
Embedding fashions energy many fashionable functions—from semantic search and Retrieval-Augmented Technology (RAG) to suggestion programs and content material understanding. Nonetheless, deciding on an embedding mannequin requires cautious consideration—after you’ve ingested your information, migrating to a special mannequin means re-embedding your whole corpus, rebuilding vector indexes, and validating search high quality from scratch. The best embedding mannequin ought to ship sturdy baseline efficiency, adapt to your particular use-case, and help the modalities you want now and sooner or later.
The Amazon Nova Multimodal Embeddings mannequin generates embeddings tailor-made to your particular use case—from single-modality textual content or picture search to advanced multimodal functions spanning paperwork, movies, and blended content material.
On this put up, you’ll discover ways to use Amazon Nova Multimodal Embeddings to your particular use circumstances:
- Simplify your structure with cross-modal search and visible doc retrieval
- Optimize efficiency by deciding on embedding parameters matched to your workload
- Implement widespread patterns by way of answer walkthroughs for media search, ecommerce discovery, and clever doc retrieval
This information offers a sensible basis to configure Amazon Nova Multimodal Embeddings for media asset search programs, product discovery experiences, and doc retrieval functions.
Multimodal enterprise use circumstances
You should utilize Amazon Nova Multimodal Embeddings throughout a number of enterprise eventualities. The next desk offers typical use circumstances and question examples:
| Modality | Content material kind | Use circumstances | Typical question examples |
| Video retrieval | Quick video search | Asset library and media administration | “Kids opening Christmas presents,” “Blue whale breaching the ocean floor” |
| Lengthy video phase search | Movie and leisure, broadcast media, safety surveillance | “Particular scene in a film,” “Particular footage in information,” “Particular habits in surveillance” | |
| Duplicate content material identification | Media content material administration | Related or duplicate video identification | |
| Picture retrieval | Thematic picture search | Asset library, storage, and media administration | “Pink automobile with sunroof driving alongside the coast” |
| Picture reference search | E-commerce, design | “Sneakers just like this” + |
|
| Reverse picture search | Content material administration | Discover related content material based mostly on uploaded picture | |
| Doc retrieval | Particular info pages | Monetary companies, advertising markups, promoting brochures | Textual content info, information tables, chart web page |
| Cross-page complete info | Information retrieval enhancement | Complete info extraction from multi-page textual content, charts, and tables | |
| Textual content retrieval | Thematic info retrieval | Information retrieval enhancement | “Subsequent steps in reactor decommissioning procedures” |
| Textual content similarity evaluation | Media content material administration | Duplicate headline detection | |
| Computerized subject clustering | Finance, healthcare | Symptom classification and summarization | |
| Contextual affiliation retrieval | Finance, authorized, insurance coverage | “Most declare quantity for company inspection accident violations” | |
| Audio and voice retrieval | Audio retrieval | Asset library and media asset administration | “Christmas music ringtone,” “Pure tranquil sound results” |
| Lengthy audio phase search | Podcasts, assembly recordings | “Podcast host discussing neuroscience and sleep’s influence on mind well being” |
Optimize efficiency for particular use circumstances
Amazon Nova Multimodal Embeddings mannequin optimizes its efficiency for particular use circumstances with embeddingPurpose parameter settings. It has completely different vectorization methods: retrieval system mode and ML activity mode.
- Retrieval system mode (together with
GENERIC_INDEXand numerous*_RETRIEVALparameters) targets info retrieval eventualities, distinguishing between two uneven phases: storage/INDEX and question/RETRIEVAL. See the next desk for retrieval system classes and parameter choice.
| Section | Parameter choice | Cause |
| Storage section (all sorts) | GENERIC_INDEX |
Optimized for indexing and storage |
| Question section (mixed-modal repository) | GENERIC_RETRIEVAL |
Search in blended content material |
| Question section (text-only repository) | TEXT_RETRIEVAL |
Search in text-only content material |
| Question section (image-only repository) | IMAGE_RETRIEVAL |
Search in photographs (photographs, illustrations, and so forth) |
| Question section (doc image-only repository) | DOCUMENT_RETRIEVAL |
Search in doc photographs (scans, PDF screenshots, and so forth) |
| Question section (video-only repository) | VIDEO_RETRIEVAL |
Search in movies |
| Question section (audio-only repository) | AUDIO_RETRIEVAL/td> |
Search in audio |
- ML activity mode (together with
CLASSIFICATIONandCLUSTERINGparameters) targets machine studying eventualities. This parameter allows the mannequin to flexibly adapt to several types of downstream activity necessities. - CLASSIFICATION: Generated vectors are extra appropriate for distinguishing classification boundaries, facilitating downstream classifier coaching or direct classification.
