On this article, you’ll be taught what knowledge leakage is, the way it silently inflates mannequin efficiency, and sensible patterns for stopping it throughout frequent workflows.
Subjects we are going to cowl embrace:
- Figuring out goal leakage and eradicating target-derived options.
- Stopping prepare–take a look at contamination by ordering preprocessing appropriately.
- Avoiding temporal leakage in time sequence with correct function design and splits.
Let’s get began.
3 Delicate Methods Information Leakage Can Smash Your Fashions (and Methods to Forestall It)
Picture by Editor
Introduction
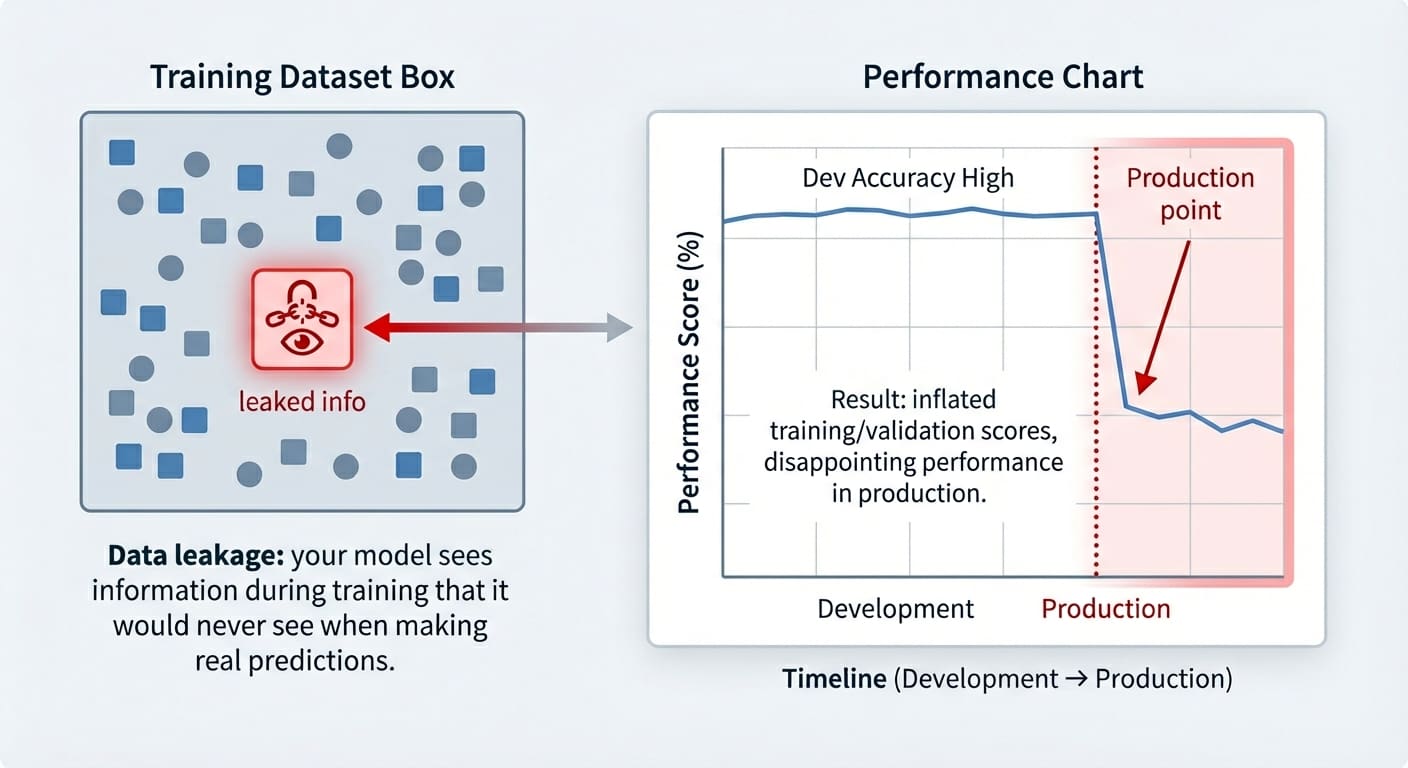
Information leakage is an usually unintentional drawback that will occur in machine studying modeling. It occurs when the information used for coaching incorporates info that “shouldn’t be recognized” at this stage — i.e. this info has leaked and develop into an “intruder” inside the coaching set. Because of this, the educated mannequin has gained a form of unfair benefit, however solely within the very brief run: it’d carry out suspiciously effectively on the coaching examples themselves (and validation ones, at most), nevertheless it later performs fairly poorly on future unseen knowledge.
