This put up was written with NVIDIA and the authors wish to thank Adi Margolin, Eliuth Triana, and Maryam Motamedi for his or her collaboration.
Organizations at the moment face the problem of processing giant volumes of audio knowledge–from buyer calls and assembly recordings to podcasts and voice messages–to unlock worthwhile insights. Computerized Speech Recognition (ASR) is a essential first step on this course of, changing speech to textual content in order that additional evaluation may be carried out. Nonetheless, working ASR at scale is computationally intensive and may be costly. That is the place asynchronous inference on Amazon SageMaker AI is available in. By deploying state-of-the-art ASR fashions (like NVIDIA Parakeet fashions) on SageMaker AI with asynchronous endpoints, you possibly can deal with giant audio information and batch workloads effectively. With asynchronous inference, long-running requests may be processed within the background (with outcomes delivered later); it additionally helps auto-scaling to zero when there’s no work and handles spikes in demand with out blocking different jobs.
On this weblog put up, we’ll discover the best way to host the NVIDIA Parakeet ASR mannequin on SageMaker AI and combine it into an asynchronous pipeline for scalable audio processing. We’ll additionally spotlight the advantages of Parakeet’s structure and the NVIDIA Riva toolkit for speech AI, and talk about the best way to use NVIDIA NIM for deployment on AWS.
NVIDIA speech AI applied sciences: Parakeet ASR and Riva Framework
NVIDIA presents a complete suite of speech AI applied sciences, combining high-performance fashions with environment friendly deployment options. At its core, the Parakeet ASR mannequin household represents state-of-the-art speech recognition capabilities, reaching industry-leading accuracy with low phrase error charges (WERs) . The mannequin’s structure makes use of the Quick Conformer encoder with the CTC or transducer decoder, enabling 2.4× quicker processing than customary Conformers whereas sustaining accuracy.
NVIDIA speech NIM is a set of GPU-accelerated microservices for constructing customizable speech AI functions. NVIDIA Speech fashions ship correct transcription accuracy and pure, expressive voices in over 36 languages–supreme for customer support, contact facilities, accessibility, and world enterprise workflows. Builders can fine-tune and customise fashions for particular languages, accents, domains, and vocabularies, supporting accuracy and model voice alignment.