- CLUSTERING: Generated vectors are extra appropriate for forming cluster facilities, facilitating downstream clustering algorithms.
Walkthrough of constructing multimodal search and retrieval answer
Amazon Nova Multimodal Embeddings is purpose-built for multimodal search and retrieval, which is the muse of multimodal agentic RAG programs. The next diagrams present the right way to construct a multimodal search and retrieval answer.
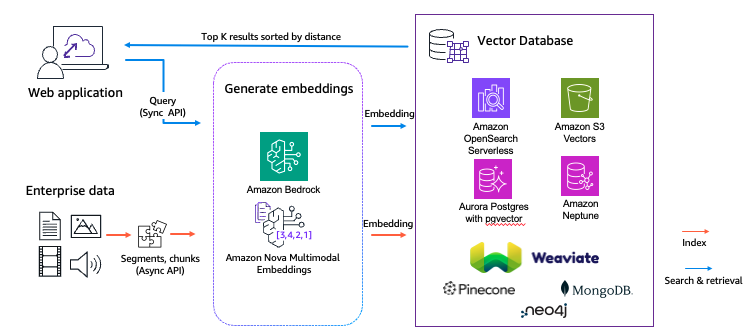
In a multimodal search and retrieval answer, proven within the previous diagram, uncooked content material—together with textual content, photographs, audio, and video—is initially reworked into vector representations by way of an embedding mannequin to encapsulate semantic options. Subsequently, these vectors are saved in a vector database. Consumer queries are equally transformed into question vectors inside the similar vector house. The retrieval of the highest Okay most related gadgets is achieved by calculating the similarity between the question vector and the listed vectors. This multimodal search and retrieval answer could be encapsulated as a Mannequin Context Protocol (MCP) software, thereby facilitating entry inside a multimodal agentic RAG answer, proven within the following diagram.
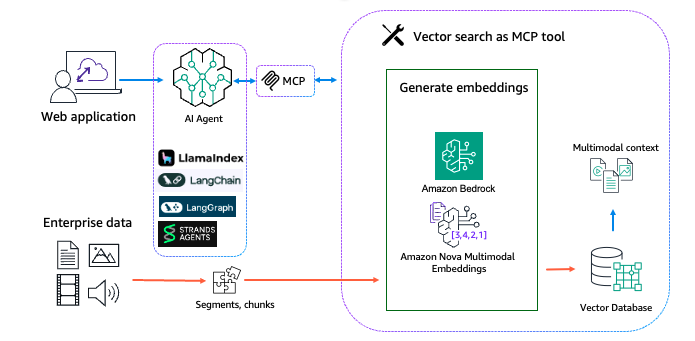
The multimodal search and retrieval answer could be divided into two distinct information flows:
- Information ingestion
- Runtime search and retrieval
The next lists the widespread modules inside every information circulation, together with the related instruments and applied sciences:
| Information circulation | Module | Description | Widespread instruments and applied sciences |
| Information ingestion | Generate embeddings | Convert inputs (textual content, photographs, audio, video, and so forth) into vector representations | Embeddings mannequin. |
| Retailer embeddings in vector shops | Retailer generated vectors in a vector database or storage construction for subsequent retrieval | Common vector databases | |
| Runtime search and retrieval | Similarity Retrieval Algorithm | Calculate similarity and distance between question vectors and listed vectors, retrieve closest gadgets | Widespread distances: cosine similarity, internal product, Euclidean distanceDatabase help for k-NN and ANN, resembling Amazon OpenSearch k-NN |
| Prime Okay Retrieval and Voting Mechanism | Choose the highest Okay nearest neighbors from retrieval outcomes, then presumably mix a number of methods (voting, reranking, fusion) | For instance, prime Okay nearest neighbors, fusion of key phrase retrieval and vector retrieval (hybrid search) | |
| Integration Technique and Hybrid Retrieval | Mix a number of retrieval mechanisms or modal outcomes, resembling key phrase and vector or, textual content and picture retrieval fusion | Hybrid search (resembling Amazon OpenSearch hybrid) |
We are going to discover a number of cross-modal enterprise use circumstances and supply a high-level overview of the right way to tackle them utilizing Amazon Nova Multimodal Embeddings.
