
Clever Doc Processing (IDP) transforms how organizations deal with unstructured doc information, enabling computerized extraction of beneficial info from invoices, contracts, and experiences. At the moment, we discover the best way to programmatically create an IDP answer that makes use of Strands SDK, Amazon Bedrock AgentCore, Amazon Bedrock Data Base, and Bedrock Information Automation (BDA). This answer is supplied via a Jupyter pocket book that permits customers to add multi-modal enterprise paperwork and extract insights utilizing BDA as a parser to retrieve related chunks and increase a immediate to a foundational mannequin (FM). On this use case, our answer performs retrieval of related context for public college districts from a Nation’s Report Card from the U.S Division of Training.
Amazon Bedrock Information Automation can be utilized as a standalone function or as a parser when organising a data base for Retrieval-Augmented Technology (RAG) workflows. BDA can be utilized to generate beneficial insights from unstructured, multi-modal content material comparable to paperwork, pictures, video, and audio. With BDA, you possibly can construct automated IDP and RAG workflows, rapidly and cost-effectively. In constructing your RAG workflow, you should utilize Amazon OpenSearch Service to retailer the vector embeddings of crucial paperwork. On this submit, Bedrock AgentCore makes use of BDA through instruments to carry out multi-modal RAG for the IDP answer.
Amazon Bedrock AgentCore is a completely managed service that permits you to construct and configure autonomous brokers. Builders can construct and deploy brokers utilizing well-liked frameworks and a set of fashions together with these from Amazon Bedrock, Anthropic, Google, and OpenAI all with out managing the underlying infrastructure or writing customized code.
Strands Brokers SDK is a complicated open-source toolkit that revolutionizes synthetic intelligence (AI) agent improvement via a model-driven method. Builders can create a Strands Agent with a immediate (defining agent habits) and a listing of instruments. A big language mannequin (LLM) performs the reasoning, autonomously deciding the optimum actions and when to make use of instruments primarily based on the context and job. This workflow helps advanced techniques, minimizing the code usually wanted to orchestrate multi-agent collaboration. Strands SDK is used for creating the agent and defining the instruments wanted to carry out clever doc processing.
Observe the next stipulations and step-by-step implementations to deploy the answer in your personal AWS setting.
Conditions
To observe together with the instance use instances, arrange the next stipulations:
Structure
The answer makes use of the next AWS providers:
- Amazon S3 for doc storage and add capabilities
- Bedrock Data Bases to transform objects saved in S3 right into a RAG-ready workflow
- Amazon OpenSearch for vector embeddings
- Amazon Bedrock AgentCore for the IDP workflow
- Strands Agent SDK for the open supply framework of defining instruments to carry out IDP
- Bedrock Information Automation (BDA) to extract structured insights out of your paperwork
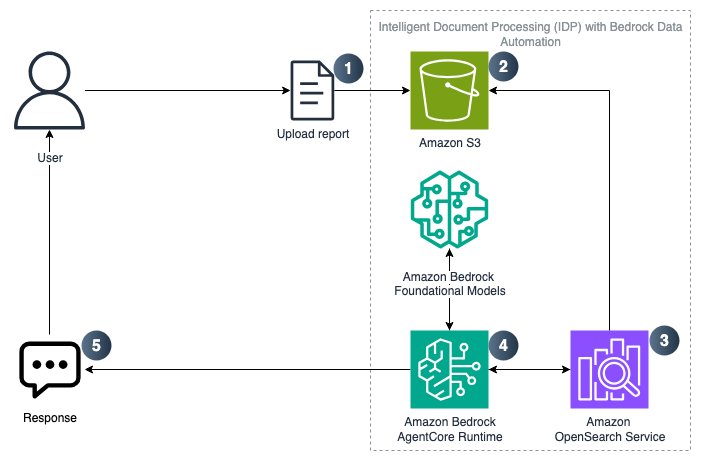
Observe these steps to get began:
- Add related paperwork to Amazon S3
- Create Amazon Bedrock Data Base and parse S3 information supply utilizing Amazon Bedrock Information Automation.
- Doc chunks saved as vector embeddings in Amazon OpenSearch
- Strands Agent deployed on Amazon Bedrock AgentCore Runtime performs RAG to reply consumer questions.
