you’ll bump into when doing AI engineering work is that there’s no actual blueprint to observe.
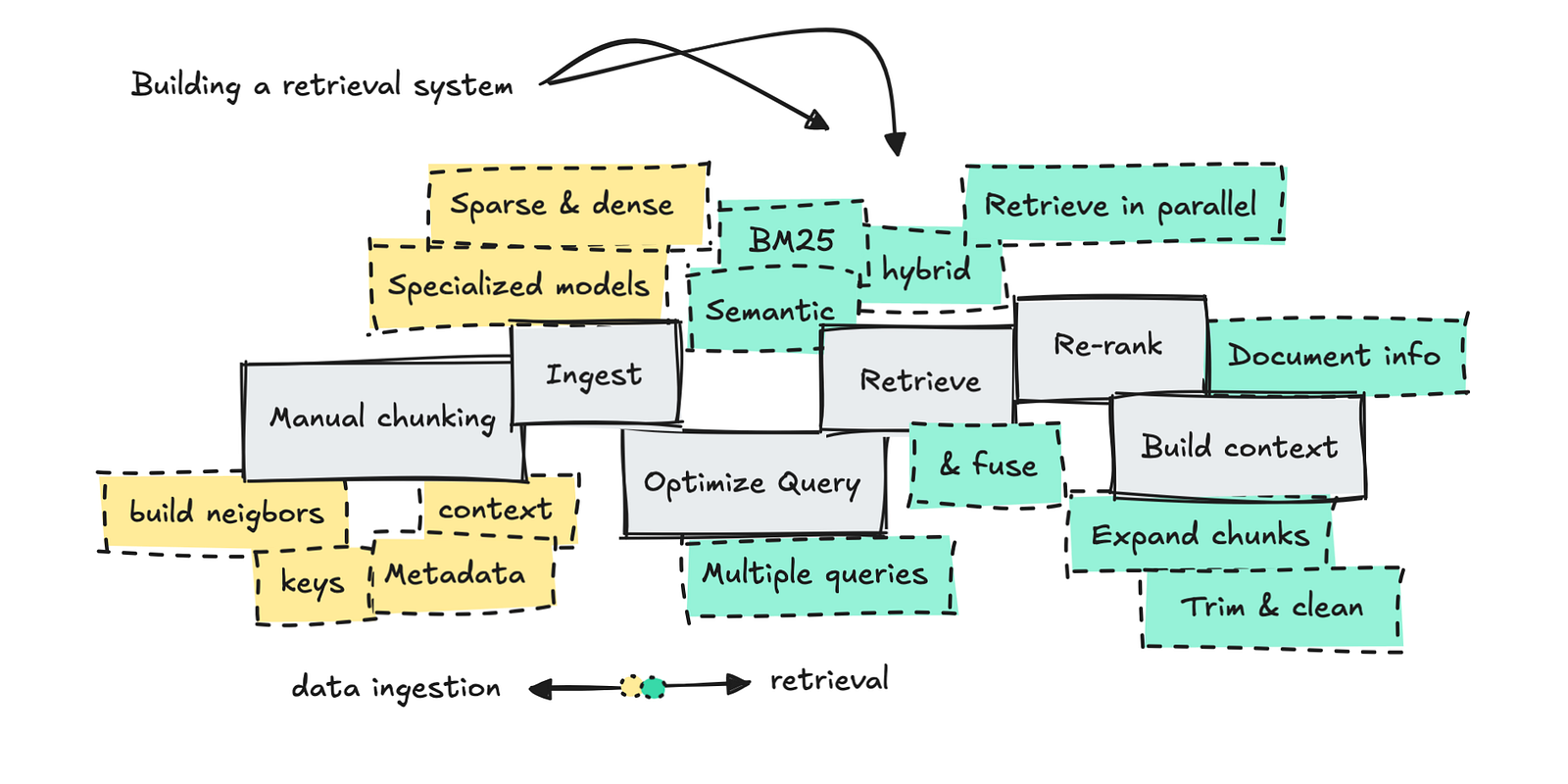
Sure, for probably the most primary elements of retrieval (the “R” in RAG), you’ll be able to chunk paperwork, use semantic search on a question, re-rank the outcomes, and so forth. This half is well-known.
However when you begin digging into this space, you start to ask questions like: how can we name a system clever if it’s solely in a position to learn a number of chunks right here and there in a doc? So, how will we make certain it has sufficient info to truly reply intelligently?
Quickly, you’ll end up taking place a rabbit gap, making an attempt to discern what others are doing in their very own orgs, as a result of none of that is correctly documented, and persons are nonetheless constructing their very own setups.
It will lead you to implement varied optimization methods: constructing customized chunkers, rewriting consumer queries, utilizing completely different search strategies, filtering with metadata, and increasing context to incorporate neighboring chunks.

Therefore why I’ve now constructed a slightly bloated retrieval system to indicate you the way it works. So, let’s stroll by it so we are able to see the outcomes of every step, but in addition to debate the trade-offs.
To demo this method in public, I made a decision to embed 150 current ArXiv papers (2,250 pages) that point out RAG. This implies the system we’re testing right here is designed for scientific papers, and all of the check queries will probably be RAG-related.
I’ve collected the uncooked outputs for every step for a number of queries on this repository, if you wish to take a look at the entire thing intimately.
For the tech stack, I’m utilizing Qdrant and Redis to retailer information, and Cohere and OpenAI for the LLMs. I don’t depend on any framework to construct the pipelines (because it makes it more durable to debug).
As all the time, I do a fast evaluate of what we’re doing for rookies, so if RAG is already acquainted to you, be happy to skip the primary part.
Recap retrieval & RAG
While you work with AI information programs like Copilot (the place you feed it your customized docs to reply from) you’re employed with a RAG system.
RAG stands for Retrieval Augmented Technology and is separated into two elements, the retrieval half and the technology half.
Retrieval refers back to the strategy of fetching info in your recordsdata, utilizing key phrase and semantic matching, based mostly on a consumer question. The technology half is the place the LLM is available in and solutions based mostly on the offered context and the consumer question.

For anybody new to RAG it could seem to be a chunky method to construct programs. Shouldn’t an LLM do many of the work by itself?
Sadly, LLMs are static, and we have to engineer programs so that every time we name on them, we give them the whole lot they want upfront to allow them to reply the query.
I’ve written about constructing RAG bots for Slack earlier than. This one makes use of commonplace chunking strategies, for those who’re eager to get a way of how folks construct one thing easy.
This text goes a step additional and tries to rebuild the whole retrieval pipeline with none frameworks, to do some fancy stuff like construct a multi-query optimizer, fuse outcomes, and develop the chunks to construct higher context for the LLM.
As we’ll see although, all of these fancy additions we’ll need to pay for in latency and extra work.
Processing completely different paperwork
As with all information engineering drawback, your first hurdle will probably be to architect easy methods to retailer information. With retrieval, we deal with one thing referred to as chunking, and the way you do it and what you retailer with it’s important to constructing a well-engineered system.
After we do retrieval, we search textual content, and to try this we have to separate the textual content into completely different chunks of data. These items of textual content are what we’ll later search to discover a match for a question.
Most straightforward programs use normal chunkers, merely splitting the total textual content by size, paragraph, or sentence.

However each doc is completely different, so by doing this you danger shedding context.
To know this, you need to take a look at completely different paperwork to see how all of them observe completely different constructions. You’ll have an HR doc with clear part headers, and API docs with unnumbered sections utilizing code blocks and tables.
When you utilized the identical chunking logic to all of those, you’d danger splitting every textual content the mistaken method. Which means that as soon as the LLM will get the chunks of data, will probably be incomplete, which can trigger it to fail at producing an correct reply.
Moreover, for every chunk of data, you additionally want to consider the info you need it to carry.
Ought to it include sure metadata so the system can apply filters? Ought to it hyperlink to related info so it will probably join information? Ought to it maintain context so the LLM understands the place the data comes from?
This implies the structure of the way you retailer information turns into a very powerful half. When you begin storing info and later understand it’s not sufficient, you’ll need to redo it. When you understand you’ve sophisticated the system, you’ll have to begin from scratch.
This technique will ingest Excel and PDFs, specializing in including context, keys, and neighbors. It will will let you see what this seems to be like when doing retrieval later.
For this demo, I’ve saved information in Redis and Qdrant. We use Qdrant to do semantic, BM25, and hybrid search, and to develop content material we fetch information from Redis.
Ingesting tabular recordsdata
First we’ll undergo how one can chunk tabular information, add context, and hold info related with keys.
When coping with already structured tabular information, like in Excel recordsdata, it would seem to be the plain strategy is to let the system search it instantly. However semantic matching is definitely fairly efficient for messy consumer queries.
SQL or direct queries solely work for those who already know the schema and actual fields. As an example, for those who get a question like “Mazda 2023 specs” from a consumer, semantically matching rows will give us one thing to go on.
I’ve talked to firms that needed their system to match paperwork throughout completely different Excel recordsdata. To do that, we are able to retailer keys together with the chunks (with out going full KG).