Use case: Product retrieval and classification
E-commerce functions require the potential to routinely classify product photographs and determine related gadgets with out the necessity for guide tagging. The next diagram illustrates a high-level answer:
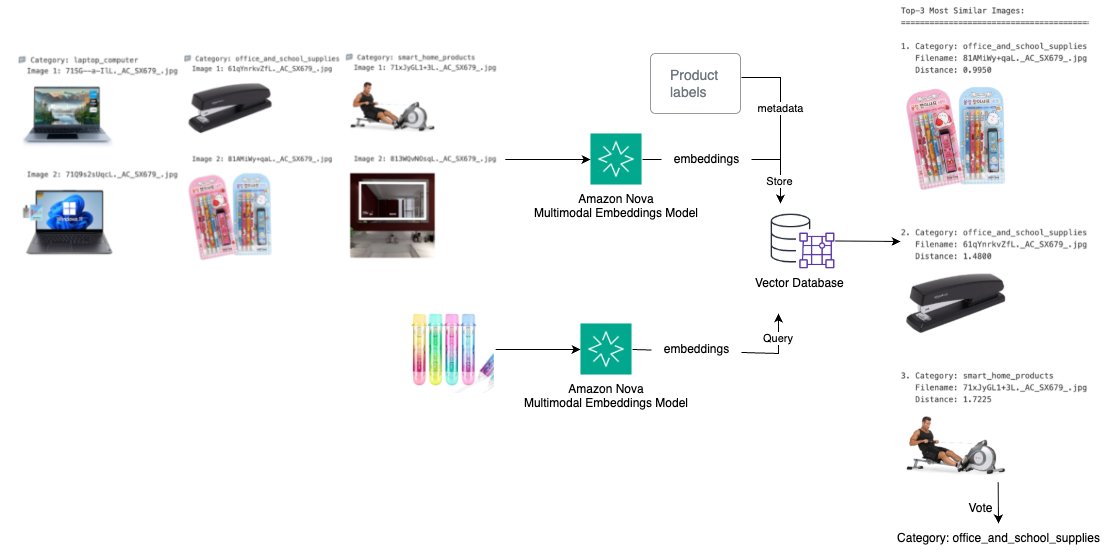
- Convert product photographs to embeddings utilizing Amazon Nova Multimodal Embeddings
- Retailer embeddings and labels as metadata in a vector database
- Question new product photographs and discover the highest Okay related merchandise
- Use a voting mechanism on retrieved outcomes to foretell class
Key embeddings parameters:
| Parameter | Worth | Goal |
embeddingPurpose |
GENERIC_INDEX (indexing) and IMAGE_RETRIEVAL (querying) |
Optimizes for product picture retrieval |
embeddingDimension |
1024 |
Balances accuracy and efficiency |
detailLevel |
STANDARD_IMAGE |
Appropriate for product photographs |
Use case: Clever doc retrieval
Monetary analysts, authorized groups, and researchers must rapidly discover particular info (tables, charts, clauses) throughout advanced multi-page paperwork with out guide evaluation. The next diagram illustrates a high-level answer:
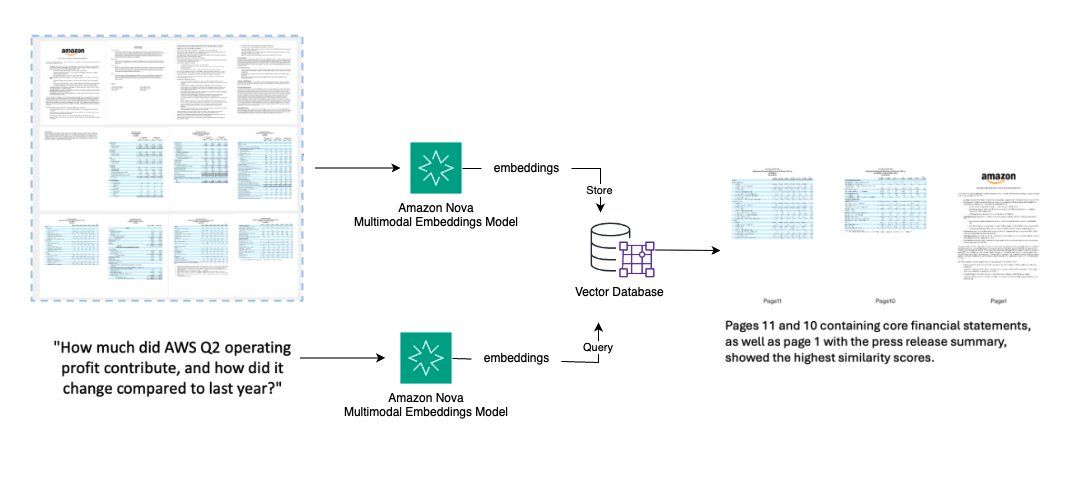
- Convert every PDF web page to a high-resolution picture
- Generate embeddings for all doc pages
- Retailer embeddings in a vector database
- Settle for pure language queries and convert to embeddings
- Retrieve the highest Okay most related pages based mostly on semantic similarity
- Return pages with monetary tables, charts, or particular content material
Key embeddings parameters:
| Parameter | Worth | Goal |
embeddingPurpose |
GENERIC_INDEX (indexing) and DOCUMENT_RETRIEVAL (querying) |
Optimizes for doc content material understanding |
embeddingDimension |
3072 |
Highest precision for advanced doc buildings |
detailLevel |
DOCUMENT_IMAGE |
Preserves tables, charts, and textual content structure |
