
Voice AI brokers are reshaping how we work together with know-how. From customer support and healthcare help to house automation and private productiveness, these clever digital assistants are quickly gaining reputation throughout industries. Their pure language capabilities, fixed availability, and growing sophistication make them beneficial instruments for companies searching for effectivity and people needing seamless digital experiences.
Amazon Nova Sonic delivers real-time, human-like voice conversations by the bidirectional streaming interface. It understands completely different talking kinds and generates expressive responses that adapt to each the phrases spoken and the best way they’re spoken. The mannequin helps a number of languages and presents each masculine and female voices, making it preferrred for buyer help, advertising calls, voice assistants, and academic purposes.
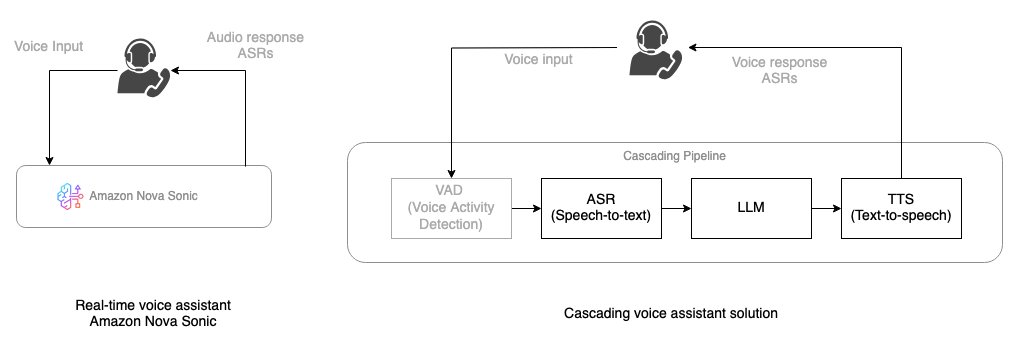
In comparison with newer architectures comparable to Amazon Nova Sonic—which mixes speech understanding and technology right into a single end-to-end mannequin—traditional AI voice chat techniques use cascading architectures with sequential processing. These techniques course of a consumer’s speech by a definite pipeline: The cascaded fashions strategy breaks down voice AI processing into separate elements:
- Voice exercise detection (VAD): A pre-processing VAD is required to detect when the consumer pauses or stops talking.
- Speech-to-text (STT): The consumer’s spoken phrases are transformed right into a written textual content format by an automated speech recognition (ASR) mannequin.
- Giant language mannequin (LLM) processing: The transcribed textual content is then fed to a LLM or dialogue supervisor, which analyzes the enter and generates a related textual response primarily based on the dialog’s context.
- Textual content-to-speech (TTS): The AI’s text-based reply is then transformed again into natural-sounding spoken audio by a TTS mannequin, which is then performed to the consumer.
The next diagram illustrates the conceptual stream of how customers work together with Nova Sonic for real-time voice conversations in comparison with a cascading voice assistant answer.
The core challenges of cascading structure
Whereas a cascading structure presents advantages comparable to modular design, specialised elements, and debuggability, cumulative latency and decreased interactivity are its drawbacks.
The cascade impact
Think about a voice assistant dealing with a easy climate question. In cascading pipelines, every processing step introduces latency and potential errors. Buyer implementations confirmed how preliminary misinterpretations can compound by the pipeline, usually leading to irrelevant responses. This cascading impact sophisticated troubleshooting and negatively impacted total consumer expertise.
Time is all the things
Actual conversations require pure timing. Sequential processing can create noticeable delays in response occasions. These interruptions in conversational stream can result in consumer friction.
The combination problem
Voice AI calls for extra than simply speech processing—it requires pure interplay patterns. Buyer suggestions highlighted how orchestrating a number of elements made it troublesome to deal with dynamic dialog components like interruptions or fast exchanges. Engineering sources usually targeted extra on pipeline administration.
Useful resource actuality
Cascading architectures require unbiased computing sources, monitoring, and upkeep for every element. This architectural complexity impacts each growth velocity and operational effectivity. Scaling challenges intensify as dialog volumes enhance, affecting system reliability and price optimization.
Affect on voice assistant growth
These insights drove key architectural selections in Nova Sonic growth, addressing the basic want for unified speech-to-speech processing that allows pure, responsive voice experiences with out the complexity of multi-component administration.