So as an example, if we’re working with Excel recordsdata containing buy information, we might ingest information for every row like so:
{
"chunk_id": "Sales_Q1_123::row::1",
"doc_id": "Sales_Q1_123:1234"
"location": {"sheet_name": "Gross sales Q1", "row_n": 1},
"sort": "chunk",
"textual content": "OrderID: 1001234f67 n Buyer: Alice Hemsworth n Merchandise: Blue sweater 4, Purple pants 6",
"context": "Quarterly gross sales snapshot",
"keys": {"OrderID": "1001234f67"},
}If we resolve later within the retrieval pipeline to attach info, we are able to do commonplace search utilizing the keys to seek out connecting chunks. This permits us to make fast hops between paperwork with out including one other router step to the pipeline.

We will additionally set a abstract for every doc. This acts as a gatekeeper to chunks.
{
"chunk_id": "Sales_Q1::abstract",
"doc_id": "Sales_Q1_123:1234"
"location": {"sheet_name": "Gross sales Q1"},
"sort": "abstract",
"textual content": "Sheet tracks Q1 orders for 2025, sort of product, and buyer names for reconciliation.",
"context": ""
}The gatekeeper abstract concept may be a bit sophisticated to grasp at first, however it additionally helps to have the abstract saved on the doc stage for those who want it when constructing the context later.
When the LLM units up this abstract (and a quick context string), it will probably counsel the important thing columns (i.e. order IDs and so forth).
As a observe, all the time set the important thing columns manually for those who can, if that’s not attainable, arrange some validation logic to verify the keys aren’t simply random (it will probably occur that an LLM will select bizarre columns to retailer whereas ignoring probably the most very important ones).
For this method with the ArXiv papers, I’ve ingested two Excel recordsdata that include info on title and writer stage.
The chunks will look one thing like this:
{
"chunk_id": "titles::row::8817::250930134607",
"doc_id": "titles::250930134607",
"location": {
"sheet_name": "titles",
"row_n": 8817
},
"sort": "chunk",
"textual content": "id: 2507 2114ntitle: Gender Similarities Dominate Mathematical Cognition on the Neural Degree: A Japanese fMRI Research Utilizing Superior Wavelet Evaluation and Generative AInkeywords: FMRI; Practical Magnetic Resonance Imaging; Gender Variations; Machine Studying; Mathematical Efficiency; Time Frequency Evaluation; Waveletnabstract_url: https://arxiv.org/abs/2507.21140ncreated: 2025-07-23 00:00:00 UTCnauthor_1: Tatsuru Kikuchi",
"context": "Analyzing developments in AI and computational analysis articles.",
"keys": {
"id": "2507 2114",
"author_1": "Tatsuru Kikuchi"
}
}These Excel recordsdata have been strictly not obligatory (the PDF recordsdata would have been sufficient), however they’re a method to demo how the system can lookup keys to seek out connecting info.
I created summaries for these recordsdata too.
{
"chunk_id": "titles::abstract::250930134607",
"doc_id": "titles::250930134607",
"location": {
"sheet_name": "titles"
},
"sort": "abstract",
"textual content": "The dataset consists of articles with varied attributes together with ID, title, key phrases, authors, and publication date. It accommodates a complete of 2508 rows with a wealthy number of matters predominantly round AI, machine studying, and superior computational strategies. Authors typically contribute in groups, indicated by a number of writer columns. The dataset serves tutorial and analysis functions, enabling catego",
}We additionally retailer info in Redis at doc stage, which tells us what it’s about, the place to seek out it, who’s allowed to see it, and when it was final up to date. It will permit us to replace stale info later.
Now let’s flip to PDF recordsdata, that are the worst monster you’ll take care of.
Ingesting PDF docs
To course of PDF recordsdata, we do related issues as with tabular information, however chunking them is far more durable, and we retailer neighbors as a substitute of keys.
To begin processing PDFs, we’ve a number of frameworks to work with, resembling LlamaParse and Docling, however none of them are good, so we’ve to construct out the system additional.
PDF paperwork are very onerous to course of, as most don’t observe the identical construction. Additionally they typically include figures and tables that the majority programs can’t deal with appropriately.
Nonetheless, a instrument like Docling may help us at the least parse regular tables correctly and map out every aspect to the right web page and aspect quantity.
From right here, we are able to create our personal programmatic logic by mapping sections and subsections for every aspect, and smart-merging snippets so chunks learn naturally (i.e. don’t cut up mid-sentence).
We additionally make certain to group chunks by part, protecting them collectively by linking their IDs in a subject referred to as neighbors.

This permits us to maintain the chunks small however nonetheless develop them after retrieval.
The top outcome will probably be one thing like beneath:
{
"chunk_id": "S3::C02::251009105423",
"doc_id": "2507.18910v1",
"location": {
"page_start": 2,
"page_end": 2
},
"sort": "chunk",
"textual content": "1 Introductionnn1.1 Background and MotivationnnLarge-scale pre-trained language fashions have demonstrated a capability to retailer huge quantities of factual information of their parameters, however they wrestle with accessing up-to-date info and offering verifiable sources. This limitation has motivated methods that increase generative fashions with info retrieval. Retrieval-Augmented Technology (RAG) emerged as an answer to this drawback, combining a neural retriever with a sequence-to-sequence generator to floor outputs in exterior paperwork [52]. The seminal work of [52] launched RAG for knowledge-intensive duties, displaying {that a} generative mannequin (constructed on a BART encoder-decoder) might retrieve related Wikipedia passages and incorporate them into its responses, thereby attaining state-of-the-art efficiency on open-domain query answering. RAG is constructed upon prior efforts wherein retrieval was used to boost query answering and language modeling [48, 26, 45]. In contrast to earlier extractive approaches, RAG produces free-form solutions whereas nonetheless leveraging non-parametric reminiscence, providing the most effective of each worlds: improved factual accuracy and the flexibility to quote sources. This functionality is particularly necessary to mitigate hallucinations (i.e., plausible however incorrect outputs) and to permit information updates with out retraining the mannequin [52, 33].",
"context": "Systematic evaluate of RAG's improvement and functions in NLP, addressing challenges and developments.",
"section_neighbours": {
"earlier than": [
"S3::C01::251009105423"
],
"after": [
"S3::C03::251009105423",
"S3::C04::251009105423",
"S3::C05::251009105423",
"S3::C06::251009105423",
"S3::C07::251009105423"
]
},
"keys": {}
}After we arrange information like this, we are able to contemplate these chunks as seeds. We’re trying to find the place there could also be related info based mostly on the consumer question, and increasing from there.
The distinction from easier RAG programs is that we attempt to benefit from the LLM’s rising context window to ship in additional info (however there are clearly commerce offs to this).
You’ll have the ability to see a messy resolution of what this seems to be like when constructing the context within the retrieval pipeline later.
Constructing the retrieval pipeline
Since I’ve constructed this pipeline piece by piece, it permits us to check every half and undergo why we make sure selections in how we retrieve and rework info earlier than handing it over to the LLM.
We’ll undergo semantic, hybrid, and BM25 search, constructing a multi-query optimizer, re-ranking outcomes, increasing content material to construct the context, after which handing the outcomes to an LLM to reply.
We’ll finish the part with some dialogue on latency, pointless complexity, and what to chop to make the system quicker.
If you wish to take a look at the output of a number of runs of this pipeline, go to this repository.
Semantic, BM25 and hybrid search
The primary a part of this pipeline is to verify we’re getting again related paperwork for a consumer question. To do that, we work with semantic, BM25, and hybrid search.
For easy retrieval programs, folks will often simply use semantic search. To carry out semantic search, we embed dense vectors for every chunk of textual content utilizing an embedding mannequin.
If that is new to you, observe that embeddings signify every bit of textual content as a degree in a high-dimensional house. The place of every level displays how the mannequin understands its which means, based mostly on patterns it realized throughout coaching.

Texts with related meanings will then find yourself shut collectively.
Which means that if the mannequin has seen many examples of comparable language, it turns into higher at inserting associated texts close to one another, and due to this fact higher at matching a question with probably the most related content material.
I’ve written about this earlier than, utilizing clustering on varied embeddings fashions to see how they carried out for a use case, for those who’re eager to study extra.
To create dense vectors, I used OpenAI’s Giant embedding mannequin, since I’m working with scientific papers.
This mannequin is costlier than their small one and maybe not ideally suited for this use case.
I’d look into specialised fashions for particular domains or contemplate fine-tuning your individual. As a result of keep in mind if the embedding mannequin hasn’t seen many examples much like the texts you’re embedding, will probably be more durable to match them to related paperwork.
To help hybrid and BM25 search, we additionally construct a lexical index (sparse vectors). BM25 works on actual tokens (for instance, “ID 826384”) as a substitute of returning “similar-meaning” textual content the way in which semantic search does.
To check semantic search, we’ll arrange a question that I feel the papers we’ve ingested can reply, resembling: “Why do LLMs worsen with longer context home windows and what to do about it?”
