detecting throttling situations, routing requests to out there fashions, and sustaining response high quality with out user-visible degradation.
Row-Degree Safety (RLS) and Knowledge Governance
Earlier than information retrieval happens, the RLS software enforces row-level safety based mostly on consumer identification and organizational hierarchy. This safety layer operates transparently to customers whereas sustaining strict information governance:
- Gross sales representatives entry solely prospects assigned to their territories
- Regional managers view aggregated information throughout their areas
- Executives have broader visibility aligned with their duties
The RLS software routes queries to acceptable information partitions and applies filters on the database question stage, so safety could be enforced within the information layer slightly than counting on application-level filtering.
Outcomes and influence
CAKE has remodeled how AWS gross sales groups entry and act on buyer intelligence. By offering immediate entry to unified insights by means of pure language queries, CAKE reduces the time spent trying to find data from hours to seconds as per surveys/suggestions from customers, serving to gross sales representatives deal with strategic buyer engagement slightly than information gathering.
The multi-agent structure delivers question responses in seconds for many queries, with the parallel execution mannequin supporting simultaneous information retrieval from a number of sources. The information graph allows subtle reasoning that goes past easy information aggregation—CAKE explains why tendencies happen, identifies patterns throughout seemingly unrelated information factors, and generates suggestions grounded in enterprise relationships. Maybe most significantly, CAKE democratizes entry to buyer intelligence throughout the group. Gross sales representatives, account managers, options architects, and executives work together with the identical unified system, offering constant buyer insights whereas sustaining acceptable safety and entry controls.
Conclusion
On this publish, we confirmed how Amazon Bedrock AgentCore helps CAKE’s multi-agent structure. Constructing multi-agent AI techniques historically requires vital infrastructure funding, together with implementing customized agent coordination protocols, managing parallel execution frameworks, monitoring dialog state, dealing with failure modes, and constructing safety enforcement layers. Amazon Bedrock AgentCore reduces this undifferentiated heavy lifting by offering these capabilities as managed companies inside Amazon Bedrock.
Amazon Bedrock AgentCore offers the runtime infrastructure for orchestration, and specialised information shops excel at their particular entry patterns. Neptune handles relationship traversal, DynamoDB offers immediate metric lookups, and OpenSearch Service helps semantic doc search, however our customized agent, constructed on Amazon Bedrock AgentCore, coordinates these elements, mechanically routing queries to the appropriate instruments, executing them in parallel, synthesizing their outcomes, and sustaining safety boundaries all through the workflow. The CAKE expertise demonstrates how Amazon Bedrock AgentCore might help groups construct multi-agent AI techniques, dashing up the method from months of infrastructure growth to weeks of enterprise logic implementation. By offering orchestration infrastructure as a managed service, Amazon Bedrock AgentCore helps groups deal with area experience and buyer worth slightly than constructing distributed techniques infrastructure from scratch.
To be taught extra about Amazon Bedrock AgentCore and constructing multi-agent AI techniques, discuss with the Amazon Bedrock Person Information, Amazon Bedrock Workshop, and Amazon Bedrock Brokers. For the newest information on AWS, see What’s New with AWS.
Acknowledgments
We prolong our honest gratitude to our govt sponsors and mentors whose imaginative and prescient and steerage made this initiative potential: Aizaz Manzar, Director of AWS International Gross sales; Ali Imam, Head of Startup Phase; and Akhand Singh, Head of Knowledge Engineering.
We additionally thank the devoted staff members whose technical experience and contributions have been instrumental in bringing this product to life: Aswin Palliyali Venugopalan, Software program Dev Supervisor; Alok Singh, Senior Software program Growth Engineer; Muruga Manoj Gnanakrishnan, Principal Knowledge Engineer; Sai Meka, Machine Studying Engineer; Invoice Tran, Knowledge Engineer; and Rui Li, Utilized Scientist.
In regards to the authors
 Monica Jain is a Senior Technical Product Supervisor at AWS International Gross sales and an analytics skilled driving AI-powered gross sales intelligence at scale. She leads the event of generative AI and ML-powered information merchandise—together with information graphs, AI-augmented analytics, pure language question techniques, and suggestion engines, that enhance vendor productiveness and decision-making. Her work allows AWS executives and sellers worldwide to entry real-time insights and speed up data-driven buyer engagement and income progress.
Monica Jain is a Senior Technical Product Supervisor at AWS International Gross sales and an analytics skilled driving AI-powered gross sales intelligence at scale. She leads the event of generative AI and ML-powered information merchandise—together with information graphs, AI-augmented analytics, pure language question techniques, and suggestion engines, that enhance vendor productiveness and decision-making. Her work allows AWS executives and sellers worldwide to entry real-time insights and speed up data-driven buyer engagement and income progress.