Evaluating the 2 approaches
To check the speech-to-speech and cascaded strategy to constructing voice AI brokers, take into account the next:
| Consideration | Speech-to-speech (Nova Sonic) | Cascaded fashions |
| Latency |
Optimized latency efficiency and TTFA We consider the latency efficiency of Nova Sonic mannequin utilizing the Time to First Audio (TTFA 1.09) metric. TTFA measures the elapsed time from the completion of a consumer’s spoken question till the primary byte of response audio is acquired. See technical report and mannequin card. |
Potential added latency and errors Cascaded fashions can use a number of fashions throughout speech recognition, language understanding, and voice technology, however are challenged by added latency and potential error propagation between phases. By utilizing fashionable asynchronous orchestration frameworks like Pipecat and LiveKit, you possibly can decrease latency. Streaming elements and utilizing text-to-speech fillers assist preserve pure conversational stream and cut back delays |
| Structure and growth complexity |
Simplified structure Nova Sonic combines speech-to-text, pure language understanding, and text-to-speech within the one mannequin with built-in instrument use and barge-in detection, offering an event-driven structure for key enter and output occasions, and a bidirectional streaming API for a simplified developer expertise. |
Potential complexity in structure Builders want to pick out best-in-class fashions for every stage of the pipeline, whereas orchestrating further elements comparable to asynchronous pipelines for delegated brokers and power use, TTS fillers and (VAD). |
| Mannequin choice and customization |
Much less management over particular person elements Amazon Nova Sonic permits customization of voices, built-in instrument use and integrations to Amazon Bedrock Information Bases and Amazon Bedrock AgentCore. Nevertheless, it presents much less granular management over particular person mannequin elements in comparison with totally modular cascaded techniques. |
Potential granular management over every step Cascaded fashions present extra management over every step by permitting particular person tuning, alternative, and optimization of every mannequin elements comparable to STT, language understanding, and TTS independently. This consists of fashions from Amazon Bedrock Market, Amazon SageMaker AI and fantastic–tuned fashions. This modularity permits choice and adaptability of fashions, making it preferrred for advanced or specialised capabilities requiring tailor-made efficiency. |
| Value construction |
Simplified value construction by an built-in strategy Amazon Nova Sonic is priced on a token-based consumption mannequin. |
Potential complexity in prices related to a number of elements Cascaded fashions encompass a number of elements whose prices should be estimated. That is particularly necessary at scale and excessive volumes. |
| Language and accent help | Languages supported by Nova Sonic | Potential broader language help by specialised fashions together with the flexibility to modify languages mid-conversation |
| Area availability | Areas supported by Nova Sonic | Potential broader area help due to the broad collection of fashions and skill to self-host fashions on Amazon Elastic Kubernetes Service (Amazon EKS) or Amazon SageMaker. |
The 2 approaches even have some shared traits.
| Telephony and transport choices | Each cascaded and speech-to-speech approaches help quite a lot of telephony and transport protocols comparable to WebRTC and WebSocket, enabling real-time, low-latency audio streaming over the online and cellphone networks. These protocols facilitate seamless, bidirectional audio alternate essential for pure conversational experiences, permitting voice AI techniques to combine simply with present communication infrastructures whereas sustaining responsiveness and audio high quality. |
| Evaluations, observability, and testing | Each cascaded and speech-to-speech voice AI approaches could be systematically evaluated, noticed, and examined for dependable comparability. Investing in a voice AI analysis and observability system is really useful to realize confidence in manufacturing accuracy and efficiency. Such a system must be able to tracing your entire input-to-output pipeline, capturing metrics and dialog information end-to-end to comprehensively assess high quality, latency, and conversational robustness over time. |