[1] rating=0.5071 doc=docs_ingestor/docs/arxiv/2508.15253.pdf chunk=S3::C02::251009131027
textual content: 1 Introduction This problem is exacerbated when incorrect but extremely ranked contexts function onerous negatives. Standard RAG, i.e. , merely appending * Corresponding writer 1 https://github.com/eunseongc/CARE Determine 1: LLMs wrestle to resolve context-memory battle. Inexperienced bars present the variety of questions appropriately answered with out retrieval in a closed-book setting. Blue and yellow bars present efficiency when supplied with a constructive or detrimental context, respectively. Closed-book w/ Constructive Context W/ Adverse Context 1 8k 25.1% 49.1% 39.6% 47.5% 6k 4k 1 2k 4 Mistral-7b LLaMA3-8b GPT-4o-mini Claude-3.5 retrieved context to the immediate, struggles to discriminate between incorrect exterior context and proper parametric information (Ren et al., 2025). This misalignment results in overriding appropriate inner representations, leading to substantial efficiency degradation on questions that the mannequin initially answered appropriately. As proven in Determine 1, we noticed important efficiency drops of 25.149.1% throughout state-of-the-
[2] rating=0.5022 doc=docs_ingestor/docs/arxiv/2508.19614.pdf chunk=S3::C03::251009132038
textual content: 1 Introductions Regardless of these advances, LLMs may underutilize correct exterior contexts, disproportionately favoring inner parametric information throughout technology [50, 40]. This overreliance dangers propagating outdated info or hallucinations, undermining the trustworthiness of RAG programs. Surprisingly, current research reveal a paradoxical phenomenon: injecting noise-random paperwork or tokens-to retrieved contexts that already include answer-relevant snippets can enhance the technology accuracy [10, 49]. Whereas this noise-injection strategy is straightforward and efficient, its underlying affect on LLM stays unclear. Moreover, lengthy contexts containing noise paperwork create computational overhead. Due to this fact, you will need to design extra principled methods that may obtain related advantages with out incurring extreme price.
[3] rating=0.4982 doc=docs_ingestor/docs/arxiv/2508.19614.pdf chunk=S6::C18::251009132038
textual content: 4 Experiments 4.3 Evaluation Experiments Qualitative Research In Desk 4, we analyze a case research from the NQ dataset utilizing the Llama2-7B mannequin, evaluating 4 decoding methods: GD(0), CS, DoLA, and LFD. Regardless of entry to groundtruth paperwork, each GD(0) and DoLA generate incorrect solutions (e.g., '18 minutes'), suggesting restricted capability to combine contextual proof. Equally, whereas CS produces {a partially} related response ('Texas Revolution'), it reveals diminished factual consistency with the supply materials. In distinction, LFD demonstrates superior utilization of retrieved context, synthesizing a exact and factually aligned reply. Extra case research and analyses are offered in Appendix F.
[4] rating=0.4857 doc=docs_ingestor/docs/arxiv/2507.23588.pdf chunk=S6::C03::251009122456
textual content: 4 Outcomes Determine 4: Change in consideration sample distribution in several fashions. For DiffLoRA variants we plot consideration mass for essential element (inexperienced) and denoiser element (yellow). Observe that spotlight mass is normalized by the variety of tokens in every a part of the sequence. The detrimental consideration is proven after it's scaled by λ . DiffLoRA corresponds to the variant with learnable λ and LoRa parameters in each phrases. BOS CONTEXT 1 MAGIC NUMBER CONTEXT 2 QUERY 0 0.2 0.4 0.6 BOS CONTEXT 1 MAGIC NUMBER CONTEXT 2 QUERY BOS CONTEXT 1 MAGIC NUMBER CONTEXT 2 QUERY BOS CONTEXT 1 MAGIC NUMBER CONTEXT 2 QUERY Llama-3.2-1B LoRA DLoRA-32 DLoRA, Tulu-3 carry out equally because the preliminary mannequin, nonetheless they're outperformed by LoRA. When growing the context size with extra pattern demonstrations, DiffLoRA appears to wrestle much more in TREC-fine and Banking77. This may be because of the nature of instruction tuned information, and the max_sequence_length = 4096 utilized throughout finetuning. LoRA is much less impacted, seemingly as a result of it diverges much less
[5] rating=0.4838 doc=docs_ingestor/docs/arxiv/2508.15253.pdf chunk=S3::C03::251009131027
textual content: 1 Introduction To mitigate context-memory battle, current research resembling adaptive retrieval (Ren et al., 2025; Baek et al., 2025) and the decoding methods (Zhao et al., 2024; Han et al., 2025) regulate the affect of exterior context both earlier than or throughout reply technology. Nevertheless, because of the LLM's restricted capability in detecting conflicts, it's inclined to deceptive contextual inputs that contradict the LLM's parametric information. Not too long ago, sturdy coaching has geared up LLMs, enabling them to determine conflicts (Asai et al., 2024; Wang et al., 2024). As proven in Determine 2(a), it permits the LLM to dis-
[6] rating=0.4827 doc=docs_ingestor/docs/arxiv/2508.05266.pdf chunk=S27::C03::251009123532
textual content: B. Subclassification Standards for Misinterpretation of Design Specs Initially, relating to long-context situations, we noticed that instantly prompting LLMs to generate RTL code based mostly on prolonged contexts typically resulted in sure code segments failing to precisely mirror high-level necessities. Nevertheless, by manually decomposing the lengthy context-retaining solely the important thing descriptive textual content related to the inaccurate segments whereas omitting pointless details-the LLM regenerated RTL code that appropriately matched the specs. As proven in Fig 23, after handbook decomposition of the lengthy context, the LLM efficiently generated the right code. This demonstrates that redundancy in lengthy contexts is a limiting consider LLMs' capability to generate correct RTL code.
[7] rating=0.4798 doc=docs_ingestor/docs/arxiv/2508.19614.pdf chunk=S3::C02::251009132038
textual content: 1 Introductions Determine 1: Illustration for layer-wise habits in LLMs for RAG. Given a question and retrieved paperwork with the right reply ('Actual Madrid'), shallow layers seize native context, center layers deal with answer-relevant content material, whereas deep layers might over-rely on inner information and hallucinate (e.g., 'Barcelona'). Our proposal, LFD fuses middle-layer alerts into the ultimate output to protect exterior information and enhance accuracy. Shallow Layers Center Layers Deep Layers Who has extra la liga titles actual madrid or barcelona? …9 groups have been topped champions, with Actual Madrid profitable the title a report 33 instances and Barcelona 25 instances … Question Retrieved Doc …with Actual Madrid profitable the title a report 33 instances and Barcelona 25 instances … Quick-context Modeling Deal with Proper Reply Reply is barcelona Unsuitable Reply LLMs …with Actual Madrid profitable the title a report 33 instances and Barcelona 25 instances … …with Actual Madrid profitable the title a report 33 instances and Barcelona 25 instances … Inside Data ConfouFrom the outcomes above, we are able to see that it’s in a position to match some attention-grabbing passages the place they talk about matters that may reply the question.
If we strive BM25 (which matches actual tokens) with the identical question, we get again these outcomes:
[1] rating=22.0764 doc=docs_ingestor/docs/arxiv/2507.20888.pdf chunk=S4::C27::251009115003
textual content: 3 APPROACH 3.2.2 Venture Data Retrieval Related Code Retrieval. Related snippets inside the similar undertaking are worthwhile for code completion, even when they don't seem to be solely replicable. On this step, we additionally retrieve related code snippets. Following RepoCoder, we not use the unfinished code because the question however as a substitute use the code draft, as a result of the code draft is nearer to the bottom fact in comparison with the unfinished code. We use the Jaccard index to calculate the similarity between the code draft and the candidate code snippets. Then, we acquire a listing sorted by scores. Because of the doubtlessly giant variations in size between code snippets, we not use the top-k technique. As an alternative, we get code snippets from the best to the bottom scores till the preset context size is crammed.
[2] rating=17.4931 doc=docs_ingestor/docs/arxiv/2508.09105.pdf chunk=S20::C08::251009124222
textual content: C. Ablation Research Ablation outcome throughout White-Field attribution: Desk V reveals the comparability end in strategies of WhiteBox Attribution with Noise, White-Field Attrition with Various Mannequin and our present technique Black-Field zero-gradient Attribution with Noise underneath two LLM classes. We will know that: First, The White-Field Attribution with Noise is underneath the specified situation, thus the typical Accuracy Rating of two LLMs get the 0.8612 and 0.8073. Second, the the choice fashions (the 2 fashions are exchanged for attribution) attain the 0.7058 and 0.6464. Lastly, our present technique Black-Field Attribution with Noise get the Accuracy of 0.7008 and 0.6657 by two LLMs.
[3] rating=17.1458 doc=docs_ingestor/docs/arxiv/2508.05100.pdf chunk=S4::C03::251009123245
textual content: Preliminaries Primarily based on this, impressed by current analyses (Zhang et al. 2024c), we measure the quantity of data a place receives utilizing discrete entropy, as proven within the following equation: which quantifies how a lot info t i receives from the eye perspective. This perception means that LLMs wrestle with longer sequences when not educated on them, seemingly because of the discrepancy in info acquired by tokens in longer contexts. Primarily based on the earlier evaluation, the optimization of consideration entropy ought to deal with two elements: The knowledge entropy at positions which might be comparatively necessary and sure include key info ought to enhance.Right here, the outcomes are lackluster for this question — however typically queries embody particular key phrases we have to match, the place BM25 is the higher selection.