Seamless integration with LLMs and the NVIDIA Nemo Retriever make NVIDIA fashions supreme for agentic AI functions, serving to your group stand out with safer, high-performing, voice AI. The NIM framework delivers these providers as containerized options, making deployment easy by way of Docker containers that embody the mandatory dependencies and optimizations.
This mixture of high-performance fashions and deployment instruments offers organizations with an entire resolution for implementing speech recognition at scale.
Resolution overview
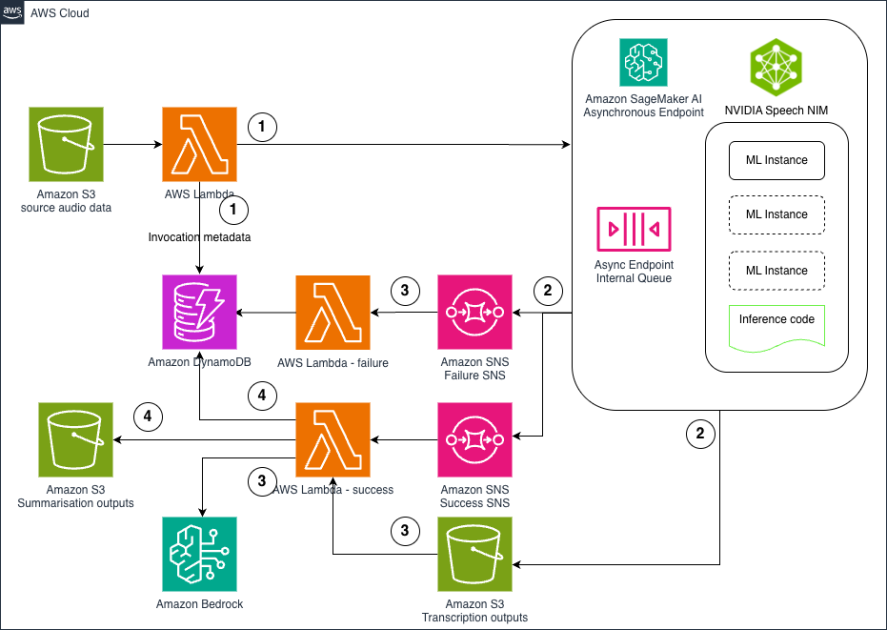
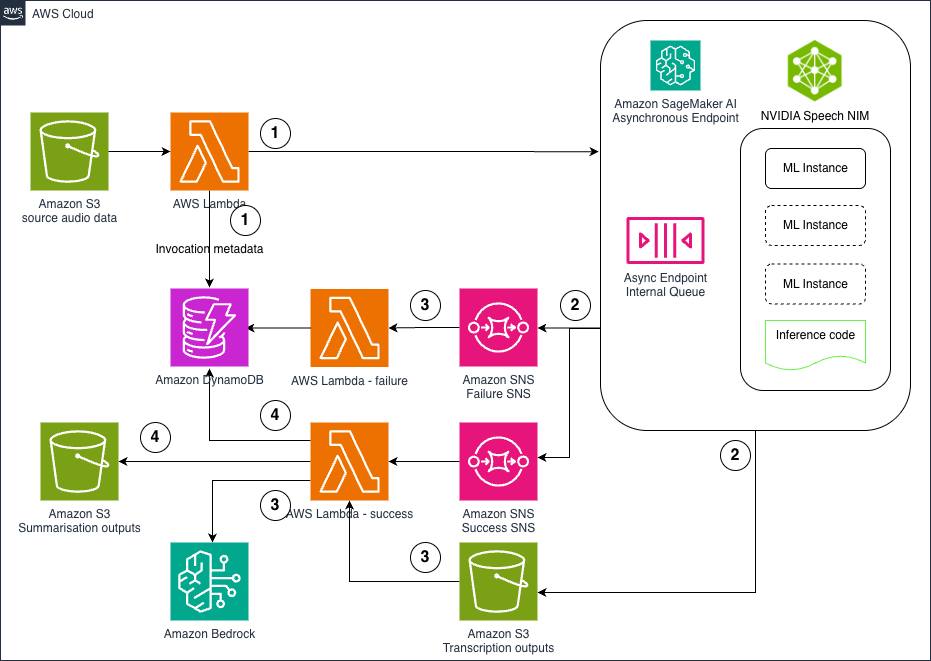
The structure illustrated within the diagram showcases a complete asynchronous inference pipeline designed particularly for ASR and summarization workloads. The answer offers a sturdy, scalable, and cost-effective processing pipeline.
Structure elements
The structure consists of 5 key elements working collectively to create an environment friendly audio processing pipeline. At its core, the SageMaker AI asynchronous endpoint hosts the Parakeet ASR mannequin with auto scaling capabilities that may scale to zero when idle for value optimization.
- The info ingestion course of begins when audio information are uploaded to Amazon Easy Storage Service (Amazon S3), triggering AWS Lambda features that course of metadata and provoke the workflow.
- For occasion processing, the SageMaker endpoint mechanically sends out Amazon Easy Notification Service (Amazon SNS) success and failure notifications by way of separate queues, enabling correct dealing with of transcriptions.
- Efficiently transcribed content material on Amazon S3 strikes to Amazon Bedrock LLMs for clever summarization and extra processing like classification and insights extraction.
- Lastly, a complete monitoring system utilizing Amazon DynamoDB shops workflow standing and metadata, enabling real-time monitoring and analytics of your complete pipeline.
Detailed implementation walkthrough
On this part, we are going to present the detailed walkthrough of the answer implementation.