This text exhibits three sensible machine studying eventualities wherein knowledge leakage could occur, highlighting the way it impacts educated fashions, and showcasing methods to forestall this challenge in every state of affairs. The info leakage eventualities coated are:
- Goal leakage
- Prepare-test cut up contamination
- Temporal leakage in time sequence knowledge
Information Leakage vs. Overfitting
Although knowledge leakage and overfitting can produce similar-looking outcomes, they’re totally different issues.
Overfitting arises when a mannequin memorizes overly particular patterns from the coaching set, however the mannequin will not be essentially receiving any illegitimate info it shouldn’t know on the coaching stage — it’s simply studying excessively from the coaching knowledge.
Information leakage, in contrast, happens when the mannequin is uncovered to info it mustn’t have throughout coaching. Furthermore, whereas overfitting usually arises as a poorly generalizing mannequin on the validation set, the results of information leakage could solely floor at a later stage, typically already in manufacturing when the mannequin receives actually unseen knowledge.

Information leakage vs. overfitting
Picture by Editor
Let’s take a more in-depth take a look at 3 particular knowledge leakage eventualities.
State of affairs 1: Goal Leakage
Goal leakage happens when options comprise info that straight or not directly reveals the goal variable. Typically this may be the results of a wrongly utilized function engineering course of wherein target-derived options have been launched within the dataset. Passing coaching knowledge containing such options to a mannequin is corresponding to a pupil dishonest on an examination: a part of the solutions they need to provide you with by themselves has been supplied to them.
The examples on this article use scikit-learn, Pandas, and NumPy.
Let’s see an instance of how this drawback could come up when coaching a dataset to foretell diabetes. To take action, we are going to deliberately incorporate a predictor function derived from the goal variable, 'goal' (after all, this challenge in apply tends to occur accidentally, however we’re injecting it on objective on this instance as an instance how the issue manifests!):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from sklearn.datasets import load_diabetes import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_cut up
X, y = load_diabetes(return_X_y=True, as_frame=True) df = X.copy() df[‘target’] = (y > y.median()).astype(int) # Binary end result
# Add leaky function: associated to the goal however with some random noise df[‘leaky_feature’] = df[‘target’] + np.random.regular(0, 0.5, measurement=len(df))
# Prepare and take a look at mannequin with leaky function X_leaky = df.drop(columns=[‘target’]) y = df[‘target’]
X_train, X_test, y_train, y_test = train_test_split(X_leaky, y, random_state=0, stratify=y) clf = LogisticRegression(max_iter=1000).match(X_train, y_train) print(“Check accuracy with leakage:”, clf.rating(X_test, y_test)) |
Now, to match accuracy outcomes on the take a look at set with out the “leaky function”, we are going to take away it and retrain the mannequin:
|
# Eradicating leaky function and repeating the method X_clean = df.drop(columns=[‘target’, ‘leaky_feature’]) X_train, X_test, y_train, y_test = train_test_split(X_clean, y, random_state=0, stratify=y) clf = LogisticRegression(max_iter=1000).match(X_train, y_train) print(“Check accuracy with out leakage:”, clf.rating(X_test, y_test)) |
You might get a end result like:
|
Check accuracy with leakage: 0.8288288288288288 Check accuracy with out leakage: 0.7477477477477478 |
Which makes us surprise: wasn’t knowledge leakage speculated to destroy our mannequin, because the article title suggests? In reality, it’s, and because of this knowledge leakage may be troublesome to identify till it is perhaps late: as talked about within the introduction, the issue usually manifests as inflated accuracy each in coaching and in validation/take a look at units, with the efficiency downfall solely noticeable as soon as the mannequin is uncovered to new, real-world knowledge. Methods to forestall it ideally embrace a mix of steps like fastidiously analyzing correlations between the goal and the remainder of the options, checking function weights in a newly educated mannequin and seeing if any function has an excessively massive weight, and so forth.
State of affairs 2: Prepare-Check Cut up Contamination
One other very frequent knowledge leakage state of affairs usually arises after we don’t put together the information in the correct order, as a result of sure, order issues in knowledge preparation and preprocessing. Particularly, scaling the information earlier than splitting it into coaching and take a look at/validation units may be the proper recipe to by chance (and really subtly) incorporate take a look at knowledge info — by the statistics used for scaling — into the coaching course of.