We will check this by altering the question to “papers from Anirban Saha Anik” utilizing BM25.
[1] rating=62.3398 doc=authors.csv chunk=authors::row::1::251009110024
textual content: author_name: Anirban Saha Anik n_papers: 2 article_1: 2509.01058 article_2: 2507.07307
[2] rating=56.4007 doc=titles.csv chunk=titles::row::24::251009110138
textual content: id: 2509.01058 title: Talking on the Proper Degree: Literacy-Managed Counterspeech Technology with RAG-RL key phrases: Managed-Literacy; Well being Misinformation; Public Well being; RAG; RL; Reinforcement Studying; Retrieval Augmented Technology abstract_url: https://arxiv.org/abs/2509.01058 created: 2025-09-10 00:00:00 UTC author_1: Xiaoying Tune author_2: Anirban Saha Anik author_3: Dibakar Barua author_4: Pengcheng Luo author_5: Junhua Ding author_6: Lingzi Hong
[3] rating=56.2614 doc=titles.csv chunk=titles::row::106::251009110138
textual content: id: 2507.07307 title: Multi-Agent Retrieval-Augmented Framework for Proof-Primarily based Counterspeech Towards Well being Misinformation key phrases: Proof Enhancement; Well being Misinformation; LLMs; Giant Language Fashions; RAG; Response Refinement; Retrieval Augmented Technology abstract_url: https://arxiv.org/abs/2507.07307 created: 2025-07-27 00:00:00 UTC author_1: Anirban Saha Anik author_2: Xiaoying Tune author_3: Elliott Wang author_4: Bryan Wang author_5: Bengisu Yarimbas author_6: Lingzi HongAll the outcomes above point out “Anirban Saha Anik,” which is precisely what we’re on the lookout for.
If we ran this with semantic search, it might return not simply the title “Anirban Saha Anik” however related names as effectively.
[1] rating=0.5810 doc=authors.csv chunk=authors::row::1::251009110024
textual content: author_name: Anirban Saha Anik n_papers: 2 article_1: 2509.01058 article_2: 2507.07307
[2] rating=0.4499 doc=authors.csv chunk=authors::row::55::251009110024
textual content: author_name: Anand A. Rajasekar n_papers: 1 article_1: 2508.0199
[3] rating=0.4320 doc=authors.csv chunk=authors::row::59::251009110024
textual content: author_name: Anoop Mayampurath n_papers: 1 article_1: 2508.14817
[4] rating=0.4306 doc=authors.csv chunk=authors::row::69::251009110024
textual content: author_name: Avishek Anand n_papers: 1 article_1: 2508.15437
[5] rating=0.4215 doc=authors.csv chunk=authors::row::182::251009110024
textual content: author_name: Ganesh Ananthanarayanan n_papers: 1 article_1: 2509.14608It is a good instance of how semantic search isn’t all the time the perfect technique — related names don’t essentially imply they’re related to the question.
So, there are instances the place semantic search is good, and others the place BM25 (token matching) is the higher selection.
We will additionally use hybrid search, which mixes semantic and BM25.
You’ll see the outcomes beneath from working hybrid search on the unique question: “why do LLMs worsen with longer context home windows and what to do about it?”
[1] rating=0.5000 doc=docs_ingestor/docs/arxiv/2508.15253.pdf chunk=S3::C02::251009131027
textual content: 1 Introduction This problem is exacerbated when incorrect but extremely ranked contexts function onerous negatives. Standard RAG, i.e. , merely appending * Corresponding writer 1 https://github.com/eunseongc/CARE Determine 1: LLMs wrestle to resolve context-memory battle. Inexperienced bars present the variety of questions appropriately answered with out retrieval in a closed-book setting. Blue and yellow bars present efficiency when supplied with a constructive or detrimental context, respectively. Closed-book w/ Constructive Context W/ Adverse Context 1 8k 25.1% 49.1% 39.6% 47.5% 6k 4k 1 2k 4 Mistral-7b LLaMA3-8b GPT-4o-mini Claude-3.5 retrieved context to the immediate, struggles to discriminate between incorrect exterior context and proper parametric information (Ren et al., 2025). This misalignment results in overriding appropriate inner representations, leading to substantial efficiency degradation on questions that the mannequin initially answered appropriately. As proven in Determine 1, we noticed important efficiency drops of 25.149.1% throughout state-of-the-
[2] rating=0.5000 doc=docs_ingestor/docs/arxiv/2507.20888.pdf chunk=S4::C27::251009115003
textual content: 3 APPROACH 3.2.2 Venture Data Retrieval Related Code Retrieval. Related snippets inside the similar undertaking are worthwhile for code completion, even when they don't seem to be solely replicable. On this step, we additionally retrieve related code snippets. Following RepoCoder, we not use the unfinished code because the question however as a substitute use the code draft, as a result of the code draft is nearer to the bottom fact in comparison with the unfinished code. We use the Jaccard index to calculate the similarity between the code draft and the candidate code snippets. Then, we acquire a listing sorted by scores. Because of the doubtlessly giant variations in size between code snippets, we not use the top-k technique. As an alternative, we get code snippets from the best to the bottom scores till the preset context size is crammed.
[3] rating=0.4133 doc=docs_ingestor/docs/arxiv/2508.19614.pdf chunk=S3::C03::251009132038
textual content: 1 Introductions Regardless of these advances, LLMs may underutilize correct exterior contexts, disproportionately favoring inner parametric information throughout technology [50, 40]. This overreliance dangers propagating outdated info or hallucinations, undermining the trustworthiness of RAG programs. Surprisingly, current research reveal a paradoxical phenomenon: injecting noise-random paperwork or tokens-to retrieved contexts that already include answer-relevant snippets can enhance the technology accuracy [10, 49]. Whereas this noise-injection strategy is straightforward and efficient, its underlying affect on LLM stays unclear. Moreover, lengthy contexts containing noise paperwork create computational overhead. Due to this fact, you will need to design extra principled methods that may obtain related advantages with out incurring extreme price.
[4] rating=0.1813 doc=docs_ingestor/docs/arxiv/2508.19614.pdf chunk=S6::C18::251009132038
textual content: 4 Experiments 4.3 Evaluation Experiments Qualitative Research In Desk 4, we analyze a case research from the NQ dataset utilizing the Llama2-7B mannequin, evaluating 4 decoding methods: GD(0), CS, DoLA, and LFD. Regardless of entry to groundtruth paperwork, each GD(0) and DoLA generate incorrect solutions (e.g., '18 minutes'), suggesting restricted capability to combine contextual proof. Equally, whereas CS produces {a partially} related response ('Texas Revolution'), it reveals diminished factual consistency with the supply materials. In distinction, LFD demonstrates superior utilization of retrieved context, synthesizing a exact and factually aligned reply. Extra case research and analyses are offered in Appendix F.I discovered semantic search labored finest for this question, which is why it may be helpful to run multi-queries with completely different search strategies to fetch the primary chunks (although this additionally provides complexity).
So, let’s flip to constructing one thing that may rework the unique question into a number of optimized variations and fuse the outcomes.
Multi-query optimizer
For this half we take a look at how we are able to optimize messy consumer queries by producing a number of focused variations and deciding on the correct search technique for every. It might enhance recall however it introduces trade-offs.
All of the agent abstraction programs you see often rework the consumer question when performing search. For instance, while you use the QueryTool in LlamaIndex, it makes use of an LLM to optimize the incoming question.

We will rebuild this half ourselves, however as a substitute we give it the flexibility to create a number of queries, whereas additionally setting the search technique. While you’re working with extra paperwork, you would even have it set filters at this stage.
As for creating a whole lot of queries, I’d attempt to hold it easy, as points right here will trigger low-quality outputs in retrieval. The extra unrelated queries the system generates, the extra noise it introduces into the pipeline.
The perform I’ve created right here will generate 1–3 academic-style queries, together with the search technique for use, based mostly on a messy consumer question.
Authentic question:
why is everybody saying RAG would not scale? how are folks fixing that?
Generated queries:
- hybrid: RAG scalability points
- hybrid: options to RAG scaling challengesWe’ll get again outcomes like these:
Question 1 (hybrid) prime 20 for question: RAG scalability points
[1] rating=0.5000 doc=docs_ingestor/docs/arxiv/2507.18910.pdf chunk=S22::C05::251104142800
textual content: 7 Challenges of RAG 7.2.1 Scalability and Infrastructure Deploying RAG at scale requires substantial engineering to keep up giant information corpora and environment friendly retrieval indices. Techniques should deal with hundreds of thousands or billions of paperwork, demanding important computational assets, environment friendly indexing, distributed computing infrastructure, and value administration methods [21]. Environment friendly indexing strategies, caching, and multi-tier retrieval approaches (resembling cascaded retrieval) change into important at scale, particularly in giant deployments like internet engines like google.