SageMaker asynchronous endpoint conditions
To run the instance notebooks, you want an AWS account with an AWS Identification and Entry Administration (IAM) function with least-privilege permissions to handle assets created. For particulars, consult with Create an AWS account. You may have to request a service quota enhance for the corresponding SageMaker async internet hosting cases. On this instance, we’d like one ml.g5.xlarge SageMaker async internet hosting occasion and a ml.g5.xlarge SageMaker pocket book occasion. You can even select a special built-in growth surroundings (IDE), however make certain the surroundings comprises GPU compute assets for native testing.
SageMaker asynchronous endpoint configuration
While you deploy a customized mannequin like Parakeet, SageMaker has a few choices:
- Use a NIM container supplied by NVIDIA
- Use a big mannequin inference (LMI) container
- Use a prebuilt PyTorch container
We’ll present examples for all three approaches.
Utilizing an NVIDIA NIM container
NVIDIA NIM offers a streamlined strategy to deploying optimized AI fashions by way of containerized options. Our implementation takes this idea additional by making a unified SageMaker AI endpoint that intelligently routes between HTTP and gRPC protocols to assist maximize each efficiency and capabilities whereas simplifying the deployment course of.
Modern dual-protocol structure
The important thing innovation is the mixed HTTP + gRPC structure that exposes a single SageMaker AI endpoint with clever routing capabilities. This design addresses the widespread problem of selecting between protocol effectivity and have completeness by mechanically deciding on the optimum transport methodology. The HTTP route is optimized for easy transcription duties with information underneath 5MB, offering quicker processing and decrease latency for widespread use circumstances. In the meantime, the gRPC route helps bigger information (SageMaker AI real-time endpoints assist a max payload of 25MB) and superior options like speaker diarization with exact word-level timing info. The system’s auto-routing performance analyzes incoming requests to find out file measurement and requested options, then mechanically selects essentially the most acceptable protocol with out requiring handbook configuration. For functions that want specific management, the endpoint additionally helps compelled routing by way of /invocations/http for easy transcription or /invocations/grpc when speaker diarization is required. This flexibility permits each automated optimization and fine-grained management primarily based on particular software necessities.
Superior speech recognition and speaker diarization capabilities
The NIM container permits a complete audio processing pipeline that seamlessly combines speech recognition with speaker identification by way of the NVIDIA Riva built-in capabilities. The container handles audio preprocessing, together with format conversion and segmentation, whereas ASR and speaker diarization processes run concurrently on the identical audio stream. Outcomes are mechanically aligned utilizing overlapping time segments, with every transcribed phase receiving acceptable speaker labels (for instance, Speaker_0, Speaker_1). The inference handler processes audio information by way of the whole pipeline, initializing each ASR and speaker diarization providers, working them in parallel, and aligning transcription segments with speaker labels. The output contains the complete transcription, timestamped segments with speaker attribution, confidence scores, and complete speaker depend in a structured JSON format.
Implementation and deployment
The implementation extends NVIDIA parakeet-1-1b-ctc-en-us NIM container as the inspiration, including a Python aiohttp server that seamlessly manages the whole NIM lifecycle by mechanically beginning and monitoring the service. The server handles protocol adaptation by translating SageMaker inference requests to acceptable NIM APIs, implements the clever routing logic that analyzes request traits, and offers complete error dealing with with detailed error messages and fallback mechanisms for sturdy manufacturing deployment. The containerized resolution streamlines deployment by way of customary Docker and AWS CLI instructions, that includes a pre-configured Docker file with the mandatory dependencies and optimizations. The system accepts a number of enter codecs together with multipart form-data (really helpful for optimum compatibility), JSON with base64 encoding for easy integration eventualities, and uncooked binary uploads for direct audio processing.
For detailed implementation directions and dealing examples, groups can reference the full implementation and deployment pocket book within the AWS samples repository, which offers complete steering on deploying Parakeet ASR with NIM on SageMaker AI utilizing the deliver your individual container (BYOC) strategy. For organizations with particular architectural preferences, separate HTTP-only and gRPC-only implementations are additionally accessible, offering easier deployment fashions for groups with well-defined use circumstances whereas the mixed implementation presents most flexibility and automated optimization.