- Finish consumer receives response
Configure the AWS CLI
Use the next command to configure the AWS Command Line Interface (AWS CLI) with the AWS credentials to your Amazon account and AWS Area. Earlier than you start, test AWS Bedrock Information Automation for area availability and pricing:
Clone and construct the GitHub repository domestically
Open Jupyter pocket book known as:
Bedrock Information Automation with AgentCore Pocket book directions:
This pocket book demonstrates the best way to create an IDP answer utilizing BDA with Amazon Bedrock AgentCore Runtime. As an alternative of conventional Bedrock Brokers, we’ll deploy a Strands Agent via AgentCore, offering enterprise-grade capabilities with framework flexibility. Extra particular directions are included within the Jupyter pocket book. Right here’s an summary of how one can setup Bedrock Data Bases with information automation as a parser with Bedrock AgentCore.
Steps:
- Import libraries and setup AgentCore capabilities
- Create the Data Base for Amazon Bedrock with BDA
- Add the tutorial experiences dataset to Amazon S3
- Deploy the Strands Agent utilizing AgentCore Runtime
- Take a look at the AgentCore-hosted agent
- Clear-up all assets
Safety concerns
The implementation makes use of a number of safety guardrails like:
- Safe file add dealing with
- Id and Entry Administration (IAM) role-based entry management
- Enter validation and error dealing with
Observe: This implementation is for demonstration functions. Further safety controls, testing, and architectural evaluations are required earlier than deploying in a manufacturing setting.
Advantages and use instances
This answer is especially beneficial for:
- Automated doc processing workflows
- Clever doc evaluation on large-scale datasets
- Query-answering techniques primarily based on doc content material
- Multi-modal content material processing
Conclusion
This answer demonstrates the best way to use Amazon Bedrock AgentCore’s capabilities to construct clever doc processing functions. By constructing Strands Brokers to assist Amazon Bedrock Information Automation, we are able to create highly effective functions that perceive and work together with multi-modal doc content material utilizing instruments. With Amazon Bedrock Information Automation, we are able to improve the RAG expertise for extra advanced information codecs together with visible wealthy paperwork, pictures, audios, and video.
Further assets
For extra info, go to Amazon Bedrock.
Service Person Guides:
Related Samples:
In regards to the authors
 Raian Osman is a Technical Account Supervisor at AWS and works carefully with Training know-how clients primarily based out of North America. He has been with AWS for over 3 years and started his journey working as a Options Architect. Raian works carefully with organizations to optimize and safe workloads on AWS, whereas exploring modern use instances for generative AI.
Raian Osman is a Technical Account Supervisor at AWS and works carefully with Training know-how clients primarily based out of North America. He has been with AWS for over 3 years and started his journey working as a Options Architect. Raian works carefully with organizations to optimize and safe workloads on AWS, whereas exploring modern use instances for generative AI.
 Andy Orlosky is a Strategic Pursuit Options Architect at Amazon Internet Providers (AWS) primarily based out of Austin, Texas. He has been with AWS for about 2 years however has labored carefully with Training clients throughout public sector. As a pacesetter within the AI/ML Technical Area Neighborhood, Andy continues to dive deep along with his clients to design and scale generative AI options. He holds 7 AWS certifications and enjoys spending time along with his household, enjoying sports activities with pals, and cheering for his favourite sports activities groups in his free time.
Andy Orlosky is a Strategic Pursuit Options Architect at Amazon Internet Providers (AWS) primarily based out of Austin, Texas. He has been with AWS for about 2 years however has labored carefully with Training clients throughout public sector. As a pacesetter within the AI/ML Technical Area Neighborhood, Andy continues to dive deep along with his clients to design and scale generative AI options. He holds 7 AWS certifications and enjoys spending time along with his household, enjoying sports activities with pals, and cheering for his favourite sports activities groups in his free time.
 Spencer Harrison is a associate options architect at Amazon Internet Providers (AWS), the place he helps public sector organizations use cloud know-how to concentrate on enterprise outcomes. He’s captivated with utilizing know-how to enhance processes and workflows. Spencer’s pursuits outdoors of labor embrace studying, pickleball, and private finance.
Spencer Harrison is a associate options architect at Amazon Internet Providers (AWS), the place he helps public sector organizations use cloud know-how to concentrate on enterprise outcomes. He’s captivated with utilizing know-how to enhance processes and workflows. Spencer’s pursuits outdoors of labor embrace studying, pickleball, and private finance.


{kind=link}