[2] rating=0.5000 doc=docs_ingestor/docs/arxiv/2507.07695.pdf chunk=SDOC::SUM::251104135247
textual content: This paper proposes the KeyKnowledgeRAG (K2RAG) framework to boost the effectivity and accuracy of Retrieval-Increase-Generate (RAG) programs. It addresses the excessive computational prices and scalability points related to naive RAG implementations by incorporating methods resembling information graphs, a hybrid retrieval strategy, and doc summarization to cut back coaching instances and enhance reply accuracy. Evaluations present that K2RAG considerably outperforms conventional implementations, attaining larger reply similarity and quicker execution instances, thereby offering a scalable resolution for firms in search of sturdy question-answering programs.
[...]
Question 2 (hybrid) prime 20 for question: options to RAG scaling challenges
[1] rating=0.5000 doc=docs_ingestor/docs/arxiv/2507.18910.pdf chunk=S22::C05::251104142800
textual content: 7 Challenges of RAG 7.2.1 Scalability and Infrastructure Deploying RAG at scale requires substantial engineering to keep up giant information corpora and environment friendly retrieval indices. Techniques should deal with hundreds of thousands or billions of paperwork, demanding important computational assets, environment friendly indexing, distributed computing infrastructure, and value administration methods [21]. Environment friendly indexing strategies, caching, and multi-tier retrieval approaches (resembling cascaded retrieval) change into important at scale, particularly in giant deployments like internet engines like google.
[2] rating=0.5000 doc=docs_ingestor/docs/arxiv/2508.05100.pdf chunk=S3::C06::251104155301
textual content: Introduction Empirical analyses throughout a number of real-world benchmarks reveal that BEE-RAG basically alters the entropy scaling legal guidelines governing typical RAG programs, which gives a sturdy and scalable resolution for RAG programs coping with long-context situations. Our essential contributions are summarized as follows: We introduce the idea of balanced context entropy, a novel consideration reformulation that ensures entropy invariance throughout various context lengths, and allocates consideration to necessary segments. It addresses the vital problem of context enlargement in RAG.
[...]We will additionally check the system with particular key phrases like names and IDs to verify it chooses BM25 slightly than semantic search.
Authentic question:
any papers from Chenxin Diao?
Generated queries:
- BM25: Chenxin DiaoIt will pull up outcomes the place Chenxin Diao is clearly talked about.
I ought to observe, BM25 might trigger points when customers misspell names, resembling asking for “Chenx Dia” as a substitute of “Chenxin Diao.” So in actuality chances are you’ll simply need to slap hybrid search on all of them (and later let the re-ranker handle removing irrelevant outcomes).
If you wish to do that even higher, you’ll be able to construct a retrieval system that generates a number of instance queries based mostly on the enter, so when the unique question is available in, you fetch examples to assist information the optimizer.
This helps as a result of smaller fashions aren’t nice at remodeling messy human queries into ones with extra exact tutorial phrasing.
To offer you an instance, when a consumer is asking why the LLM is mendacity, the optimizer might rework the question to one thing like “causes of inaccuracies in giant language fashions” slightly than instantly search for “hallicunations.”
After we fetch ends in parallel, we fuse them. The outcome will look one thing like this:
RRF Fusion prime 38 for question: why is everybody saying RAG would not scale? how are folks fixing that?
[1] rating=0.0328 doc=docs_ingestor/docs/arxiv/2507.18910.pdf chunk=S22::C05::251104142800
textual content: 7 Challenges of RAG 7.2.1 Scalability and Infrastructure Deploying RAG at scale requires substantial engineering to keep up giant information corpora and environment friendly retrieval indices. Techniques should deal with hundreds of thousands or billions of paperwork, demanding important computational assets, environment friendly indexing, distributed computing infrastructure, and value administration methods [21]. Environment friendly indexing strategies, caching, and multi-tier retrieval approaches (resembling cascaded retrieval) change into important at scale, particularly in giant deployments like internet engines like google.
[2] rating=0.0313 doc=docs_ingestor/docs/arxiv/2507.18910.pdf chunk=S22::C42::251104142800
textual content: 7 Challenges of RAG 7.5.5 Scalability Scalability challenges come up as information corpora develop. Superior indexing, distributed retrieval, and approximate nearest neighbor methods facilitate environment friendly dealing with of large-scale information bases [57]. Selective indexing and corpus curation, mixed with infrastructure enhancements like caching and parallel retrieval, permit RAG programs to scale to large information repositories. Analysis signifies that moderate-sized fashions augmented with giant exterior corpora can outperform considerably bigger standalone fashions, suggesting parameter effectivity benefits [10].
[3] rating=0.0161 doc=docs_ingestor/docs/arxiv/2507.07695.pdf chunk=SDOC::SUM::251104135247
textual content: This paper proposes the KeyKnowledgeRAG (K2RAG) framework to boost the effectivity and accuracy of Retrieval-Increase-Generate (RAG) programs. It addresses the excessive computational prices and scalability points related to naive RAG implementations by incorporating methods resembling information graphs, a hybrid retrieval strategy, and doc summarization to cut back coaching instances and enhance reply accuracy. Evaluations present that K2RAG considerably outperforms conventional implementations, attaining larger reply similarity and quicker execution instances, thereby offering a scalable resolution for firms in search of sturdy question-answering programs.
[4] rating=0.0161 doc=docs_ingestor/docs/arxiv/2508.05100.pdf chunk=S3::C06::251104155301
textual content: Introduction Empirical analyses throughout a number of real-world benchmarks reveal that BEE-RAG basically alters the entropy scaling legal guidelines governing typical RAG programs, which gives a sturdy and scalable resolution for RAG programs coping with long-context situations. Our essential contributions are summarized as follows: We introduce the idea of balanced context entropy, a novel consideration reformulation that ensures entropy invariance throughout various context lengths, and allocates consideration to necessary segments. It addresses the vital problem of context enlargement in RAG.
[...]We see that there are some good matches, but in addition a number of irrelevant ones that we’ll have to filter out additional.
As a observe earlier than we transfer on, that is in all probability the step you’ll minimize or optimize when you’re making an attempt to cut back latency.
I discover LLMs aren’t nice at creating key queries that really pull up helpful info all that effectively, so if it’s not finished proper, it simply provides extra noise.
Including a re-ranker
We do get outcomes again from the retrieval system, and a few of these are good whereas others are irrelevant, so most retrieval programs will use a re-ranker of some kind.
A re-ranker takes in a number of chunks and offers every one a relevancy rating based mostly on the unique consumer question. You could have a number of selections right here, together with utilizing one thing smaller, however I’ll use Cohere’s re-ranker.
We will check this re-ranker on the primary query we used within the earlier part: “Why is everybody saying RAG doesn’t scale? How are folks fixing that?”
[... optimizer... retrieval... fuse...]
Rerank abstract:
- technique=cohere
- mannequin=rerank-english-v3.0
- candidates=32
- eligible_above_threshold=4
- saved=4 (reranker_threshold=0.35)
Reranked Related (4/32 saved ≥ 0.35) prime 4 for question: why is everybody saying RAG would not scale? how are folks fixing that?
[1] rating=0.7920 doc=docs_ingestor/docs/arxiv/2507.07695.pdf chunk=S4::C08::251104135247
textual content: 1 Introduction Scalability: Naive implementations of Retrieval-Augmented Technology (RAG) typically depend on 16-bit floating-point giant language fashions (LLMs) for the technology element. Nevertheless, this strategy introduces important scalability challenges because of the elevated reminiscence calls for required to host the LLM in addition to longer inference instances as a consequence of utilizing the next precision quantity sort. To allow extra environment friendly scaling, it's essential to combine strategies or methods that scale back the reminiscence footprint and inference instances of generator fashions. Quantized fashions supply extra scalable options as a consequence of much less computational necessities, therefore when growing RAG programs we should always goal to make use of quantized LLMs for more economical deployment as in comparison with a full fine-tuned LLM whose efficiency may be good however is costlier to deploy as a consequence of larger reminiscence necessities. A quantized LLM's position within the RAG pipeline itself needs to be minimal and for technique of rewriting retrieved info right into a presentable trend for the top customers
[2] rating=0.4749 doc=docs_ingestor/docs/arxiv/2507.18910.pdf chunk=S22::C42::251104142800
textual content: 7 Challenges of RAG 7.5.5 Scalability Scalability challenges come up as information corpora develop. Superior indexing, distributed retrieval, and approximate nearest neighbor methods facilitate environment friendly dealing with of large-scale information bases [57]. Selective indexing and corpus curation, mixed with infrastructure enhancements like caching and parallel retrieval, permit RAG programs to scale to large information repositories. Analysis signifies that moderate-sized fashions augmented with giant exterior corpora can outperform considerably bigger standalone fashions, suggesting parameter effectivity benefits [10].