AWS prospects can deploy these fashions both as production-grade NVIDIA NIM containers instantly from SageMaker Market or JumpStart, or open supply NVIDIA fashions accessible on Hugging Face, which may be deployed by way of customized containers on SageMaker or Amazon Elastic Kubernetes Service (Amazon EKS). This enables organizations to decide on between totally managed, enterprise-tier endpoints with auto-scaling and safety, or versatile open-source growth for analysis or constrained use circumstances.
Utilizing an AWS LMI container
LMI containers are designed to simplify internet hosting giant fashions on AWS. These containers embody optimized inference engines like vLLM, FasterTransformer, or TensorRT-LLM that may mechanically deal with issues like mannequin parallelism, quantization, and batching for giant fashions. The LMI container is basically a pre-configured Docker picture that runs an inference server (for instance a Python server with these optimizations) and permits you to specify mannequin parameters through the use of surroundings variables.
To make use of the LMI container for Parakeet, we’d usually:
- Select the suitable LMI picture: AWS offers completely different LMI pictures for various frameworks. For Parakeet , we would use the DJLServing picture for environment friendly inference. Alternatively, NVIDIA Triton Inference Server (which Riva makes use of) is an possibility if we package deal the mannequin in ONNX or TensorRT format.
- Specify the mannequin configuration: With LMI, we frequently present a model_id (if pulling from Hugging Face Hub) or a path to our mannequin, together with configuration for the best way to load it (variety of GPUs, tensor parallel diploma, quantization bits). The container then downloads the mannequin and initializes it with the required settings. We will additionally obtain our personal mannequin information from Amazon S3 as an alternative of utilizing the Hub.
- Outline the inference handler: The LMI container may require a small handler script or configuration to inform it the best way to course of requests. For ASR, this may contain studying the audio enter, passing it to the mannequin, and returning textual content.
AWS LMI containers ship excessive efficiency and scalability by way of superior optimization strategies, together with steady batching, tensor parallelism, and state-of-the-art quantization strategies. LMI containers combine a number of inference backends (vLLM, TensorRT-LLM by way of a single unified configuration), serving to customers seamlessly experiment and swap between frameworks to search out the optimum efficiency stack on your particular use case.
Utilizing a SageMaker PyTorch container
SageMaker presents PyTorch Deep Studying Containers (DLCs) that include PyTorch and plenty of widespread libraries pre-installed. In this instance, we demonstrated the best way to prolong our prebuilt container to put in obligatory packages for the mannequin. You may obtain the mannequin instantly from Hugging Face throughout the endpoint creation or obtain the Parakeet mannequin artifacts, packaging it with obligatory configuration information right into a mannequin.tar.gz archive, and importing it to Amazon S3. Together with the mannequin artifacts, an inference.py script is required because the entry level script to outline mannequin loading and inference logic, together with audio preprocessing and transcription dealing with. When utilizing the SageMaker Python SDK to create a PyTorchModel, the SDK will mechanically repackage the mannequin archive to incorporate the inference script underneath /choose/ml/mannequin/code/inference.py, whereas preserving mannequin artifacts in /choose/ml/mannequin/ on the endpoint. As soon as the endpoint is deployed efficiently, it may be invoked by way of the predict API by sending audio information as byte streams to get transcription outcomes.
For the SageMaker real-time endpoint, we presently permit a most of 25MB for payload measurement. Be sure you have arrange the container to additionally permit the utmost request measurement. Nonetheless, in case you are planning to make use of the identical mannequin for the asynchronous endpoint, the utmost file measurement that the async endpoint helps is 1GB and the response time is as much as 1 hour. Accordingly, it is best to setup the container to be ready for this payload measurement and timeout. When utilizing the PyTorch containers, listed here are some key configuration parameters to contemplate:
- SAGEMAKER_MODEL_SERVER_WORKERS: Set the variety of torch employees that can load the variety of fashions copied into GPU reminiscence.