When coping with text-based paperwork that lack visible components, it’s really helpful to extract the textual content content material and apply a chunking technique and to make use of GENERIC_INDEX for indexing and TEXT_RETRIEVAL for querying.
Use case: Video clips search
Media functions require environment friendly strategies to find particular video clips from intensive video libraries utilizing pure language descriptions. By changing movies and textual content queries into embeddings inside a unified semantic house, similarity matching can be utilized to retrieve related video segments. The next diagram illustrates a high-level answer:
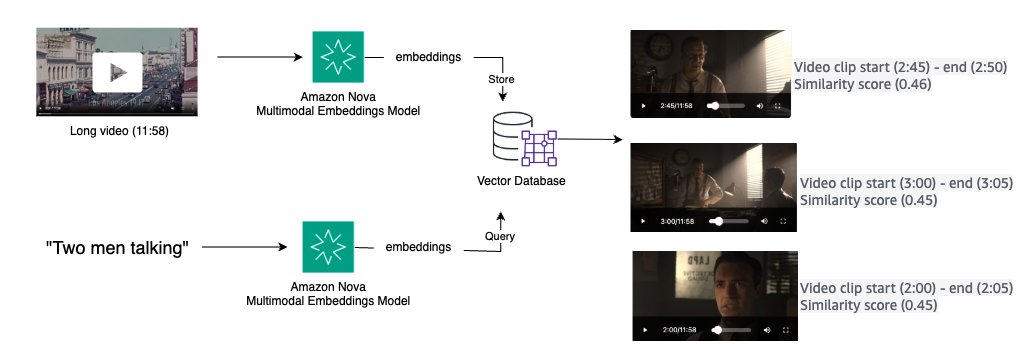
- Generate embeddings with Amazon Nova Multimodal Embeddings utilizing the
invoke_modelAPI for brief movies or thestart_async_invokeAPI for lengthy movies with segmentation - Retailer embeddings in a vector database
- Settle for pure language queries and convert to embeddings
- Retrieve the highest Okay video clips from the vector database for evaluation or additional modifying
Key embeddings parameters:
| Parameter | Worth | Goal |
EmbeddingPurpose |
GENERIC_INDEX (indexing) and VIDEO_RETRIEVAL (querying) |
Optimize for video indexing and retrieval |
embeddingDimension |
1024 |
Stability precision and price |
embeddingMode |
AUDIO_VIDEO_COMBINED |
Fuse visible and audio content material. |
Use case: Audio fingerprinting
Music functions and copyright administration programs must determine duplicate or related audio content material, and match audio segments to supply tracks for copyright detection and content material recognition. The next diagram illustrates a high-level answer:
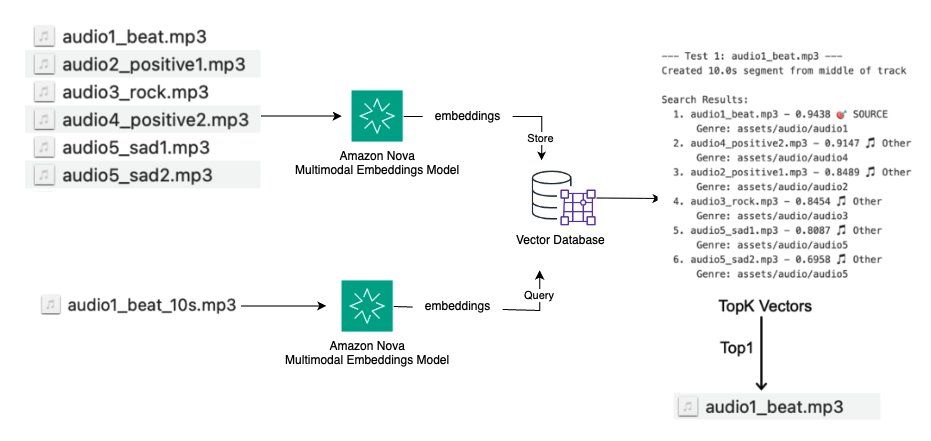
- Convert audio information to embeddings utilizing Amazon Nova Multimodal Embeddings
- Retailer embeddings in a vector database with style and different metadata
- Question with audio segments and discover the highest Okay related tracks
- Examine similarity scores to determine supply matches and detect duplicates
Key embeddings parameters:
| Parameter | Worth | Goal |
embeddingPurpose |