[3] rating=0.4304 doc=docs_ingestor/docs/arxiv/2507.18910.pdf chunk=S22::C05::251104142800
textual content: 7 Challenges of RAG 7.2.1 Scalability and Infrastructure Deploying RAG at scale requires substantial engineering to keep up giant information corpora and environment friendly retrieval indices. Techniques should deal with hundreds of thousands or billions of paperwork, demanding important computational assets, environment friendly indexing, distributed computing infrastructure, and value administration methods [21]. Environment friendly indexing strategies, caching, and multi-tier retrieval approaches (resembling cascaded retrieval) change into important at scale, particularly in giant deployments like internet engines like google.
[4] rating=0.3556 doc=docs_ingestor/docs/arxiv/2509.13772.pdf chunk=S11::C02::251104182521
textual content: 7. Dialogue and Limitations Scalability of RAGOrigin: We lengthen our analysis by scaling the NQ dataset's information database to 16.7 million texts, combining entries from the information database of NQ, HotpotQA, and MS-MARCO. Utilizing the identical consumer questions from NQ, we assess RAGOrigin's efficiency underneath bigger information volumes. As proven in Desk 16, RAGOrigin maintains constant effectiveness and efficiency even on this considerably expanded database. These outcomes exhibit that RAGOrigin stays sturdy at scale, making it appropriate for enterprise-level functions requiring giantKeep in mind, at this level, we’ve already reworked the consumer question, finished semantic or hybrid search, and fused the outcomes earlier than passing the chunks to the re-ranker.
When you take a look at the outcomes, we are able to clearly see that it’s in a position to determine a number of related chunks that we are able to use as seeds.
Keep in mind it solely has 150 docs to go on within the first place.
You can even see that it returns a number of chunks from the identical doc. We’ll set this up later within the context building, however if you would like distinctive paperwork fetched, you’ll be able to add some customized logic right here to set the restrict for distinctive docs slightly than chunks.
We will do this with one other query: “hallucinations in RAG vs regular LLMs and easy methods to scale back them”
[... optimizer... retrieval... fuse...]
Rerank abstract:
- technique=cohere
- mannequin=rerank-english-v3.0
- candidates=35
- eligible_above_threshold=12
- saved=5 (threshold=0.2)
Reranked Related (5/35 saved ≥ 0.2) prime 5 for question: hallucinations in rag vs regular llms and easy methods to scale back them
[1] rating=0.9965 doc=docs_ingestor/docs/arxiv/2508.19614.pdf chunk=S7::C03::251104164901
textual content: 5 Associated Work Hallucinations in LLMs Hallucinations in LLMs seek advice from cases the place the mannequin generates false or unsupported info not grounded in its reference information [42]. Present mitigation methods embody multi-agent debating, the place a number of LLM cases collaborate to detect inconsistencies by iterative debates [8, 14]; self-consistency verification, which aggregates and reconciles a number of reasoning paths to cut back particular person errors [53]; and mannequin enhancing, which instantly modifies neural community weights to appropriate systematic factual errors [62, 19]. Whereas RAG programs goal to floor responses in retrieved exterior information, current research present that they nonetheless exhibit hallucinations, particularly those who contradict the retrieved content material [50]. To deal with this limitation, our work conducts an empirical research analyzing how LLMs internally course of exterior information
[2] rating=0.9342 doc=docs_ingestor/docs/arxiv/2508.05509.pdf chunk=S3::C01::251104160034
textual content: Introduction Giant language fashions (LLMs), like Claude (Anthropic 2024), ChatGPT (OpenAI 2023) and the Deepseek collection (Liu et al. 2024), have demonstrated exceptional capabilities in lots of real-world duties (Chen et al. 2024b; Zhou et al. 2025), resembling query answering (Allam and Haggag 2012), textual content comprehension (Wright and Cervetti 2017) and content material technology (Kumar 2024). Regardless of the success, these fashions are sometimes criticized for his or her tendency to supply hallucinations, producing incorrect statements on duties past their information and notion (Ji et al. 2023; Zhang et al. 2024). Not too long ago, retrieval-augmented technology (RAG) (Gao et al. 2023; Lewis et al. 2020) has emerged as a promising resolution to alleviate such hallucinations. By dynamically leveraging exterior information from textual corpora, RAG permits LLMs to generate extra correct and dependable responses with out expensive retraining (Lewis et al. 2020; Determine 1: Comparability of three paradigms. LAG reveals larger light-weight properties in comparison with GraphRAG whereas
[3] rating=0.9030 doc=docs_ingestor/docs/arxiv/2509.13702.pdf chunk=S3::C01::251104182000
textual content: ABSTRACT Hallucination stays a vital barrier to the dependable deployment of Giant Language Fashions (LLMs) in high-stakes functions. Present mitigation methods, resembling Retrieval-Augmented Technology (RAG) and post-hoc verification, are sometimes reactive, inefficient, or fail to deal with the basis trigger inside the generative course of. Impressed by dual-process cognitive concept, we suggest D ynamic S elfreinforcing C alibration for H allucination S uppression (DSCC-HS), a novel, proactive framework that intervenes instantly throughout autoregressive decoding. DSCC-HS operates by way of a two-phase mechanism: (1) Throughout coaching, a compact proxy mannequin is iteratively aligned into two adversarial roles-a Factual Alignment Proxy (FAP) and a Hallucination Detection Proxy (HDP)-through contrastive logit-space optimization utilizing augmented information and parameter-efficient LoRA adaptation. (2) Throughout inference, these frozen proxies dynamically steer a big goal mannequin by injecting a real-time, vocabulary-aligned steering vector (computed because the
[4] rating=0.9007 doc=docs_ingestor/docs/arxiv/2509.09360.pdf chunk=S2::C05::251104174859
textual content: 1 Introduction Determine 1. Normal Retrieval-Augmented Technology (RAG) workflow. A consumer question is encoded right into a vector illustration utilizing an embedding mannequin and queried towards a vector database constructed from a doc corpus. Essentially the most related doc chunks are retrieved and appended to the unique question, which is then offered as enter to a big language mannequin (LLM) to generate the ultimate response. Corpus Retrieved_Chunks Vectpr DB Embedding mannequin Question Response LLM Retrieval-Augmented Technology (RAG) [17] goals to mitigate hallucinations by grounding mannequin outputs in retrieved, up-to-date paperwork, as illustrated in Determine 1. By injecting retrieved textual content from re- a
[5] rating=0.8986 doc=docs_ingestor/docs/arxiv/2508.04057.pdf chunk=S20::C02::251104155008
textual content: Parametric information can generate correct solutions. Results of LLM hallucinations. To evaluate the influence of hallucinations when giant language fashions (LLMs) generate solutions with out retrieval, we conduct a managed experiment based mostly on a easy heuristic: if a generated reply accommodates numeric values, it's extra more likely to be affected by hallucination. It's because LLMs are usually much less dependable when producing exact information resembling numbers, dates, or counts from parametric reminiscence alone (Ji et al. 2023; Singh et al. 2025). We filter out all instantly answered queries (DQs) whose generated solutions include numbers, and we then rerun our DPR-AIS for these queries (referred to Exclude num ). The outcomes are reported in Tab. 5. Total, excluding numeric DQs ends in barely improved efficiency. The common actual match (EM) will increase from 35.03 to 35.12, and the typical F1 rating improves from 35.68 to 35.80. Whereas these good points are modest, they arrive with a rise within the retriever activation (RA) ratio-from 75.5% to 78.1%.This question additionally performs effectively sufficient (for those who take a look at the total chunks returned).
We will additionally check messier consumer queries, like: “why is the llm mendacity and rag assist with this?”
[... optimizer...]
Authentic question:
why is the llm mendacity and rag assist with this?
Generated queries:
- semantic: discover causes for LLM inaccuracies
- hybrid: RAG methods for LLM truthfulness
[...retrieval... fuse...]
Rerank abstract:
- technique=cohere
- mannequin=rerank-english-v3.0
- candidates=39
- eligible_above_threshold=39
- saved=6 (threshold=0)
Reranked Related (6/39 saved ≥ 0) prime 6 for question: why is the llm mendacity and rag assist with this?
[1] rating=0.0293 doc=docs_ingestor/docs/arxiv/2507.05714.pdf chunk=S3::C01::251104134926
textual content: 1 Introduction Retrieval Augmentation Technology (hereafter known as RAG) helps giant language fashions (LLMs) (OpenAI et al., 2024) scale back hallucinations (Zhang et al., 2023) and entry real-time information 1 *Equal contribution.
[2] rating=0.0284 doc=docs_ingestor/docs/arxiv/2508.15437.pdf chunk=S3::C01::251104164223
textual content: 1 Introduction Giant language fashions (LLMs) augmented with retrieval have change into a dominant paradigm for knowledge-intensive NLP duties. In a typical retrieval-augmented technology (RAG) setup, an LLM retrieves paperwork from an exterior corpus and circumstances technology on the retrieved proof (Lewis et al., 2020b; Izacard and Grave, 2021). This setup mitigates a key weak point of LLMs-hallucination-by grounding technology in externally sourced information. RAG programs now energy open-domain QA (Karpukhin et al., 2020), reality verification (V et al., 2024; Schlichtkrull et al., 2023), knowledge-grounded dialogue, and explanatory QA.