- TS_DEFAULT_RESPONSE_TIMEOUT: Set the day trip setting for Torch server employees; for lengthy audio processing, you possibly can set it to a better quantity
- TS_MAX_REQUEST_SIZE: Set the byte measurement values for requests to 1G for async endpoints.
- TS_MAX_RESPONSE_SIZE: Set the byte measurement values for response.
Within the instance pocket book, we additionally showcase the best way to leverage the SageMaker native session supplied by the SageMaker Python SDK. It helps you create estimators and run coaching, processing, and inference jobs regionally utilizing Docker containers as an alternative of managed AWS infrastructure, offering a quick solution to take a look at and debug your machine studying scripts earlier than scaling to manufacturing.
CDK pipeline conditions
Earlier than deploying this resolution, be sure you have:
- AWS CLI configured with acceptable permissions – Set up Information
- AWS Cloud Improvement Package (AWS CDK) put in – Set up Information
- Node.js 18+ and Python 3.9+ put in
- Docker – Set up Information
- SageMaker endpoint deployed together with your ML mannequin (Parakeet ASR fashions or comparable)
- Amazon SNS matters created for achievement and failure notifications
CDK pipeline setup
The answer deployment begins with provisioning the mandatory AWS assets utilizing Infrastructure as Code (IaC) ideas. AWS CDK creates the foundational elements together with:
- DynamoDB Desk: Configured for on-demand capability to trace invocation metadata, processing standing, and outcomes
- S3 Buckets: Safe storage for enter audio information, transcription outputs, and summarization outcomes
- SNS matters: Separate queues for achievement and failure occasion dealing with
- Lambda features: Serverless features for metadata processing, standing updates, and workflow orchestration
- IAM roles and insurance policies: Acceptable permissions for cross-service communication and useful resource entry
Setting setup
Clone the repository and set up dependencies:
Configuration
Replace the SageMaker endpoint configuration in bin/aws-blog-sagemaker.ts:
When you have adopted the pocket book to deploy the endpoint, it is best to have created the 2 SNS matters. In any other case, be sure you create the proper SNS matters utilizing CLI:
Construct and deploy
Earlier than you deploy the AWS CloudFormation template, make certain Docker is working.
Confirm deployment
After profitable deployment, be aware the output values:
- DynamoDB desk identify for standing monitoring
- Lambda operate ARNs for processing and standing updates
- SNS subject ARNs for notifications
Submit audio file for processing
Processing Audio Recordsdata
Replace the upload_audio_invoke_lambda.sh
Run the Script:
AWS_PROFILE=default ./scripts/upload_audio_invoke_lambda.sh
This script will:
- Obtain a pattern audio file
- Add the audio file to your s3 bucket
- Ship the bucket path to Lambda and set off the transcription and summarization pipeline
Monitoring progress
You may verify the lead to DynamoDB desk utilizing the next command:
Examine processing standing within the DynamoDB desk:
- submitted: Efficiently queued for inference
- accomplished: Transcription accomplished efficiently
- failed: Processing encountered an error
Audio processing and workflow orchestration
The core processing workflow follows an event-driven sample:
Preliminary processing and metadata extraction: When audio information are uploaded to S3, the triggered Lambda operate analyzes the file metadata, validates format compatibility, and creates detailed invocation information in DynamoDB. This facilitates complete monitoring from the second audio content material enters the system.
Asynchronous Speech Recognition: Audio information are processed by way of the SageMaker endpoint utilizing optimized ASR fashions. The asynchronous course of can deal with varied file sizes and durations with out timeout issues. Every processing request is assigned a singular identifier for monitoring functions.
Success path processing: Upon profitable transcription, the system mechanically initiates the summarization workflow. The transcribed textual content is shipped to Amazon Bedrock, the place superior language fashions generate contextually acceptable summaries primarily based on configurable parameters comparable to abstract size, focus areas, and output format.