| Developer frameworks | Each cascaded and speech-to-speech approaches are effectively supported by main open-source voice AI frameworks like Pipecat and LiveKit. These frameworks present modular, versatile pipelines and real-time processing capabilities that builders can use to construct, customise, and orchestrate voice AI fashions effectively throughout completely different elements and interplay kinds. |
When to make use of every strategy
The next diagram reveals a sensible framework to information your structure resolution:
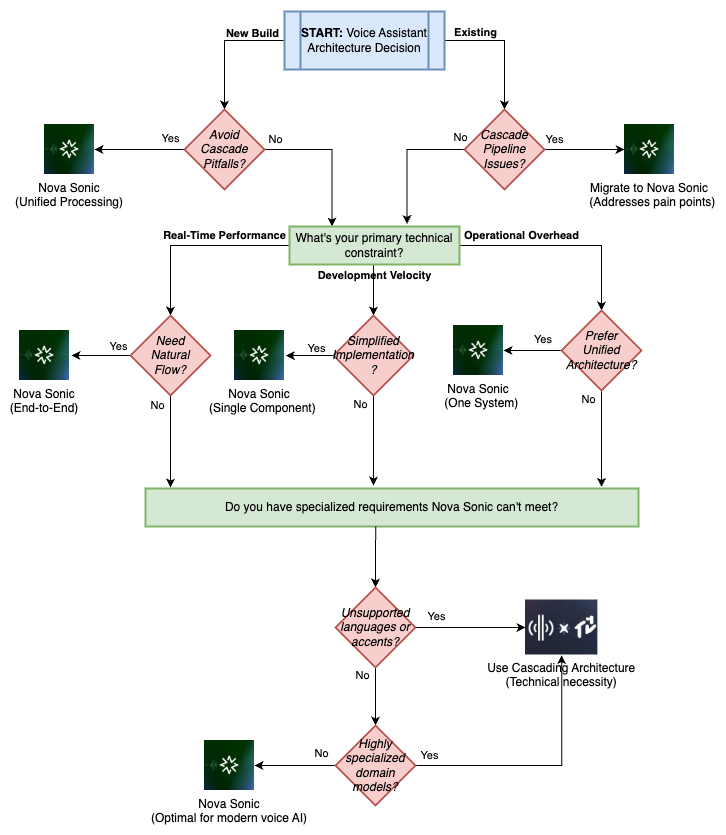
Use speech-to-speech when:
- Simplicity of implementation is necessary
- The use case matches inside Nova Sonic’s capabilities
- You’re on the lookout for a real-time chat expertise that feels human-like and delivers low latency
Use cascaded fashions when:
- Customization of particular person elements is required
- You could use specialised fashions from the Amazon Bedrock Market, Amazon SageMaker AI, or fine-tuned fashions to your particular area
- You want help for languages or accents not lined by Nova Sonic
- The use case requires specialised processing at particular phases
Conclusion
On this publish, you realized how Amazon Nova Sonic is designed to unravel a few of the challenges confronted by cascaded approaches, simplify constructing voice AI brokers, and supply pure conversational capabilities. We additionally supplied steering on when to decide on every strategy that will help you make knowledgeable selections to your voice AI tasks. When you’re trying to improve your cascaded voice system, you recognize have the fundamentals of find out how to migrate to Nova Sonic so you possibly can provide seamless, real-time conversational experiences with a simplified structure.
To study extra, see Amazon Nova Sonic and make contact with your account crew to discover how one can speed up your voice AI initiatives.
Sources
In regards to the authors
 Daniel Wirjo is a Options Architect at AWS, targeted on AI and SaaS startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive development and innovation on AWS. Outdoors of labor, Daniel enjoys taking walks with a espresso in hand, appreciating nature, and studying new concepts.
Daniel Wirjo is a Options Architect at AWS, targeted on AI and SaaS startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive development and innovation on AWS. Outdoors of labor, Daniel enjoys taking walks with a espresso in hand, appreciating nature, and studying new concepts.
 Ravi Thakur is a Sr Options Architect at AWS primarily based in Charlotte, NC. He has cross‑business expertise throughout retail, monetary companies, healthcare, and vitality & utilities, and makes a speciality of fixing advanced enterprise challenges utilizing effectively‑architected cloud patterns. His experience spans microservices, cloud‑native architectures, and generative AI. Outdoors of labor, Ravi enjoys bike rides and household getaways.
Ravi Thakur is a Sr Options Architect at AWS primarily based in Charlotte, NC. He has cross‑business expertise throughout retail, monetary companies, healthcare, and vitality & utilities, and makes a speciality of fixing advanced enterprise challenges utilizing effectively‑architected cloud patterns. His experience spans microservices, cloud‑native architectures, and generative AI. Outdoors of labor, Ravi enjoys bike rides and household getaways.
 Lana Zhang is a Senior Specialist Options Architect for Generative AI at AWS throughout the Worldwide Specialist Group. She makes a speciality of AI/ML, with a give attention to use circumstances comparable to AI voice assistants and multimodal understanding. She works carefully with clients throughout various industries, together with media and leisure, gaming, sports activities, promoting, monetary companies, and healthcare, to assist them remodel their enterprise options by AI.
Lana Zhang is a Senior Specialist Options Architect for Generative AI at AWS throughout the Worldwide Specialist Group. She makes a speciality of AI/ML, with a give attention to use circumstances comparable to AI voice assistants and multimodal understanding. She works carefully with clients throughout various industries, together with media and leisure, gaming, sports activities, promoting, monetary companies, and healthcare, to assist them remodel their enterprise options by AI.



{kind=link}