[3] rating=0.0277 doc=docs_ingestor/docs/arxiv/2509.09651.pdf chunk=S3::C01::251104180034
textual content: 1 Introduction Giant Language Fashions (LLMs) have reworked pure language processing, attaining state-ofthe-art efficiency in summarization, translation, and query answering. Nevertheless, regardless of their versatility, LLMs are vulnerable to producing false or deceptive content material, a phenomenon generally known as hallucination [9, 21]. Whereas typically innocent in informal functions, such inaccuracies pose important dangers in domains that demand strict factual correctness, together with medication, regulation, and telecommunications. In these settings, misinformation can have extreme penalties, starting from monetary losses to security hazards and authorized disputes.
[4] rating=0.0087 doc=docs_ingestor/docs/arxiv/2507.07695.pdf chunk=S4::C08::251104135247
textual content: 1 Introduction Scalability: Naive implementations of Retrieval-Augmented Technology (RAG) typically depend on 16-bit floating-point giant language fashions (LLMs) for the technology element. Nevertheless, this strategy introduces important scalability challenges because of the elevated reminiscence calls for required to host the LLM in addition to longer inference instances as a consequence of utilizing the next precision quantity sort. To allow extra environment friendly scaling, it's essential to combine strategies or methods that scale back the reminiscence footprint and inference instances of generator fashions. Quantized fashions supply extra scalable options as a consequence of much less computational necessities, therefore when growing RAG programs we should always goal to make use of quantized LLMs for more economical deployment as in comparison with a full fine-tuned LLM whose efficiency may be good however is costlier to deploy as a consequence of larger reminiscence necessities. A quantized LLM's position within the RAG pipeline itself needs to be minimal and for technique of rewriting retrieved info right into a presentable trend for the top customersEarlier than we transfer on, I would like to notice that there are moments the place this re-ranker doesn’t try this effectively, as you’ll see above from the scores.
At instances it estimates that the chunks doesn’t reply the consumer’s query however it really does, at the least after we take a look at these chunks as seeds.
Often for a re-ranker, the chunks ought to trace on the total content material, however we’re utilizing these chunks as seeds, so in some instances it’ll charge outcomes very low, however it’s sufficient for us to go on.
For this reason I’ve saved the rating threshold very low.
There could also be higher choices right here that you simply may need to discover, perhaps constructing a customized re-ranker that understands what you’re on the lookout for.
Nonetheless, now that we’ve a number of related paperwork, we’ll use its metadata that we set earlier than on ingestion to develop and fan out the chunks so the LLM will get sufficient context to grasp easy methods to reply the query.
Construct the context
Now that we’ve a number of chunks as seeds, we’ll pull up extra info from Redis, develop, and construct the context.
This step is clearly much more sophisticated, as you’ll want to construct logic for which chunks to fetch and the way (keys in the event that they exist, or neighbors if there are any), fetch info in parallel, after which clear out the chunks additional.
After getting all of the chunks (plus info on the paperwork themselves), you’ll want to put them collectively, i.e. de-duping chunks, maybe setting a restrict on how far the system can develop, and highlighting which chunks have been fetched and which have been expanded.
The top outcome will appear like one thing beneath:
Expanded context home windows (Markdown prepared):
## Doc #1 - Fusing Data and Language: A Comparative Research of Data Graph-Primarily based Query Answering with LLMs
- `doc_id`: `doc::6371023da29b4bbe8242ffc5caf4a8cd`
- **Final Up to date:** 2025-11-04T17:44:07.300967+00:00
- **Context:** Comparative research on methodologies for integrating information graphs in QA programs utilizing LLMs.
- **Content material fetched inside doc:**
```textual content
[start on page 4]
LLMs in QA
The appearance of LLMs has steered in a transformative period in NLP, notably inside the area of QA. These fashions, pre-trained on large corpora of numerous textual content, exhibit subtle capabilities in each pure language understanding and technology. Their proficiency in producing coherent, contextually related, and human-like responses to a broad spectrum of prompts makes them exceptionally well-suited for QA duties, the place delivering exact and informative solutions is paramount. Current developments by fashions resembling BERT [57] and ChatGPT [58], have considerably propelled the sector ahead. LLMs have demonstrated robust efficiency in open-domain QA scenarios-such as commonsense reasoning[20]-owing to their in depth embedded information of the world. Furthermore, their capability to understand and articulate responses to summary or contextually nuanced queries and reasoning duties [22] underscores their utility in addressing complicated QA challenges that require deep semantic understanding. Regardless of their strengths, LLMs additionally pose challenges: they will exhibit contextual ambiguity or overconfidence of their outputs ('hallucinations')[21], and their substantial computational and reminiscence necessities complicate deployment in resource-constrained environments.
RAG, fantastic tuning in QA
---------------------- this was the passage that we matched to the question -------------
LLMs additionally face issues relating to area particular QA or duties the place they're wanted to recall factual info precisely as a substitute of simply probabilistically producing no matter comes subsequent. Analysis has additionally explored completely different prompting methods, like chain-of-thought prompting[24], and sampling based mostly strategies[23] to cut back hallucinations. Modern analysis more and more explores methods resembling fine-tuning and retrieval augmentation to boost LLM-based QA programs. Superb-tuning on domain-specific corpora (e.g., BioBERT for biomedical textual content [17], SciBERT for scientific textual content [18]) has been proven to sharpen mannequin focus, lowering irrelevant or generic responses in specialised settings resembling medical or authorized QA. Retrieval-augmented architectures resembling RAG [19] mix LLMs with exterior information bases, to attempt to additional mitigate problems with factual inaccuracy and allow real-time incorporation of recent info. Constructing on RAG's capability to bridge parametric and non-parametric information, many fashionable QA pipelines introduce a light-weight re-ranking step [25] to sift by the retrieved contexts and promote passages which might be most related to the question. Nevertheless, RAG nonetheless faces a number of challenges. One key challenge lies within the retrieval step itself-if the retriever fails to fetch related paperwork, the generator is left to hallucinate or present incomplete solutions. Furthermore, integrating noisy or loosely related contexts can degrade response high quality slightly than improve it, particularly in high-stakes domains the place precision is vital. RAG pipelines are additionally delicate to the standard and area alignment of the underlying information base, and so they typically require in depth tuning to steadiness recall and precision successfully.
--------------------------------------------------------------------------------------
[end on page 5]
```
## Doc #2 - Every to Their Personal: Exploring the Optimum Embedding in RAG
- `doc_id`: `doc::3b9c43d010984d4cb11233b5de905555`
- **Final Up to date:** 2025-11-04T14:00:38.215399+00:00
- **Context:** Enhancing Giant Language Fashions utilizing Retrieval-Augmented Technology methods.
- **Content material fetched inside doc:**
```textual content
[start on page 1]
1 Introduction
Giant language fashions (LLMs) have lately accelerated the tempo of transformation throughout a number of fields, together with transportation (Lyu et al., 2025), arts (Zhao et al., 2025), and schooling (Gao et al., 2024), by varied paradigms resembling direct reply technology, coaching from scratch on various kinds of information, and fine-tuning heading in the right direction domains. Nevertheless, the hallucination drawback (Henkel et al., 2024) related to LLMs has confused folks for a very long time, stemming from a number of components resembling a lack of understanding on the given immediate (Huang et al., 2025b) and a biased coaching course of (Zhao, 2025).
Serving as a extremely environment friendly resolution, RetrievalAugmented Technology (RAG) has been extensively employed in establishing basis fashions (Chen et al., 2024) and sensible brokers (Arslan et al., 2024). In comparison with coaching strategies like fine-tuning and prompt-tuning, its plug-and-play characteristic makes RAG an environment friendly, easy, and costeffective strategy. The principle paradigm of RAG includes first calculating the similarities between a query and chunks in an exterior information corpus, adopted by incorporating the highest Okay related chunks into the immediate to information the LLMs (Lewis et al., 2020).
Regardless of the benefits of RAG, deciding on the suitable embedding fashions stays a vital concern, as the standard of retrieved references instantly influences the technology outcomes of the LLM (Tu et al., 2025). Variations in coaching information and mannequin structure result in completely different embedding fashions offering advantages throughout varied domains. The differing similarity calculations throughout embedding fashions typically go away researchers unsure about how to decide on the optimum one. Consequently, bettering the accuracy of RAG from the attitude of embedding fashions continues to be an ongoing space of analysis.
---------------------- this was the passage that we matched to the question -------------
To deal with this analysis hole, we suggest two strategies for bettering RAG by combining the advantages of a number of embedding fashions. The primary technique is known as Combination-Embedding RAG, which kinds the retrieved supplies from a number of embedding fashions based mostly on normalized similarity and selects the highest Okay supplies as closing references. The second technique is known as Assured RAG, the place we first make the most of vanilla RAG to generate solutions a number of instances, every time using a unique embedding mannequin and recording the related confidence metrics, after which choose the reply with the best confidence stage as the ultimate response. By validating our strategy utilizing a number of LLMs and embedding fashions, we illustrate the superior efficiency and generalization of Assured RAG, regardless that MixtureEmbedding RAG might lose to vanilla RAG. The principle contributions of this paper could be summarized as follows:
We first level out that in RAG, completely different embedding fashions function inside their very own prior domains. To leverage the strengths of assorted embedding fashions, we suggest and check two novel RAG strategies: MixtureEmbedding RAG and Assured RAG. These strategies successfully make the most of the retrieved outcomes from completely different embedding fashions to their fullest extent.