Error dealing with and restoration: Failed processing makes an attempt set off devoted Lambda features that log detailed error info, replace processing standing, and might provoke retry logic for transient failures. This sturdy error dealing with ends in minimal knowledge loss and offers clear visibility into processing points.
Actual-world functions
Customer support analytics: Organizations can course of 1000’s of customer support name recordings to generate transcriptions and summaries, enabling sentiment evaluation, high quality assurance, and insights extraction at scale.
Assembly and convention processing: Enterprise groups can mechanically transcribe and summarize assembly recordings, creating searchable archives and actionable summaries for members and stakeholders.
Media and content material processing: Media firms can course of podcast episodes, interviews, and video content material to generate transcriptions and summaries for improved accessibility and content material discoverability.
Compliance and authorized documentation: Authorized and compliance groups can course of recorded depositions, hearings, and interviews to create correct transcriptions and summaries for case preparation and documentation.
Cleanup
After getting used the answer, take away the SageMaker endpoints to stop incurring extra prices. You should use the supplied code to delete real-time and asynchronous inference endpoints, respectively:
You also needs to delete all of the assets created by the CDK stack.
Conclusion
The mixing of highly effective NVIDIA speech AI applied sciences with AWS cloud infrastructure creates a complete resolution for large-scale audio processing. By combining Parakeet ASR’s industry-leading accuracy and velocity with NVIDIA Riva’s optimized deployment framework on the Amazon SageMaker asynchronous inference pipeline, organizations can obtain each high-performance speech recognition and cost-effective scaling. The answer leverages the managed providers of AWS (SageMaker AI, Lambda, S3, and Bedrock) to create an automatic, scalable pipeline for processing audio content material. With options like auto scaling to zero, complete error dealing with, and real-time monitoring by way of DynamoDB, organizations can deal with extracting enterprise worth from their audio content material fairly than managing infrastructure complexity. Whether or not processing customer support calls, assembly recordings, or media content material, this structure delivers dependable, environment friendly, and cost-effective audio processing capabilities. To expertise the complete potential of this resolution, we encourage you to discover the answer and attain out to us when you have any particular enterprise necessities and wish to customise the answer on your use case.
In regards to the authors
 Melanie Li, PhD, is a Senior Generative AI Specialist Options Architect at AWS primarily based in Sydney, Australia, the place her focus is on working with prospects to construct options utilizing state-of-the-art AI/ML instruments. She has been actively concerned in a number of generative AI initiatives throughout APJ, harnessing the ability of LLMs. Previous to becoming a member of AWS, Dr. Li held knowledge science roles within the monetary and retail industries.
Melanie Li, PhD, is a Senior Generative AI Specialist Options Architect at AWS primarily based in Sydney, Australia, the place her focus is on working with prospects to construct options utilizing state-of-the-art AI/ML instruments. She has been actively concerned in a number of generative AI initiatives throughout APJ, harnessing the ability of LLMs. Previous to becoming a member of AWS, Dr. Li held knowledge science roles within the monetary and retail industries.
 Tony Trinh is a Senior AI/ML Specialist Architect at AWS. With 13+ years of expertise within the IT {industry}, Tony makes a speciality of architecting scalable, compliance-driven AI and ML options—significantly in generative AI, MLOps, and cloud-native knowledge platforms. As a part of his PhD, he’s doing analysis in Multimodal AI and Spatial AI. In his spare time, Tony enjoys mountain climbing, swimming and experimenting with dwelling enchancment.
Tony Trinh is a Senior AI/ML Specialist Architect at AWS. With 13+ years of expertise within the IT {industry}, Tony makes a speciality of architecting scalable, compliance-driven AI and ML options—significantly in generative AI, MLOps, and cloud-native knowledge platforms. As a part of his PhD, he’s doing analysis in Multimodal AI and Spatial AI. In his spare time, Tony enjoys mountain climbing, swimming and experimenting with dwelling enchancment.