These fast code excerpts based mostly on the favored wine dataset present the flawed vs. proper solution to apply scaling and splitting (it’s a matter of order, as you’ll discover!):
|
import pandas as pd from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression
X, y = load_wine(return_X_y=True, as_frame=True)
# WRONG: scaling the total dataset earlier than splitting could trigger leakage scaler = StandardScaler().match(X) X_scaled = scaler.rework(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42, stratify=y)
clf = LogisticRegression(max_iter=2000).match(X_train, y_train) print(“Accuracy with leakage:”, clf.rating(X_test, y_test)) |
The best method:
|
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
scaler = StandardScaler().match(X_train) # the scaler solely “learns” from coaching knowledge… X_train_scaled = scaler.rework(X_train) X_test_scaled = scaler.rework(X_test) # … however, after all, it’s utilized to each partitions
clf = LogisticRegression(max_iter=2000).match(X_train_scaled, y_train) print(“Accuracy with out leakage:”, clf.rating(X_test_scaled, y_test)) |
Relying on the particular drawback and dataset, making use of the correct or flawed method will make little or no distinction as a result of typically the test-specific leaked info could statistically be similar to that within the coaching knowledge. Don’t take this with no consideration in all datasets and, as a matter of fine apply, at all times cut up earlier than scaling.
State of affairs 3: Temporal Leakage in Time Collection Information
The final leakage state of affairs is inherent to time sequence knowledge, and it happens when details about the long run — i.e. info to be forecasted by the mannequin — is someway leaked into the coaching set. For instance, utilizing future values to foretell previous ones in a inventory pricing state of affairs will not be the correct method to construct a forecasting mannequin.
This instance considers a synthetically generated small dataset of every day inventory costs, and we deliberately add a brand new predictor variable that leaks in details about the long run that the mannequin shouldn’t concentrate on at coaching time. Once more, we do that on objective right here as an instance the difficulty, however in real-world eventualities this isn’t too uncommon to occur because of components like inadvertent function engineering processes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression
np.random.seed(0) dates = pd.date_range(“2020-01-01”, durations=300)
# Artificial knowledge era with some patterns to introduce temporal predictability pattern = np.linspace(100, 150, 300) seasonality = 5 * np.sin(np.linspace(0, 10*np.pi, 300))
# Autocorrelated small noise: earlier day knowledge partly influences subsequent day noise = np.random.randn(300) * 0.5 for i in vary(1, 300): noise[i] += 0.7 * noise[i–1]
costs = pattern + seasonality + noise df = pd.DataFrame({“date”: dates, “worth”: costs})
# WRONG CASE: introducing leaky function (next-day worth) df[‘future_price’] = df[‘price’].shift(–1) df = df.dropna(subset=[‘future_price’])
X_leaky = df[[‘price’, ‘future_price’]] y = (df[‘future_price’] > df[‘price’]).astype(int)
X_train, X_test = X_leaky.iloc[:250], X_leaky.iloc[250:] y_train, y_test = y.iloc[:250], y.iloc[250:]
clf = LogisticRegression(max_iter=500) clf.match(X_train, y_train) print(“Accuracy with leakage:”, clf.rating(X_test, y_test)) |
If we needed to complement our time sequence dataset with new, significant options for higher prediction, the correct method is to include info describing the previous, slightly than the long run. Rolling statistics are a good way to do that, as proven on this instance, which additionally reformulates the predictive job into classification as a substitute of numerical forecasting:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# New goal: next-day course (improve vs lower) df[‘target’] = (df[‘price’].shift(–1) > df[‘price’]).astype(int)
# Added function associated to the previous: 3-day rolling imply df[‘rolling_mean’] = df[‘price’].rolling(3).imply()
df_clean = df.dropna(subset=[‘rolling_mean’, ‘target’]) X_clean = df_clean[[‘rolling_mean’]] y_clean = df_clean[‘target’]
X_train, X_test = X_clean.iloc[:250], X_clean.iloc[250:] y_train, y_test = y_clean.iloc[:250], y_clean.iloc[250:]
from sklearn.linear_model import LogisticRegression clf = LogisticRegression(max_iter=500) clf.match(X_train, y_train) print(“Accuracy with out leakage:”, clf.rating(X_test, y_test)) |
As soon as once more, you might even see inflated outcomes for the flawed case, however be warned: issues could flip the other way up as soon as in manufacturing if there was impactful knowledge leakage alongside the best way.