--------------------------------------------------------------------------------------
Whereas Combination-Embedding RAG performs equally to vanilla RAG, the Assured RAG technique reveals superior efficiency in comparison with each the vanilla LLM and vanilla RAG, with common enhancements of 9.9% and 4.9%, respectively, when utilizing the most effective confidence metric. Moreover, we talk about the optimum variety of embedding fashions for the Assured RAG technique based mostly on the outcomes.
[...]The full context will include a number of paperwork and lands round 2–3k tokens. There’s some waste right here, however as a substitute of deciding for the LLM, we ship in additional info so it will probably scan total paperwork slightly than remoted chunks.
Keep in mind you’ll be able to check out the pipeline for 5 completely different queries right here to see the way it works.
For the system you construct, you’ll be able to cache this context as effectively so the LLM can reply follow-up questions.
Add within the LLM to reply (the G in RAG)
Let’s end up with the final step, simply to see how the LLM solutions with the context it has been handed.
I didn’t plan on including this half, as this text is primarily concerning the retrieval pipeline, however it’s good to check with an LLM to see if it will probably interpret the data into one thing coherent.
When you use a bigger LLM right here, you’ll be able to anticipate the latency to go up fairly a bit. On the similar time, for those who use a smaller mannequin, it could not reply as intelligently.
I made a decision to check with GPT-5 (low reasoning), because it’s very low cost to make use of but in addition fairly gradual. You’ll see the outcome beneath with the messy consumer question: “why is the llm mendacity and might rag assist with this?”
[optimize query... retrieve... fuse... re-rank... expand... build context...]
LLM Solutions:
LLMs typically "lie" as a result of they generate the subsequent seemingly phrases based mostly on patterns, not on verified information. With out grounding in sources, they will produce assured however false statements-known as hallucinations-and their constructed‑in information could be outdated or incomplete [6][3]. That is dangerous in domains that demand strict accuracy (e.g., regulation or telecom laws) the place small errors have large penalties [3].
RAG helps by having the mannequin first retrieve related paperwork from an exterior corpus after which generate solutions grounded in that proof. This reduces hallucinations and brings in up‑to‑date info [2][6][1]. In follow, area‑tailor-made RAG has raised accuracy considerably; for instance, a radio‑laws RAG pipeline boosted GPT‑4o accuracy by +11.9% over vanilla prompting and achieved as much as 97% retrieval accuracy, supporting extra dependable solutions [3].
Nevertheless, RAG is barely nearly as good as its retrieval and the way effectively the mannequin makes use of the retrieved textual content. Static, off‑the‑shelf retrievers could be brittle for complicated duties (e.g., multihop questions or procedural queries) that want iterative lookups or question reformulation [2]. Naive RAG may drown the mannequin in lengthy, noisy contexts or pull semantically related however irrelevant chunks-the "needle‑in‑a‑haystack" problem-leading to mistaken solutions [4].
Higher RAG practices deal with this: instruction‑tuning for RAG that teaches filtering, combining a number of sources, and RAG‑particular reasoning with a "suppose earlier than answering" strategy (HIRAG) improves use of proof [1]; adaptive, suggestions‑pushed retrieval decides when and easy methods to retrieve and re‑rank proof [2]; and pipeline designs that optimize chunking and retrieval elevate reply accuracy [4].
If hallucination nonetheless persists, methods that steer decoding instantly (past RAG) can additional suppress it [5].
cited paperwork:
[1] doc::b0610cc6134b401db0ea68a77096e883 - HIRAG: Hierarchical-Thought Instruction-Tuning Retrieval-Augmented Technology
[2] doc::53b521e646b84289b46e648c66dde56a - Check-time Corpus Suggestions: From Retrieval to RAG
[3] doc::9694bd0124d0453c81ecb32dd75ab489 - Retrieval-Augmented Technology for Dependable Interpretation of Radio Rules
[4] doc::6d7a7d88cfc04636b20931fdf22f1e61 - KeyKnowledgeRAG (Okay^2RAG): An Enhanced RAG technique for improved LLM question-answering capabilities
[5] doc::3c9a1937ecbc454b8faff4f66bdf427f - DSCC-HS: A Dynamic Self-Reinforcing Framework for Hallucination Suppression in Giant Language Fashions
[6] doc::688cfbc0abdc4520a73e219ac26aff41 - A Systematic Overview of Key Retrieval-Augmented Technology (RAG) Techniques: Progress, Gaps, and Future InstructionsYou’ll see that it cites sources appropriately and makes use of the data it has been handed, however as we’re utilizing GPT-5, the latency is sort of excessive with this huge context.
It takes about 9 seconds to first token with GPT-5 (however it’ll rely in your surroundings).
If the whole retrieval pipeline takes about 4–5 seconds (and this isn’t optimized), this implies the final half will take about 2–3 instances longer.
Some folks will argue that you’ll want to ship in much less info within the context window to lower latency for this half however that additionally defeats the aim of what we’re making an attempt to do.
Others will argue for utilizing chain prompting, having one smaller LLM extract helpful info after which letting one other greater LLM reply with an optimized context window however I’m unsure how a lot you save by way of time or if it’s price it.
Others will go as small as attainable, sacrificing “intelligence” for pace and value. However there’s additionally a danger of utilizing smaller with greater than a 2k window as they will begin to hallucinate.
Nonetheless, it’s as much as you ways you optimize the system. That’s the onerous half.
If you wish to study the whole pipeline for a number of queries see this folder.
Let’s speak latency & price
Individuals speaking about sending in total docs into an LLM are in all probability not ruthlessly optimizing for latency of their programs. That is the half you’ll spend probably the most time with, customers don’t need to wait.
Sure you’ll be able to apply some UX methods, however devs may suppose you’re lazy in case your retrieval pipeline is slower than a number of seconds.
That is additionally why it’s attention-grabbing that we see this shift into agentic search within the wild, it’s a lot slower so as to add giant context home windows, LLM-based question transforms, auto “router” chains, sub-question decomposition and multi-step “agentic” question engines.
For this method right here (largely constructed with Codex and my directions) we land at round 4–5 seconds for retrieval in a Serverless surroundings.

That is form of gradual (however fairly low cost).
You may optimize every step right here to carry that quantity down, protecting most issues heat. Nevertheless, utilizing the APIs you’ll be able to’t all the time management how briskly they return a response.
Some folks will argue to host your individual smaller fashions for the optimizer and routers, however then you’ll want to add in prices to host which might simply add a number of hundred {dollars} per 30 days.
With this pipeline right here, every run (with out caching) price us 1.2 cents ($0.0121) so for those who had your org ask 200 questions day by day you’d pay round $2.42 with GPT-5.
When you change to GPT-5-mini for the principle LLM, one pipeline run would drop to 0.41 cents, and quantity to about $0.82 per day for 200 runs.
As for embedding the paperwork, I paid round $0.5 for 200 PDF recordsdata utilizing OpenAI’s giant mannequin. This price will enhance as you scale which is one thing to think about, then it will probably make sense with small or specialised fine-tuned mannequin.
How you can enhance it
As we’re solely working with current RAG papers, when you scale it, you’ll be able to add some stuff to make it extra sturdy.
I ought to first observe although that you could be not see many of the actual points till your docs begin rising. No matter feels stable with a number of hundred docs will begin to really feel messy when you ingest tens of 1000’s.
You may have the optimizer set filters, maybe utilizing semantic matching for matters. You can even have it set the dates to maintain the data recent whereas introducing an authority sign in re-ranking that enhances sure sources.
Some groups take this a bit additional and design their very own scoring capabilities to resolve what ought to floor and easy methods to prioritize paperwork, however this relies solely on what your corpus seems to be like.
If you’ll want to ingest a number of thousand docs, it would make sense to skip the LLM throughout ingestion and as a substitute use it within the retrieval pipeline, the place it analyzes paperwork solely when a question asks for it. You may then cache that outcome for subsequent time.
Lastly, all the time keep in mind so as to add correct evals to indicate retrieval high quality and groundedness, particularly for those who’re switching fashions to optimize for price. I’ll attempt to do some writing on this sooner or later.
When you’re nonetheless with me this far, a query you’ll be able to ask your self is whether or not it’s price it to construct a system like this or whether it is an excessive amount of work.
I’d do one thing that may clearly evaluate the output high quality for naive RAG vs better-chunked RAG with enlargement/metadata sooner or later.
I’d additionally like to check the identical use case utilizing information graphs.
To take a look at extra of my work and observe my future writing, join with me on LinkedIn, Medium, Substack, or test my web site.
❤
PS. I’m on the lookout for some work in January. When you want somebody who’s constructing on this house (and enjoys constructing bizarre, enjoyable issues whereas explaining tough technical ideas), get in contact.



{kind=link}