 Alick Wong is a Senior Options Architect at Amazon Net Providers, the place he helps startups and digital-native companies modernize, optimize, and scale their platforms within the cloud. Drawing on his expertise as a former startup CTO, he works intently with founders and engineering leaders to drive development and innovation on AWS.
Alick Wong is a Senior Options Architect at Amazon Net Providers, the place he helps startups and digital-native companies modernize, optimize, and scale their platforms within the cloud. Drawing on his expertise as a former startup CTO, he works intently with founders and engineering leaders to drive development and innovation on AWS.
 Andrew Smith is a Sr. Cloud Assist Engineer within the SageMaker, Imaginative and prescient & Different crew at AWS, primarily based in Sydney, Australia. He helps prospects utilizing many AI/ML providers on AWS with experience in working with Amazon SageMaker. Outdoors of labor, he enjoys spending time with family and friends in addition to studying about completely different applied sciences.
Andrew Smith is a Sr. Cloud Assist Engineer within the SageMaker, Imaginative and prescient & Different crew at AWS, primarily based in Sydney, Australia. He helps prospects utilizing many AI/ML providers on AWS with experience in working with Amazon SageMaker. Outdoors of labor, he enjoys spending time with family and friends in addition to studying about completely different applied sciences.
 Derrick Choo is a Senior AI/ML Specialist Options Architect at AWS who accelerates enterprise digital transformation by way of cloud adoption, AI/ML, and generative AI options. He makes a speciality of full-stack growth and ML, designing end-to-end options spanning frontend interfaces, IoT functions, knowledge integrations, and ML fashions, with a selected deal with pc imaginative and prescient and multi-modal techniques.
Derrick Choo is a Senior AI/ML Specialist Options Architect at AWS who accelerates enterprise digital transformation by way of cloud adoption, AI/ML, and generative AI options. He makes a speciality of full-stack growth and ML, designing end-to-end options spanning frontend interfaces, IoT functions, knowledge integrations, and ML fashions, with a selected deal with pc imaginative and prescient and multi-modal techniques.
 Tim Ma is a Principal Specialist in Generative AI at AWS, the place he collaborates with prospects to design and deploy cutting-edge machine studying options. He additionally leads go-to-market methods for generative AI providers, serving to organizations harness the potential of superior AI applied sciences.
Tim Ma is a Principal Specialist in Generative AI at AWS, the place he collaborates with prospects to design and deploy cutting-edge machine studying options. He additionally leads go-to-market methods for generative AI providers, serving to organizations harness the potential of superior AI applied sciences.
 Curt Lockhart is an AI Options Architect at NVIDIA, the place he helps prospects deploy language and imaginative and prescient fashions to construct finish to finish AI workflows utilizing NVIDIA’s tooling on AWS. He enjoys making complicated AI really feel approachable and spending his time exploring the artwork, music, and open air of the Pacific Northwest.
Curt Lockhart is an AI Options Architect at NVIDIA, the place he helps prospects deploy language and imaginative and prescient fashions to construct finish to finish AI workflows utilizing NVIDIA’s tooling on AWS. He enjoys making complicated AI really feel approachable and spending his time exploring the artwork, music, and open air of the Pacific Northwest.
 Francesco Ciannella is a senior engineer at NVIDIA, the place he works on conversational AI options constructed round giant language fashions (LLMs) and audio language fashions (ALMs). He holds a M.S. in engineering of telecommunications from the College of Rome “La Sapienza” and an M.S. in language applied sciences from the Faculty of Laptop Science at Carnegie Mellon College.
Francesco Ciannella is a senior engineer at NVIDIA, the place he works on conversational AI options constructed round giant language fashions (LLMs) and audio language fashions (ALMs). He holds a M.S. in engineering of telecommunications from the College of Rome “La Sapienza” and an M.S. in language applied sciences from the Faculty of Laptop Science at Carnegie Mellon College.



{kind=link}