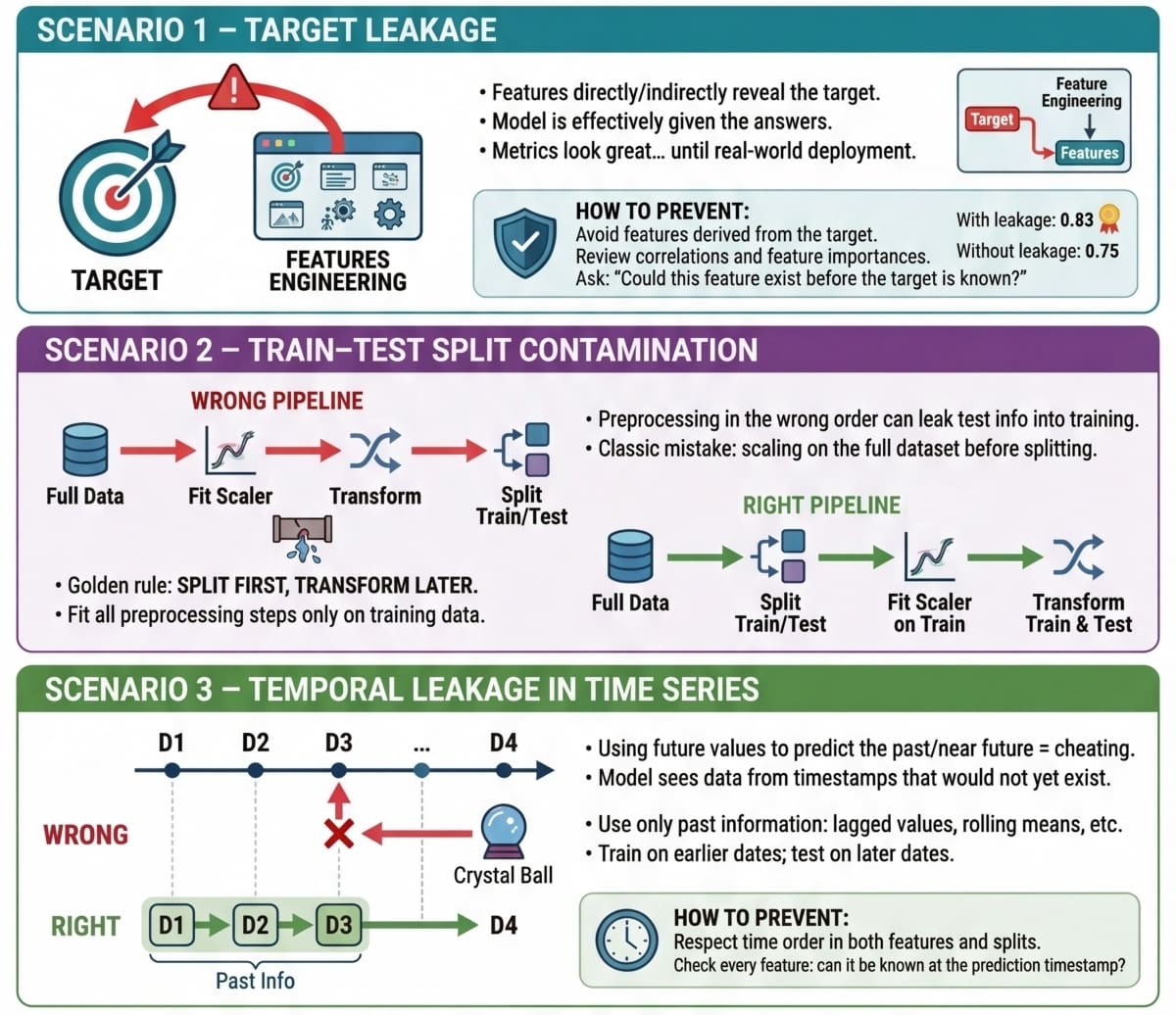
Information leakage eventualities summarized
Picture by Editor
Wrapping Up
This text confirmed, by three sensible eventualities, some types wherein knowledge leakage could manifest throughout machine studying modeling processes, outlining their impression and methods to navigate these points, which, whereas apparently innocent at first, could later wreak havoc (actually!) whereas in manufacturing.

Information leakage guidelines
Picture by Editor



{kind=link}