GENERIC_INDEX (indexing) and AUDIO_RETRIEVAL (querying) |
Optimizes for audio fingerprinting and matching |
embeddingDimension |
1024 |
Balances accuracy and efficiency for audio similarity |
Conclusion
You should utilize Amazon Nova Multimodal Embeddings to work with numerous information varieties inside a unified semantic house. By supporting textual content, photographs, paperwork, video, and audio by way of versatile purpose-optimized embedding API parameters, you’ll be able to construct simpler retrieval programs, classification pipelines, and semantic search functions. Whether or not you’re implementing cross-modal search, doc intelligence, or product classification, Amazon Nova Multimodal Embeddings offers the muse to extract insights from unstructured information at scale. Begin exploring the Amazon Nova Multimodal Embeddings: State-of-the-art embedding mannequin for agentic RAG and semantic search and GitHub samples to combine Amazon Nova Multimodal Embeddings into your functions at this time.
Concerning the authors
 Yunyi Gao is a Generative AI Specialiat Options Architect at Amazon Internet Companies (AWS), accountable for consulting on the design of AWS AI/ML and GenAI options and architectures.
Yunyi Gao is a Generative AI Specialiat Options Architect at Amazon Internet Companies (AWS), accountable for consulting on the design of AWS AI/ML and GenAI options and architectures.
 Sharon Li is an AI/ML Specialist Options Architect at Amazon Internet Companies (AWS) based mostly in Boston, Massachusetts. With a ardour for leveraging cutting-edge know-how, Sharon is on the forefront of creating and deploying revolutionary generative AI options on the AWS cloud platform.
Sharon Li is an AI/ML Specialist Options Architect at Amazon Internet Companies (AWS) based mostly in Boston, Massachusetts. With a ardour for leveraging cutting-edge know-how, Sharon is on the forefront of creating and deploying revolutionary generative AI options on the AWS cloud platform.



{kind=link}