 M. Umar Javed is a Senior Utilized Scientist at AWS, with over 8 years of expertise throughout academia and trade and a PhD in ML principle. At AWS, he builds production-grade generative AI and machine studying options, with work spanning multi-agent LLM architectures, analysis on small language fashions, information graphs, suggestion techniques, reinforcement studying, and multi-modal deep studying. Previous to AWS, Umar contributed to ML analysis at NREL, CISCO, Oxford, and UCSD. He’s a recipient of the ECEE Excellence Award (2021) and contributed to 2 Donald P. Eckman Awards (2021, 2023).
M. Umar Javed is a Senior Utilized Scientist at AWS, with over 8 years of expertise throughout academia and trade and a PhD in ML principle. At AWS, he builds production-grade generative AI and machine studying options, with work spanning multi-agent LLM architectures, analysis on small language fashions, information graphs, suggestion techniques, reinforcement studying, and multi-modal deep studying. Previous to AWS, Umar contributed to ML analysis at NREL, CISCO, Oxford, and UCSD. He’s a recipient of the ECEE Excellence Award (2021) and contributed to 2 Donald P. Eckman Awards (2021, 2023).
 Damien Forthomme is a Senior Utilized Scientist at AWS, main a Knowledge Science staff in AWS Gross sales, Advertising, and International Providers (SMGS). With greater than 10 years of expertise and a PhD in Physics, he focuses on utilizing and constructing superior machine studying and generative AI instruments to floor the appropriate information to the appropriate folks on the proper time. His work encompasses initiatives resembling forecasting, suggestion techniques, core foundational datasets creation, and constructing generative AI merchandise that improve gross sales productiveness for the group.
Damien Forthomme is a Senior Utilized Scientist at AWS, main a Knowledge Science staff in AWS Gross sales, Advertising, and International Providers (SMGS). With greater than 10 years of expertise and a PhD in Physics, he focuses on utilizing and constructing superior machine studying and generative AI instruments to floor the appropriate information to the appropriate folks on the proper time. His work encompasses initiatives resembling forecasting, suggestion techniques, core foundational datasets creation, and constructing generative AI merchandise that improve gross sales productiveness for the group.
 Mihir Gadgil is a Senior Knowledge Engineer in AWS Gross sales, Advertising, and International Providers (SMGS), specializing in enterprise-scale information options and generative AI functions. With over 9 years of expertise and a Grasp’s in Data Expertise & Administration, he focuses on constructing strong information pipelines, advanced information modeling, and ETL/ELT processes. His experience drives enterprise transformation by means of revolutionary information engineering options and superior analytics capabilities.
Mihir Gadgil is a Senior Knowledge Engineer in AWS Gross sales, Advertising, and International Providers (SMGS), specializing in enterprise-scale information options and generative AI functions. With over 9 years of expertise and a Grasp’s in Data Expertise & Administration, he focuses on constructing strong information pipelines, advanced information modeling, and ETL/ELT processes. His experience drives enterprise transformation by means of revolutionary information engineering options and superior analytics capabilities.
 Sujit Narapareddy, Head of Knowledge & Analytics at AWS International Gross sales, is a expertise chief driving world enterprise transformation. He leads information product and platform groups that energy the AWS’s Go-to-Market by means of AI-augmented analytics and clever automation. With a confirmed observe report in enterprise options, he has remodeled gross sales productiveness, information governance, and operational excellence. Beforehand at JPMorgan Chase Enterprise Banking, he formed next-generation FinTech capabilities by means of information innovation.
Sujit Narapareddy, Head of Knowledge & Analytics at AWS International Gross sales, is a expertise chief driving world enterprise transformation. He leads information product and platform groups that energy the AWS’s Go-to-Market by means of AI-augmented analytics and clever automation. With a confirmed observe report in enterprise options, he has remodeled gross sales productiveness, information governance, and operational excellence. Beforehand at JPMorgan Chase Enterprise Banking, he formed next-generation FinTech capabilities by means of information innovation.
 Norman Braddock, Senior Supervisor of AI Product Administration at AWS, is a product chief driving the transformation of enterprise intelligence by means of agentic AI. He leads the Analytics & Insights Product Administration staff inside Gross sales, Advertising, and International Providers (SMGS), delivering merchandise that bridge AI mannequin efficiency with measurable enterprise influence. With a background spanning procurement, manufacturing, and gross sales operations, he combines deep operational experience with product innovation to form the way forward for autonomous enterprise administration.
Norman Braddock, Senior Supervisor of AI Product Administration at AWS, is a product chief driving the transformation of enterprise intelligence by means of agentic AI. He leads the Analytics & Insights Product Administration staff inside Gross sales, Advertising, and International Providers (SMGS), delivering merchandise that bridge AI mannequin efficiency with measurable enterprise influence. With a background spanning procurement, manufacturing, and gross sales operations, he combines deep operational experience with product innovation to form the way forward for autonomous enterprise administration.



{kind=link}